Mitigating Spurious Correlations with Memorization-Guided Dataset De-Biasing
Pith reviewed 2026-06-28 15:45 UTC · model grok-4.3
The pith
A two-stage scoring function selects small data subsets that let standard models outperform specialized debiasing methods on spurious correlations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
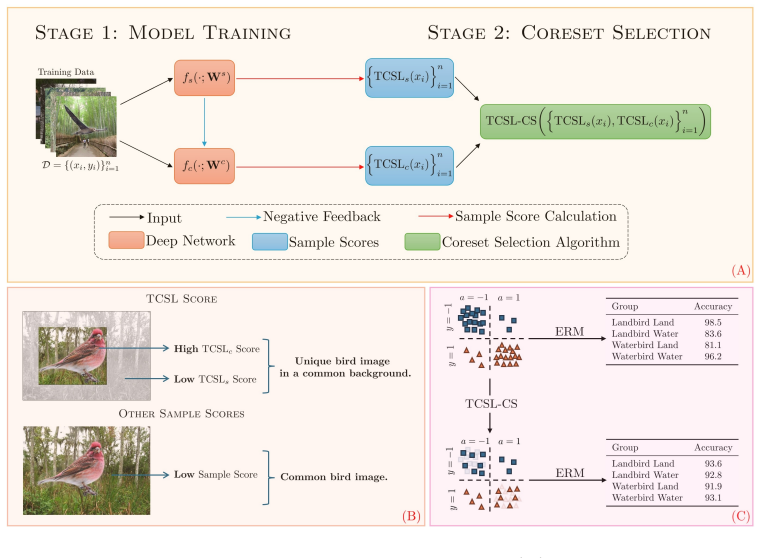
We propose a two-stage sample scoring function that disentangles the learning dynamics of core and spurious features and evaluates their difficulty separately. Based on our proposed metric, we introduce a new algorithm to find and prioritize informative samples both with and without spurious correlations. A standard ERM model trained on our selected samples achieves superior performance compared to state-of-the-art debiasing techniques, while requiring as little as 10% of the original training data.
What carries the argument
two-stage sample scoring function that evaluates difficulty of core features separately from spurious features
If this is right
- A standard ERM model on the selected subset outperforms state-of-the-art debiasing techniques.
- The required training set can be reduced to 10% of the original data.
- Sample selection succeeds without access to group labels.
- The method prioritizes informative samples both inside and outside the spurious-correlation majority group.
- Existing scoring functions are shown to depend on spurious features and therefore mis-rank sample importance.
Where Pith is reading between the lines
- The selection procedure could lower the cost of training on large real-world datasets that contain hidden biases.
- The same scoring idea might extend to other label-free data pruning tasks beyond spurious-correlation mitigation.
- Testing the method on datasets where spurious features are harder to isolate would reveal the limits of the two-stage separation.
- Pairing the selected subset with lightweight regularization could produce further gains on minority samples.
Load-bearing premise
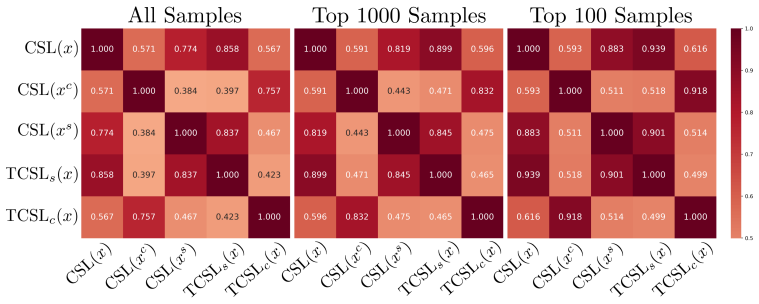
The two-stage scoring function can disentangle the learning dynamics of core features from those of spurious features in a way that existing scoring functions cannot.
What would settle it
Retraining a standard model on the selected 10% subset yields lower accuracy on minority-group test samples than full-data training or competing debiasing methods.
Figures
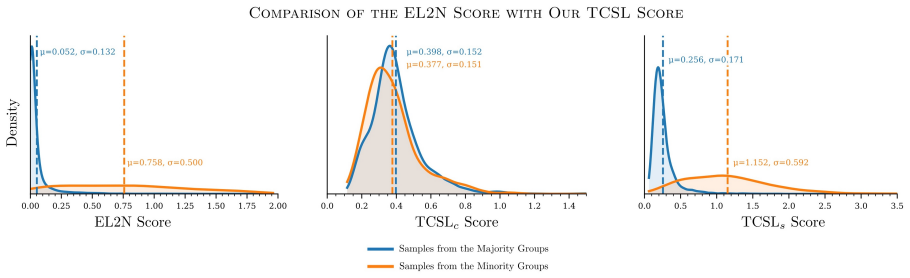
read the original abstract
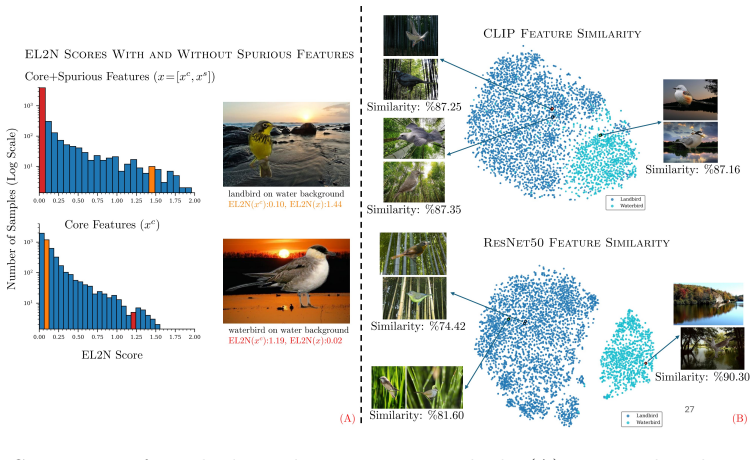
Real-world datasets often contain spurious correlations that are not causally related to the target label. When such correlations dominate the majority of training samples, models tend to rely on them, leading to misclassification of minority samples that do not exhibit the same spurious patterns. While a potential approach is to select subsets of data to better represent the minority samples, this may require access to group labels, which are typically unknown. Furthermore, as we demonstrate, widely used sample scoring functions in the invariant subset or coreset selection literature largely depend on spurious features and therefore fail to accurately capture the importance or difficulty of core, causally relevant features. Accordingly, we propose to mitigate spurious correlations by developing a two-stage sample scoring function that disentangles the learning dynamics of core and spurious features and evaluates their difficulty separately. Based on our proposed metric, we introduce a new algorithm to find and prioritize informative samples both with and without spurious correlations. Extensive experiments demonstrate that a standard ERM model trained on our selected samples achieves superior performance compared to state-of-the-art debiasing techniques, while requiring as little as 10\% of the original training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing sample scoring functions in coreset/invariant subset selection largely depend on spurious features. It proposes a two-stage memorization-guided scoring function that disentangles core-feature and spurious-feature learning dynamics, uses this to select an informative 10% subset (with and without spurious correlations), and shows that standard ERM trained on this subset outperforms state-of-the-art debiasing methods.
Significance. If the two-stage metric reliably isolates core-feature difficulty, the result would be significant: it offers a label-free route to data-efficient debiasing that reduces training data to 10% while beating specialized debiasing algorithms. The approach also supplies a concrete, falsifiable test of whether early vs. late training dynamics can be used to separate core and spurious signals.
major comments (2)
- [§3] §3 (two-stage scoring function): the central claim that the first stage (early dynamics) and second stage (later dynamics) disentangle core vs. spurious difficulty lacks an identifiability argument or ablation. No formal criterion is given showing that stage-1 scores remain invariant when the strength of the spurious correlation is varied while core features are held fixed; without this, the selected 10% subset could still be dominated by majority spurious patterns.
- [§4–5] §4–5 (experimental validation): the superiority of ERM on the selected subset over SOTA debiasing baselines is reported, but the manuscript provides no controlled experiment that varies only the spurious-correlation strength while measuring whether the two-stage scores correctly up-weight minority core samples. The 10% data-sufficiency claim therefore rests on the unverified separation assumption.
minor comments (2)
- [§3] Notation for the two-stage metric (Eq. (3) or equivalent) should explicitly define the early-training window and the memorization threshold used in each stage.
- [Abstract / §2] The abstract states that existing scoring functions 'largely depend on spurious features'; this should be supported by a quantitative comparison (e.g., correlation of each baseline score with spurious vs. core labels) rather than left as a qualitative assertion.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major comments point by point below, indicating where we will make revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (two-stage scoring function): the central claim that the first stage (early dynamics) and second stage (later dynamics) disentangle core vs. spurious difficulty lacks an identifiability argument or ablation. No formal criterion is given showing that stage-1 scores remain invariant when the strength of the spurious correlation is varied while core features are held fixed; without this, the selected 10% subset could still be dominated by majority spurious patterns.
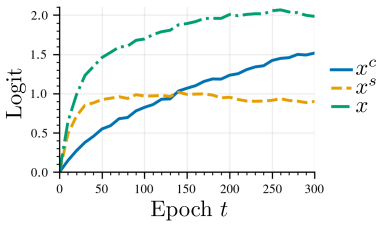
Authors: We acknowledge that our manuscript does not include a formal identifiability argument or a specific ablation varying spurious correlation strength while holding core features fixed. The two-stage approach is motivated by established observations in the memorization literature that models learn spurious features faster than core features in the presence of strong correlations. In the revised manuscript, we will add an ablation study on synthetic datasets where we systematically vary the spurious correlation strength and demonstrate that the stage-1 scores prioritize samples based on core feature difficulty, leading to subsets that improve minority group performance. revision: yes
-
Referee: [§4–5] §4–5 (experimental validation): the superiority of ERM on the selected subset over SOTA debiasing baselines is reported, but the manuscript provides no controlled experiment that varies only the spurious-correlation strength while measuring whether the two-stage scores correctly up-weight minority core samples. The 10% data-sufficiency claim therefore rests on the unverified separation assumption.
Authors: The experiments in the manuscript are performed on several benchmark datasets that exhibit different levels of spurious correlations, and we consistently observe that ERM on the 10% subset outperforms debiasing methods. However, we agree that a more controlled experiment isolating the effect of spurious correlation strength would provide stronger validation. We will include such an experiment in the revision using a controlled synthetic dataset to explicitly measure how the two-stage scores up-weight minority core samples as spurious strength varies. revision: yes
Circularity Check
No circularity detected; proposal is self-contained without reduction to inputs or self-citations.
full rationale
The abstract and available text introduce a two-stage sample scoring function as a novel proposal to disentangle core and spurious feature dynamics, with no equations, derivations, or self-citations provided that would reduce the metric or selection algorithm to fitted parameters, prior self-work, or definitional equivalence. No load-bearing steps match the enumerated circularity patterns, as the central claim of superior ERM performance on a 10% subset is presented as an empirical outcome rather than a constructed prediction. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
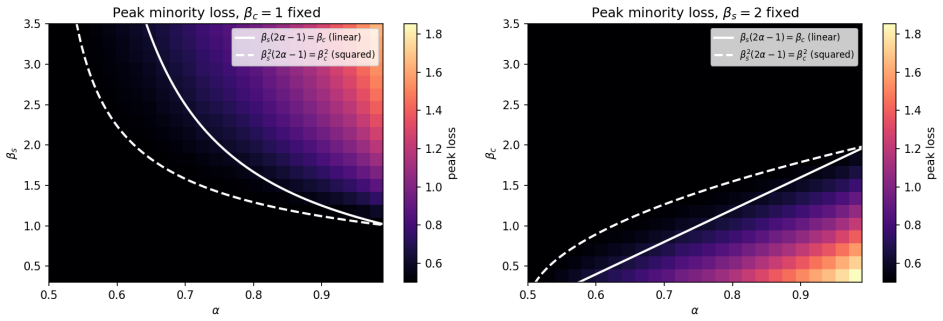
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, L´ eon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Reza Bayat, Mohammad Pezeshki, Elvis Dohmatob, David Lopez-Paz, and Pascal Vin- cent. The pitfalls of memorization: When memorization hurts generalization.arXiv preprint arXiv:2412.07684, 2024
-
[3]
How spurious features are memorized: Precise analysis for random and ntk features
Simone Bombari and Marco Mondelli. How spurious features are memorized: Precise analysis for random and ntk features. InForty-first International Conference on Machine Learning, 2024. 12
2024
-
[4]
Environment inference for invariant learning
Elliot Creager, J¨ orn-Henrik Jacobsen, and Richard Zemel. Environment inference for invariant learning. InInternational Conference on Machine Learning, pages 2189–2200. PMLR, 2021
2021
-
[5]
Robust learning with pro- gressive data expansion against spurious correlation.Advances in neural information processing systems, 36:1390–1402, 2023
Yihe Deng, Yu Yang, Baharan Mirzasoleiman, and Quanquan Gu. Robust learning with pro- gressive data expansion against spurious correlation.Advances in neural information processing systems, 36:1390–1402, 2023
2023
-
[6]
The impact of coreset selection on spurious correlations and group robustness
Amaya Dharmasiri, William Yang, Polina Kirichenko, Lydia T Liu, and Olga Russakovsky. The impact of coreset selection on spurious correlations and group robustness. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[7]
Optimal shrinkage of eigenvalues in the spiked covariance model.Annals of statistics, 46(4):1742, 2018
David L Donoho, Matan Gavish, and Iain M Johnstone. Optimal shrinkage of eigenvalues in the spiked covariance model.Annals of statistics, 46(4):1742, 2018
2018
-
[8]
Does learning require memorization? a short tale about a long tail
Vitaly Feldman. Does learning require memorization? a short tale about a long tail. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, pages 954–959, 2020
2020
-
[9]
Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
Arthur Jacot, Franck Gabriel, and Cl´ ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
2018
-
[10]
Last layer re- training is sufficient for robustness to spurious correlations,
Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Last layer re-training is sufficient for robustness to spurious correlations.arXiv preprint arXiv:2204.02937, 2022
-
[11]
Wide neural networks of any depth evolve as linear models under gradient descent.Advances in neural information processing systems, 32, 2019
Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl- Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent.Advances in neural information processing systems, 32, 2019
2019
-
[12]
A whac-a-mole dilemma: Shortcuts come in multiples where mitigating one amplifies others
Zhiheng Li, Ivan Evtimov, Albert Gordo, Caner Hazirbas, Tal Hassner, Cristian Canton Ferrer, Chenliang Xu, and Mark Ibrahim. A whac-a-mole dilemma: Shortcuts come in multiples where mitigating one amplifies others. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20071–20082, 2023
2023
-
[13]
Metashift: A dataset of datasets for evaluating contextual distri- bution shifts and training conflicts
Weixin Liang and James Zou. Metashift: A dataset of datasets for evaluating contextual distri- bution shifts and training conflicts. InInternational Conference on Learning Representations, 2022
2022
-
[14]
The global k-means clustering algorithm
Aristidis Likas, Nikos Vlassis, and Jakob J Verbeek. The global k-means clustering algorithm. Pattern recognition, 36(2):451–461, 2003
2003
-
[15]
Just train twice: Improving group robustness without training group information
Evan Z Liu, Behzad Haghgoo, Annie S Chen, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, and Chelsea Finn. Just train twice: Improving group robustness without training group information. InInternational Conference on Machine Learning, pages 6781–
-
[16]
Avoiding spurious correlations via logit correction.arXiv preprint arXiv:2212.01433, 2022
Sheng Liu, Xu Zhang, Nitesh Sekhar, Yue Wu, Prateek Singhal, and Carlos Fernandez-Granda. Avoiding spurious correlations via logit correction.arXiv preprint arXiv:2212.01433, 2022
-
[17]
Adyasha Maharana, Prateek Yadav, and Mohit Bansal. D2 pruning: Message passing for balancing diversity and difficulty in data pruning.arXiv preprint arXiv:2310.07931, 2023. 13
-
[18]
Severing spurious correlations with data pruning
Varun Mulchandani and Jung-Eun Kim. Severing spurious correlations with data pruning. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[19]
SGD on Neural Networks Learns Functions of Increasing Complexity
Preetum Nakkiran, Gal Kaplun, Dimitris Kalimeris, Tristan Yang, Benjamin L Edelman, Fred Zhang, and Boaz Barak. Sgd on neural networks learns functions of increasing complexity. arXiv preprint arXiv:1905.11604, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[20]
Learning from failure: De-biasing classifier from biased classifier.Advances in Neural Information Processing Systems, 33:20673–20684, 2020
Junhyun Nam, Hyuntak Cha, Sungsoo Ahn, Jaeho Lee, and Jinwoo Shin. Learning from failure: De-biasing classifier from biased classifier.Advances in Neural Information Processing Systems, 33:20673–20684, 2020
2020
-
[21]
Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186,
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
-
[22]
Asymptotics of sample eigenstructure for a large dimensional spiked covariance model.Statistica Sinica, pages 1617–1642, 2007
Debashis Paul. Asymptotics of sample eigenstructure for a large dimensional spiked covariance model.Statistica Sinica, pages 1617–1642, 2007
2007
-
[23]
Deep learning on a data diet: Finding important examples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
2021
-
[24]
GuanWen Qiu, Da Kuang, and Surbhi Goel. Complexity matters: Dynamics of feature learning in the presence of spurious correlations.arXiv preprint arXiv:2403.03375, 2024
-
[25]
Simple and fast group robustness by automatic feature reweighting
Shikai Qiu, Andres Potapczynski, Pavel Izmailov, and Andrew Gordon Wilson. Simple and fast group robustness by automatic feature reweighting. InInternational Conference on Machine Learning, pages 28448–28467. PMLR, 2023
2023
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[27]
Towards mem- orization estimation: Fast, formal and free
Deepak Ravikumar, Efstathia Soufleri, Abolfazl Hashemi, and Kaushik Roy. Towards mem- orization estimation: Fast, formal and free. InForty-second International Conference on Machine Learning, 2025
2025
-
[28]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[30]
Distributionally robust neural networks
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks. InInternational Conference on Learning Representations, 2020
2020
-
[31]
Upweighting easy samples in fine-tuning mitigates forgetting
Sunny Sanyal, Hayden Prairie, Rudrajit Das, Ali Kavis, and Sujay Sanghavi. Upweighting easy samples in fine-tuning mitigates forgetting. InForty-second International Conference on Machine Learning, 2025
2025
-
[32]
The pitfalls of simplicity bias in neural networks.Advances in Neural Information Processing Systems, 33:9573–9585, 2020
Harshay Shah, Kaustav Tamuly, Aditi Raghunathan, Prateek Jain, and Praneeth Netrapalli. The pitfalls of simplicity bias in neural networks.Advances in Neural Information Processing Systems, 33:9573–9585, 2020. 14
2020
-
[33]
No subclass left behind: Fine-grained robustness in coarse-grained classification problems.Advances in Neural Information Processing Systems, 33:19339–19352, 2020
Nimit Sohoni, Jared Dunnmon, Geoffrey Angus, Albert Gu, and Christopher R´ e. No subclass left behind: Fine-grained robustness in coarse-grained classification problems.Advances in Neural Information Processing Systems, 33:19339–19352, 2020
2020
-
[34]
Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Informa- tion Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Informa- tion Processing Systems, 35:19523–19536, 2022
2022
-
[35]
Group robust classification without any group information.Advances in Neural Information Processing Systems, 36:56553–56575, 2023
Christos Tsirigotis, Joao Monteiro, Pau Rodriguez, David Vazquez, and Aaron C Courville. Group robust classification without any group information.Advances in Neural Information Processing Systems, 36:56553–56575, 2023
2023
-
[36]
Deep learning generalizes because the parameter-function map is biased towards simple functions
Guillermo Valle-Perez, Chico Q Camargo, and Ard A Louis. Deep learning generalizes because the parameter-function map is biased towards simple functions.arXiv preprint arXiv:1805.08522, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Drop: Distributionally robust data pruning
Artem M Vysogorets, Kartik Ahuja, and Julia Kempe. Drop: Distributionally robust data pruning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[38]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
2011
-
[39]
On the effect of key factors in spurious correlation: A theoretical perspective
Yipei Wang and Xiaoqian Wang. On the effect of key factors in spurious correlation: A theoretical perspective. InInternational Conference on Artificial Intelligence and Statistics, pages 3745–3753. PMLR, 2024
2024
-
[41]
Nonlinear spiked covariance matrices and signal propagation in deep neural networks
Zhichao Wang, Denny Wu, and Zhou Fan. Nonlinear spiked covariance matrices and signal propagation in deep neural networks. InThe Thirty Seventh Annual Conference on Learning Theory, pages 4891–4957. PMLR, 2024
2024
-
[42]
Identifying spurious biases early in training through the lens of simplicity bias
Yu Yang, Eric Gan, Gintare Karolina Dziugaite, and Baharan Mirzasoleiman. Identifying spurious biases early in training through the lens of simplicity bias. InInternational conference on artificial intelligence and statistics, pages 2953–2961. PMLR, 2024
2024
-
[43]
arXiv preprint arXiv:2203.01517 , year=
Michael Zhang, Nimit S Sohoni, Hongyang R Zhang, Chelsea Finn, and Christopher R´ e. Correct-n-contrast: A contrastive approach for improving robustness to spurious correlations. arXiv preprint arXiv:2203.01517, 2022
-
[44]
Generalized cross entropy loss for training deep neural net- works with noisy labels.Advances in neural information processing systems, 31, 2018
Zhilu Zhang and Mert Sabuncu. Generalized cross entropy loss for training deep neural net- works with noisy labels.Advances in neural information processing systems, 31, 2018
2018
-
[45]
Coverage-centric coreset selection for high pruning rates
Haizhong Zheng, Rui Liu, Fan Lai, and Atul Prakash. Coverage-centric coreset selection for high pruning rates. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[46]
Places: An Image Database for Deep Scene Understanding
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Antonio Torralba, and Aude Oliva. Places: An image database for deep scene understanding.arXiv preprint arXiv:1610.02055, 2016. 15 Appendix A Related Work 17 B Theoretical Analysis 18 B.1 Homogeneous Spiked Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 B.2 Heterogeneous Spiked Model . ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
The network’s output function at initializationh(x;W 0) (which we refer to as the logit) becomes a draw from a Gaussian Process (Proposition 1 in [9])
-
[48]
The Neural Tangent KernelK(x, x ′;W) :=∇ Wh(x;W)· ∇ Wh(x′;W) converges to a deter- ministic, positive semi-definite kernelK(x, x ′) that is constant in time (Theorem 1 in [9])
-
[49]
The evolution of the logit outputsh(x i;W t) for thentraining samples under gradient flow for the empirical lossL(W) = 1 n Pn i=1 ℓ(yi, h(xi;W t)) is governed by an exact, deterministic, non-linear Ordinary Differential Equation (ODE) in function space (Theorem 2 in [9]). For a specific logith j(t)≡h(x j;W t), the dynamic is ∂h(xj;W t) ∂t =− 1 n nX i=1 K(...
-
[50]
Forj∈G 1 (majority group,y j =a j), the expected margin¯m t(xj)is positive, and the loss ℓ( ¯mt(xj))is less thanlog(2)
-
[51]
21 Proof.By Assumption 1, the initial expected logit is ¯h0(xj) = 0, so the initial expected margin is ¯m0(xj) = 0
Forj∈G 2 (minority group,y j =−a j), the expected margin¯mt(xj)is negative, and the loss ℓ( ¯mt(xj))is greater thanlog(2). 21 Proof.By Assumption 1, the initial expected logit is ¯h0(xj) = 0, so the initial expected margin is ¯m0(xj) = 0. We compute the initial time-derivative of the expected margin ∂¯mt(xj) ∂t t=0 =y j ∂¯hc t(xj) ∂t t=0 + ∂¯hs t(xj) ∂t t...
-
[52]
The initial velocity isR c +R s = βc 2 + βs(2α−1) 2 >0
Forj∈G 1,y jaj = 1. The initial velocity isR c +R s = βc 2 + βs(2α−1) 2 >0. Since ¯m0(xj) = 0 and ∂¯mt(xj) ∂t t=0 >0, there existsT 1 >0 such that ¯m t(xj)>0 fort∈(0, T 1). Thus, ℓ( ¯mt(xj))< ℓ(0) = log(2)
-
[53]
hard” (lowβ) and “easy
Forj∈G 2,y jaj =−1. The initial velocity isR c−Rs = βc 2 − βs(2α−1) 2 <0 by the simplicity bias condition. Since ¯m0(xj) = 0 and ∂¯mt(xj) ∂t t=0 <0, there existsT 2 >0 such that ¯m t(xj)<0 fort∈(0, T 2). Thus,ℓ( ¯mt(xj))> ℓ(0) = log(2). LetT= min(T 1, T2). Fort∈(0, T), both statements hold. The following theorem characterizes the initial curvature of the ...
-
[54]
High-Dimensional Statistics A Non-Asymptotic Viewpoint
Therefore, the functionσ ′ :R→Ris uniformly L-Lipschitz continuous. Applying the Gaussian Lipschitz concentration inequality (see Chapter 2.3 and Theorem 2.26 in the book “High-Dimensional Statistics A Non-Asymptotic Viewpoint” by Martin J. Wainwright) for the functionσ ′ evaluated on the Gaussian random variableZyields the stated exponential tail bound w...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.