Human-Alignment, Calibration, and Activation Patterns in Large Language Model Uncertainty
Pith reviewed 2026-06-28 23:07 UTC · model grok-4.3
The pith
Large language models display uncertainty aligned with human judgments in both behavior and internal activations, while also showing calibration, and instruct fine-tuning modulates these traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Models show evidence of simultaneous human-alignment and calibration on uncertainty across the tested datasets, with these signals present in both overt outputs and activation patterns; instruct fine-tuning alters the expression of alignment and calibration on each facet.
What carries the argument
Uncertainty alignment, the measured similarity between LLM uncertainty signals (behavioral and activation-based) and human uncertainty judgments.
If this is right
- Alignment and calibration can coexist in the same model outputs and internal states on factual tasks.
- Instruct fine-tuning changes the degree of human-like uncertainty alignment.
- Internal activations carry detectable human-similar uncertainty information separate from output text.
- The pattern appears in both multiple-choice and open-ended recall settings.
Where Pith is reading between the lines
- If activation patterns reliably track alignment, they could serve as an internal probe for uncertainty without needing external human labels.
- Alignment might allow new fine-tuning objectives that explicitly reward human-like doubt patterns.
- The distinction between alignment and calibration could inform targeted interventions against overconfident hallucinations.
Load-bearing premise
The chosen datasets and definitions of human uncertainty and LLM uncertainty produce valid, comparable signals that can be separated from calibration effects.
What would settle it
A dataset where measured LLM behavioral or activation uncertainty shows no correlation with human uncertainty ratings on the same items, or where instruct fine-tuning produces no measurable change in alignment or calibration scores.
Figures
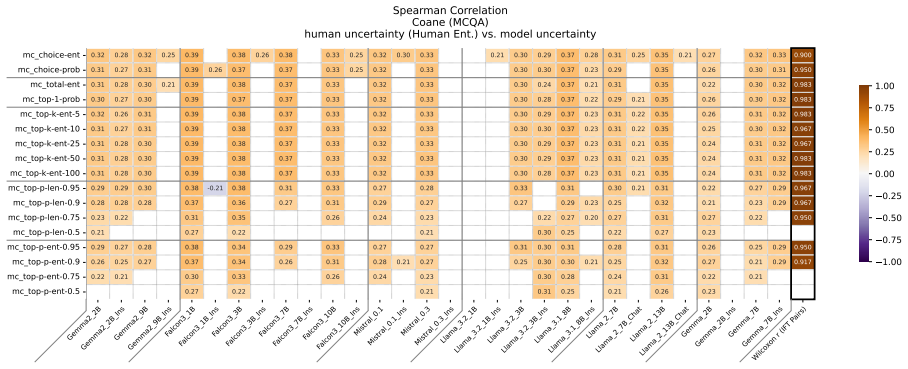
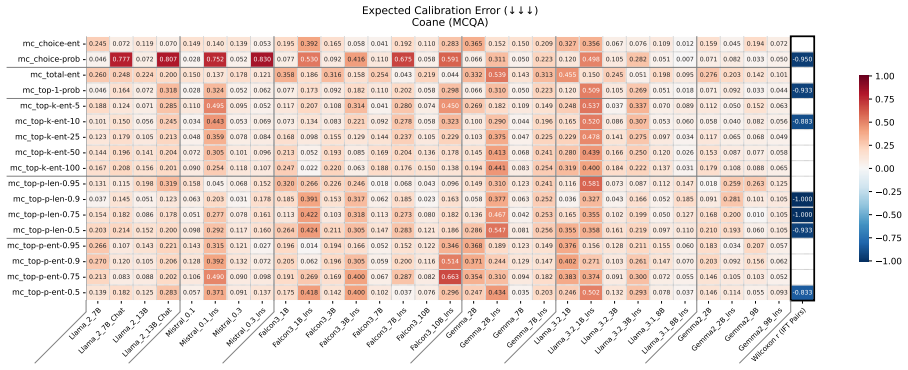
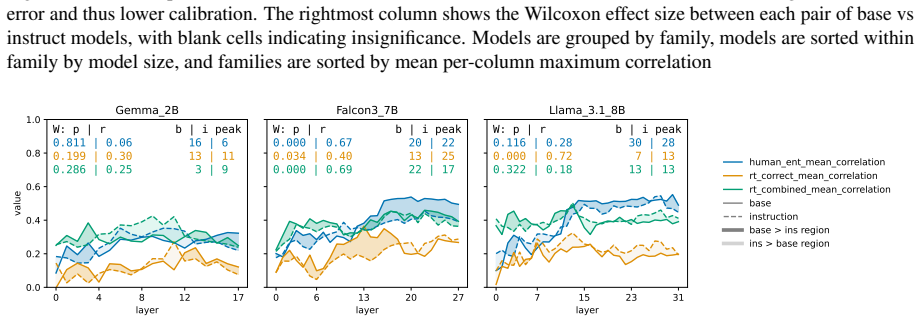
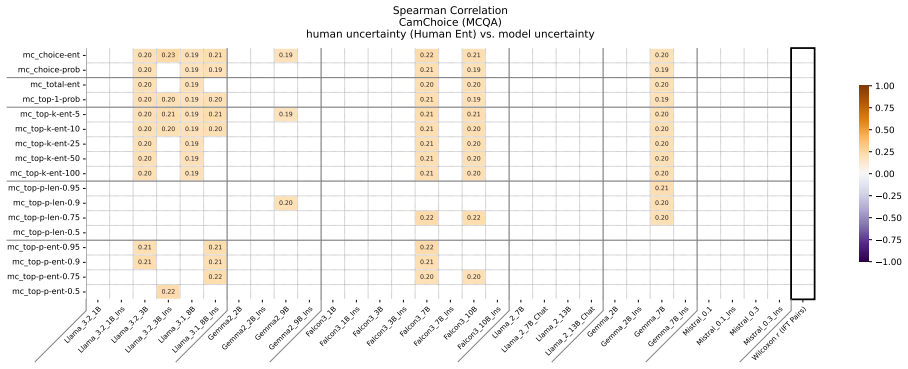
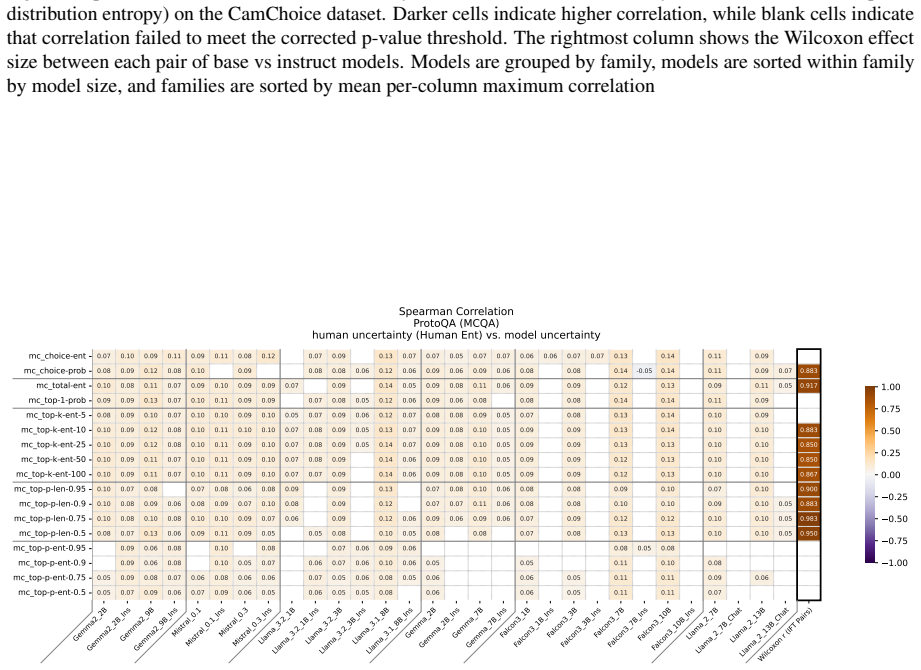
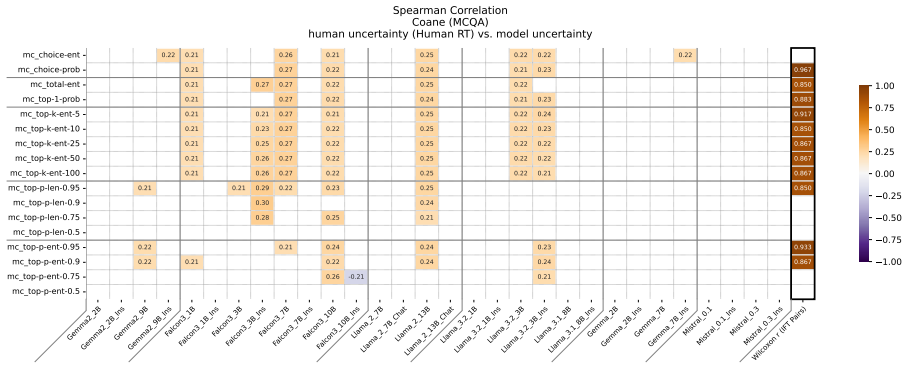
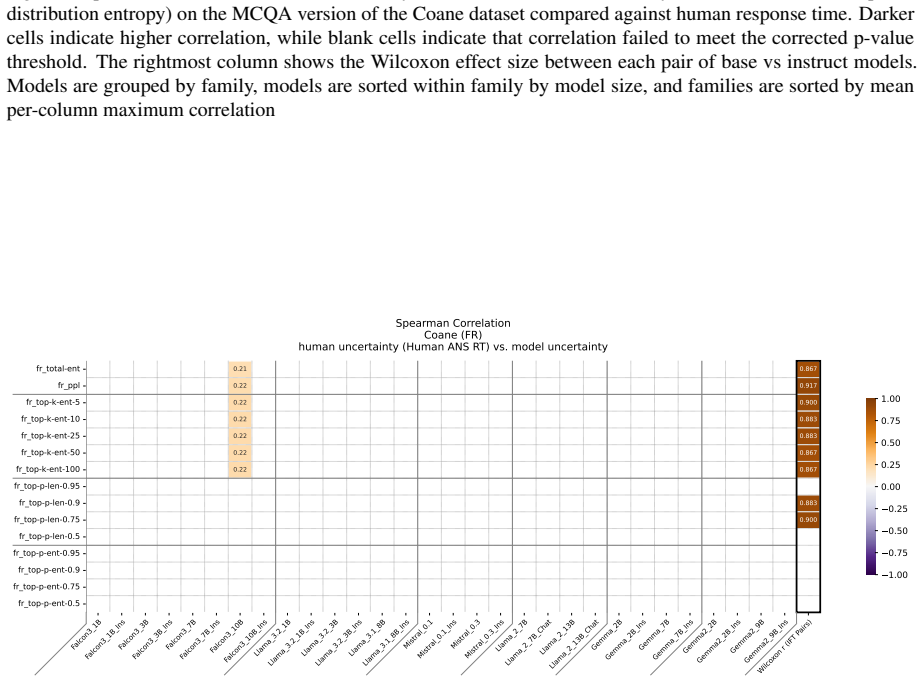
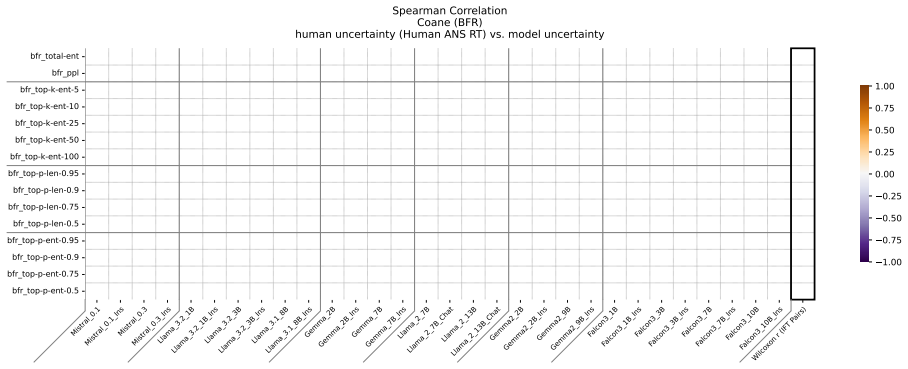

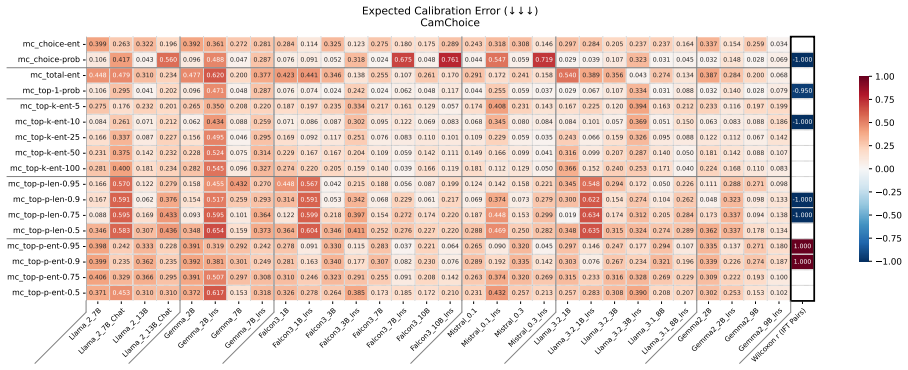
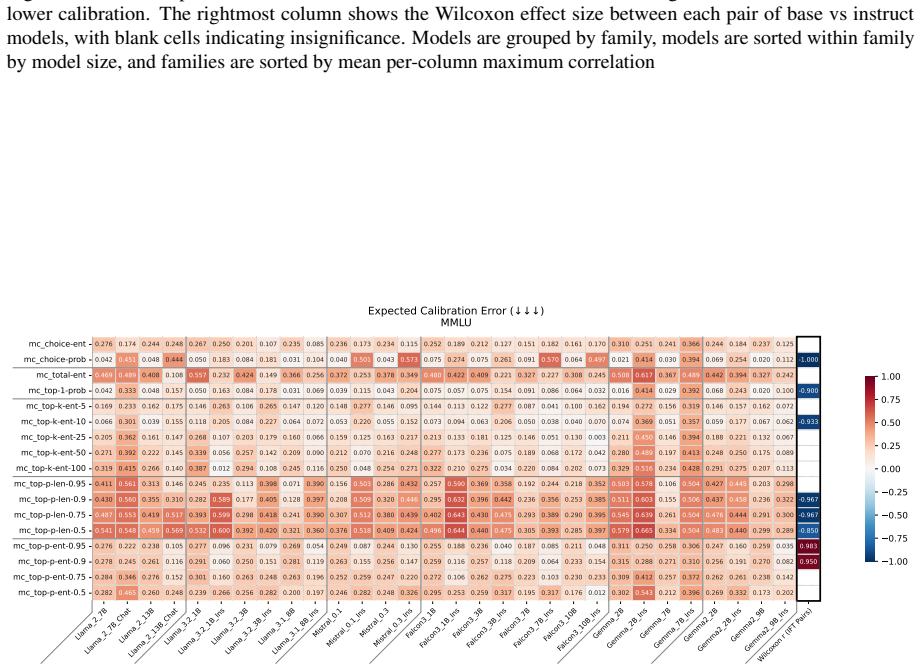
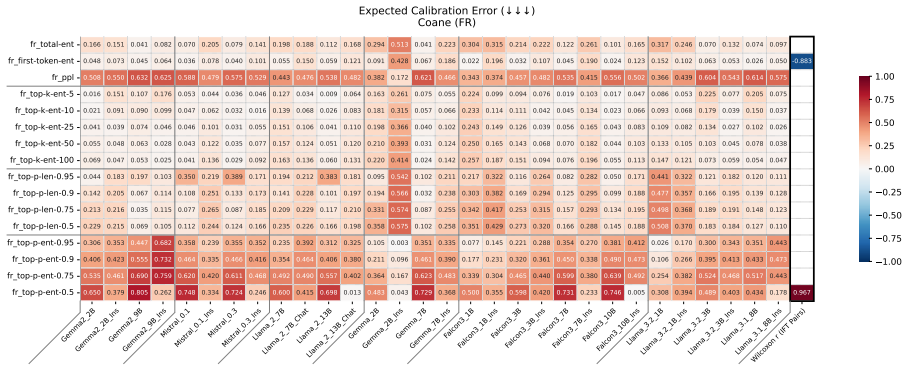
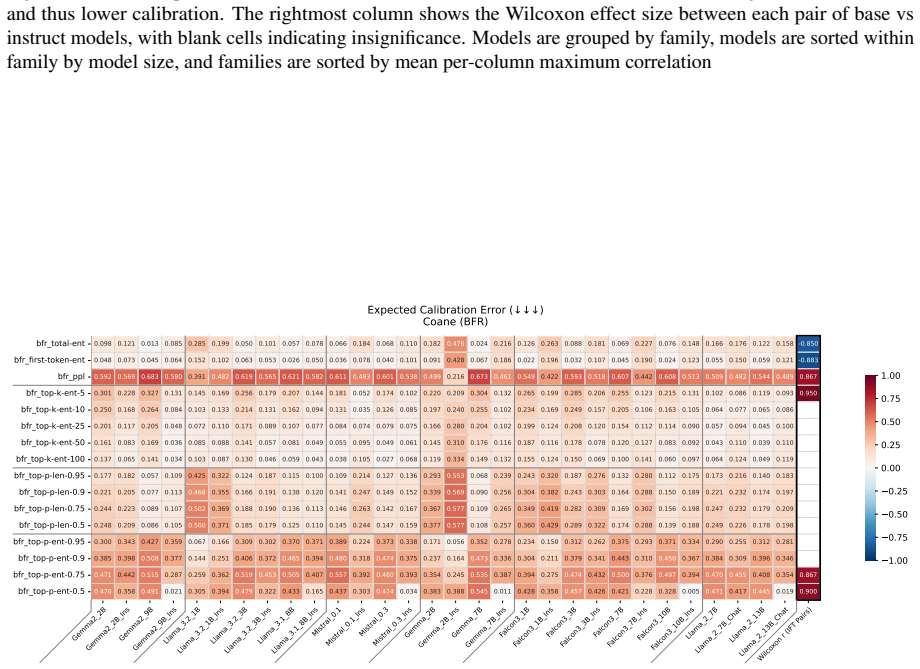
read the original abstract
Uncertainty Quantification is a large and growing subfield of large language model behavioral analysis. Primarily to recognize and combat hallucination, the field has largely focused on measuring and improving calibration, the accuracy of uncertainty judgments to task efficacy. In this work, we investigate the relatively underexplored question of how similar large language model uncertainty is to human uncertainty. We investigate the presence and strength of human-similar uncertainty signals, deemed uncertainty alignment, in large language model overt behavior and internal activation patterns. We identify whether the models show evidence of simultaneous alignment and calibration on a variety of datasets covering both multiple choice and open ended factual recall. And we characterize the effect of instruct fine-tuning on each of these facets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates uncertainty quantification in LLMs beyond calibration, focusing on human-similarity (alignment) of uncertainty signals in both overt behavior and internal activation patterns. It examines whether models exhibit simultaneous alignment and calibration across multiple-choice and open-ended factual recall datasets, and characterizes the impact of instruct fine-tuning on alignment, calibration, and activation patterns.
Significance. If substantiated with rigorous operational definitions and controls, the work could contribute to understanding LLM uncertainty by linking behavioral and representational signals to human uncertainty, potentially informing hallucination mitigation strategies that go beyond standard calibration metrics.
major comments (2)
- [Abstract] Abstract: The investigative claims rest on operational definitions of human uncertainty, LLM uncertainty (behavioral plus activations), alignment, and calibration, yet no details are provided on how these are measured or distinguished; without these, it is impossible to evaluate whether the signals are valid or confounded.
- [Abstract] Abstract: The claim of examining 'simultaneous alignment and calibration' requires explicit metrics for each and a method to assess their joint presence; the abstract provides no indication of how independence or interaction between these constructs is tested.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. The full manuscript contains the operational definitions, metrics, and analysis methods referenced in the abstract, but we agree that the abstract itself can be strengthened for clarity without altering the underlying claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The investigative claims rest on operational definitions of human uncertainty, LLM uncertainty (behavioral plus activations), alignment, and calibration, yet no details are provided on how these are measured or distinguished; without these, it is impossible to evaluate whether the signals are valid or confounded.
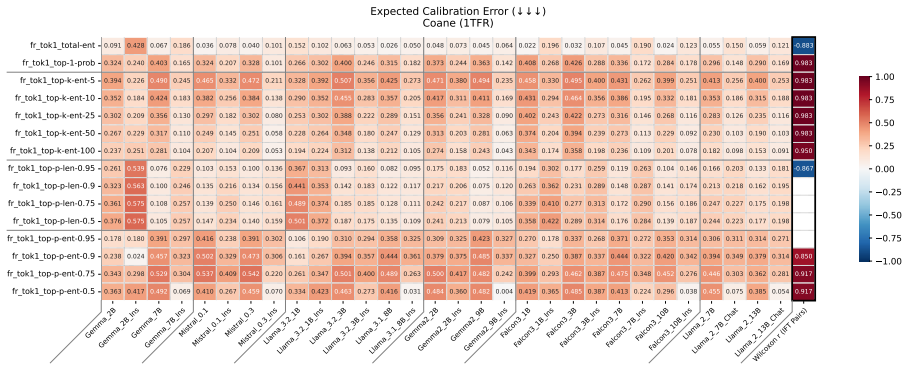
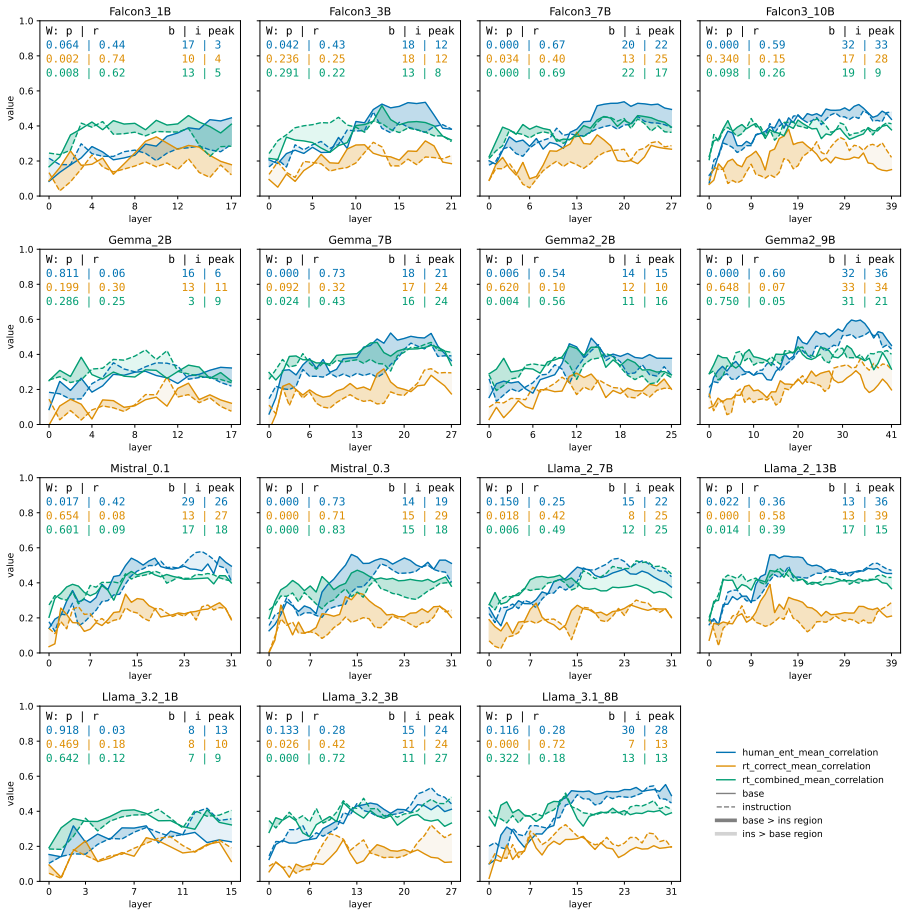
Authors: We acknowledge that the abstract is high-level and does not include measurement details. The full paper defines human uncertainty via participant response distributions on the same factual items, LLM behavioral uncertainty via both token-level entropy and verbalized confidence, alignment via rank correlation between human and model uncertainty signals, and calibration via expected calibration error; activation patterns are probed via linear classifiers on hidden states. We will revise the abstract to briefly reference these operationalizations. revision: yes
-
Referee: [Abstract] Abstract: The claim of examining 'simultaneous alignment and calibration' requires explicit metrics for each and a method to assess their joint presence; the abstract provides no indication of how independence or interaction between these constructs is tested.
Authors: The manuscript evaluates joint presence by computing alignment (correlation) and calibration (ECE) on identical model outputs per dataset, then reporting co-occurrence rates and the correlation between the two metrics across models and datasets. This is presented in the results on multiple-choice and open-ended tasks. We will update the abstract to indicate the use of these joint metrics. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an exploratory empirical study of LLM uncertainty alignment and calibration across datasets, with no equations, derivations, fitted parameters, or first-principles claims that could reduce to self-definition or input-by-construction. The abstract and described approach rely on observational comparisons of overt behavior, activations, and instruct-tuning effects, which are externally falsifiable via independent datasets rather than internally forced. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are present in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Truth is universal: Robust detection of lies in llms.Advances in Neural Information Processing Systems, 37:138393–138431. Jennifer H Coane and Sharda Umanath. 2021. A database of general knowledge question perfor- mance in older adults.Behavior Research Methods, 53(1):415–429. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. William E Hick. 1952. On the rate of gain of informa- tion.Quarterly Journal of experimental psychology, 4(1):11–26. Jerry Huang, Peng Lu, and Qiuhao Zeng. 2025a. Cali- brated language models and how to find them with label smoothing.arXiv preprint arXiv:2508.00264. Yuhe...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
PMLR. Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar. 2025. A survey on un- certainty quantification of large language models: Taxonomy, open research challenges, and future di- rections.ACM Computing Surveys, 58(3):1–38. Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Cata- rina Belem, Sheer Karny, Xinyue Hu, Lukas W Mayer, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.