REVIEW 2 major objections 2 minor 1 cited by
LLM agents over-call tools because their call/no-call mapping includes an activation-independent bias toward calling.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 16:03 UTC pith:U3SDSGQS
load-bearing objection The paper finds a consistent over-calling bias in LLM agents traceable to an activation offset via SAEs, with a steering fix that improves accuracy, but the offset may partly reflect feature selection choices. the 2 major comments →
To Call or Not to Call: Diagnosing Intrinsic Over-Calling Bias in LLM Agents
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across all six models the decision boundary is neutral only when no-call activation exceeds call activation by the estimated offset, confirming the presence of an activation-independent call bias. Applying Adaptive Margin-Calibrated Steering to cancel the offset along the SAE decoder directions mitigates over-calling and raises overall accuracy with negligible loss in call accuracy.
What carries the argument
Sparse Autoencoders that extract behavior-aligned feature bases for the call/no-call decision, reduced to a signed activation margin whose offset is estimated and then cancelled by Adaptive Margin-Calibrated Steering.
Load-bearing premise
The SAE-recovered feature directions are causally aligned with the actual call/no-call decision boundary rather than being an artifact of feature selection.
What would settle it
If Adaptive Margin-Calibrated Steering applied to the diagnosed offset fails to reduce over-calling rates or to improve overall accuracy on the When2Call benchmark, the Intrinsic Bias Hypothesis would be falsified.
If this is right
- The same activation-independent offset appears consistently across models from three different families.
- Cancelling the offset improves overall accuracy while call accuracy remains nearly unchanged.
- Over-calling can be treated as a mechanistic object rather than an empirical observation only.
- The bias correction requires no retraining and works through a closed-form shift along existing SAE directions.
Where Pith is reading between the lines
- The same diagnostic and correction approach could be tested on other agent decisions such as when to stop or when to plan.
- If the offset originates in training data, similar biases may appear in non-agent LLM tasks that involve binary choices.
- Future measurements could check whether the offset size scales with model size or training compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM agents exhibit over-calling on the When2Call benchmark due to an Intrinsic Bias Hypothesis (IBH): an activation-independent call offset in the decision mapping. Using SAEs across six models from three families, the authors recover behavior-aligned call/no-call feature bases, reduce them to a signed activation margin, and directly estimate the offset. They report that models are decision-neutral only when no_call activation outweighs call activation. They then introduce Adaptive Margin-Calibrated Steering (AMCS) to cancel the offset, which mitigates over-calling, raises overall accuracy, and preserves call accuracy. Code is provided.
Significance. If the diagnosed offset proves robust to feature-selection choices and the AMCS intervention is shown to be independent of the SAE fitting process, the work would convert an observed empirical bias into a mechanistic, causally correctable object. The consistency of results across six models and the release of reproducible code are clear strengths. The approach could inform bias diagnosis in other agentic settings.
major comments (2)
- [Methods] Methods (SAE feature selection and margin reduction): The offset is recovered by selecting SAE features via correlation with call labels on When2Call and then computing a signed activation margin. Without reported ablations on alternative selection criteria (e.g., mutual information, activation magnitude), different sparsity levels, or balanced vs. imbalanced training data, it remains possible that the zero-crossing shift is an artifact of the pipeline rather than an intrinsic model property. This directly affects the load-bearing IBH claim.
- [Results] Results (causal steering test and accuracy numbers): The manuscript states that cancelling the offset improves overall accuracy with negligible drop in call accuracy, but provides no details on exact margin calculation, statistical significance tests, or controls for confounding factors in feature selection. These omissions make it difficult to assess whether the reported gains are robust or driven by the same data-dependent correlations used to define the offset.
minor comments (2)
- [Abstract] Abstract: The phrase 'activation-independent call offset' is introduced without a concise mathematical definition; a short equation or explicit formula would clarify the quantity being estimated.
- [Introduction] The When2Call benchmark description would benefit from a brief table summarizing call vs. no-call accuracy for each of the six models to make the empirical phenomenon immediately visible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments on feature selection robustness and result details are well-taken and point to opportunities to strengthen the evidence for the Intrinsic Bias Hypothesis (IBH). We address each major comment below and will revise the manuscript accordingly to improve clarity and demonstrate robustness.
read point-by-point responses
-
Referee: [Methods] Methods (SAE feature selection and margin reduction): The offset is recovered by selecting SAE features via correlation with call labels on When2Call and then computing a signed activation margin. Without reported ablations on alternative selection criteria (e.g., mutual information, activation magnitude), different sparsity levels, or balanced vs. imbalanced training data, it remains possible that the zero-crossing shift is an artifact of the pipeline rather than an intrinsic model property. This directly affects the load-bearing IBH claim.
Authors: We agree that additional validation is needed to confirm the offset is not an artifact of the correlation-based selection. Correlation was chosen because it directly ties features to the behavioral labels in When2Call, but we acknowledge this could introduce pipeline dependence. In the revision we will add ablations using mutual information and activation-magnitude selection, vary SAE sparsity levels, and compare balanced versus imbalanced training sets for feature discovery. These results will be reported in an expanded Methods section and supplementary material, showing that the decision-neutral point (no_call activation outweighing call activation) remains consistent across criteria. revision: yes
-
Referee: [Results] Results (causal steering test and accuracy numbers): The manuscript states that cancelling the offset improves overall accuracy with negligible drop in call accuracy, but provides no details on exact margin calculation, statistical significance tests, or controls for confounding factors in feature selection. These omissions make it difficult to assess whether the reported gains are robust or driven by the same data-dependent correlations used to define the offset.
Authors: We accept that the current presentation lacks sufficient detail for full evaluation of robustness. The revised Results section will include the exact formula for the signed activation margin, report statistical significance (paired t-tests and Wilcoxon tests on accuracy deltas across models and runs), and add a control using a held-out validation split for feature selection before applying AMCS. This separation will show that accuracy gains from offset cancellation are not artifacts of the original selection correlations and that AMCS remains effective as an independent intervention. revision: yes
Circularity Check
Offset estimated from SAE margin on call-labeled data then presented as independent evidence for IBH
specific steps
-
fitted input called prediction
[Abstract]
"Using Sparse Autoencoders (SAEs), we recover behavior-aligned feature bases for the call/no_call decision, reduce them to a signed activation margin, and estimate the offset directly. Across all six models, the model is decision-neutral only when no_call activation outweighs call activation, consistent with IBH."
The signed activation margin and offset are computed from SAE features chosen for correlation with call behavior on the benchmark; the reported neutrality condition (no_call must outweigh call) is therefore the direct numerical result of that estimation, rendering the 'consistent with IBH' statement a restatement of the fitted input rather than a separate verification.
full rationale
The derivation recovers SAE features aligned to call/no-call labels, reduces them to a signed margin, estimates the offset directly from that margin, and reports that decision neutrality occurs only when no_call activation exceeds call activation as confirmation of the Intrinsic Bias Hypothesis. This step is a direct readout of the fitted quantity rather than an independent prediction. The later AMCS causal intervention supplies partial independence, preventing a higher score, but the initial diagnostic claim remains partially constructed from the same feature-selection and reduction pipeline.
Axiom & Free-Parameter Ledger
free parameters (1)
- call offset
axioms (1)
- domain assumption SAE decoder directions align with behaviorally relevant call/no-call features
invented entities (1)
-
Intrinsic Bias Hypothesis (IBH) offset
no independent evidence
read the original abstract
LLM agents exhibit a consistent tendency to over-call, invoking tools even in situations where none is needed. On the When2Call benchmark, six models from three families show high call accuracy but much lower no-call accuracy, leaving overall accuracy in the 55%-70% range. We trace this to an Intrinsic Bias Hypothesis (IBH): the call/no-call decision mapping carries an activation-independent call offset, so the model favors call even at activation parity. Using Sparse Autoencoders (SAEs), we recover behavior-aligned feature bases for the call/no_call decision, reduce them to a signed activation margin, and estimate the offset directly. Across all six models, the model is decision-neutral only when no_call activation outweighs call activation, consistent with IBH. We then causally test IBH with Adaptive Margin-Calibrated Steering (AMCS), a closed-form counter-bias shift along SAE decoder directions. Cancelling the diagnosed offset mitigates over-calling and improves overall accuracy with a negligible drop in call accuracy. Our work recasts over-calling from an empirical phenomenon into a mechanistic object amenable to causal correction. Code is available at https://github.com/SKURA502/agent-sae/.
Figures











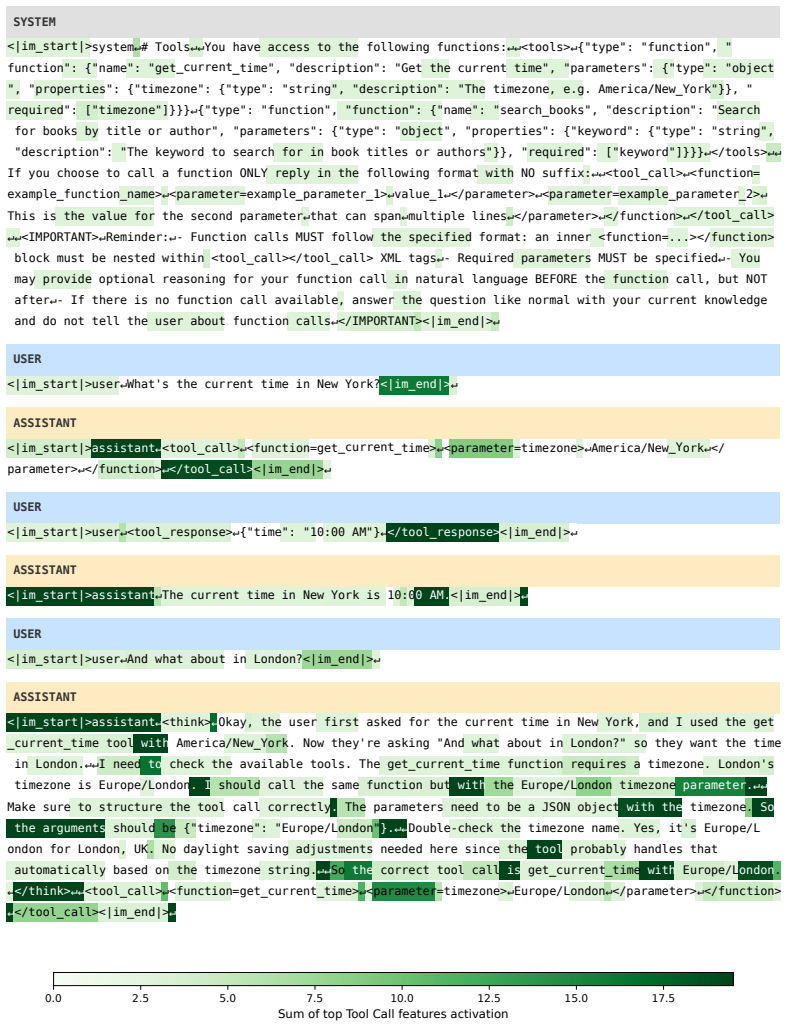

Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize this as the Intrinsic Bias Hypothesis (IBH): over-calling reflects an activation-independent call offset in the decision mapping. ... Pr(ˆdi=1|mi)=σ(βmi + β0), β>0, β0>0.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Adaptive Margin-Calibrated Steering (AMCS), a closed-form counter-bias shift along SAE decoder directions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Do LLMs Know Their Vulnerable Scenarios?
Scenario jailbreaks suppress refusal via internal concept directions; Concept2Scenario attributes those concepts with SAEs and turns them into transferable natural-language attack scenarios.
Reference graph
Works this paper leans on
-
[1]
OpenAI. Openai GPT-5 system card.CoRR, abs/2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Anthropic. Claude opus 4.6 system card. Technical report, Anthropic, February 2026
work page 2026
-
[3]
Google DeepMind. Gemma 4 model card. https://ai.google.dev/gemma/docs/core/ model_card_4, April 2026. Accessed: 2026-04-08
work page 2026
-
[4]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
work page 2026
-
[5]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS, 2023
work page 2023
-
[6]
Toolllm: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world APIs. InICLR. OpenReview.net, 2024
work page 2024
-
[7]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.CoRR, abs/2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
AFlow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. AFlow: Automating agentic workflow generation. InICLR. OpenReview.net, 2025
work page 2025
-
[9]
Gemma Team. Gemma 3 technical report.CoRR, abs/2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mistral AI. Ministral 3.CoRR, abs/2601.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
When2call: When (not) to call tools
Hayley Ross, Ameya Sunil Mahabaleshwarkar, and Yoshi Suhara. When2call: When (not) to call tools. InNAACL (Long Papers), pages 3391–3409. Association for Computational Linguistics, 2025
work page 2025
-
[12]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InICLR. OpenReview.net, 2024
work page 2024
-
[13]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. 2025
work page 2025
-
[14]
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
work page 2024
-
[15]
Ehud Karpas, Omri Abend, Yonatan Berant, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tennenholtz. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR. OpenReview.net, 2023
work page 2023
-
[17]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InICLR. OpenReview.net, 2024. 10
work page 2024
-
[18]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): from tool use to agentic evaluation of large language models. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
work page 2025
-
[19]
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeffrey Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Isaac Bloom, Stella Biderman, Adrià Garriga-Alonso, Arthur Conmy, Neel Nanda, Jessica Rumbelow, Martin Wattenberg, Nandi Schoots, Joseph Miller, William Saunders, Eric J. Michaud, Stephen Casper, Max T...
work page 2025
-
[20]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
work page 2023
-
[21]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.CoRR, abs/2407.14435, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling.CoRR, abs/2101.00027, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR (Poster). OpenReview.net, 2019. 11 A SAE Training Details Table 2: SAE training configuration for each target model. d is the text-backbone residual width, L is the number of transformer blocks, ℓ is the zero-indexed hook block, M= 8d is the SAE dictionary size, andK=⌊d/32⌋is ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.