CLIF: Concept-Level Influence Functions for Transparent Bottleneck Models
Pith reviewed 2026-05-20 06:17 UTC · model grok-4.3
The pith
Influence functions applied to concept bottleneck models identify critical samples and concepts for model predictions and allow corrections by adjustment without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extending influence functions to the concept representations inside transparent bottleneck architectures allows quantification of the contribution of specific training samples and bottleneck concepts to any given prediction, with the result that targeted edits to the most influential samples or concepts can be used to debug and correct model behavior.
What carries the argument
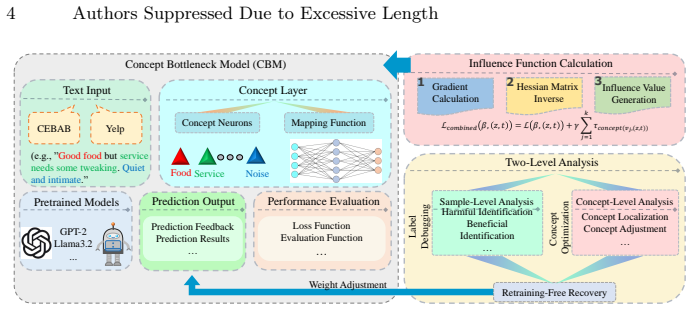
Concept-level influence functions that estimate the effect of upweighting or relabeling individual training points or modifying concept activations on the model's output.
If this is right
- Model performance can be restored to baseline by adjusting the most influential training samples identified by the method.
- Key concepts driving predictions in the bottleneck can be identified and their modification leads to observable changes in model outputs.
- Efficient data debugging becomes possible without the need for full model retraining.
- Interpretability is enhanced at both instance and concept levels for high-stakes NLP applications.
Where Pith is reading between the lines
- Similar influence-based debugging could be tested on other types of interpretable models beyond bottleneck architectures.
- The approach might support the creation of automated pipelines for cleaning training data in deployed systems.
- Validation on whether influence scores align with human annotations of important concepts would strengthen the method's practical value.
Load-bearing premise
The influence scores accurately measure the causal contribution of particular samples and concepts to the predictions rather than merely reflecting correlations.
What would settle it
An experiment that adjusts the labels or weights of the samples ranked highest by influence and checks whether performance on a held-out test set returns to the original baseline level; failure to restore performance would falsify the claim.
Figures
read the original abstract
In recent years, the black-box nature of deep learning models has limited their application in high-stakes domains such as medical diagnosis and finance, where interpretability is essential. To address this, we propose a novel approach using influence functions to enhance interpretability in NLP models at both the sample and concept levels. Experiments on CEBaB and Yelp datasets show that influence functions effectively identify the most impactful training samples, both helpful and harmful, on model predictions. By adjusting the labels and weights of these samples, we demonstrate that model performance can be restored to baseline levels without retraining, confirming the value of influence functions for efficient data debugging. Furthermore, our concept-level analysis identifies key concepts within Concept Bottleneck Models (CBM) that significantly affect predictions. Modifying these concepts alters model behavior observably, providing clear insights into the decision process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLIF, which extends influence functions to provide interpretability for Concept Bottleneck Models (CBMs) at both the training-sample level and the concept level. On the CEBaB and Yelp datasets, the authors claim that influence scores successfully identify the most helpful and harmful training examples for model predictions. They further assert that adjusting the labels or weights of these examples restores model performance to baseline levels without retraining. At the concept level, the method identifies influential concepts whose modification produces observable changes in model behavior.
Significance. If the reported restoration results hold under validated influence approximations, the work supplies a practical, retraining-free method for data debugging and concept-level interpretation in transparent NLP architectures. This could be useful for high-stakes applications. The dual sample- and concept-level analysis extends existing influence-function techniques to CBMs in a potentially useful way, though the strength of the contribution depends on the rigor of the empirical validation.
major comments (2)
- [Experiments] Experiments section: The headline claim that label/weight adjustments on influential samples restore baseline performance rests on the accuracy of the first-order influence-function approximation for these perturbations. No leave-one-out retraining, second-order error bounds, or direct comparison of predicted versus actual performance deltas is reported for the CEBaB or Yelp interventions. This approximation is known to degrade for large changes (e.g., full label flips) or ill-conditioned Hessians in deep models, making the causal restoration result insecure.
- [Abstract and §4] Abstract and §4: The manuscript asserts positive experimental outcomes on CEBaB and Yelp but supplies no quantitative results (accuracy deltas, baselines, statistical tests, or sample sizes). Without these numbers it is impossible to assess whether the influence-based adjustments actually achieve the claimed restoration or merely produce small, statistically insignificant changes.
minor comments (2)
- [Abstract] The abstract would be strengthened by including one or two key quantitative results (e.g., accuracy before/after adjustment) to support the stated claims.
- [Method] Clarify the exact definition of the concept-level influence score (e.g., whether it is computed on the concept predictor or the final classifier) and provide the corresponding equation in the method section.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating where revisions will be made to strengthen the empirical validation and clarity of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline claim that label/weight adjustments on influential samples restore baseline performance rests on the accuracy of the first-order influence-function approximation for these perturbations. No leave-one-out retraining, second-order error bounds, or direct comparison of predicted versus actual performance deltas is reported for the CEBaB or Yelp interventions. This approximation is known to degrade for large changes (e.g., full label flips) or ill-conditioned Hessians in deep models, making the causal restoration result insecure.
Authors: We agree that the first-order approximation carries known limitations for large perturbations and that direct validation would strengthen the causal claims. The original experiments followed the standard efficient application of influence functions from prior literature, but we acknowledge the absence of leave-one-out comparisons or Hessian diagnostics. In the revised manuscript we will add a new validation subsection reporting (i) leave-one-out retraining results on a computationally feasible subset of CEBaB and Yelp examples, (ii) the condition numbers of the relevant Hessians, and (iii) direct numerical comparison between predicted and observed performance deltas. These additions will be presented alongside the existing results without changing the core methodology. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: The manuscript asserts positive experimental outcomes on CEBaB and Yelp but supplies no quantitative results (accuracy deltas, baselines, statistical tests, or sample sizes). Without these numbers it is impossible to assess whether the influence-based adjustments actually achieve the claimed restoration or merely produce small, statistically insignificant changes.
Authors: We accept that the abstract and the high-level summary in §4 currently lack explicit numerical values, which reduces verifiability. The detailed accuracy deltas, baselines, and sample sizes appear in the tables of the experiments section, but we will revise both the abstract and §4 to include the key quantitative findings (e.g., restoration deltas and statistical significance) together with explicit pointers to the tables. Sample sizes and any applicable p-values will also be stated clearly. revision: yes
Circularity Check
No circularity: empirical application of existing influence functions with no self-referential derivations
full rationale
The paper presents an empirical study applying influence functions to identify impactful samples and concepts in Concept Bottleneck Models on CEBaB and Yelp datasets. No equations, derivations, or first-principles claims are advanced that reduce to fitted parameters or self-citations by construction. The central results are experimental demonstrations of label/weight adjustments restoring baseline performance, which rely on external validation rather than internal redefinition. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. The work is self-contained against external benchmarks as a straightforward extension of prior influence-function techniques.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics
Barshan, E., Prince, S., Benos, P.V.: Relatif: An interpretable method for recom- mending influential data in deep learning. In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. pp. 1539–1547 (2020)
work page 2020
-
[2]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Basu, S., Christensen, E.J., Raff, E., Barford, P.: Influence functions in deep learn- ing are fragile. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 3645–3652 (2020)
work page 2020
-
[3]
In: Proceedings of the 40th International Conference on Machine Learning
Basu, S., Raff, E., Barford, P.: Reliable influence functions for deep neural net- works. In: Proceedings of the 40th International Conference on Machine Learning. pp. 1453–1465 (2023)
work page 2023
-
[4]
In: Proceedings of the AAAI Conference on Artificial In- telligence
Chauhan, K., Tiwari, R., Freyberg, J., Shenoy, P., Dvijotham, K.: Interactive con- cept bottleneck models. In: Proceedings of the AAAI Conference on Artificial In- telligence. vol. 37(5), pp. 5948–5955 (2023)
work page 2023
-
[5]
In: International Conference on Machine Learning
Chen, J., Song, M., Weng, Z.: Concept whitening for interpretable image recogni- tion. In: International Conference on Machine Learning. pp. 1626–1635 (2020)
work page 2020
-
[6]
Clark, K., Khandelwal, U., Levy, O., Manning, C.D.: What does bert look at? an analysis of bert’s attention. In: Proceedings of the 2019 ACL Workshop Black- boxNLP: Analyzing and Interpreting Neural Networks for NLP. pp. 276–286 (2019)
work page 2019
-
[7]
Delobelle, P., Winters, T., Berendt, B.: RobBERT: a Dutch RoBERTa-based Language Model. In: Cohn, T., He, Y., Liu, Y. (eds.) Findings of the Associa- tion for Computational Linguistics: EMNLP 2020. pp. 3255–3265. Association for Computational Linguistics, Online (Nov 2020). https://doi.org/10.18653/v1/2020. findings-emnlp.292, https://aclanthology.org/202...
-
[8]
BERT: Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, Volume 1 (Long and Short Paper...
-
[9]
Towards A Rigorous Science of Interpretable Machine Learning
Doshi-Velez,F.,Kim,B.:Towardsarigorousscienceofinterpretablemachinelearn- ing. In: arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Advances in Neural Information Processing Systems35, 23386–23397 (2022)
Havasi, M., Parbhoo, S., Doshi-Velez, F.: Addressing leakage in concept bottle- neck models. Advances in Neural Information Processing Systems35, 23386–23397 (2022)
work page 2022
-
[11]
Jain, S., Wallace, B.C.: Attention is not explanation. arXiv preprint arXiv:1902.10186 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[12]
Kim, B., Wattenberg, M., Gilmer, J.: Interpretability beyond feature attribu- tion: Quantitative testing with concept activation vectors (tcav). arXiv preprint arXiv:1711.11279 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
[Kingma and Ba, 2014] Diederik P Kingma and Jimmy Ba
Kim, E., Jung, D., Park, S., Kim, S., Yoon, S.: Probabilistic concept bottleneck models. arXiv preprint arXiv:2306.01574 (2023)
-
[14]
In: Proceedings of the 34th International Conference on Machine Learning
Koh, P.W., Liang, P.: Understanding black-box predictions via influence functions. In: Proceedings of the 34th International Conference on Machine Learning. pp. 1885–1894 (2017)
work page 2017
-
[15]
In: International Conference on Machine Learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International Conference on Machine Learning. pp. 5338–5347 (2020) CLIF: Concept-Level Influence Functions for Transparent Bottleneck Models 13
work page 2020
-
[16]
In: Advances in Neural Information Processing Systems
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Advances in Neural Information Processing Systems. pp. 4765–4774 (2017)
work page 2017
-
[17]
MetaAI: The llama 3 herd of models (2024), https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
-
[19]
In: The Eleventh International Conference on Learning Representations (2022)
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free concept bottleneck models. In: The Eleventh International Conference on Learning Representations (2022)
work page 2022
-
[20]
Transactions of the Association for Computational Linguis- tics11, 87–103 (2023)
Peruzzo, L., Schioppa, G., Müller, M.: Layer-wise influence functions for analyzing large language models. Transactions of the Association for Computational Linguis- tics11, 87–103 (2023)
work page 2023
-
[21]
Advances in Neural Information Processing Systems34, 10064–10075 (2021)
Pezeshki, M., Guo, Q., Huang, J., Laurent, T., Peyré, G., Lacoste-Julien, S.: Gradient-based data subset selection for efficient deep learning. Advances in Neural Information Processing Systems34, 10064–10075 (2021)
work page 2021
-
[22]
In: Pro- ceedings of the Conference (2019), openAI Blog
Radford, A., et al.: Language models are unsupervised multitask learners. In: Pro- ceedings of the Conference (2019), openAI Blog
work page 2019
-
[23]
Ribeiro, M.T., Singh, S., Guestrin, C.: Why should i trust you?: Explaining the pre- dictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 1135–1144 (2016)
work page 2016
-
[24]
Nature Machine Intelligence1(5), 206–215 (2019)
Rudin, C.: Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence1(5), 206–215 (2019)
work page 2019
-
[25]
Journal of Machine Learning Research23, 1–29 (2022)
Schioppa, G., Peruzzo, L., Müller, M.: Efficient estimation of influence functions in deep learning. Journal of Machine Learning Research23, 1–29 (2022)
work page 2022
-
[26]
IEEE Access9, 11974–12001 (2021)
Stepin, I., Alonso, J.M.S., Pereira-Fariña, M., Alani, H.: A survey of contrastive and counterfactual explanation generation methods for explainable artificial intel- ligence. IEEE Access9, 11974–12001 (2021)
work page 2021
-
[27]
arXiv preprint arXiv:2312.15033 (2023)
Tan, Z., Chen, T., Zhang, Z., Liu, H.: Sparsity-guided holistic explanation for llms with interpretable inference-time intervention. arXiv preprint arXiv:2312.15033 (2023)
-
[28]
arXiv preprint arXiv:2311.05014 (2023)
Tan, Z., Cheng, L., Wang, S., Bo, Y., Li, J., Liu, H.: Interpreting pretrained lan- guage models via concept bottlenecks. arXiv preprint arXiv:2311.05014 (2023)
-
[29]
Team, Q.: Qwen2 technical report. arXiv preprint arXiv:2407.10671 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Team, Q.: Qwen2.5: A party of foundation models (September 2024), https:// qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[31]
In: Harvard Journal of Law & Technology
Wachter, S., Mittelstadt, B., Russell, C.: Counterfactual explanations without opening the black box: Automated decisions and the gdpr. In: Harvard Journal of Law & Technology. vol. 31, pp. 841–887 (2017)
work page 2017
-
[32]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Wang, J., Li, M., Zhang, J., Liu, Y.: Cebab: A large-scale annotated corpus for chinese sentiment analysis. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 1234–1244 (2021)
work page 2021
-
[33]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
Wiegreffe, S., Pinter, Y.: Attention is not not explanation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. pp. 11–20 (2019)
work page 2019
-
[34]
Advances in Neural Information Processing Systems33, 20554–20565 (2020)
Yeh, C.K., Kim, B., Arik, S.K., Li, C.L., Pfister, T., Ravikumar, P.: Completeness- aware concept-based explanations in deep neural networks. Advances in Neural Information Processing Systems33, 20554–20565 (2020)
work page 2020
-
[35]
In: Proceedings of the 2021 International Conference on Data Mining
Yelp: Yelp open dataset: Restaurant reviews and ratings. In: Proceedings of the 2021 International Conference on Data Mining. pp. 1567–1571 (2021)
work page 2021
-
[36]
In: The Eleventh International Conference on Learning Representations (2022)
Yuksekgonul, M., Wang, M., Zou, J.: Post-hoc concept bottleneck models. In: The Eleventh International Conference on Learning Representations (2022)
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.