ReFPO: Reflow Regularization for Flow Matching Policy Gradients
Pith reviewed 2026-06-26 14:37 UTC · model grok-4.3
The pith
Flow matching policy gradients implicitly perform advantage-weighted Reflow, so an explicit geometric regularizer added in one line stabilizes training and supports accurate one-step inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The gradient updates in Flow Matching Policy Gradients can be interpreted as an implicit advantage-weighted Reflow process. Building on this, ReFPO introduces an explicit geometric regularizer implemented with a single line of code change. This regularization reduces CFM proxy-ratio spikes, stabilizes training, and enables high-fidelity one-step inference often matching or exceeding multi-step performance across GridWorld, MuJoCo Playground, and Humanoid Control tasks.
What carries the argument
The advantage-weighted Reflow process interpretation of FPO gradients, which motivates the explicit Reflow geometric regularizer.
If this is right
- Reduces CFM proxy-ratio spikes during training
- Stabilizes PPO-style training without auxiliary stages
- Enables high-fidelity one-step inference that matches or exceeds multi-step
- Improves average performance and discretization robustness in control tasks
Where Pith is reading between the lines
- This geometric regularization might apply to other generative policy optimization methods beyond flow matching.
- Explicit path rectification could further improve sample efficiency in high-dimensional control.
- Stable one-step inference opens possibilities for real-time deployment of generative policies in robotics.
Load-bearing premise
The gradient updates in Flow Matching Policy Gradients can be interpreted as an implicit advantage-weighted Reflow process.
What would settle it
If experiments show that the explicit Reflow regularizer does not reduce CFM proxy-ratio spikes or improve one-step inference performance compared to standard FPO, the value of the regularization would be falsified.
Figures

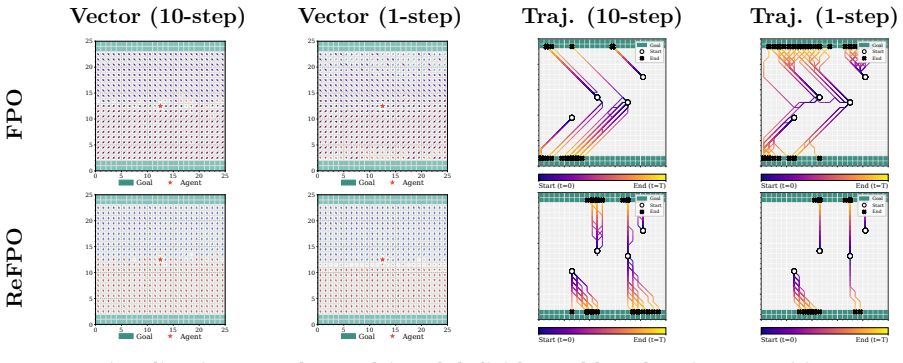
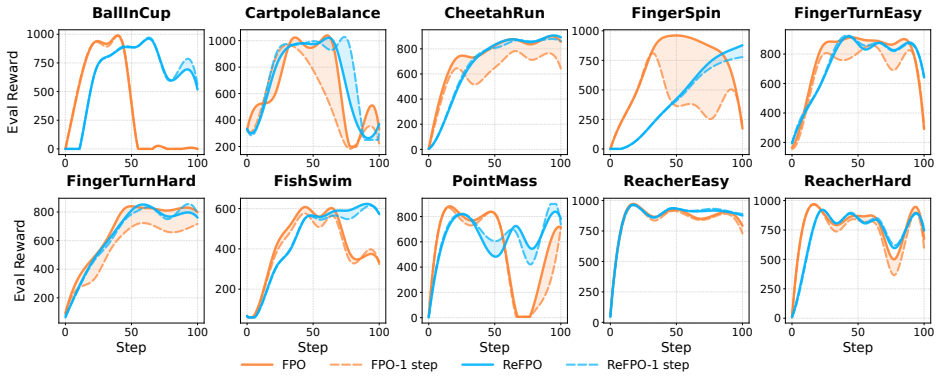
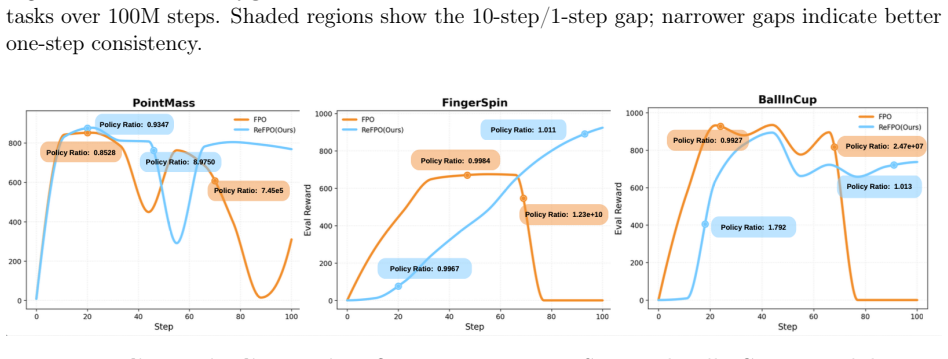
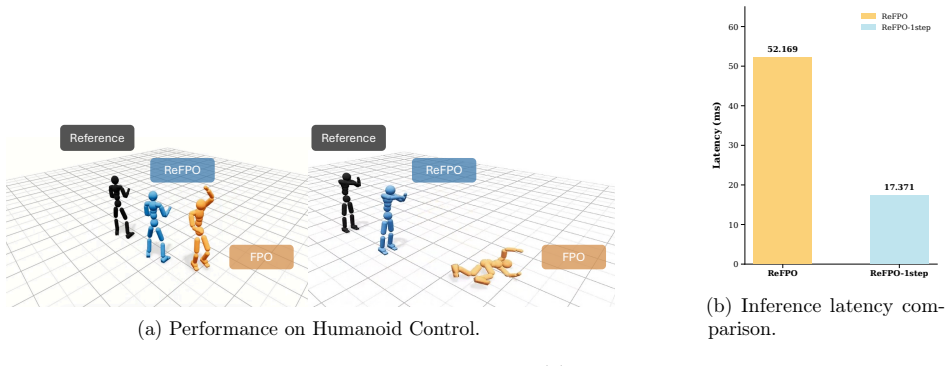
read the original abstract
We present Reflow-regularized Flow Matching Policy Gradients (ReFPO), a simple online RL method that adds explicit Reflow regularization to FPO for efficient flow-based control. We uncover a key structural property: the gradient updates in Flow Matching Policy Gradients (FPO) can be interpreted as an implicit advantage-weighted Reflow process, providing a new geometric perspective on flow-based policy gradients. Building on this insight, ReFPO introduces an explicit geometric regularizer that can be implemented with a single line of code change without incurring additional computational overhead or auxiliary distillation stages. By synergizing advantage-guided updates with path rectification, our method reduces CFM proxy-ratio spikes, stabilizes PPO-style training, and enables high-fidelity one-step inference that often matches or exceeds multi-step performance. We experimentally demonstrate that ReFPO improves average performance and discretization robustness across GridWorld, MuJoCo Playground, and high-dimensional Humanoid Control tasks, providing a scalable and stable approach for generative policies in complex physical simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReFPO, which augments Flow Matching Policy Gradients (FPO) with an explicit Reflow regularization term. It claims that FPO gradient updates constitute an implicit advantage-weighted Reflow process, motivating a single-line geometric regularizer that reduces CFM proxy-ratio spikes, stabilizes training, and supports high-fidelity one-step inference. Experiments on GridWorld, MuJoCo Playground, and Humanoid control tasks report improved average performance and discretization robustness.
Significance. If the structural property is rigorously established and the regularizer proves effective without hidden costs, the work supplies a lightweight stabilization technique for flow-based generative policies in RL. The geometric framing could inform future policy-gradient designs that combine advantage weighting with path rectification, and the single-line implementation claim is a practical strength if verified.
major comments (2)
- [Section 3 (Structural Property and Motivation)] The central structural claim—that FPO gradients are an implicit advantage-weighted Reflow process—is load-bearing for the motivation of the explicit regularizer, yet no derivation is supplied that aligns the CFM velocity field, advantage weighting, and path-rectification terms. Without this step-by-step equivalence (or an ablation isolating the implicit Reflow component), the geometric justification remains an unverified modeling choice rather than a necessary consequence of the FPO objective.
- [§4 (Method)] §4 (Method) and Algorithm 1: the claim that the regularizer incurs “no additional computational overhead” and requires only “a single line of code change” must be supported by explicit complexity analysis and a side-by-side code diff; the current description does not quantify the extra gradient term’s cost relative to the base FPO update.
minor comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): performance claims are stated without error bars, number of seeds, or statistical tests; tables or figures should report mean ± std across runs to substantiate “improves average performance.”
- [§2 (Preliminaries)] Notation: the distinction between the CFM proxy ratio and the advantage-weighted Reflow objective is introduced without a clear equation reference; a dedicated notation table or inline definitions would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and commit to revisions that strengthen the manuscript where the points are valid.
read point-by-point responses
-
Referee: [Section 3 (Structural Property and Motivation)] The central structural claim—that FPO gradients are an implicit advantage-weighted Reflow process—is load-bearing for the motivation of the explicit regularizer, yet no derivation is supplied that aligns the CFM velocity field, advantage weighting, and path-rectification terms. Without this step-by-step equivalence (or an ablation isolating the implicit Reflow component), the geometric justification remains an unverified modeling choice rather than a necessary consequence of the FPO objective.
Authors: We agree that the structural claim is central and that the manuscript lacks an explicit derivation. In the revision we will add a step-by-step derivation in Section 3 that aligns the CFM velocity field, advantage weighting, and path-rectification terms. We will also include an ablation isolating the implicit Reflow component. revision: yes
-
Referee: [§4 (Method)] §4 (Method) and Algorithm 1: the claim that the regularizer incurs “no additional computational overhead” and requires only “a single line of code change” must be supported by explicit complexity analysis and a side-by-side code diff; the current description does not quantify the extra gradient term’s cost relative to the base FPO update.
Authors: We acknowledge that the overhead and single-line claims require explicit support. In the revision we will add a complexity analysis of the extra gradient term relative to base FPO and include a side-by-side code diff (in the main text or appendix) to demonstrate the change and quantify cost. revision: yes
Circularity Check
No circularity: structural interpretation presented as modeling insight without reduction to fitted inputs or self-citation chains
full rationale
The paper states an interpretation of FPO gradients as an implicit advantage-weighted Reflow process and uses it to motivate an explicit regularizer, but the provided text contains no equations, fitting procedures, or self-citations that reduce the claimed property or regularizer to the inputs by construction. The regularizer is introduced as an additive change rather than a tautological renaming or statistical forcing of a fitted quantity. No load-bearing step equates the output to the input via definition or prior self-work, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=YCWjhGrJFD
2024
-
[2]
Openai gym.arXiv preprint arXiv:1606.01540, 2016
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
Pith/arXiv arXiv 2016
-
[3]
One-step flow policy mirror descent
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent. arXiv preprint arXiv:2507.23675, 2025
arXiv 2025
-
[4]
Zhenglin Cheng, Peng Sun, Jianguo Li, and Tao Lin. Twinflow: Realizing one-step generation on large models with self-adversarial flows.arXiv preprint arXiv:2512.05150, 2025
arXiv 2025
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[6]
Online reward-weighted fine-tuning of flow matching with wasserstein regularization
Jiajun Fan, Shuaike Shen, Chaoran Cheng, Yuxin Chen, Chumeng Liang, and Ge Liu. Online reward-weighted fine-tuning of flow matching with wasserstein regularization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=OlzB6LnXcS
2025
-
[8]
Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
Pith/arXiv arXiv 2025
-
[9]
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
Pith/arXiv arXiv 2023
-
[10]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, pages 9902–9915. PMLR, 2022
2022
-
[11]
Understanding diffusion objectives as the ELBO with simple data augmentation
Diederik P Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=NnMEadcdyD
2023
-
[12]
Optimal flow matching: Learning straight trajectories in just one step.Advances in Neural Information Processing Systems, 37:104180–104204, 2024
Nikita Kornilov, Petr Mokrov, Alexander Gasnikov, and Aleksandr Korotin. Optimal flow matching: Learning straight trajectories in just one step.Advances in Neural Information Processing Systems, 37:104180–104204, 2024
2024
-
[13]
JunzheLi, YutaoCui, TaoHuang, YinpingMa, ChunFan, MilesYang, andZhaoZhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025
Pith/arXiv arXiv 2025
-
[14]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=XUks1Y96NR. 12
2025
-
[15]
Shanchuan Lin, Ceyuan Yang, Zhijie Lin, Hao Chen, and Haoqi Fan. Adversarial flow models. arXiv preprint arXiv:2511.22475, 2025
Pith/arXiv arXiv 2025
-
[16]
Flashaudio: Rectified flow for fast and high-fidelity text-to-audio generation
Huadai Liu, Jialei Wang, Rongjie Huang, Yang Liu, Heng Lu, Zhou Zhao, and Wei Xue. Flashaudio: Rectified flow for fast and high-fidelity text-to-audio generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13694–13710, 2025
2025
-
[17]
Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Pith/arXiv arXiv 2025
-
[18]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=XVjTT1nw5z
2023
-
[19]
Soflow: Solution flow models for one-step generative modeling.arXiv preprint arXiv:2512.15657, 2025
Tianze Luo, Haotian Yuan, and Zhuang Liu. Soflow: Solution flow models for one-step generative modeling.arXiv preprint arXiv:2512.15657, 2025
arXiv 2025
-
[20]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023
2023
-
[21]
Flow-based policy for online reinforcement learning.arXiv preprint arXiv:2506.12811, 2025
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, Tao Kong, Jiafeng Xu, and Xiao Ma. Flow-based policy for online reinforcement learning.arXiv preprint arXiv:2506.12811, 2025
arXiv 2025
-
[22]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[23]
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[24]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
arXiv 2025
-
[25]
Thanh Nguyen and Chang D Yoo. Revisiting diffusion q-learning: From iterative denoising to one-step action generation.arXiv preprint arXiv:2508.13904, 2025
arXiv 2025
-
[26]
Flow q-learning.arXiv preprint arXiv:2502.02538, 2025
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning.arXiv preprint arXiv:2502.02538, 2025
arXiv 2025
-
[27]
Deepmimic: Example- guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. Deepmimic: Example- guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[28]
Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz
Allen Z. Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=mEpqHvbD2h. 13
2025
-
[29]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[30]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642, 2025
arXiv 2025
-
[31]
LEARNING STRAIGHT FLOWS BY LEARNING CURVED INTERPOLANTS
Shiv Shankar and Tomas Geffner. LEARNING STRAIGHT FLOWS BY LEARNING CURVED INTERPOLANTS. InICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy, 2025. URLhttps://openreview.net/forum?id=9bJ2PJFNX4
2025
-
[32]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models, 2023. URL https://arxiv.org/abs/2303.01469
Pith/arXiv arXiv 2023
-
[33]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
Pith/arXiv arXiv 2018
-
[34]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[35]
Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, pages 1–34, 2024
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, pages 1–34, 2024
2024
-
[36]
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032, 2024
Pith/arXiv arXiv 2024
-
[37]
dm_control: Software and tasks for continuous control.Software Impacts, 6:100022, 2020
Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. dm_control: Software and tasks for continuous control.Software Impacts, 6:100022, 2020
2020
-
[38]
Zeyuan Wang, Da Li, Yulin Chen, Ye Shi, Liang Bai, Tianyuan Yu, and Yanwei Fu. One-step gen- erative policies with q-learning: A reformulation of meanflow.arXiv preprint arXiv:2511.13035, 2025
arXiv 2025
-
[39]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[40]
Consistency flow matching: Defining straight flows with velocity consistency.CoRR, 2024
Ling Yang, Zixiang Zhang, Zhilong Zhang, Xingchao Liu, Minkai Xu, Wentao Zhang, Chenlin Meng, Stefano Ermon, and Bin Cui. Consistency flow matching: Defining straight flows with velocity consistency.CoRR, 2024
2024
-
[41]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024. 14
2024
-
[42]
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur Allshire, Erik Frey, Koushil Sreenath, Lueder A Kahrs, et al. Mujoco playground. arXiv preprint arXiv:2502.08844, 2025
arXiv 2025
-
[43]
Energy-weighted flow matching for offline reinforcement learning
Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning. InThe Thirteenth International Conference on Learning Representations,
-
[44]
URLhttps://openreview.net/forum?id=HA0oLUvuGI
-
[45]
Reinflow: Fine-tuning flow matching policy with online reinforcement learning
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[46]
Xinxi Zhang, Shiwei Tan, Quang Nguyen, Quan Dao, Ligong Han, Xiaoxiao He, Tunyu Zhang, Alen Mrdovic, and Dimitris Metaxas. Flow straighter and faster: Efficient one-step generative modeling via meanflow on rectified trajectories.arXiv preprint arXiv:2511.23342, 2025
arXiv 2025
-
[47]
SCot: Unifying consistency models and rectified flows via straight-consistent trajectories
zhangkai wu, Xuhui Fan, Hongyu Wu, and Longbing Cao. SCot: Unifying consistency models and rectified flows via straight-consistent trajectories. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id= GV82iAD70j
2025
-
[48]
Linqi Zhou, Mathias Parger, Ayaan Haque, and Jiaming Song. Terminal velocity matching. arXiv preprint arXiv:2511.19797, 2025
arXiv 2025
-
[49]
Huminhao Zhu, Fangyikang Wang, Tianyu Ding, Qing Qu, and Zhihui Zhu. Analyzing and mitigating model collapse in rectified flow models.arXiv preprint arXiv:2412.08175, 2024
arXiv 2024
-
[50]
Slimflow: Training smaller one-step diffusion models with rectified flow
Yuanzhi Zhu, Xingchao Liu, and Qiang Liu. Slimflow: Training smaller one-step diffusion models with rectified flow. InEuropean Conference on Computer Vision, pages 342–359. Springer, 2024
2024
-
[51]
Di [m] o: Distilling masked diffusion models into one-step generator
Yuanzhi Zhu, Xi Wang, Stéphane Lathuilière, and Vicky Kalogeiton. Di [m] o: Distilling masked diffusion models into one-step generator. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18606–18618, 2025. 15 A Code and Supplementary Videos The source code for ReFPO is included in the supplementary materials to ensure the rep...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.