BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
Pith reviewed 2026-07-01 05:57 UTC · model grok-4.3
The pith
A learned policy selects per-sample block size from prefilling to adapt diffusion speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
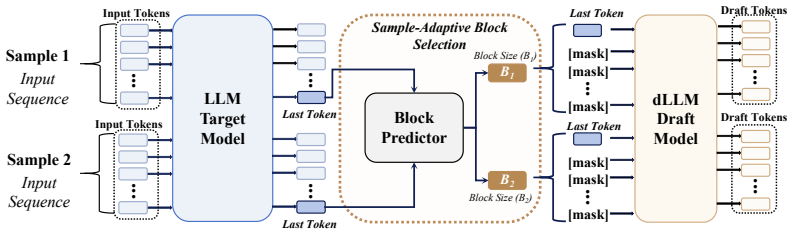
Block size selection is cast as an instance-adaptive policy-learning problem whose solution is a single forward pass on the prefilling representation that yields the per-sample block size for the subsequent diffusion-based speculative steps.
What carries the argument
instance-adaptive decision mechanism that predicts block size from the prefilling representation in one pass
If this is right
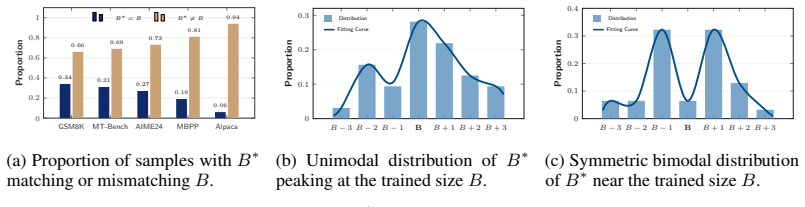
- Optimal block sizes concentrate locally around the training value, shrinking the decision space.
- Prediction occurs only once after prefilling, preserving the original parallelism of diffusion steps.
- The same prefilling representation already computed by the target model supplies the features, adding no extra passes.
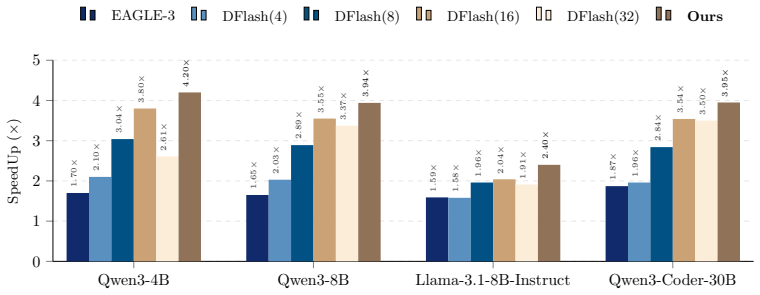
- The method reports 5.92 acceptance length and 4.20× speedup on Qwen3-4B at temperature 1.
Where Pith is reading between the lines
- The same local-structure observation could be tested on non-diffusion speculative methods to see whether block-size adaptation transfers.
- If the policy generalizes across model families, a single trained predictor might serve multiple target models without retraining.
- Combining the adaptive block choice with orthogonal speed-ups such as quantization or early-exit would be a direct next measurement.
Load-bearing premise
The optimal block size for any given input can be recovered reliably from the prefilling representation alone.
What would settle it
Measure acceptance length on held-out samples when the policy is replaced by a random or constant block size; if the gap disappears, the adaptive prediction is not carrying the gain.
Figures

read the original abstract
Speculative decoding accelerates inference by using a lightweight draft model to generate candidate tokens in parallel, and are then verified by the target model, enabling lossless acceleration. Recently, diffusion-based speculative decoding further improves parallelism by generating multiple tokens per forward pass via block-level diffusion, achieving state-of-the-art (SOTA) performance. However, existing methods adopt a fixed inference block size and assume a uniform optimal decoding strategy across all inputs. In this paper, we show that this assumption is suboptimal, as the optimal block size varies across samples and plays a critical role in speculative decoding performance. Moreover, these values exhibit a clear local structure, concentrating around the training block size, which reduces the problem to a low-dimensional and structured decision space. Based on these insights, we propose BlockPilot, a sample-adaptive policy that predicts the optimal block size from the prefilling representation. Specifically, we formulate block size selection as a lightweight policy learning problem and propose an instance-adaptive decision mechanism that predicts the optimal block size based on the representation of the prefilling stage. The prediction is performed only once after prefilling, allowing for seamless integration. Extensive experiments demonstrate that our method is plug-and-play, introduces minimal overhead, and consistently improves efficiency, achieving an acceptance length of 5.92 and a 4.20$\times$ speedup on Qwen3-4B under temperature $T=1$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BlockPilot, an instance-adaptive policy for diffusion-based speculative decoding. It observes that optimal block sizes vary across samples yet exhibit local structure around the training block size, reducing the decision to a low-dimensional prediction problem. The method trains a lightweight policy to select the block size once from the prefilling-stage representation and applies the fixed choice for the entire generation, claiming plug-and-play integration, minimal overhead, an acceptance length of 5.92, and 4.20× speedup on Qwen3-4B at temperature 1.
Significance. If the empirical gains are robustly supported and the per-sample constancy assumption holds, the approach offers a low-overhead way to improve existing diffusion speculative decoders without retraining the draft or target models.
major comments (2)
- [Method and Experiments sections] The central adaptive benefit rests on the claim that optimal block size is stable within each sample. The manuscript should include a direct measurement of intra-sequence variation in optimal block size (e.g., token-by-token oracle block sizes) to test whether a single post-prefill prediction captures the structure or merely approximates a fixed-block baseline; without this, the reported gains may not exceed what a well-tuned static block size already achieves.
- [§3 (Policy Learning)] The abstract and method description state that the policy is trained on observed data, yet no information is supplied on the training procedure, loss, data exclusion rules, or how the policy avoids simply memorizing the training block size distribution. This information is required to assess whether the 4.20× speedup is an artifact of the fitting process rather than a genuine generalization.
minor comments (1)
- Clarify the exact architecture and input features of the policy network; the current description leaves the dimensionality and training data size unspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Method and Experiments sections] The central adaptive benefit rests on the claim that optimal block size is stable within each sample. The manuscript should include a direct measurement of intra-sequence variation in optimal block size (e.g., token-by-token oracle block sizes) to test whether a single post-prefill prediction captures the structure or merely approximates a fixed-block baseline; without this, the reported gains may not exceed what a well-tuned static block size already achieves.
Authors: We appreciate the referee's emphasis on validating the intra-sequence stability assumption. Our analysis in the manuscript shows that optimal block sizes vary across samples yet concentrate locally around the training block size, which motivates the single post-prefill prediction. To directly test whether this captures per-sample structure or approximates a static baseline, we will add a new experiment in the revised manuscript. This will compute token-by-token oracle block sizes on held-out sequences and report intra-sequence variation statistics (e.g., variance and range within each generation). The results will clarify the extent of stability and whether the reported gains exceed those of a well-tuned fixed block size. revision: yes
-
Referee: [§3 (Policy Learning)] The abstract and method description state that the policy is trained on observed data, yet no information is supplied on the training procedure, loss, data exclusion rules, or how the policy avoids simply memorizing the training block size distribution. This information is required to assess whether the 4.20× speedup is an artifact of the fitting process rather than a genuine generalization.
Authors: We acknowledge the omission of training details in the submitted version. In the revised manuscript, we will expand §3 with the following: the policy (a lightweight 2-layer MLP) is trained via supervised classification on oracle-derived optimal block size labels collected from a separate training prompt set; the loss is cross-entropy with label smoothing; data exclusion ensures no overlap with validation or test sets; and memorization is mitigated by model capacity limits, dropout (p=0.1), L2 regularization, and early stopping on a held-out validation split. These additions will demonstrate that the policy learns generalizable patterns rather than fitting the training distribution. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical policy learning
full rationale
The paper observes (empirically) that optimal block sizes vary across samples and cluster locally around training values, then trains a lightweight policy to predict block size once from the prefilling representation. This is standard supervised learning on data-derived targets; the reported acceptance length and speedup are measured outcomes, not quantities forced by definition or self-citation. No load-bearing step reduces by construction to its own inputs, and no self-citation chains or uniqueness theorems are invoked. The approach remains falsifiable on external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The prefilling representation contains sufficient information to predict the optimal block size for a given input
Reference graph
Works this paper leans on
-
[1]
Large language models: a survey of their development, capabilities, and applications.Knowledge and Information Systems, 67(3):2967–3022, 2025
Yadagiri Annepaka and Partha Pakray. Large language models: a survey of their development, capabilities, and applications.Knowledge and Information Systems, 67(3):2967–3022, 2025
2025
-
[2]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models, 2025. URL https://arxiv.org/abs/2503. 09573
2025
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Smooth Loss Functions for Deep Top-k Classification
Leonard Berrada, Andrew Zisserman, and M Pawan Kumar. Smooth loss functions for deep top-k classification.arXiv preprint arXiv:1802.07595, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads,
-
[6]
URLhttps://arxiv.org/abs/2401.10774
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
DFlash: Block Diffusion for Flash Speculative Decoding
Jian Chen, Yesheng Liang, and Zhijian Liu. Dflash: Block diffusion for flash speculative decoding.arXiv preprint arXiv:2602.06036, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pages 370–387. Springer, 2024
2024
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
SDAR: A synergistic diffusion- autoregression paradigm for scalable sequence generation, 2025
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. Sdar: A synergistic diffusion- autoregression paradigm for scalable sequence generation, 2025. URL https://arxiv.org/ abs/2510.06303
-
[12]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
2023
-
[13]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects.Authorea preprints, 1(3):1–26, 2023
Muhammad Usman Hadi, Rizwan Qureshi, Abbas Shah, Muhammad Irfan, Anas Zafar, Muham- mad Bilal Shaikh, Naveed Akhtar, Jia Wu, Seyedali Mirjalili, et al. Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects.Authorea preprints, 1(3):1–26, 2023
2023
-
[16]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. 10
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Speed: Speculative pipelined execution for efficient decoding
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Hasan Genc, Kurt Keutzer, Amir Gholami, and Yakun Sophia Shao. Speed: Speculative pipelined execution for efficient decoding. InEnhancing LLM Performance: Efficacy, Fine-Tuning, and Inference Techniques, pages 19–32. Springer, 2025
2025
-
[18]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
The winograd schema challenge.KR, 2012(13th):3, 2012
Hector J Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge.KR, 2012(13th):3, 2012
2012
-
[20]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, pages 19274–19286, 2023
2023
-
[21]
DiffuSpec: Unlocking diffusion language models for speculative decoding, 2025
Guanghao Li, Zhihui Fu, Min Fang, Qibin Zhao, Ming Tang, Chun Yuan, and Jun Wang. Diffuspec: Unlocking diffusion language models for speculative decoding, 2025. URL https: //arxiv.org/abs/2510.02358
-
[22]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees, 2024. URL https://arxiv.org/abs/2406.16858
-
[23]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025. URL https://arxiv.org/ abs/2503.01840
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty, 2025. URLhttps://arxiv.org/abs/2401.15077
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[26]
Tidar: Think in diffusion, talk in autoregression, 2025
Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, and Pavlo Molchanov. Tidar: Think in diffusion, talk in autoregression, 2025. URL https://arxiv.org/abs/2511.08923
-
[27]
American Invitational Mathematics Examination - AIME, 2025
MAA. American Invitational Mathematics Examination - AIME, 2025. URL https://maa. org/math-competitions/american-invitational-mathematics-examination-aime
2025
-
[28]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models, 2025. URL https: //arxiv.org/abs/2502.09992
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Lorenzo Papa, Paolo Russo, Irene Amerini, and Luping Zhou. A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking.IEEE transactions on pattern analysis and machine intelligence, 46(12):7682–7700, 2024
2024
-
[30]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[31]
Choice of plausible alterna- tives: An evaluation of commonsense causal reasoning
Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S Gordon. Choice of plausible alterna- tives: An evaluation of commonsense causal reasoning. InAAAI spring symposium: logical formalizations of commonsense reasoning, pages 90–95, 2011
2011
-
[32]
Your llm knows the future: Uncovering its multi-token prediction potential, 2025
Mohammad Samragh, Arnav Kundu, David Harrison, Kumari Nishu, Devang Naik, Minsik Cho, and Mehrdad Farajtabar. Your llm knows the future: Uncovering its multi-token prediction potential, 2025. URLhttps://arxiv.org/abs/2507.11851
-
[33]
Christopher, Thomas Hartvigsen, and Ferdinando Fioretto
Jameson Sandler, Jacob K. Christopher, Thomas Hartvigsen, and Ferdinando Fioretto. Specdiff- 2: Scaling diffusion drafter alignment for faster speculative decoding, 2025. URL https: //arxiv.org/abs/2511.00606. 11
-
[34]
Accelerating transformer inference for translation via parallel decoding
Andrea Santilli, Silvio Severino, Emilian Postolache, Valentino Maiorca, Michele Mancusi, Riccardo Marin, and Emanuele Rodolà. Accelerating transformer inference for translation via parallel decoding. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12336–12355, 2023
2023
-
[35]
Blockwise parallel decoding for deep autoregressive models.Advances in Neural Information Processing Systems, 31, 2018
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[36]
Efficient transformers: A survey
Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 55(6):1–28, 2022
2022
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
arXiv preprint arXiv:2312.03863 , volume=
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, et al. Efficient large language models: A survey.arXiv preprint arXiv:2312.03863, 2023
-
[39]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf. Transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2020
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[40]
Fast-dllm v2: Efficient block-diffusion llm,
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dllm v2: Efficient block-diffusion llm,
- [41]
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. 12 A Theoretical Analysis of Sample-Adaptive Block Size Selection A.1 Acceptance Length as a...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.