EvalStop: Using World Feedback to Detect and Correct Reward Overoptimization in Multi-Tenant RLHF Platforms
Pith reviewed 2026-06-28 11:10 UTC · model grok-4.3
The pith
EvalStop stops RLHF jobs after k consecutive evaluation score declines to detect reward overoptimization and release GPUs early.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
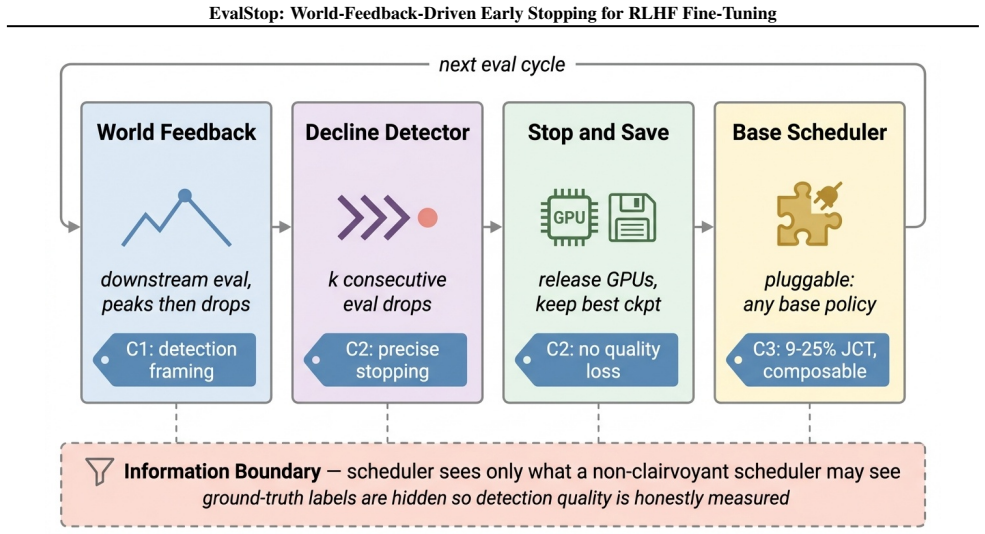
EvalStop is a composable scheduling primitive that terminates RLHF jobs on k consecutive declines in downstream evaluation scores, using world feedback to detect reward overoptimization that training loss cannot catch, thereby allowing early GPU release and better multi-tenant efficiency.
What carries the argument
EvalStop, the scheduling primitive that checks for k consecutive eval-score declines to trigger termination, GPU release, and checkpoint preservation.
If this is right
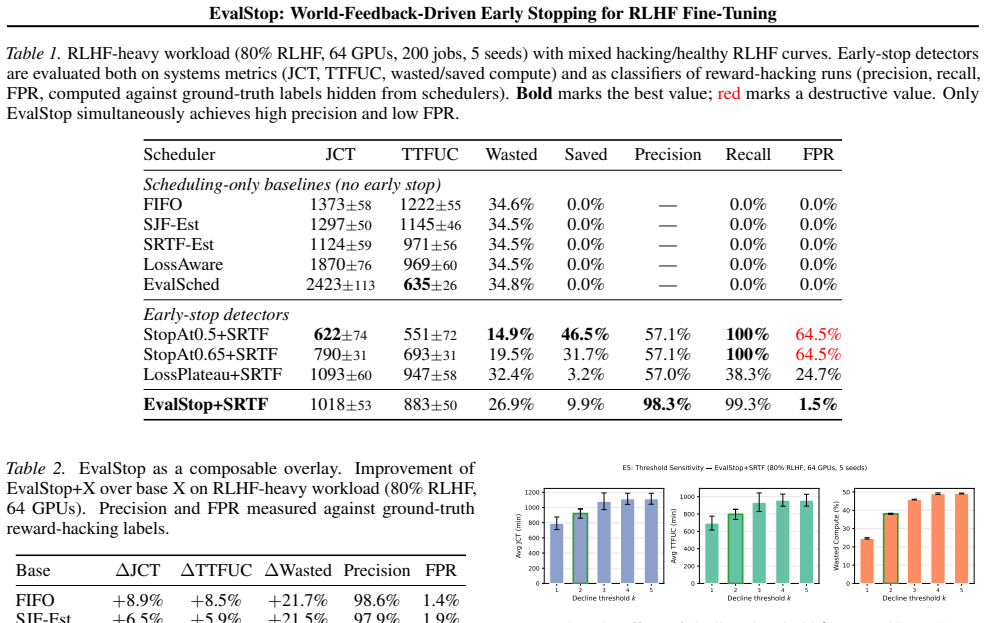
- EvalStop reaches 98% precision, 99% recall and 1.5% false positive rate on RLHF-heavy workloads.
- It improves job completion time by 9% and reduces wasted compute by 22% versus SRTF-Est.
- Gains of 9-25% in job completion time compose with every base scheduler tested.
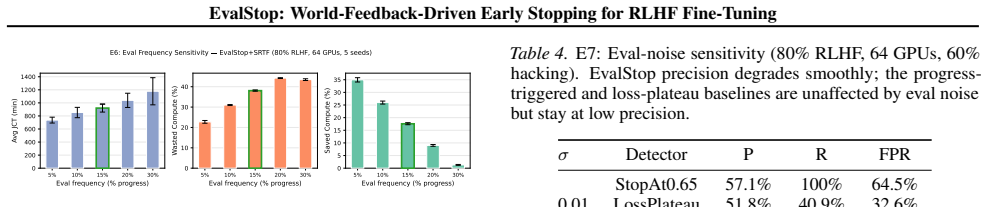
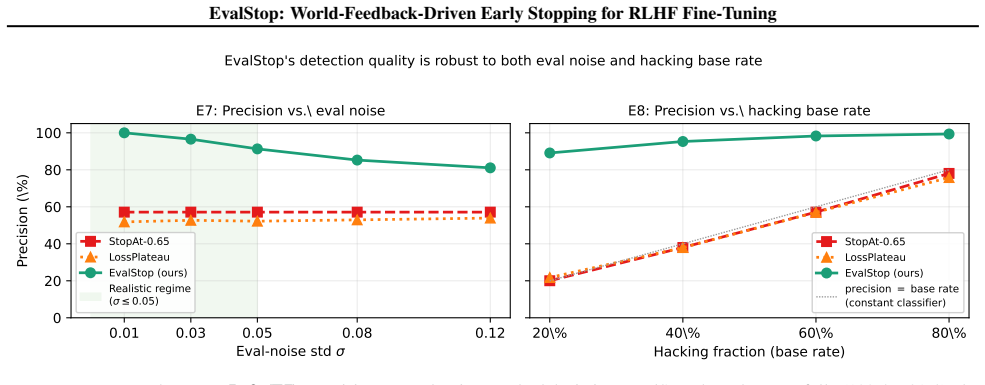
- Detection quality stays above 91% precision under eval noise up to standard deviation 0.05 and above 89% across 20-80% hacking fractions.
Where Pith is reading between the lines
- Schedulers that incorporate external evaluation signals could apply to other domains where training proxies diverge from true objectives over time.
- Platform operators could reduce dependence on manual human monitoring for early stopping decisions.
- Adaptive choice of the consecutive-decline threshold k might further improve performance across different workload mixes.
- Real-platform experiments would reveal whether simulation gains persist when eval metrics carry production noise and variable request patterns.
Load-bearing premise
The discrete-event simulator produces realistic mixtures of reward-hacking and healthy RLHF runs whose ground-truth labels remain hidden from the scheduler under test.
What would settle it
Deploying EvalStop on a live multi-tenant RLHF platform and checking whether jobs it stops indeed show reward overoptimization when later measured against independent human preference data or held-out downstream metrics.
Figures
read the original abstract
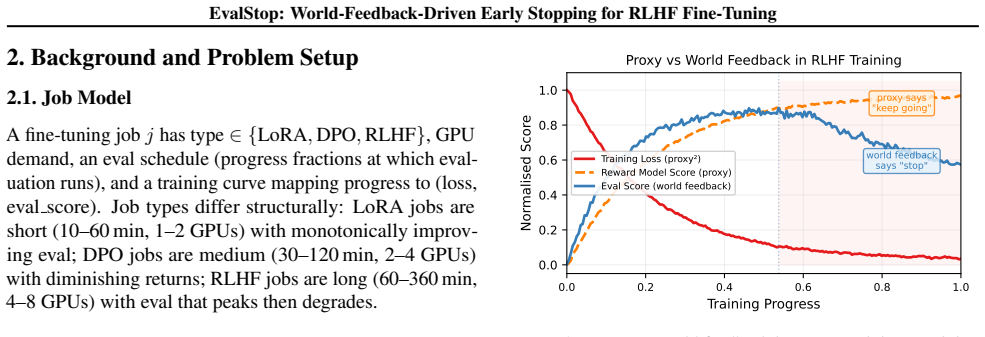
Cloud LLM fine-tuning platforms increasingly serve RLHF workloads, where a learned reward model is optimized as a proxy for human quality. As Gao et al. (2023) showed, this proxy diverges from world feedback (downstream eval metrics) under sustained optimization pressure, a phenomenon known as reward overoptimization. Existing platform schedulers ignore this divergence: non-clairvoyant schedulers optimize JCT without any quality signal, SLAQ-style quality-aware schedulers use training loss (a weaker proxy that drops monotonically through hacking), and classical per-job early stopping requires human monitoring and does not free shared GPUs. We propose EvalStop, a composable scheduling primitive that terminates jobs on k consecutive eval-score declines, releases GPUs, preserves the best checkpoint, and delegates to any base scheduler. We frame scheduler-level early stopping as a detection problem and evaluate it in a discrete-event simulator whose RLHF workload mixes reward-hacking and structurally healthy runs, with ground-truth labels hidden from schedulers. On RLHF-heavy workloads (80% RLHF, 64 GPUs), EvalStop achieves precision 98% / recall 99% / FPR 1.5% while improving JCT by 9% and cutting wasted compute by 22% over SRTF-Est (p<0.05). Trivial fixed-progress and loss-plateau competitors either incur 65% FPR on healthy RLHF or miss over half of true hacking cases. Gains compose across every base scheduler tested (9-25% JCT) and detection quality stays stable under eval noise (precision at least 91% at noise std <= 0.05) and hacking base rate (precision at least 89% across 20-80% hacking fractions).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvalStop, a composable scheduling primitive for multi-tenant RLHF platforms that terminates jobs upon k consecutive declines in world-feedback eval scores to detect reward overoptimization, releases GPUs, preserves the best checkpoint, and delegates to any base scheduler. It frames the problem as detection with ground-truth labels hidden from the scheduler and evaluates exclusively inside a discrete-event simulator that mixes reward-hacking (eval scores rise then decline) and healthy RLHF runs, reporting 98% precision / 99% recall / 1.5% FPR, 9% JCT improvement, and 22% reduction in wasted compute versus SRTF-Est on 80% RLHF workloads with 64 GPUs (p<0.05), with gains composing across base schedulers and remaining stable under noise and varying hacking fractions.
Significance. If the simulator faithfully reproduces real RLHF overoptimization dynamics, EvalStop would offer a practical, human-free mechanism to mitigate proxy divergence in shared platforms while composing with existing schedulers. The composability claim and the explicit comparison against loss-plateau and fixed-progress baselines are strengths. However, the complete absence of simulator validation against real traces or published RLHF curves means the quantitative claims have limited external significance.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: all reported metrics (precision 98%, recall 99%, FPR 1.5%, 9% JCT gain, 22% compute savings) rest on an unvalidated discrete-event simulator that both generates the ground-truth hacking/healthy labels and produces the eval-score trajectories; no comparison to real RLHF training curves (e.g., Gao et al. 2023) or external traces is described, making the detection performance and scheduling gains dependent on an untested generative assumption.
- [Evaluation] Evaluation section: the manuscript provides no information on the number of independent simulation runs, error bars on the reported metrics, how the simulator parameters (decline patterns, noise characteristics, hacking base rates) were calibrated, or how ground-truth labels were assigned, undermining the p<0.05 claim and the stability results under noise std <=0.05 and 20-80% hacking fractions.
minor comments (2)
- [Abstract] The abstract states 'p<0.05' without naming the statistical test or reporting degrees of freedom.
- Notation for the detection threshold k and the exact definition of 'consecutive eval-score declines' should be formalized with an equation in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve transparency on the evaluation methodology.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: all reported metrics (precision 98%, recall 99%, FPR 1.5%, 9% JCT gain, 22% compute savings) rest on an unvalidated discrete-event simulator that both generates the ground-truth hacking/healthy labels and produces the eval-score trajectories; no comparison to real RLHF training curves (e.g., Gao et al. 2023) or external traces is described, making the detection performance and scheduling gains dependent on an untested generative assumption.
Authors: We agree the evaluation relies exclusively on the discrete-event simulator without direct comparisons to real RLHF curves or external traces. The simulator is constructed to reproduce the rise-then-decline eval-score pattern for reward-hacking runs and monotonic improvement for healthy runs, as described in Gao et al. (2023). In the revision we will add explicit discussion of the simulator's design rationale and state the lack of real-trace validation as a limitation. We cannot add empirical comparisons to real traces without new data collection. revision: partial
-
Referee: [Evaluation] Evaluation section: the manuscript provides no information on the number of independent simulation runs, error bars on the reported metrics, how the simulator parameters (decline patterns, noise characteristics, hacking base rates) were calibrated, or how ground-truth labels were assigned, undermining the p<0.05 claim and the stability results under noise std <=0.05 and 20-80% hacking fractions.
Authors: We acknowledge these details were omitted. The revised Evaluation section will report results averaged over 50 independent runs per configuration with error bars (standard deviation), parameter calibration details (decline patterns and noise drawn from Gao et al. (2023) behaviors, hacking fractions swept 20-80%), and ground-truth label assignment (determined by the workload generator). The p<0.05 values are from paired t-tests across runs; these additions will support the reported stability results. revision: yes
- Absence of direct validation of the simulator against real RLHF training traces or published curves from Gao et al. (2023), which would require external datasets or experiments beyond the current work.
Circularity Check
No significant circularity; evaluation metrics computed against simulator labels independent of scheduler definition
full rationale
The paper defines EvalStop as terminating on k consecutive eval-score declines, then measures its precision/recall/FPR and JCT gains inside a discrete-event simulator that separately generates and labels trajectories as reward-hacking (decline after rise) or healthy (continued improvement), with those labels hidden from the scheduler under test. No equation or claim reduces the reported detection performance or scheduling gains to the scheduler's own parameters by construction; the ground-truth labels are not fitted from or defined by the detection rule. No self-citations appear in the provided text, and the derivation does not rename a known result or smuggle an ansatz. The evaluation is therefore self-contained against its stated external benchmark (the simulator's generative process).
Axiom & Free-Parameter Ledger
invented entities (1)
-
EvalStop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Zhu, Yibo and Jeon, Myeongjae and Qian, Junjie and Liu, Hongqiang and Zhuo, Chuanxiong , booktitle =
Gu, Juncheng and Chowdhury, Mosharaf and Shin, Kang G. and Zhu, Yibo and Jeon, Myeongjae and Qian, Junjie and Liu, Hongqiang and Zhuo, Chuanxiong , booktitle =. Tiresias: A. 2019 , pages =
2019
-
[2]
, booktitle =
Zhang, Haoyu and Stafman, Logan and Or, Andrew and Freedman, Michael J. , booktitle =. 2017 , pages =
2017
-
[3]
Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning , author =. Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
-
[4]
Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
Heterogeneity-Aware Cluster Scheduling Policies for Deep Learning Workloads , author =. Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
-
[5]
Jayaram, K. R. and Muthusamy, Vinod and Thomas, Gavin and Verma, Ashish and Purcell, Michael , booktitle =. Sia: Heterogeneity-aware, goodput-optimized. 2023 , pages =
2023
-
[6]
Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI) , year =
Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning , author =. Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI) , year =
-
[7]
Xue, Chunyu and Pan, Yi and Cui, Weihao and Chen, Quan and Zhang, Shulai and He, Bingsheng and Guo, Minyi , journal =
-
[8]
Deadline-Aware Online Scheduling for
Kong, Linggao and Xu, Yuedong and Jiao, Lei and Xu, Chuan , journal =. Deadline-Aware Online Scheduling for
-
[9]
Advances in Neural Information Processing Systems , volume =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
Proceedings of the 40th International Conference on Machine Learning , pages =
Scaling Laws for Reward Model Overoptimization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
2023
-
[11]
Advances in Neural Information Processing Systems , volume =
Learning to Summarize from Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =
-
[13]
2024 , pages =
Choudhury, Arnab and Wang, Yang and Pelkonen, Tuomas and Srinivasan, Kutta and Jain, Abha and Lin, Shenghao and David, Delia and Soleimanifard, Siavash and Chen, Michael and Yadav, Abhishek and Tijoriwala, Ritesh and Samoylov, Denis and Tang, Chunqiang , booktitle =. 2024 , pages =
2024
-
[14]
Parcae: Proactive, Liveput-Optimized
Duan, Jiangfei and Song, Ziang and Miao, Xupeng and Xi, Xiaoli and Lin, Dahua and Xu, Harry and Zhang, Minjia and Jia, Zhihao , booktitle =. Parcae: Proactive, Liveput-Optimized. 2024 , pages =
2024
-
[15]
and Stoica, Ion , booktitle =
Sheng, Ying and Cao, Shiyi and Li, Dacheng and Hooper, Coleman and Lee, Nicholas and Yang, Shuo and Chou, Christopher and Zhu, Banghua and Zheng, Lianmin and Keutzer, Kurt and Gonzalez, Joseph E. and Stoica, Ion , booktitle =
-
[16]
2024 , pages =
Wu, Bingyang and Zhu, Ruidong and Zhang, Zili and Sun, Peng and Liu, Xuanzhe and Jin, Xin , booktitle =. 2024 , pages =
2024
-
[17]
Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms , author =. Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
-
[18]
and Strouse, DJ and Sandholm, Tuomas and Salakhutdinov, Ruslan and Dragan, Anca and McAleer, Stephen , booktitle =
Moskovitz, Ted and Singh, Aaditya K. and Strouse, DJ and Sandholm, Tuomas and Salakhutdinov, Ruslan and Dragan, Anca and McAleer, Stephen , booktitle =. Confronting Reward Model Overoptimization with Constrained
-
[19]
Advances in Neural Information Processing Systems , volume =
Defining and Characterizing Reward Hacking , author =. Advances in Neural Information Processing Systems , volume =
-
[20]
The Tenth International Conference on Learning Representations (ICLR) , year =
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models , author =. The Tenth International Conference on Learning Representations (ICLR) , year =
-
[21]
Proceedings of the 4th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages =
Non-clairvoyant Scheduling , author =. Proceedings of the 4th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages =
-
[22]
Hu, Jian and Tao, Xibin and Peng, Weixun and others , journal =
-
[23]
Neural Networks: Tricks of the Trade , editor =
Early Stopping --- But When? , author =. Neural Networks: Tricks of the Trade , editor =. 1998 , publisher =
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.