When Built-in Thinking Helps and Hurts: Constraint-Level Error Shifts in Instruction Following
Pith reviewed 2026-06-27 16:32 UTC · model grok-4.3
The pith
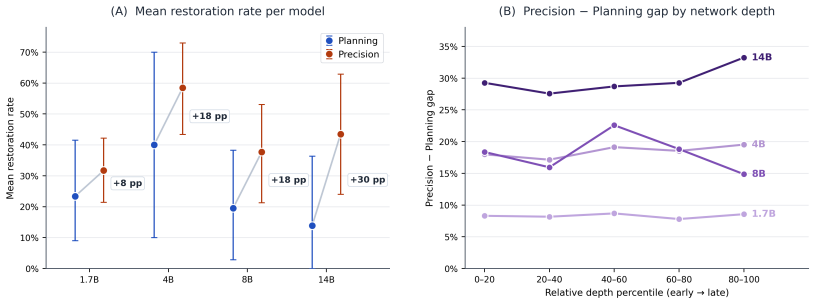
Thinking in large reasoning models improves planning constraints but worsens precision constraints in instruction following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
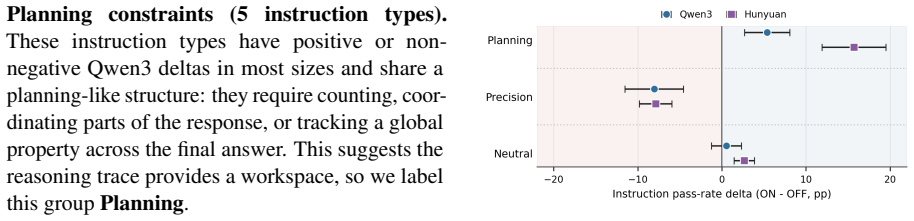
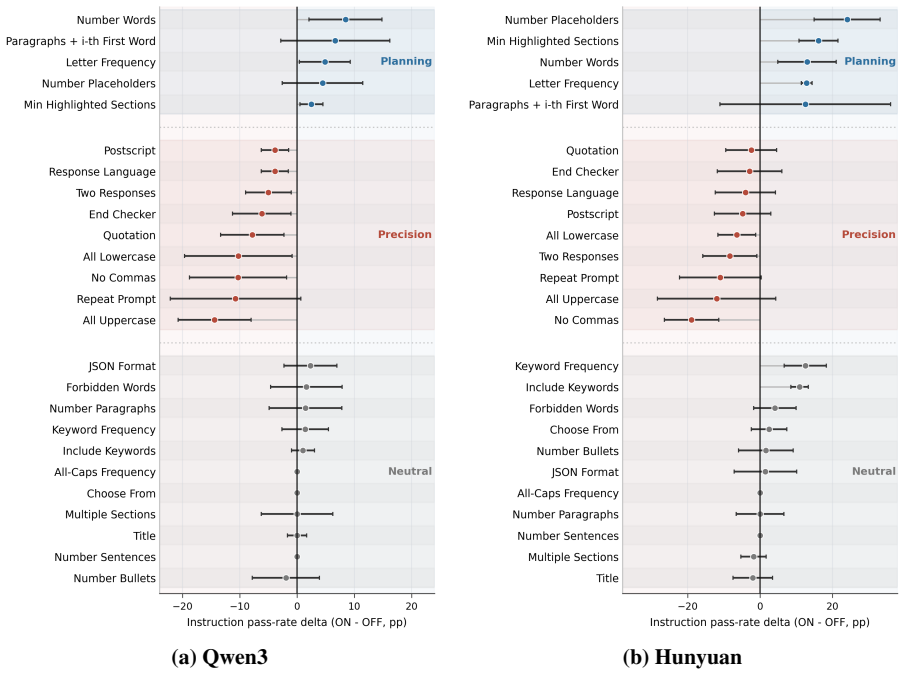
Under a post-hoc Qwen3-derived grouping, constraint types separate into Planning, which improves at the class level under thinking, and Precision, which consistently worsens; the class-level Planning/Precision sign pattern holds directionally for all four Hunyuan models despite Hunyuan's opposite aggregate direction.
What carries the argument
The post-hoc grouping of constraints into Planning (global) and Precision (local) categories that produces opposite class-level sign changes under thinking ON/OFF controls.
If this is right
- Aggregate pass rates change little while 10-20% of individual prompts switch pass/fail status.
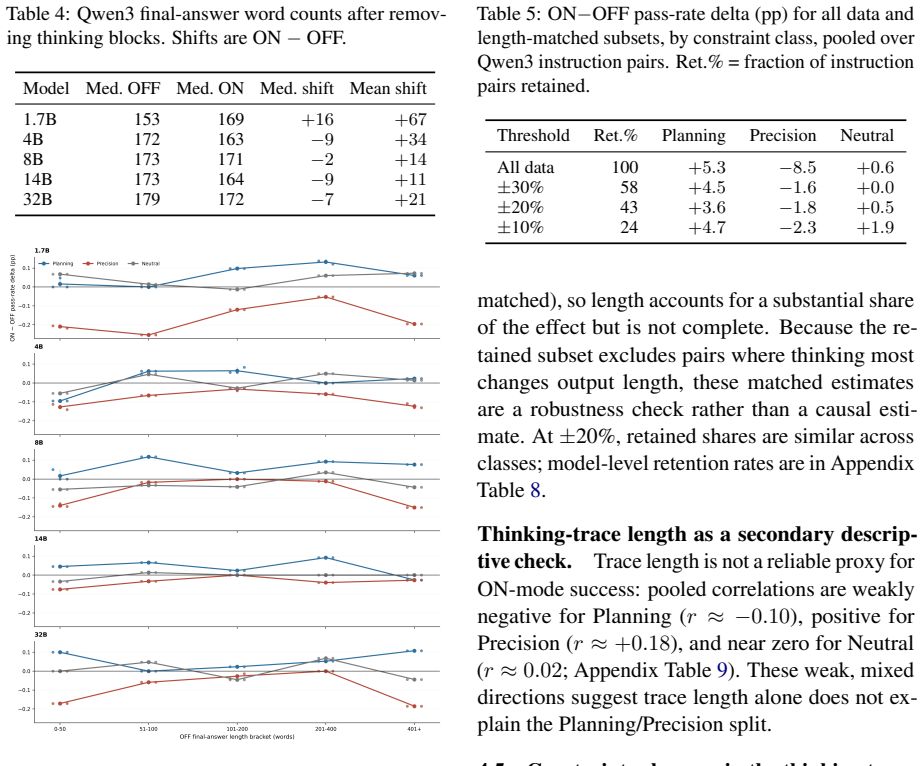
- Matched-length controls shrink but do not remove the Precision performance drop.
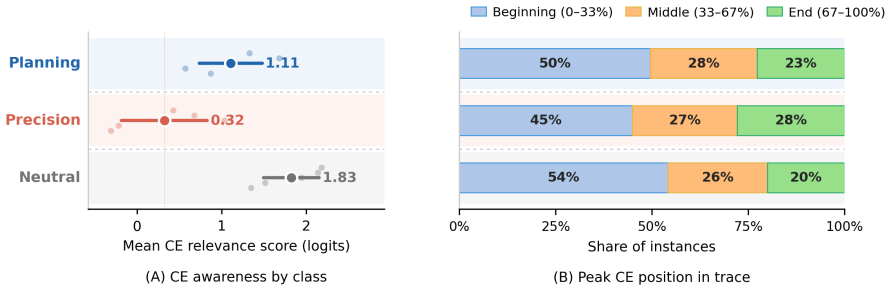
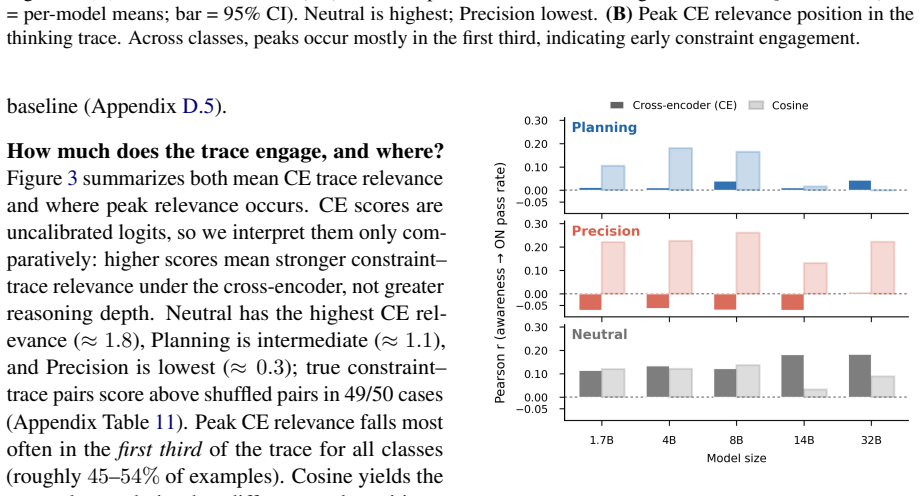
- Relevance-compliance correlations are positive for Neutral constraints, near zero for Planning, and negative for Precision.
- Activation patching restores Precision flip instances more often than Planning flip instances across model sizes.
Where Pith is reading between the lines
- The Planning/Precision split may apply to other benchmarks that mix global and local constraints.
- Future models could route thinking activation selectively by detected constraint type.
- The observed execution gap in Planning traces points to a need for better mechanisms linking internal traces to final compliance.
Load-bearing premise
The post-hoc grouping of constraints into Planning and Precision categories derived from Qwen3 patterns captures a generalizable distinction rather than an artifact of the specific models and data.
What would settle it
Finding that the Planning-improves and Precision-worsens sign pattern fails to appear in a new model family or on a different instruction-following benchmark would falsify the grouping's utility.
Figures

read the original abstract
Large reasoning models (LRMs) often improve math and coding performance, but their effect on instruction following is unclear. We study IFEval with Qwen3 models (1.7B-32B), using same-weights Thinking ON/OFF controls; four Hunyuan models provide directional cross-family support. Aggregate pass-rate changes are small (-0.55 to -3.52 pp), yet 10-20% of prompts switch between pass and fail across modes, suggesting that thinking changes the pattern of errors--some prompts improve while others worsen--rather than uniformly degrading performance. Under a post-hoc Qwen3-derived grouping, constraint types separate into Planning (global counting, structure, coordination), which improves at the class level under thinking, and Precision (exact local form), which consistently worsens; the class-level Planning/Precision sign pattern holds directionally for all four Hunyuan models despite Hunyuan's opposite aggregate direction. Thinking also changes final-answer length; matched-length analyses substantially reduce the Precision drop, but a residual penalty remains. Analyzing thinking traces with a cross-encoder relevance metric reveals three patterns: Neutral shows a positive relevance-compliance link (r approximately 0.15); Planning shows near-zero predictive correlation (r approximately 0.02) despite measurable trace engagement, consistent with an execution gap between CE-measured trace relevance and final-answer compliance; Precision shows a small negative correlation (r approximately -0.05), with failing instances having higher mean relevance than passing ones. Activation patching across four model sizes (1.7B-14B) shows that Precision flip instances are more often restored than Planning flip instances (32-58% vs. 14-40% mean layer-restoration), with the largest gap at 14B (about 30 pp).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the effects of built-in thinking (ON/OFF) on instruction following using IFEval with Qwen3 models (1.7B–32B) under same-weights controls and four Hunyuan models for cross-family directional support. Aggregate pass-rate shifts are small, but 10–20% of prompts flip pass/fail status. A post-hoc Qwen3-derived grouping partitions constraints into Planning (global counting/structure/coordination; class-level improvement under thinking) and Precision (exact local form; consistent worsening). The Planning/Precision sign pattern holds directionally in Hunyuan despite its opposite aggregate trend. Additional results cover matched-length analyses (reducing but not eliminating the Precision penalty), cross-encoder relevance metrics on thinking traces (neutral r≈0.15, planning r≈0.02, precision r≈−0.05), and activation patching (higher restoration rates for Precision flips, 32–58% vs. 14–40%).
Significance. If the post-hoc grouping is shown to be robust and generalizable, the work would provide useful evidence that thinking modes produce constraint-type-specific error shifts rather than uniform degradation, with implications for LRM deployment on instruction-following tasks. Strengths include same-weights ON/OFF controls, multi-family directional replication, matched-length controls, trace relevance analysis, and activation patching across four sizes; these elements supply both behavioral patterns and initial mechanistic observations.
major comments (1)
- [Section describing the post-hoc Qwen3-derived Planning/Precision grouping] The central claim that constraint types separate into Planning (improves) and Precision (worsens) with a cross-family sign pattern rests on a post-hoc grouping derived from observed Qwen3 performance patterns. Because the categories are constructed from the discovery model's error distribution, separation on Qwen3 is guaranteed by construction; the only external support is directional consistency in Hunyuan. The manuscript provides no pre-specified taxonomy, inter-annotator agreement statistics, or hold-out constraint validation that would demonstrate the distinction is model-independent rather than an artifact of Qwen3's particular error distribution. This issue is load-bearing for the abstract's claim of a stable class-level pattern across families.
minor comments (2)
- [Results on matched-length analyses] The matched-length analysis is described as substantially reducing the Precision drop with a residual penalty remaining; quantitative effect sizes, confidence intervals, and the exact matching procedure should be reported in a table or appendix to allow readers to assess the magnitude of the residual effect.
- [Thinking-trace relevance analysis] The relevance-compliance correlations (r ≈ 0.15, 0.02, −0.05) are reported without p-values, confidence intervals, or sample sizes per category; adding these would clarify whether the near-zero planning correlation is statistically distinguishable from the others.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The primary concern is the post-hoc derivation of the Planning/Precision grouping and its implications for the cross-family claim. We address this below.
read point-by-point responses
-
Referee: [Section describing the post-hoc Qwen3-derived Planning/Precision grouping] The central claim that constraint types separate into Planning (improves) and Precision (worsens) with a cross-family sign pattern rests on a post-hoc grouping derived from observed Qwen3 performance patterns. Because the categories are constructed from the discovery model's error distribution, separation on Qwen3 is guaranteed by construction; the only external support is directional consistency in Hunyuan. The manuscript provides no pre-specified taxonomy, inter-annotator agreement statistics, or hold-out constraint validation that would demonstrate the distinction is model-independent rather than an artifact of Qwen3's particular error distribution. This issue is load-bearing for the abstract's claim of a stable class-level pattern across families.
Authors: We agree that the grouping is post-hoc and derived from Qwen3 error patterns, so class-level separation on Qwen3 is guaranteed by construction; the manuscript already describes the grouping with the qualifier 'post-hoc Qwen3-derived'. The only cross-family evidence is the directional sign pattern (Planning improves, Precision worsens) observed in all four Hunyuan models despite their opposite aggregate trend. No pre-specified taxonomy, inter-annotator agreement, or hold-out validation is provided because the categories emerged from the data rather than being defined in advance. This is a genuine limitation for claims of model-independence. In revision we will (a) qualify the abstract and discussion to present the result as an observed Qwen3 pattern with directional replication in Hunyuan rather than a stable model-independent taxonomy, and (b) expand the limitations section to note the post-hoc origin and the absence of a priori validation. We will not add new experiments or re-label the study as pre-specified. revision: partial
Circularity Check
No significant circularity; observational analysis with explicit post-hoc grouping and independent cross-family check.
full rationale
The paper is purely observational and reports empirical patterns on IFEval with same-weights ON/OFF controls. The Planning/Precision grouping is explicitly labeled post-hoc from Qwen3 performance and is used only to summarize observed class-level sign patterns; the directional consistency on four Hunyuan models is presented as an external check rather than a prediction derived from the grouping. No equations, fitted parameters, or derivations are present that reduce any reported quantity to the same data used to define the groups. The work contains no self-citations, uniqueness theorems, or ansatzes that could create load-bearing circularity. This is the normal case of an empirical study whose central claims remain falsifiable against the held-out model family.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
MS MARCO: A human generated MAchine reading COmprehension dataset. arXiv preprint arXiv:1611.09268. Tingchen Fu, Jiawei Gu, Yafu Li, Xiaoye Qu, and Yu Cheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Scaling reasoning, losing control: Evaluating instruction following in large reasoning models.arXiv preprint arXiv:2505.14810. Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang
-
[3]
Yongchan Kwon, Shang Zhu, Federico Bianchi, Kait- lyn Zhou, and James Zou
Can LLMs sim- ulate personas with reversed performance? A sys- tematic investigation for counterfactual instruction following in math reasoning context.arXiv preprint arXiv:2504.06460. Yongchan Kwon, Shang Zhu, Federico Bianchi, Kait- lyn Zhou, and James Zou
-
[4]
ReasonIF: Large reasoning models fail to follow instructions during reasoning.arXiv preprint arXiv:2510.15211. Xiaomin Li, Zhou Yu, Zhiwei Zhang, Xupeng Chen, Ziji Zhang, Yingying Zhuang, Narayanan Sadagopan, and Anurag Beniwal
-
[5]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
When thinking fails: The pitfalls of reasoning for instruction-following in LLMs.arXiv preprint arXiv:2505.11423. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
-
[6]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114. Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 13025– 13048, Bangkok, Thailand
InFoBench: Evaluating instruction following ability in large lan- guage models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13025– 13048, Bangkok, Thailand. Association for Compu- tational Linguistics. Yulei Qin, Gang Li, Zongyi Li, Zihan Xu, Yuchen Shi, Zhekai Lin, Xiao Cui, Ke Li, and Xing Sun
2024
-
[8]
Nils Reimers and Iryna Gurevych
Incentivizing reasoning for advanced instruction- following of large language models.arXiv preprint arXiv:2506.01413. Nils Reimers and Iryna Gurevych
-
[9]
Sentence- BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Process- ing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992. As- sociation for Computational Linguistics. Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jian...
2019
-
[10]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Instruction-Following Evaluation for Large Language Models
Instruction-following evalu- ation for large language models.arXiv preprint arXiv:2311.07911. A Constraint Classification Table 7 lists the full instruction-type classifica- tion used in the paper. Classes are assigned from Qwen3 only: the empirical signal records whether the ON−OFF instruction-level pass-rate pattern is positive/near-zero with planning s...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Word count: 300,
Verdict: Execution gap.The trace explic- itly plans for two 150-word poems so the final answer reaches at least 300 words. The completed output even claims “Word count: 300,” but the final answer contains only247 words under the checker, so the Number Words constraint fails. Example 2 Qwen3-4B | Letter Frequency (i <6) | CE = 3.13 Prompt: Create a rubric ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.