Parallel Causal Associative Fields: Gated Sparse Memory for Long-Context Language Modeling
Pith reviewed 2026-06-27 13:59 UTC · model grok-4.3
The pith
Parallel causal associative fields with gated sparse memory achieve lower perplexity than dense transformers for long-context language modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
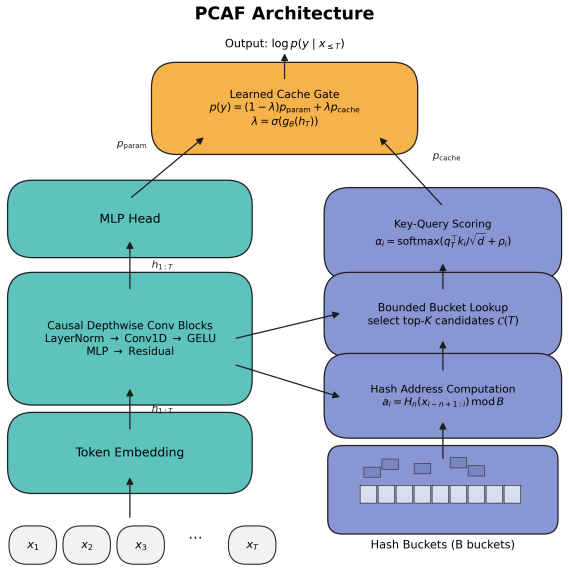
The proposed Parallel Causal Associative Field writes local records from a context window into hash buckets, retrieves a bounded candidate set for the current query, forms a sparse cache distribution over successor tokens, and mixes that cache with a parametric local language model through a learned gate, thereby maintaining sparse long-context access while avoiding a single fixed recurrent state bottleneck.
What carries the argument
The Parallel Causal Associative Field (PCAF), a parallel content-addressed memory over causal successor records that uses hash-bucket writing and bounded retrieval to create a sparse cache.
If this is right
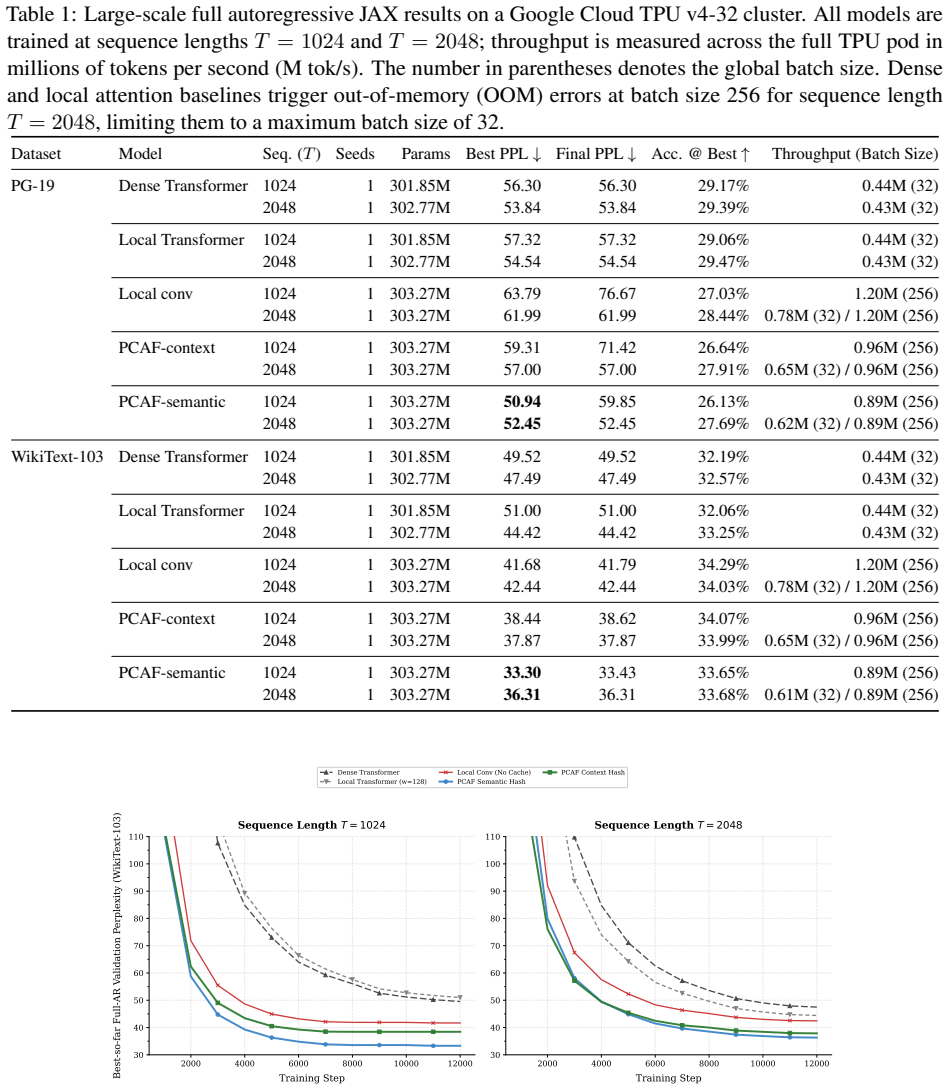
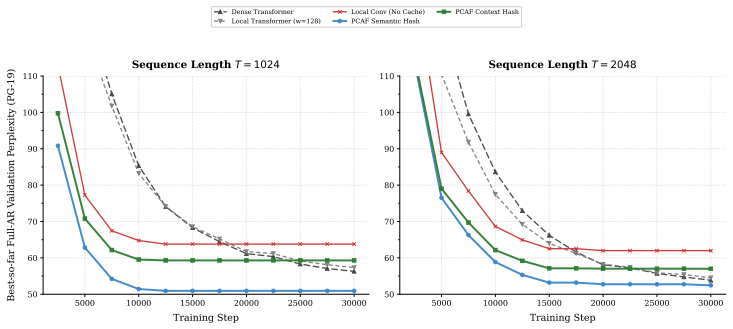
- At 303M parameters and T=2048, PCAF-semantic reaches 36.31 perplexity on WikiText-103 versus 47.49 for a matched dense Transformer.
- PCAF-semantic reaches 52.45 perplexity on PG-19 versus 53.84 for the dense baseline.
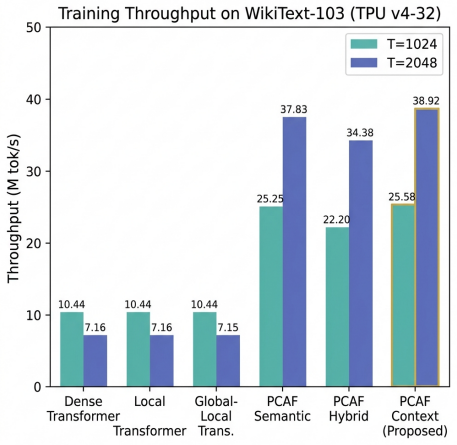
- PCAF-semantic processes 0.61-0.62M tokens/s across the TPU pod versus 0.43M tokens/s for baselines.
- The associative cache, retrieval capacity, and learned gate materially affect the speed-quality trade-off.
Where Pith is reading between the lines
- PCAF could potentially extend to even longer contexts by increasing bucket capacity without changing the core architecture.
- The gated mixing might allow hybrid models combining sparse memory with attention in specific layers.
- Similar associative fields might apply to non-language sequence tasks like time-series forecasting.
Load-bearing premise
The hash-bucket writing and bounded retrieval steps produce a useful sparse distribution over successor tokens that, when gated, improves next-token prediction beyond a standard parametric model.
What would settle it
Running the model with the associative cache disabled or with random retrieval instead of hash-bucket retrieval and observing no change or worse perplexity on WikiText-103.
Figures
read the original abstract
Transformers achieve strong language modeling performance by providing direct token-to-token communication paths, but causal self-attention scales quadratically with context length. Recurrent and state-space models reduce this cost, yet compress history into sequentially updated fixed-size states. This paper studies a third primitive: a parallel content-addressed memory over causal successor records. The proposed Parallel Causal Associative Field (PCAF) writes local records from a context window into hash buckets, retrieves a bounded candidate set for the current query, forms a sparse cache distribution over successor tokens, and mixes that cache with a parametric local language model through a learned gate. The resulting model maintains sparse long-context access while avoiding a single fixed recurrent state bottleneck. We evaluate PCAF under full autoregressive pretraining on WikiText-103 and PG-19 using a distributed Google Cloud TPU v4-32 pod. At 303M parameters and context length T = 2048, PCAF-semantic reaches 36.31 perplexity on WikiText-103 and 52.45 perplexity on PG-19, compared with 47.49 and 53.84 for a matched dense Transformer. PCAF-semantic simultaneously processes 0.61-0.62M tokens/s across the TPU pod, versus 0.43M tokens/s for dense and local attention baselines. Supporting 41M-parameter multi-seed sweeps and single-GPU component ablations show that the associative cache, retrieval capacity, and learned gate materially affect the speed-quality trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
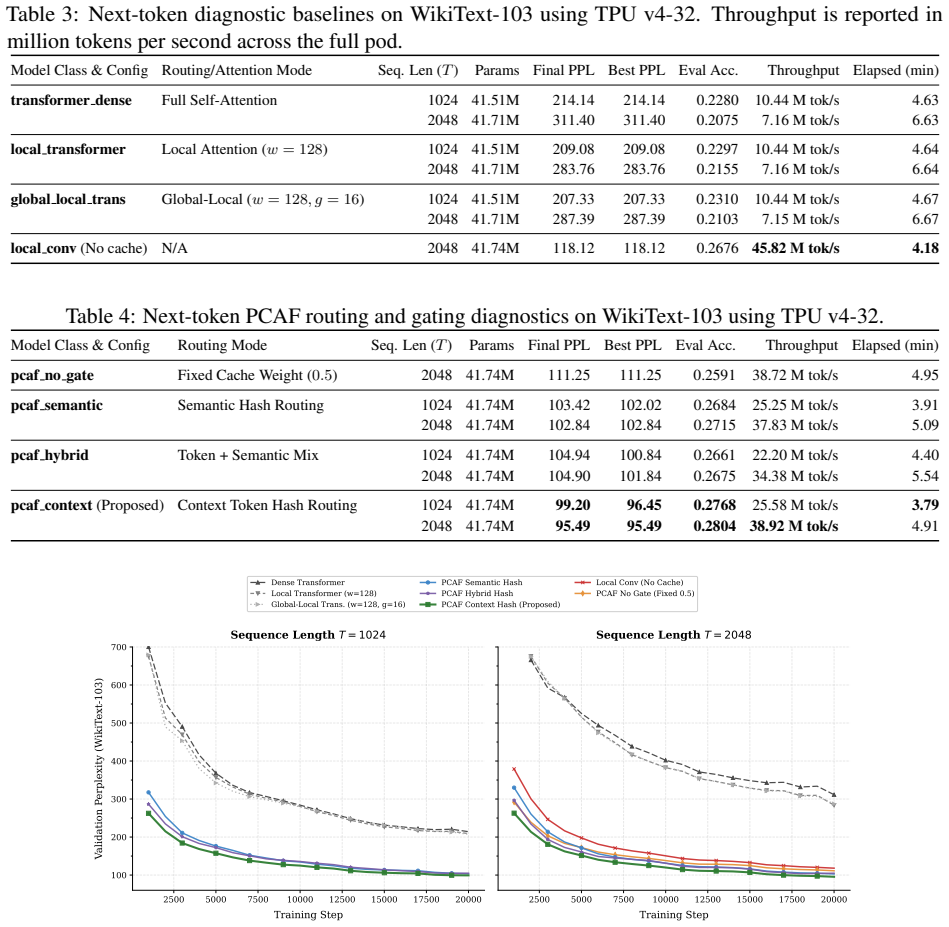
Summary. The paper proposes Parallel Causal Associative Field (PCAF), a parallel content-addressed memory mechanism for long-context language modeling. Records from a context window are written into hash buckets; a bounded candidate set is retrieved for the current query to form a sparse cache distribution over successor tokens, which is then mixed with a parametric local LM via a learned gate. At 303M parameters and T=2048, PCAF-semantic reports 36.31 perplexity on WikiText-103 and 52.45 on PG-19 (vs. 47.49 and 53.84 for a matched dense Transformer) with higher throughput (0.61-0.62M vs. 0.43M tokens/s). Supporting multi-seed ablations on the associative cache, retrieval capacity, and gate are presented.
Significance. If the performance claims hold, the work demonstrates a viable third primitive for long-context modeling that avoids both quadratic attention cost and fixed-size recurrent state compression while delivering measurable perplexity gains and throughput improvements on standard benchmarks. The multi-seed component ablations provide direct evidence that the hash-bucketed successor distribution and gating contribute to the observed speed-quality trade-off.
major comments (2)
- [abstract and evaluation section] The evaluation reports concrete perplexity and throughput numbers (abstract) but supplies no training details (optimizer, schedule, data order, initialization), baseline construction (exact architecture matching for the dense Transformer), number of seeds for the main 303M results, or statistical tests. This directly undermines assessment of the central claim that PCAF improves next-token prediction beyond the parametric baseline.
- [mechanism description] The description of hash-bucket writing and bounded retrieval (abstract) does not specify how causality is strictly enforced during parallel writes or how collisions are resolved without introducing future-token leakage; this is load-bearing for the claim that the resulting sparse distribution is a valid causal successor cache.
minor comments (2)
- [abstract] Clarify the distinction between PCAF-semantic and other variants in the results tables; the current naming is not defined in the abstract.
- [evaluation] The throughput numbers are given as a range (0.61-0.62M); provide per-run values or hardware configuration details for reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive review. We address each major comment below and indicate the revisions planned for the next manuscript version.
read point-by-point responses
-
Referee: [abstract and evaluation section] The evaluation reports concrete perplexity and throughput numbers (abstract) but supplies no training details (optimizer, schedule, data order, initialization), baseline construction (exact architecture matching for the dense Transformer), number of seeds for the main 303M results, or statistical tests. This directly undermines assessment of the central claim that PCAF improves next-token prediction beyond the parametric baseline.
Authors: We agree the evaluation section is insufficiently detailed. The revised manuscript will add a dedicated experimental setup subsection specifying the optimizer (AdamW), learning-rate schedule, data ordering, and initialization. We will also document the exact layer widths, head counts, and embedding dimensions used to construct the matched 303M-parameter dense Transformer baseline. For the main 303M results we will explicitly state that they are single-run (consistent with the scale of TPU-pod pretraining) while retaining the existing multi-seed ablations at 41M parameters; we will add statistical tests on the smaller-scale controlled experiments. revision: partial
-
Referee: [mechanism description] The description of hash-bucket writing and bounded retrieval (abstract) does not specify how causality is strictly enforced during parallel writes or how collisions are resolved without introducing future-token leakage; this is load-bearing for the claim that the resulting sparse distribution is a valid causal successor cache.
Authors: We accept that the mechanism description must be more explicit. The revised text will clarify that writes occur over strictly causal prefixes: each context window is processed left-to-right, with hash-bucket updates performed in temporal order even when the underlying hardware executes in parallel. Collisions within a bucket are resolved by a most-recent-wins rule that overwrites older entries, guaranteeing that no token beyond the current position can appear in the retrieved successor distribution. We will include pseudocode and a small illustrative diagram of the write/retrieve steps. revision: yes
- Multi-seed statistics and formal statistical tests for the primary 303M-parameter pretraining runs, which were performed only once owing to the prohibitive cost of full autoregressive training on TPU v4-32 pods.
Circularity Check
No significant circularity
full rationale
The paper reports empirical perplexity results (36.31 vs 47.49 on WikiText-103) obtained from end-to-end autoregressive pretraining on fixed public corpora at matched parameter count. The mechanism description (hash-bucket writing, bounded retrieval, gated sparse cache) is presented as an architectural choice whose value is measured by those external benchmarks rather than defined or predicted by the paper's own equations. No derivation chain, self-citation load-bearing step, or fitted-input-called-prediction is visible in the provided text; the central claim remains an independent empirical measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-token prediction on WikiText-103 and PG-19 is a sufficient proxy for long-context language modeling quality.
invented entities (1)
-
Parallel Causal Associative Field (PCAF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150,
Pith/arXiv arXiv 2004
-
[2]
Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Pith/arXiv arXiv 1904
-
[3]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
-
[4]
Improving neural language models with a continuous cache.arXiv preprint arXiv:1612.04426,
Edouard Grave, Armand Joulin, Moustapha Ciss ´e, David Grangier, and Herv ´e J´egou. Improving neural language models with a continuous cache.arXiv preprint arXiv:1612.04426,
-
[5]
Neural turing machines.arXiv preprint arXiv:1410.5401,
15 Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401,
-
[6]
Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
-
[7]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R´e. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396,
-
[8]
Xiang Hu, Jiaqi Leng, Jun Zhao, Kewei Tu, and Wei Wu. Hardware-aligned hierarchical sparse attention for efficient long-term memory access.arXiv preprint arXiv:2504.16795,
-
[9]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843,
-
[10]
RWKV: Reinventing RNNs for the transformer era.arXiv preprint arXiv:2305.13048,
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV , Xuzheng He, Haowen Hou, Pawel Kazienko, Jan Kocon, Jiaming Kong, Bart Koptyra, Hayden Lau, Jiong Lin, Krishna Sri Hari Ma, Ferdinand Microsoft´e, Aditya Mohan, Leon Ni, Non Noppakun, Dang Pan, Fed...
-
[11]
RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864,
Jianlin Su, Yu Lu, Shengding Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864,
-
[12]
16 Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jian Wang, Minghao Huang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
-
[13]
Memory networks.arXiv preprint arXiv:1410.3916,
Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks.arXiv preprint arXiv:1410.3916,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.