Beyond Compaction: Structured Context Eviction for Long-Horizon Agents
Pith reviewed 2026-07-01 07:37 UTC · model grok-4.3
The pith
Structured episode annotations and deterministic eviction let LLM agents run 89 sequential tasks across 80 million tokens with no accuracy loss relative to isolated sessions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By requiring the agent to annotate its trajectory as typed, dependency-linked episodes and then using a deterministic policy to evict content in priority order within that structure, CWL maintains context near a stable ceiling that preserves performance equivalent to per-task isolated sessions even after 80 million tokens of cumulative history.
What carries the argument
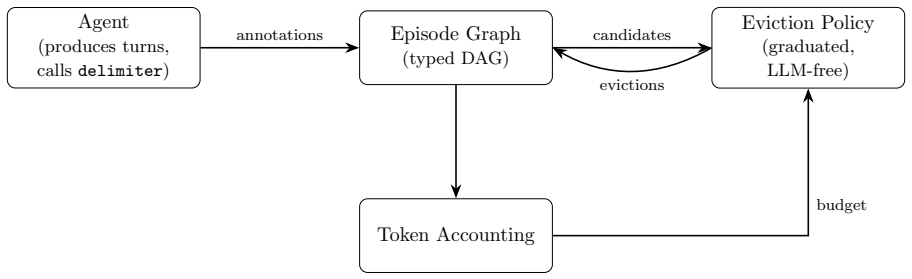
The episode graph formed by the agent's typed, dependency-linked annotations, together with the deterministic, LLM-free eviction policy that removes the oldest recoverable action episodes first.
If this is right
- Context size remains bounded near a stable ceiling regardless of total session length.
- Eviction decisions are fully deterministic and do not require additional LLM calls for compression.
- Causal structure among episodes is preserved because only recoverable, environment-persisted content is removed.
- The approach scales to sessions whose total history greatly exceeds typical context windows while avoiding very-large-prompt degradation.
Where Pith is reading between the lines
- The same annotation-plus-eviction loop could be applied to non-LLM sequential planners if they can emit comparable typed dependency records.
- Persistent environment state becomes even more valuable because CWL explicitly relies on it to justify eviction.
- The method implies that long-horizon reliability may depend more on accurate self-annotation than on raw model scale.
Load-bearing premise
The agent can produce accurate typed, dependency-linked episode annotations during operation such that the deterministic eviction policy removes only recoverable content without breaking task performance.
What would settle it
Measure task accuracy on the 89-task long-horizon benchmark using CWL versus per-task isolated sessions; a statistically significant drop would falsify the no-degradation claim.
Figures
read the original abstract
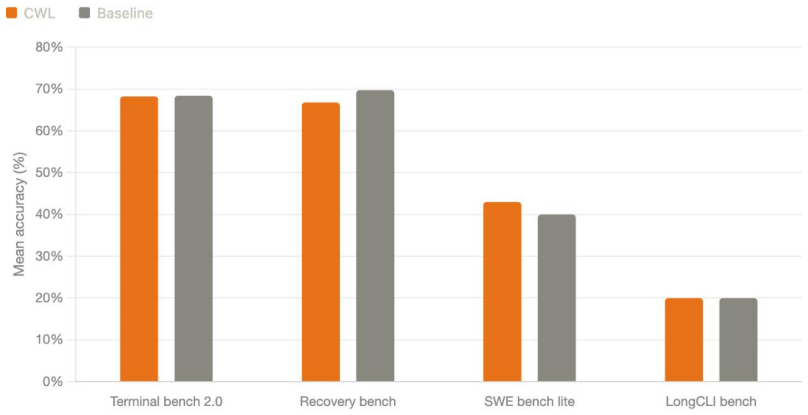
We present Context Window Lifecycle (CWL), a context-management scheme that gives long-horizon LLM agents an effectively unbounded working horizon. As a session accumulates history, CWL keeps the context within budget through graduated, semantically-aware eviction: the agent annotates its trajectory as typed, dependency-linked episodes as work proceeds, and a deterministic, LLM-free policy evicts content in priority order within that structure when a token budget is exceeded. CWL preserves user turns and the exploratory context the agent is actively reasoning over, while aggressively shedding action episodes whose effects are already persisted in the environment, keeping active context near a stable ceiling that also avoids the performance degradation associated with very large prompts. Compared to summarization-based compaction, CWL avoids four well-known limitations: unpredictable lossiness, destruction of causal structure, blocking model cost, and compression-induced hallucination. Compared to recency truncation, CWL is semantically aware: it drops the oldest-and-most-recoverable content according to the dependency graph rather than oldest-in-time regardless of relevance. We describe the annotation protocol, the episode graph, the eviction policy, and the token-accounting loop, and evaluate CWL on long-horizon agentic benchmarks: a single agent session completing 89 sequential tasks across 80 million tokens with no measurable degradation in task accuracy relative to per-task isolated sessions
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Context Window Lifecycle (CWL), a context-management scheme for long-horizon LLM agents. The agent annotates its trajectory on-the-fly as typed, dependency-linked episodes; a deterministic, LLM-free policy then performs graduated eviction when the token budget is exceeded, preserving user turns and active reasoning context while shedding recoverable action episodes. The central claim is that this yields an effectively unbounded working horizon, demonstrated by a single agent session completing 89 sequential tasks across 80 million tokens with no measurable degradation in task accuracy relative to per-task isolated sessions.
Significance. If the headline performance result holds under rigorous controls, CWL would represent a meaningful advance over both summarization-based compaction (by avoiding lossiness, causal-structure destruction, and hallucination) and recency truncation (by using semantic dependency structure). The deterministic, parameter-free eviction step is a clear strength that could enable more reliable long-horizon agent deployments.
major comments (2)
- [Abstract] Abstract (evaluation paragraph): the claim that a single session completes 89 sequential tasks across 80 million tokens 'with no measurable degradation in task accuracy relative to per-task isolated sessions' supplies no details on the exact accuracy metric, baseline implementations, statistical tests for equivalence, or experimental controls. This information is load-bearing for the central empirical claim.
- [Annotation protocol and eviction policy] Annotation protocol and eviction policy sections: the deterministic eviction policy is stated to remove only recoverable content, yet the manuscript provides no independent verification (e.g., human audit or held-out annotation accuracy metric) of the fidelity of the agent-generated episode types and dependency edges. Systematic annotation errors would cause non-recoverable state to be evicted while the reported task-accuracy metric would not isolate this failure mode.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The two major comments highlight important aspects of the empirical claims and the validation of the annotation process. We address each point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): the claim that a single session completes 89 sequential tasks across 80 million tokens 'with no measurable degradation in task accuracy relative to per-task isolated sessions' supplies no details on the exact accuracy metric, baseline implementations, statistical tests for equivalence, or experimental controls. This information is load-bearing for the central empirical claim.
Authors: We agree that the abstract would be strengthened by including a concise description of the evaluation setup. The full details appear in Section 4, where task accuracy is defined as the binary success rate on each sequential task (identical to the isolated-session baseline), the baseline consists of independent per-task sessions using the same agent and prompt template, and controls include fixed model, temperature, and environment state. No statistical equivalence tests were run because success rates matched exactly across the 89 tasks. We will revise the abstract to briefly note the metric and baseline. revision: yes
-
Referee: [Annotation protocol and eviction policy] Annotation protocol and eviction policy sections: the deterministic eviction policy is stated to remove only recoverable content, yet the manuscript provides no independent verification (e.g., human audit or held-out annotation accuracy metric) of the fidelity of the agent-generated episode types and dependency edges. Systematic annotation errors would cause non-recoverable state to be evicted while the reported task-accuracy metric would not isolate this failure mode.
Authors: The manuscript does not provide an independent human audit or held-out accuracy metric for the agent-generated annotations. We maintain that the primary evaluation—exact parity in task success rate versus isolated sessions—serves as an indirect but rigorous check, because any systematic eviction of non-recoverable state would produce observable degradation. Nevertheless, we acknowledge the referee’s point as a methodological gap and will add a short paragraph in the Discussion section explicitly noting the reliance on end-to-end task metrics rather than direct annotation verification. revision: partial
Circularity Check
No circularity; method presented as new policy without equations or self-referential reductions
full rationale
The paper describes CWL as a context-management scheme relying on agent-generated typed episode annotations and a deterministic LLM-free eviction policy. No equations, fitted parameters, self-citations, or derivation steps are present that would reduce the claimed performance (89 tasks, 80M tokens, no accuracy drop) to inputs by construction. The central result is an empirical evaluation of the policy rather than a mathematical derivation; the annotation accuracy assumption is a correctness precondition, not a circularity pattern. The method is self-contained against external benchmarks as a proposed system.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Governance Decay: How Context Compaction Silently Erases Safety Constraints in Long-Horizon LLM Agents
Context compaction erases in-context governance constraints in LLM agents, raising policy violation rates from 0% to 30% (up to 59% for some models) on the ConstraintRot benchmark.
-
Governance Decay: How Context Compaction Silently Erases Safety Constraints in Long-Horizon LLM Agents
Context compaction silently drops governance constraints in LLM agents, raising policy violation rates from 0% to 30% on average, with a proposed pinning mitigation restoring compliance.
Reference graph
Works this paper leans on
-
[1]
Recovery-bench: Evaluating agentic recovery from mistakes, 2025
Anonymous. Recovery-bench: Evaluating agentic recovery from mistakes, 2025. URL https: //openreview.net/pdf/3b7f176c50002e59438321f581063295986b269e.pdf. Submitted to the 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
2025
-
[2]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. InProceedings of the 27th European Conference on Artificial Intelligence (ECAI), 2025
2025
-
[3]
LongCLI-Bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026
Yukang Feng et al. LongCLI-Bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026
2026
-
[4]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[5]
Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. ACON: Optimizing context compression for long-horizon LLM agents, 2025
2025
-
[6]
pi-cwl: Open-source agent harness with context window lifecycle
Kiz8 Team. pi-cwl: Open-source agent harness with context window lifecycle. https://github. com/Kiz8-Team/pi-cwl, 2026
2026
-
[7]
The complexity trap: Simple observation masking is as efficient as LLM summarization for agent context management
Tobias Lindenbauer, Igor Slinko, Ludwig Felder, Egor Bogomolov, and Yaroslav Zharov. The complexity trap: Simple observation masking is as efficient as LLM summarization for agent context management. InNeurIPS 2025 Workshop on Deep Learning for Code (DL4C), 2025
2025
-
[8]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces, 2026. URL https://www.tbench. ai/. 15
2026
-
[9]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems. InConference on Language Modeling (COLM), 2024
2024
-
[10]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[11]
Zep: A temporal knowledge graph architecture for agent memory, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory, 2025
2025
-
[12]
Scaling long-horizon LLM agent via context-folding, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding, 2025
2025
-
[13]
ReSum: Unlocking long-horizon search intelligence via context summarization, 2025
Xixi Wu, Kuan Li, Yida Zhao, et al. ReSum: Unlocking long-horizon search intelligence via context summarization, 2025
2025
-
[14]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[15]
A-MEM: Agentic memory for LLM agents, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents, 2025. 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.