Deployment-Side Adaptiveness in Multi-Horizon Volatility Forecasting
Pith reviewed 2026-06-29 04:40 UTC · model grok-4.3
The pith
Varying the inference-time rollout rule for a trained MIMO volatility forecaster often improves accuracy over standard deployment, and validation can select low-cost policies that outperform the default.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
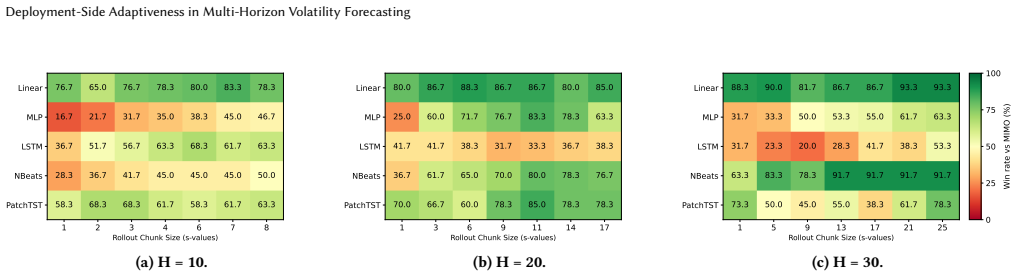
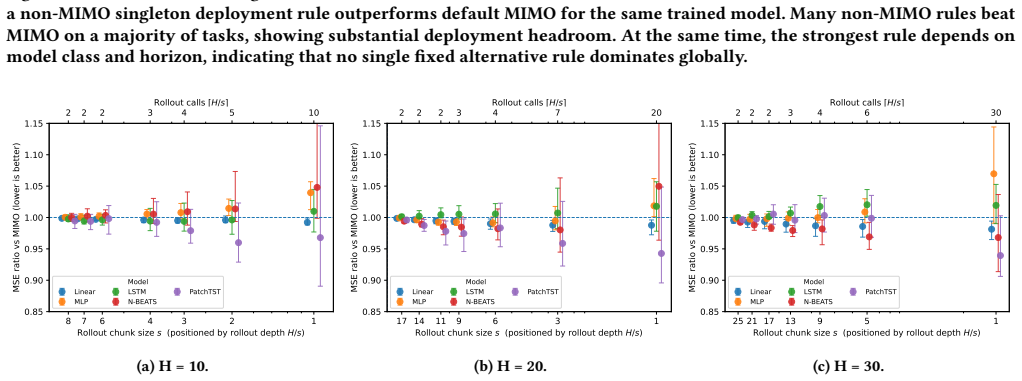
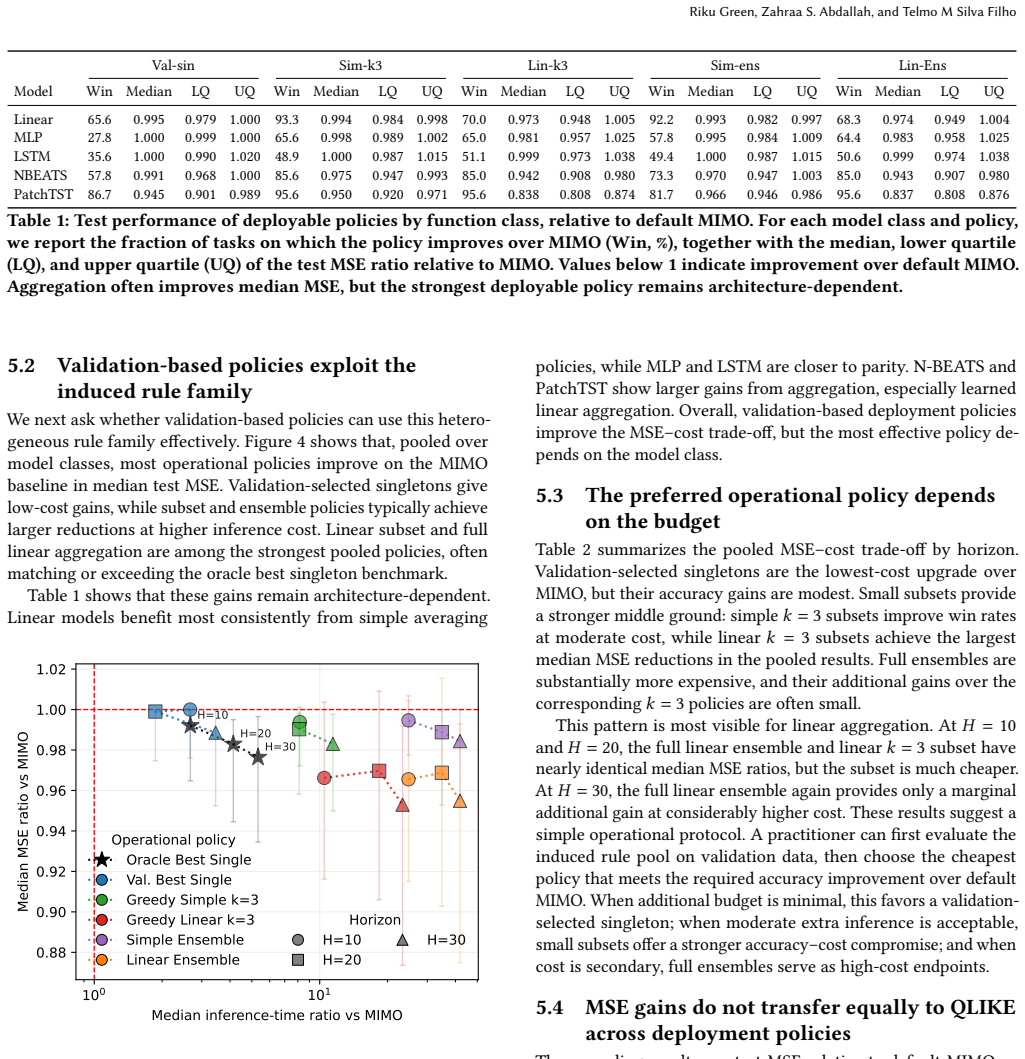
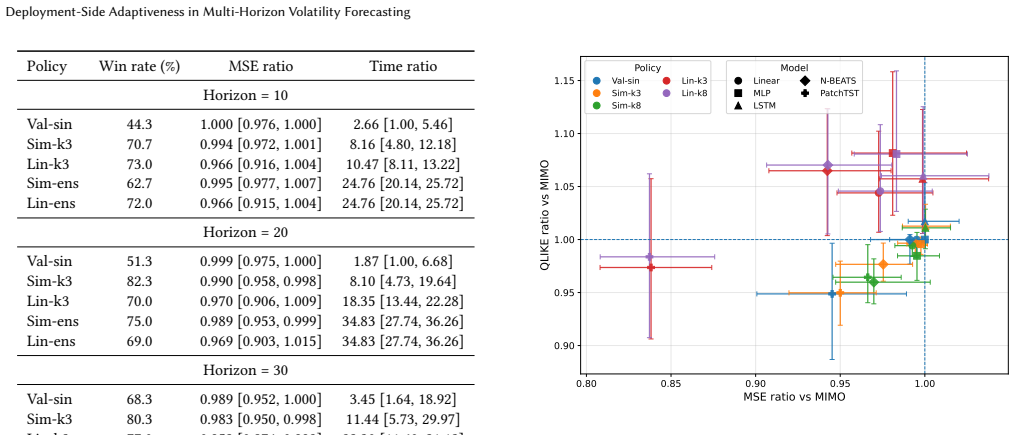
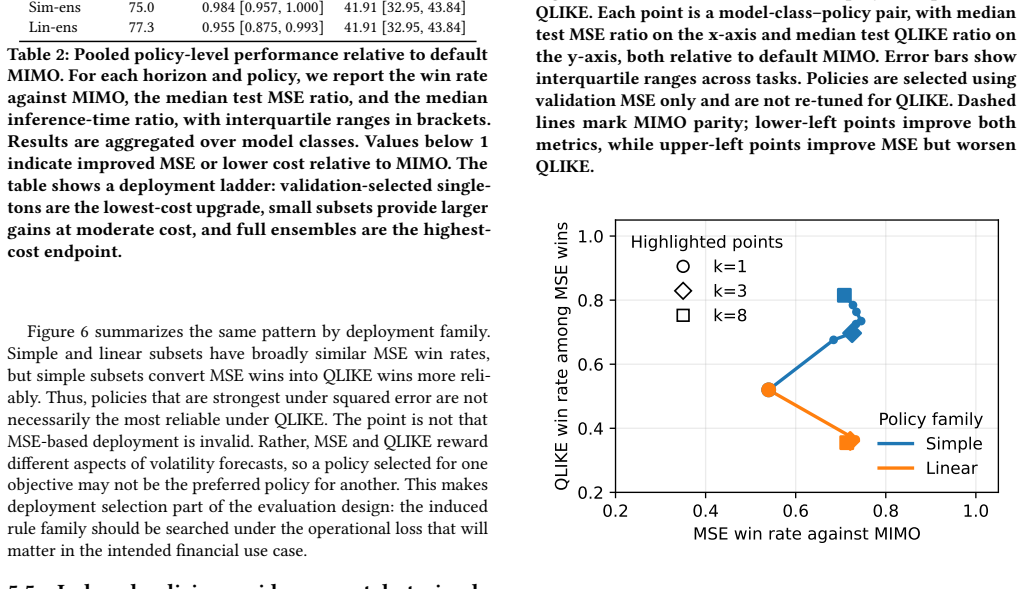
By changing the inference-time rollout rule, the same trained MIMO forecaster induces a family of forecasts; validation-selected singletons improve over default MIMO at low cost, while small rule subsets recover much of the benefit of larger ensembles at substantially lower inference cost. Non-default rollout rules often improve over standard MIMO across the series, yet policy rankings are metric-sensitive and do not transfer uniformly from MSE to QLIKE.
What carries the argument
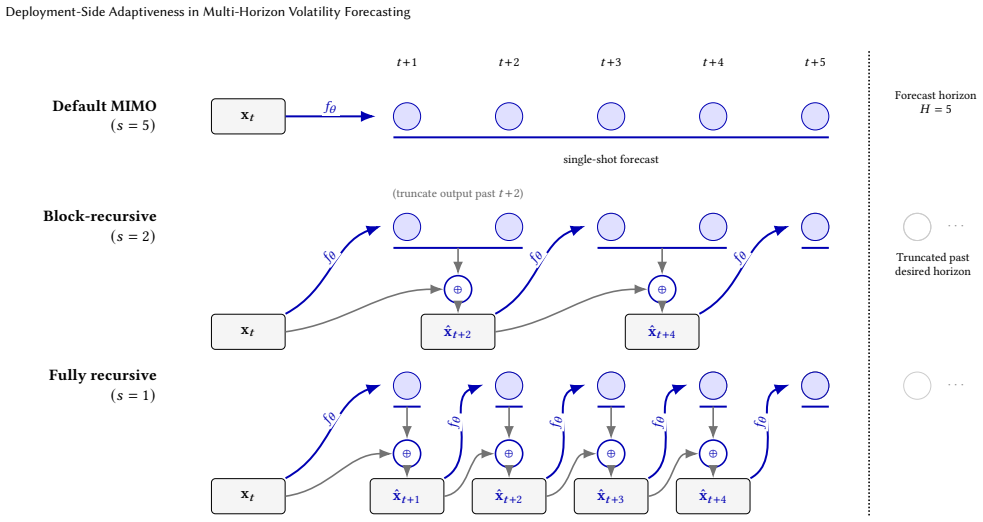
The family of forecasts induced by different inference-time rollout rules on a trained multi-output (MIMO) model; it turns one trained network into multiple deployable predictors that can be chosen by validation.
If this is right
- Non-default rollout rules improve performance over standard MIMO deployment on the 20 volatility series.
- Validation-selected singletons deliver low-cost accuracy gains over the default.
- Small rule subsets recover most ensemble benefits while cutting inference cost.
- Optimal policies change when the loss switches from MSE to QLIKE.
- Volatility forecasters need evaluation on both architecture and deployment policy.
Where Pith is reading between the lines
- The same rollout-family idea could be tested on multi-horizon tasks outside finance, such as energy demand or traffic.
- Dynamic selection of rules based on recent market regime might further reduce the gap to full ensembles.
- The approach raises the question of whether deployment adaptiveness appears in other multi-output time-series models beyond volatility.
- Live deployment on streaming market data would test whether the validation gains survive distribution shifts.
Load-bearing premise
The validation set used to select the rollout policy is representative of future unseen data, and observed performance differences arise from the rules themselves rather than from overfitting to the validation period.
What would settle it
Check whether a rollout policy chosen on the validation set still outperforms the default MIMO rule on a later test window that was never seen during policy selection.
Figures
read the original abstract
In financial forecasting, predictive performance depends not only on which model is trained, but also on how the trained model is deployed. We study this issue in multi-horizon volatility forecasting. Our starting point is that a trained multi-output (MIMO) forecaster does not define a single deployable predictor: by changing the inference-time rollout rule, the same trained model induces a family of forecasts with different accuracy and cost profiles. Across 20 stock-volatility series, three forecast horizons, and architectures ranging from linear models to PatchTST, we find that non-default rollout rules often improve over standard MIMO deployment. However, the best fixed rule varies substantially across architectures and horizons, making any single static replacement unreliable. We therefore evaluate validation-based deployment policies over the induced rule family. Under the primary MSE objective, validation-selected singletons provide a low-cost improvement over default MIMO, while small rule subsets recover much of the benefit of larger ensembles at substantially lower inference cost. We also find that policy rankings are metric-sensitive: MSE-selected policies do not transfer uniformly to QLIKE, a finance-standard volatility loss. These results show that inference-time deployment is a meaningful source of adaptiveness in financial forecasting, and that trained volatility forecasters should be evaluated not only by their architecture, but also by their deployment policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a trained MIMO forecaster in multi-horizon volatility prediction induces a family of deployable predictors via different inference-time rollout rules; across 20 stock-volatility series, three horizons, and architectures from linear models to PatchTST, non-default rules often outperform standard MIMO, validation-selected singletons yield low-cost gains over default MIMO, and small rule subsets recover much of the benefit of larger ensembles at lower inference cost, though policy rankings are sensitive to the loss (MSE vs. QLIKE).
Significance. If the central empirical patterns hold after addressing validation representativeness, the work establishes deployment policy as a distinct, low-cost source of adaptiveness in financial forecasting that complements model architecture choices. The breadth of the evaluation (20 series, multiple horizons and architectures, held-out test comparisons) and the efficiency finding on small rule subsets are strengths that would make the result practically relevant for volatility model deployment.
major comments (2)
- [Abstract and validation-based deployment policies section] The headline result on validation-selected singletons and rule subsets improving over default MIMO (abstract and results) rests on the assumption that performance differences are driven by the rollout rules and that the validation window is representative of future data. In non-stationary volatility series, a single fixed validation period risks selecting rules that exploit transient regime characteristics; the manuscript does not report multiple rolling validation windows, statistical tests for distribution shift between validation and test sets, or ablation on stability of rule rankings across windows.
- [Empirical evaluation sections] The reported consistent empirical patterns across series, horizons, and architectures lack accompanying error bars, statistical significance tests, or exact details on data splits and train/validation/test partitioning (abstract and empirical results). This leaves moderate support for the claim that observed gains arise from the rollout rules rather than sampling variability or unaccounted data characteristics.
minor comments (2)
- Notation for the family of rollout rules and the induced predictors could be introduced more explicitly with a small table or diagram to aid readability.
- The manuscript would benefit from a brief discussion of how the 20 series were selected and any preprocessing steps for the volatility targets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important considerations for robustness in non-stationary financial time series. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and validation-based deployment policies section] The headline result on validation-selected singletons and rule subsets improving over default MIMO rests on the assumption that performance differences are driven by the rollout rules and that the validation window is representative of future data. In non-stationary volatility series, a single fixed validation period risks selecting rules that exploit transient regime characteristics; the manuscript does not report multiple rolling validation windows, statistical tests for distribution shift between validation and test sets, or ablation on stability of rule rankings across windows.
Authors: We agree that non-stationarity poses a risk for validation-based selection and that additional robustness checks would strengthen the claims. Our current setup uses a single validation window immediately preceding the test period, following standard practice in financial forecasting to reflect recent regimes. However, we will add an ablation using multiple rolling validation windows, report stability of rule rankings across them, and include Kolmogorov-Smirnov tests for distribution shift between validation and test sets. These will be presented in a new subsection on validation sensitivity. revision: yes
-
Referee: [Empirical evaluation sections] The reported consistent empirical patterns across series, horizons, and architectures lack accompanying error bars, statistical significance tests, or exact details on data splits and train/validation/test partitioning. This leaves moderate support for the claim that observed gains arise from the rollout rules rather than sampling variability or unaccounted data characteristics.
Authors: We acknowledge that the current presentation would benefit from greater statistical rigor. The manuscript already specifies the 20 series, horizons, and partitioning (70/15/15 train/validation/test split with chronological ordering), but we will expand this description with exact dates and add error bars (via bootstrap resampling over series) plus paired t-tests or Wilcoxon tests for significance of gains over default MIMO. These additions will appear in the empirical evaluation and appendix. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper's claims rest entirely on direct empirical comparisons of rollout rules (selected via validation) against default MIMO deployment, evaluated on held-out test data across 20 volatility series and multiple architectures. No mathematical derivation, first-principles result, or fitted-parameter renaming is presented that reduces to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The evaluation follows standard train-val-test splits and is externally falsifiable via replication on the same data splits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Torben G Andersen, Tim Bollerslev, Francis X Diebold, and Paul Labys. 2003. Modeling and forecasting realized volatility.Econometrica71, 2 (2003), 579–625
2003
-
[2]
John M Bates and Clive WJ Granger. 1969. The combination of forecasts.Journal of the operational research society20, 4 (1969), 451–468
1969
-
[3]
Itishree Behera, Pragyan Nanda, Soma Mitra, and Swapna Kumari. 2024. Machine learning approaches for forecasting financial market volatility.Machine learning approaches in financial analytics(2024), 431–451
2024
-
[4]
Leo Breiman. 2001. Random forests.Machine learning45, 1 (2001), 5–32
2001
-
[5]
Andrea Bucci. 2017. Forecasting realized volatility: a review.Journal of Advanced Studies in Finance (JASF)8, 16 (2017), 94–138
2017
-
[6]
Kim Christensen, Mathias Siggaard, and Bezirgen Veliyev. 2023. A machine learning approach to volatility forecasting.Journal of Financial Econometrics21, 5 (2023), 1680–1727
2023
-
[7]
Peter F Christoffersen and Francis X Diebold. 2000. How relevant is volatility forecasting for financial risk management?Review of Economics and Statistics82, 1 (2000), 12–22
2000
- [8]
-
[9]
Thomas G Dietterich. 2000. Ensemble methods in machine learning. InInterna- tional workshop on multiple classifier systems. Springer, 1–15
2000
-
[10]
Jeff Fleming, Chris Kirby, and Barbara Ostdiek. 2001. The economic value of volatility timing.The Journal of Finance56, 1 (2001), 329–352
2001
-
[11]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning. PMLR, 1050–1059
2016
-
[12]
Sofia Giantsidi and Tarantola Claudia. 2025. Deep learning for financial forecast- ing: A review of recent advancements.A vailable at SSRN 5263710(2025)
2025
-
[13]
Riku Green, Zahraa S Abdallah, et al. 2026. Expectations vs. Realities: The Cost of MSE-Optimal Forecasting Under Conditional Uncertainty.arXiv preprint arXiv:2606.04342(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Riku Green, Zahraa S Abdallah, et al. 2026. Exposure Bias as Epistemic Underi- dentification in Recursive Forecasting.arXiv preprint arXiv:2606.12990(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [15]
- [16]
-
[17]
Riku Green, Grant Stevens, Zahraa S Abdallah, and Telmo M Silva Filho. 2025. Stratify: unifying multi-step forecasting strategies: R. Green et al.Data Mining and Knowledge Discovery39, 5 (2025), 64
2025
-
[18]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory.Neural computation9, 8 (1997), 1735–1780
1997
-
[19]
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. 2018. The M4 Competition: Results, findings, conclusion and way forward.International Journal of forecasting34, 4 (2018), 802–808
2018
-
[20]
Ricardo P Masini, Marcelo C Medeiros, and Eduardo F Mendes. 2023. Machine learning advances for time series forecasting.Journal of economic surveys37, 1 (2023), 76–111
2023
-
[21]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2022. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [22]
-
[23]
Mary E Thomson, Andrew C Pollock, Dilek Önkal, and M Sinan Gönül. 2019. Combining forecasts: Performance and coherence.International Journal of Fore- casting35, 2 (2019), 474–484
2019
-
[24]
Xiaoqian Wang, Rob J Hyndman, Feng Li, and Yanfei Kang. 2023. Forecast combinations: An over 50-year review.International Journal of Forecasting39, 4 (2023), 1518–1547
2023
-
[25]
Helmut Wasserbacher and Martin Spindler. 2022. Machine learning for financial forecasting, planning and analysis: recent developments and pitfalls.Digital Finance4, 1 (2022), 63–88
2022
-
[26]
Danny Wood, Tingting Mu, Andrew M Webb, Henry WJ Reeve, Mikel Lujan, and Gavin Brown. 2023. A unified theory of diversity in ensemble learning.Journal of machine learning research24, 359 (2023), 1–49
2023
-
[27]
Hao Wu and David Levinson. 2021. The ensemble approach to forecasting: A review and synthesis.Transportation Research Part C: Emerging Technologies132 (2021), 103357. A Additional Methodological Context This appendix adds a few extra notes on the forecasting target, the evaluation losses, the baseline comparison, and the rollout construction. These detail...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.