Why SWAVE May Not Be All You Need:A Concept-Evolution Retrospective on Complex-Valued Recurrent Language Models
Pith reviewed 2026-06-27 01:03 UTC · model grok-4.3
The pith
SWAVE evolved by replacing its Resonance Head to escape cos-domination collapse, enabling stable 200k-step training with an untied PAM-derived embedding table.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
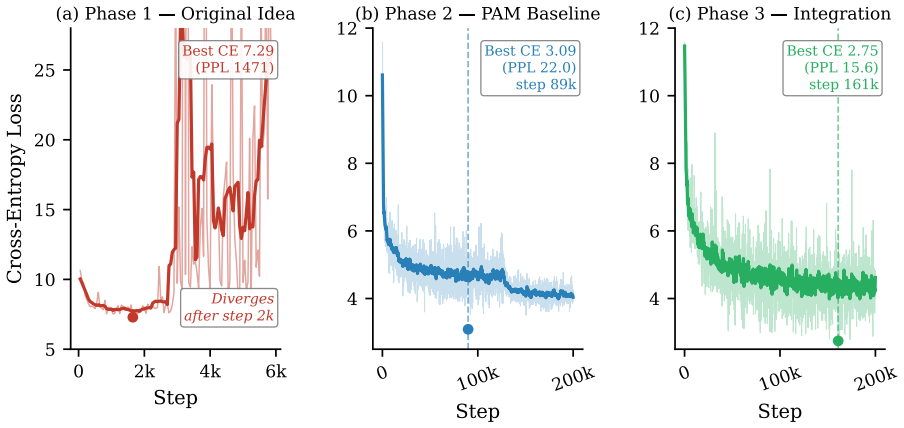
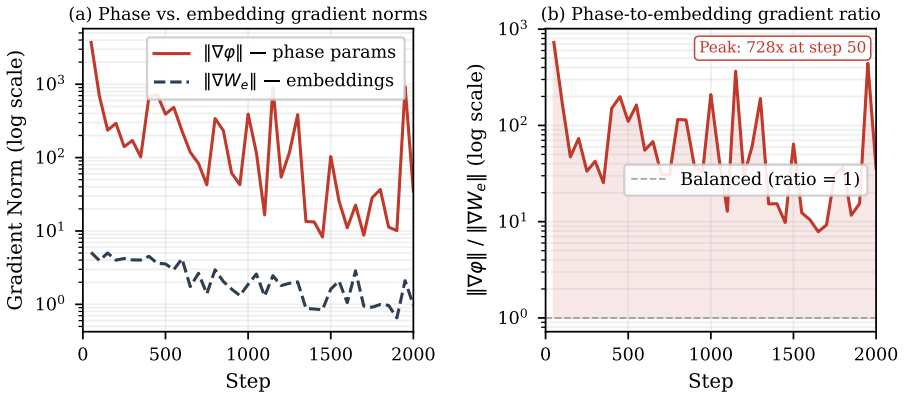
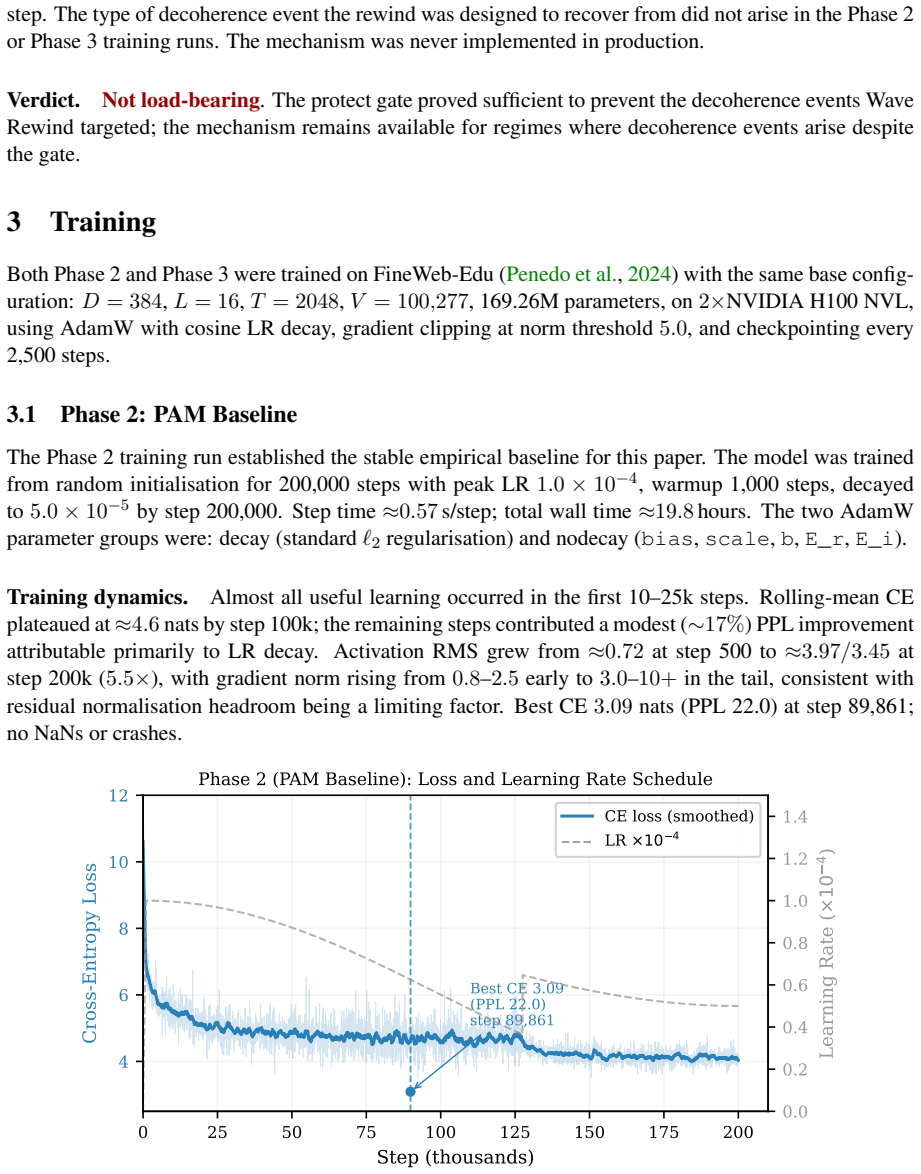
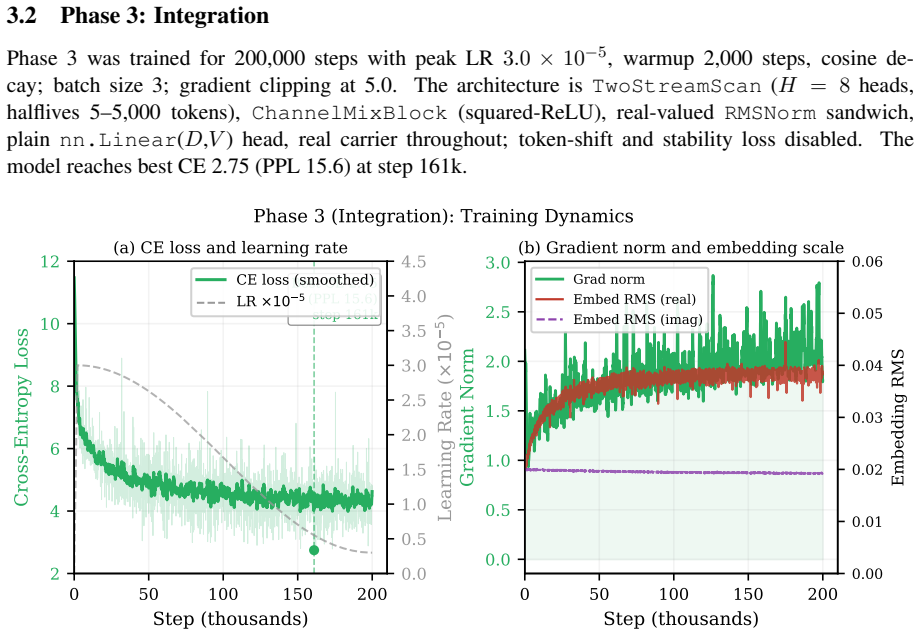
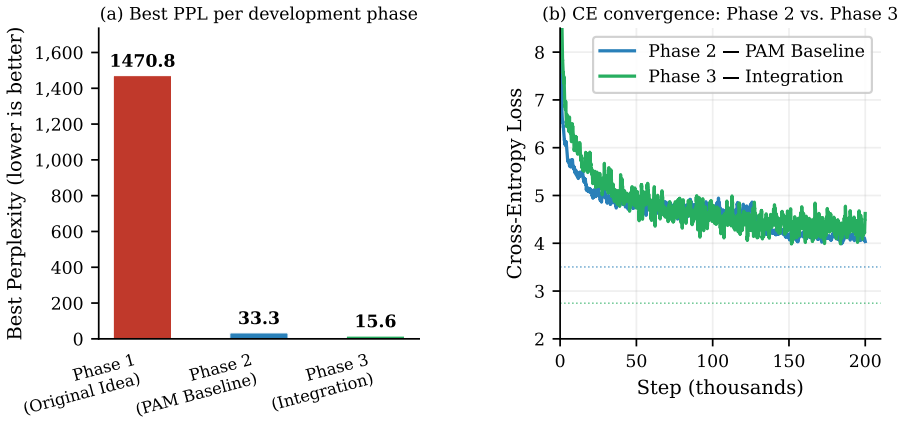
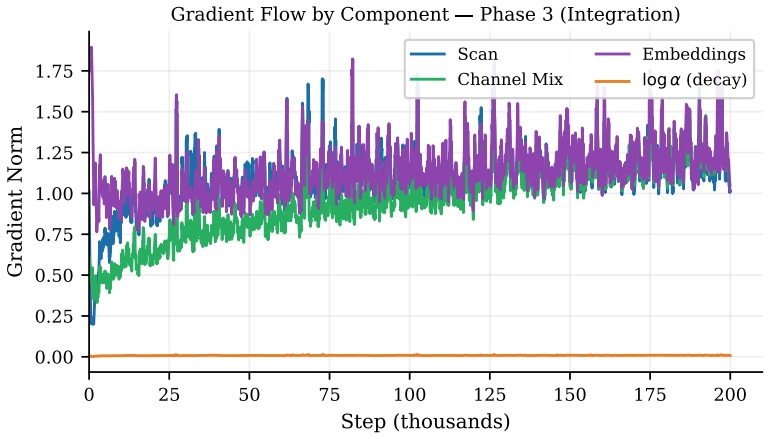
The Resonance Head structurally admits imaginary-channel collapse as a global loss minimum (cos-domination collapse) and was superseded by an untied head with independent real and imaginary embedding tables from the Phase-Associative Memory (PAM) architecture; this change resolved the degenerate minimum and enabled stable 200,000-step training (best-step PPL 22.0 at step 89,861). ComplexNorm and the Wave Propagation Scan proved load-bearing throughout and were retained; the four multi-scale retention concepts and auxiliary objectives showed no measurable improvement under controlled evaluation and were discarded.
What carries the argument
The untied head with independent real and imaginary embedding tables from the Phase-Associative Memory architecture, which eliminates the structural global minimum of cos-domination collapse that the original Resonance Head admits.
If this is right
- Stable training runs of at least 200,000 steps become feasible once the untied PAM head replaces the Resonance Head.
- ComplexNorm and Wave Propagation Scan must be kept because they carry essential signal integrity across phases.
- Multi-scale retention mechanisms can be omitted without performance loss under the same controlled conditions.
- The real-valued squared-ReLU channel mixer can replace the ComplexGatedUnit while using fewer parameters.
- Auxiliary objectives add no value once the structural collapse is removed.
Where Pith is reading between the lines
- The cos-domination collapse may appear in any complex-valued recurrent model that ties real and imaginary embedding tables.
- The plan-to-code traceability method could be applied to other recurrent or state-space architectures to surface similar hidden divergences.
- The six engineering principles may transfer to non-language sequence tasks that rely on unitary or norm-preserving transitions.
- Re-evaluating the discarded multi-scale concepts on longer contexts or different data distributions could still reveal conditional value.
Load-bearing premise
The findings that multi-scale retention concepts and auxiliary objectives added no benefit rest on controlled evaluation conditions that isolate those components from other training variables.
What would settle it
A controlled retraining run that keeps the original Resonance Head and records whether the imaginary-channel collapse still appears as the global loss minimum at convergence.
Figures
read the original abstract
SWave is a complex-valued recurrent language model (169.26M parameters, D=384, L=16, T=2048) trained on FineWeb-Edu using 2xH100 NVL. It was designed around three founding premises: that representing language as complex waves rather than real-valued numbers enables richer information encoding; that a Cayley-parameterised unitary transition provides a mathematical guarantee against state decay or explosion; and that a hidden state which rotates rather than shrinks preserves signal integrity over arbitrarily long contexts. The core of SWave evolved substantially across three development phases. The Resonance Head was found to structurally admit imaginary-channel collapse as a global loss minimum (a failure mode we term cos-domination collapse) and was superseded by an untied head with independent real and imaginary embedding tables from the Phase-Associative Memory (PAM) architecture. This resolved the degenerate minimum and enabled stable 200,000-step training (best-step PPL 22.0 at step 89,861). ComplexNorm and the Wave Propagation Scan proved load-bearing throughout all three phases and were retained to the final architecture. ProtectGatedScan was reframed as a structural prior rather than a learned behaviour. The four multi-scale retention concepts showed no measurable improvement under controlled evaluation and were found non-load-bearing. The ComplexGatedUnit was superseded by a real-valued squared-ReLU channel mixer with fewer parameters. The auxiliary training objectives showed no benefit once structural constraints were resolved. The investigation yields a formal characterisation of cos-domination collapse, a parallel scan with a log-space backward pass for numerical stability, six transferable engineering principles for complex-valued recurrent training, and a plan-to-code traceability methodology for catching structural divergences that conventional test suites miss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a retrospective on the internal development of SWAVE, a 169M-parameter complex-valued recurrent language model trained on FineWeb-Edu. It describes three phases of architectural evolution, asserts that the Resonance Head structurally admits a global loss minimum termed cos-domination collapse (imaginary-channel collapse), claims this was resolved by superseding it with an untied head using independent real/imaginary embeddings from the PAM architecture (enabling stable 200k-step training with best PPL 22.0), identifies ComplexNorm and Wave Propagation Scan as load-bearing, finds four multi-scale retention concepts and auxiliary objectives non-load-bearing, replaces ComplexGatedUnit with a real-valued squared-ReLU mixer, and reports six transferable engineering principles plus a plan-to-code traceability methodology.
Significance. If the reported collapse mode and its resolution were isolated and externally validated, the work could contribute concrete guidance on failure modes in complex-valued recurrent training. The internal retrospective format and absence of controlled ablations or external benchmarks, however, limit the result to anecdotal observations rather than generalizable findings. No machine-checked proofs, reproducible artifacts, or falsifiable predictions are provided.
major comments (3)
- [Abstract] Abstract and central claim: the assertion that replacing the Resonance Head with the untied PAM head resolved cos-domination collapse and enabled stable 200k-step training lacks any ablation isolating this change from concurrent modifications (reframing of ProtectGatedScan, replacement of ComplexGatedUnit, retention of ComplexNorm/Wave Propagation Scan). No controlled evaluation protocols or data isolating the head transition are referenced.
- [Abstract] Abstract: determinations that the four multi-scale retention concepts showed no measurable improvement and that auxiliary training objectives showed no benefit are stated as facts under 'controlled evaluation,' yet the manuscript provides no details on the identification methods, isolation from other variables, or external benchmarks supporting these load-bearing/non-load-bearing classifications.
- [Abstract] Abstract: the claim of a 'formal characterisation of cos-domination collapse' is presented as a yielded contribution, but the text supplies no mathematical derivation, proof, or section detailing how the global loss minimum was identified or shown to be structural to the Resonance Head.
minor comments (2)
- The manuscript would benefit from explicit section references or an appendix mapping the three development phases to specific architectural changes and metrics.
- Notation for complex-valued components (e.g., ProtectGatedScan, Wave Propagation Scan) should be defined at first use with equations rather than relying on retrospective narrative.
Simulated Author's Rebuttal
We thank the referee for the review and the emphasis on evidence isolation. We address each major comment below, noting that the retrospective format inherently limits controlled experimentation. Revisions will clarify claims without overstating the available evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and central claim: the assertion that replacing the Resonance Head with the untied PAM head resolved cos-domination collapse and enabled stable 200k-step training lacks any ablation isolating this change from concurrent modifications (reframing of ProtectGatedScan, replacement of ComplexGatedUnit, retention of ComplexNorm/Wave Propagation Scan). No controlled evaluation protocols or data isolating the head transition are referenced.
Authors: We agree the head replacement occurred alongside other modifications and no isolated ablation was performed. The collapse was observed with the Resonance Head and stability followed the full phase update including the untied head. The abstract will be revised to frame this as an empirical observation from sequential development rather than a causally isolated effect. revision: yes
-
Referee: [Abstract] Abstract: determinations that the four multi-scale retention concepts showed no measurable improvement and that auxiliary training objectives showed no benefit are stated as facts under 'controlled evaluation,' yet the manuscript provides no details on the identification methods, isolation from other variables, or external benchmarks supporting these load-bearing/non-load-bearing classifications.
Authors: The classifications derive from internal toggling experiments during development, but we accept that protocols and isolation details are not reported. A new subsection will be added describing the evaluation approach used to assess these components, drawing from available development logs. revision: partial
-
Referee: [Abstract] Abstract: the claim of a 'formal characterisation of cos-domination collapse' is presented as a yielded contribution, but the text supplies no mathematical derivation, proof, or section detailing how the global loss minimum was identified or shown to be structural to the Resonance Head.
Authors: The identification was empirical, based on repeated training runs exhibiting imaginary-channel dominance as a loss minimum. No mathematical derivation or proof was performed. The abstract will be updated to replace 'formal characterisation' with 'empirical identification' of the collapse mode. revision: yes
Circularity Check
Central claims of structural collapse, resolution, and load-bearing status reduce to unisolated internal training observations without external controls or verification.
specific steps
-
fitted input called prediction
[Abstract]
"The Resonance Head was found to structurally admit imaginary-channel collapse as a global loss minimum (a failure mode we term cos-domination collapse) and was superseded by an untied head with independent real and imaginary embedding tables from the Phase-Associative Memory (PAM) architecture. This resolved the degenerate minimum and enabled stable 200,000-step training (best-step PPL 22.0 at step 89,861)."
The claim that the PAM head resolved the degenerate minimum is derived from the authors' own training runs in which the change was introduced and stability was subsequently observed; without reported ablations isolating this single change from simultaneous architectural modifications, the resolution attribution reduces directly to the input observations.
-
fitted input called prediction
[Abstract]
"The four multi-scale retention concepts showed no measurable improvement under controlled evaluation and were found non-load-bearing. The ComplexGatedUnit was superseded by a real-valued squared-ReLU channel mixer with fewer parameters. The auxiliary training objectives showed no benefit once structural constraints were resolved."
Determinations that these elements showed no improvement, were non-load-bearing, or provided no benefit are made solely from the authors' internal controlled evaluations on their model variants; these conclusions are statistically forced by the same training data used to make the architectural decisions.
full rationale
The paper is a retrospective on the authors' own model development phases. Key assertions—that the Resonance Head admits cos-domination collapse, that the PAM untied head resolved it and enabled stable training, that certain components were load-bearing or showed no improvement—are presented as findings from the authors' training runs. No ablations isolating the head change from concurrent modifications (e.g., ProtectGatedScan reframing, ComplexGatedUnit replacement) are described, and no external benchmarks or independent verification are referenced. This makes the causal attributions equivalent to the input observations by construction rather than independent derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arjovsky, M., Shah, A., and Bengio, Y. (2016). Unitary Evolution Recurrent Neural Networks. In Proceedings of ICML
2016
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team (2024). Gemma 2: Improving Open Language Models at a Practical Size. arXiv:2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Gu, A., Dao, T., Ermon, S., Rudra, A., and Ré, C. (2020). HiPPO: Recurrent Memory with Optimal Polynomial Projections. In Proceedings of NeurIPS
2020
-
[4]
Gu, A., Goel, K., and Ré, C. (2022). Efficiently Modeling Long Sequences with Structured State Spaces. In Proceedings of ICLR
2022
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kaplan, J., McCandlish, S., Henighan, T., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Noest, A. J. (1992). Associative memory as a complex Hopfield network. Neural Networks, 5(2):365--376
1992
-
[8]
Peng, B., Alcaide, E., Anthony, Q., et al. (2023). RWKV: Reinventing RNNs for the Transformer Era. In Proceedings of EMNLP
2023
-
[9]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Penedo, G., Kydlíček, H., allal, L. B., et al. (2024). The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. arXiv:2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Pineau, J., Vincent-Lamarre, P., Sinha, K., et al. (2021). Improving Reproducibility in Machine Learning Research. Journal of Machine Learning Research, 22(164):1--20
2021
-
[11]
Plate, T. A. (1995). Holographic Reduced Representations. IEEE Transactions on Neural Networks, 6(3):623--641
1995
-
[12]
Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv:2002.05202
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Shazeer, N., Mirhoseini, A., Maziarz, K., et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of ICLR
2017
-
[14]
Su, J., Lu, Y., Pan, S., et al. (2021). RoFormer: Enhanced transformer with rotary position embedding. arXiv:2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Vishwakarma, S. et al. (2026). Phase-Associative Memory for sequence modelling. arXiv:2604.05030
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Wisdom, S., Powers, T., Hershey, J., Le Roux, J., and Atlas, L. (2016). Full-capacity unitary recurrent neural networks. In Proceedings of NeurIPS
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.