EHRNote-ChatQA: A Benchmark for Evidence-Grounded Multi-Turn Clinical Question Answering over Longitudinal Discharge Summaries
Pith reviewed 2026-06-27 04:34 UTC · model grok-4.3
The pith
EHRNote-ChatQA introduces the first benchmark requiring LLMs to answer multi-turn clinical questions over multiple patient discharge summaries while grounding each answer in explicit evidence from the notes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
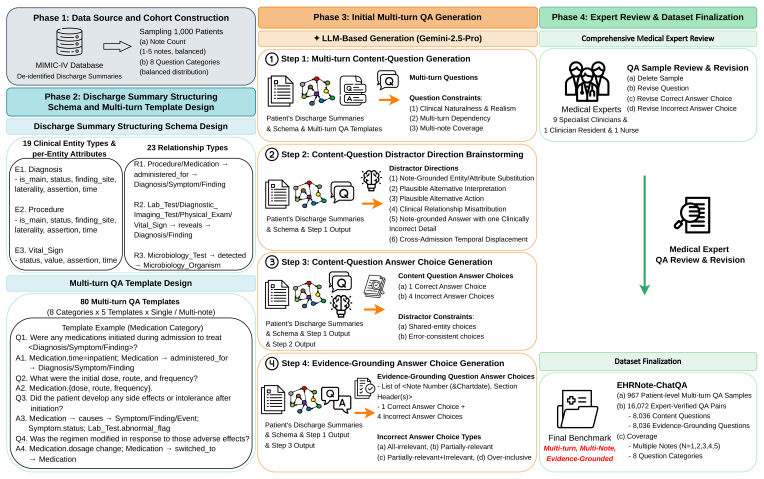
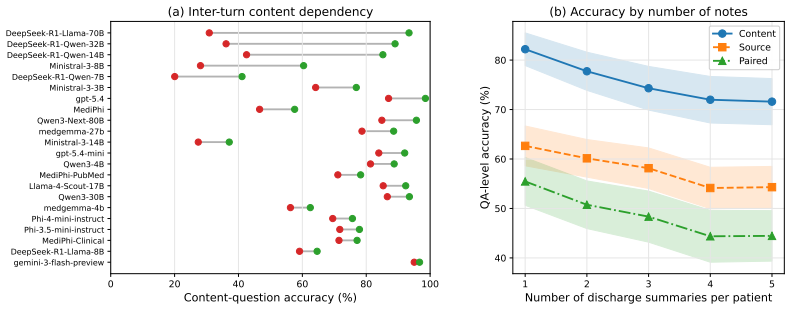
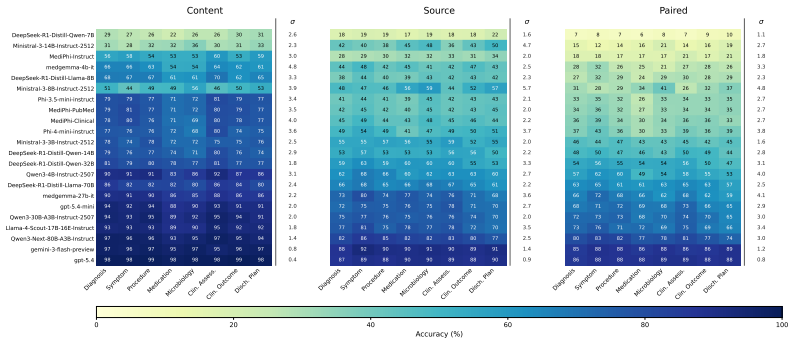
EHRNote-ChatQA is the first benchmark for evidence-grounded multi-turn clinical question answering over patients' multiple discharge summaries; it contains 967 patient-level samples and 16,072 medical-expert-verified QA pairs, and evaluation of 22 LLMs shows that models struggle more with evidence grounding than content answering, that multi-turn errors compound across turns, and that single-turn clinical QA performance does not reliably transfer to this setting.
What carries the argument
The expert-informed pipeline that combines a discharge-summary structuring schema, expert-curated multi-turn QA templates, LLM-based generation, and review/revision of every QA sample by medical experts to produce paired content and evidence-grounding questions.
If this is right
- LLMs require separate mechanisms to locate and cite evidence across multiple notes rather than relying on parametric knowledge alone.
- Error rates in multi-turn clinical dialogues increase with each additional turn, demanding explicit tracking of conversation state and prior evidence.
- Single-turn benchmarks underestimate the difficulty of longitudinal clinical QA and cannot serve as reliable proxies for this setting.
- The paired content-plus-evidence question format allows diagnosis of whether models fail at retrieval, citation, or synthesis.
- Future clinical QA systems must be evaluated on both answer accuracy and evidence faithfulness to match expert review workflows.
Where Pith is reading between the lines
- Extending the benchmark to include other note types such as progress notes or operative reports could test whether the observed challenges generalize beyond discharge summaries.
- Training or retrieval methods that explicitly link answers to note spans might reduce the grounding gap identified in the evaluations.
- The benchmark's design could inform development of clinician-facing tools that surface both answers and source evidence during patient record review.
- Similar paired-question structures might apply to non-clinical longitudinal text tasks such as legal case analysis or financial report synthesis.
Load-bearing premise
The expert-reviewed QA pairs accurately reflect the iterative synthesis and evidence verification that medical experts perform when reviewing multiple discharge summaries.
What would settle it
A controlled comparison showing that models ranked by single-turn clinical QA performance maintain the same ranking order and error patterns on the multi-turn evidence-grounded samples in EHRNote-ChatQA.
Figures





read the original abstract
Discharge summaries are crucial clinical documents containing the context of a patient's overall hospital stay, and are routinely reviewed by medical experts for patient readmission, ongoing care, and diagnostic decision-making. When reviewing them, medical experts often must iteratively synthesize information across multiple summaries while verifying the evidence supporting each answer. Although large language models (LLMs) are increasingly explored for clinical question answering, existing benchmarks do not sufficiently reflect this setting: they often evaluate exam-style medical knowledge or focus on single-turn question answering with limited evidence-grounding evaluation. We introduce EHRNote-ChatQA, the first benchmark for evidence-grounded multi-turn clinical question answering over patients' multiple discharge summaries. Built from de-identified MIMIC-IV discharge summaries, EHRNote-ChatQA contains 967 patient-level multi-turn samples spanning one to five notes and 16,072 medical-expert-verified QA pairs (8,036 content questions, each paired with an evidence-grounding question) across eight clinical categories. The benchmark is constructed through an expert-informed pipeline combining discharge-summary structuring schema, expert-curated multi-turn QA templates, and LLM-based generation, followed by review and revision of every single QA sample by 11 medical experts. Benchmarking 22 open- and closed-source LLMs reveals several challenges, including that LLMs struggle more with evidence grounding than content answering, multi-turn errors compound across turns, and single-turn clinical QA performance does not reliably transfer to this setting. These findings establish EHRNote-ChatQA as a rigorous and practical benchmark for evaluating clinical QA systems. The dataset will be made publicly available through PhysioNet credentialed access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EHRNote-ChatQA, the first benchmark for evidence-grounded multi-turn clinical question answering over longitudinal discharge summaries. Constructed from de-identified MIMIC-IV notes via an expert-informed pipeline (structuring schema, curated templates, LLM generation, and full review/revision by 11 medical experts), it comprises 967 patient-level multi-turn samples (1-5 notes) yielding 16,072 verified QA pairs (8,036 content questions each paired with an evidence-grounding question) across eight clinical categories. Benchmarking 22 LLMs reveals that models struggle more with evidence grounding than content answering, multi-turn errors compound, and single-turn clinical QA performance does not transfer reliably. The dataset will be released via PhysioNet.
Significance. If the QA pairs faithfully capture iterative evidence synthesis across multiple discharge summaries, the benchmark would fill a clear gap by providing a realistic, multi-turn, evidence-grounded evaluation setting that existing single-turn or exam-style medical QA datasets lack. The scale (967 patients, 16k pairs), expert verification of every sample, and public release are strengths; the reported LLM failure modes (grounding vs. content, error compounding) would be actionable for clinical NLP if the construction is validated.
major comments (1)
- [construction paragraph / abstract] Abstract and construction paragraph: the claim that the 16,072 pairs 'accurately reflect the iterative synthesis and evidence verification medical experts perform' rests on the pipeline of structuring schema + templates + LLM generation + review/revision by 11 experts, yet no inter-annotator agreement metrics, revision rate, or disagreement-resolution protocol are supplied. This is load-bearing for the central claim that measured LLM failures (evidence grounding > content answering, error compounding) reflect model limitations rather than residual benchmark artifacts.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address the major concern regarding the annotation process details below and plan to revise the manuscript to include additional information on the expert review.
read point-by-point responses
-
Referee: [construction paragraph / abstract] Abstract and construction paragraph: the claim that the 16,072 pairs 'accurately reflect the iterative synthesis and evidence verification medical experts perform' rests on the pipeline of structuring schema + templates + LLM generation + review/revision by 11 experts, yet no inter-annotator agreement metrics, revision rate, or disagreement-resolution protocol are supplied. This is load-bearing for the central claim that measured LLM failures (evidence grounding > content answering, error compounding) reflect model limitations rather than residual benchmark artifacts.
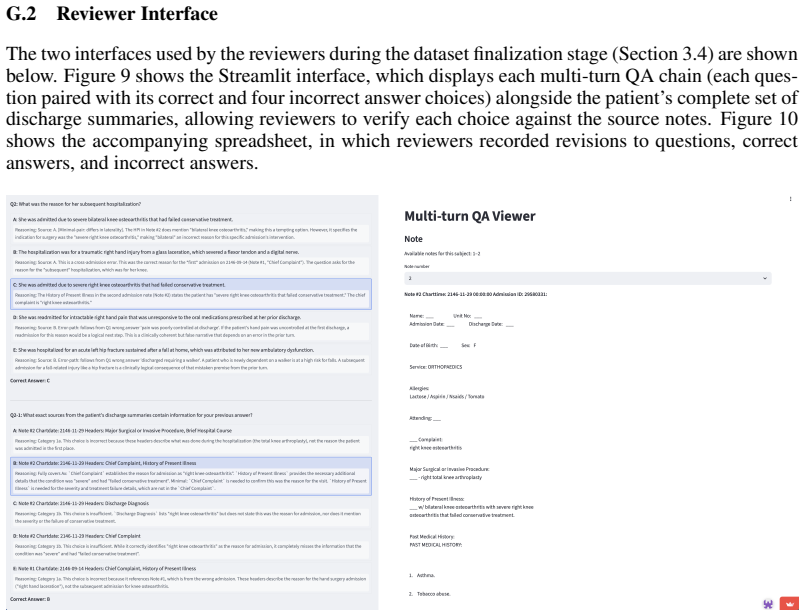
Authors: We acknowledge the importance of providing quantitative and procedural details on the expert verification process to substantiate our claims. In the revised manuscript, we will expand the 'Dataset Construction' section to include: (1) the disagreement-resolution protocol, which consisted of the 11 medical experts convening to discuss and resolve any differing opinions on QA pair accuracy and evidence grounding until consensus was reached; (2) the revision rate, which we will report based on internal logs of how many pairs were modified during review. For inter-annotator agreement, we note that the process involved a single comprehensive review pass by the expert team on all samples rather than multiple independent annotations, making traditional IAA metrics inapplicable. We will add this clarification and discuss it as a potential limitation. These revisions will strengthen the evidence that the benchmark faithfully captures expert-like iterative synthesis and that the reported LLM weaknesses are not artifacts of the construction process. revision: yes
Circularity Check
No circularity; benchmark construction and evaluation are self-contained
full rationale
The paper presents a new dataset (EHRNote-ChatQA) built via an expert-informed pipeline of structuring schema, templates, LLM generation, and expert review, followed by LLM benchmarking. No equations, fitted parameters, derivations, or self-citations appear in the provided text. Claims rest directly on the new 16,072 QA pairs and 22-model evaluations rather than reducing to prior fitted quantities or self-referential inputs by construction. This matches the default expectation for non-circular dataset papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption De-identified MIMIC-IV discharge summaries are representative of real clinical documentation and suitable for constructing QA benchmarks.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone, 2024.URL https://arxiv. org/abs/2404.14219, 2(6):4, 2024
Pith/arXiv arXiv 2024
-
[2]
Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Pith/arXiv arXiv 2024
-
[3]
Aaron Adcock, Aayushi Srivastava, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande, Abhinav Pandey, Abhinav Sharma, Abhishek Kadian, Abhishek Kumawat, Adam Kelsey, et al. The llama 4 herd: Architecture, training, evaluation, and deployment notes.arXiv preprint arXiv:2601.11659, 2026
arXiv 2026
-
[4]
Qam- pari: A benchmark for open-domain questions with many answers
Samuel Amouyal, Tomer Wolfson, Ohad Rubin, Ori Yoran, Jonathan Herzig, and Jonathan Berant. Qam- pari: A benchmark for open-domain questions with many answers. InProceedings of the third workshop on natural language generation, evaluation, and metrics (GEM), pages 97–110, 2023
2023
-
[5]
Bernd Bohnet, Vinh Q Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. Attributed question answering: Evaluation and modeling for attributed large language models.arXiv preprint arXiv:2212.08037, 2022
arXiv 2022
-
[6]
Quac: Question answering in context
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettle- moyer. Quac: Question answering in context. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2174–2184, 2018
2018
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[8]
A modular approach for clinical slms driven by synthetic data with pre-instruction tuning, model merging, and clinical-tasks alignment
Jean-Philippe Corbeil, Amin Dada, Jean-Michel Attendu, Asma Ben Abacha, Alessandro Sordoni, Lucas Caccia, François Beaulieu, Thomas Lin, Jens Kleesiek, and Paul V ozila. A modular approach for clinical slms driven by synthetic data with pre-instruction tuning, model merging, and clinical-tasks alignment. InProceedings of the 63rd Annual Meeting of the Ass...
2025
-
[9]
Answer- ing physicians’ clinical questions: obstacles and potential solutions.Journal of the American Medical Informatics Association, 12(2):217–224, 2005
John W Ely, Jerome A Osheroff, M Lee Chambliss, Mark H Ebell, and Marcy E Rosenbaum. Answer- ing physicians’ clinical questions: obstacles and potential solutions.Journal of the American Medical Informatics Association, 12(2):217–224, 2005
2005
-
[10]
Eli5: Long form question answering
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form question answering. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 3558–3567, 2019
2019
-
[11]
Medalign: A clinician- generated dataset for instruction following with electronic medical records
Scott L Fleming, Alejandro Lozano, William J Haberkorn, Jenelle A Jindal, Eduardo P Reis, Rahul Thapa, Louis Blankemeier, Julian Z Genkins, Ethan Steinberg, Ashwin Nayak, et al. Medalign: A clinician- generated dataset for instruction following with electronic medical records. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pag...
2024
-
[12]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465–6488, 2023
2023
-
[13]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforce- ment learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[14]
2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records.Journal of the American Medical Informatics Association, 27(1):3–12, 2020
Sam Henry, Kevin Buchan, Michele Filannino, Amber Stubbs, and Ozlem Uzuner. 2018 n2c2 shared task on adverse drug events and medication extraction in electronic health records.Journal of the American Medical Informatics Association, 27(1):3–12, 2020
2018
-
[15]
Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
2023
-
[16]
What dis- ease does this patient have? a large-scale open domain question answering dataset from medical exams
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What dis- ease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021. 11
2021
-
[17]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[18]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
2023
-
[19]
Mt-eval: A multi-turn capabilities evaluation benchmark for large language models
Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. Mt-eval: A multi-turn capabilities evaluation benchmark for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20153–20177, 2024
2024
-
[20]
Ehrnoteqa: An llm benchmark for real-world clinical practice using discharge summaries.Advances in Neural Information Processing Systems, 37:124575–124611, 2024
Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwanghyun Kim, Jeewon Yang, Seunghyun Won, and Edward Choi. Ehrnoteqa: An llm benchmark for real-world clinical practice using discharge summaries.Advances in Neural Information Processing Systems, 37:124575–124611, 2024
2024
-
[21]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gon- zalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[22]
Learning to ask like a physician
Eric Lehman, Vladislav Lialin, Katelyn Edelwina Legaspi, Anne Janelle Sy, Patricia Therese Pile, Nicole Rose Alberto, Richard Raymund Ragasa, Corinna Victoria Puyat, Marianne Katharina Taliño, Isabelle Rose Alberto, et al. Learning to ask like a physician. InProceedings of the 4th Clinical Natural Language Processing Workshop, pages 74–86, 2022
2022
-
[23]
Ministral 3.arXiv preprint arXiv:2601.08584, 2026
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
Pith/arXiv arXiv 2026
-
[24]
Capabilities of gpt-4 on medical challenge problems.arXiv preprint arXiv:2303.13375, 2023
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of gpt-4 on medical challenge problems.arXiv preprint arXiv:2303.13375, 2023
Pith/arXiv arXiv 2023
-
[25]
Medmcqa: A large-scale multi- subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi- subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[26]
Med-halt: Medical domain hallu- cination test for large language models
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Med-halt: Medical domain hallu- cination test for large language models. InProceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), pages 314–334, 2023
2023
-
[27]
emrqa: A large corpus for question answering on electronic medical records
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. emrqa: A large corpus for question answering on electronic medical records. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2357–2368, 2018
2018
-
[28]
Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
2019
-
[29]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[30]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[31]
Large language models encode clinical knowl- edge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowl- edge.Nature, 620(7972):172–180, 2023
2023
-
[32]
Radqa: A question answering dataset to improve comprehension of radiology reports
Sarvesh Soni, Meghana Gudala, Atieh Pajouhi, and Kirk Roberts. Radqa: A question answering dataset to improve comprehension of radiology reports. InProceedings of the thirteenth language resources and evaluation conference, pages 6250–6259, 2022. 12
2022
-
[33]
Overview of the archehr-qa 2025 shared task on grounded question answering from electronic health records
Sarvesh Soni, Soumya Gayen, and Dina Demner-Fushman. Overview of the archehr-qa 2025 shared task on grounded question answering from electronic health records. InProceedings of the 24th Workshop on Biomedical Language Processing, pages 396–405, 2025
2025
-
[34]
Asqa: Factoid questions meet long- form answers
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. Asqa: Factoid questions meet long- form answers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing, pages 8273–8288, 2022
2022
-
[35]
Evaluating temporal relations in clinical text: 2012 i2b2 challenge.Journal of the American Medical Informatics Association, 20(5):806–813, 2013
Weiyi Sun, Anna Rumshisky, and Ozlem Uzuner. Evaluating temporal relations in clinical text: 2012 i2b2 challenge.Journal of the American Medical Informatics Association, 20(5):806–813, 2013
2012
-
[36]
Extracting medication information from clinical text
Özlem Uzuner, Imre Solti, and Eithon Cadag. Extracting medication information from clinical text. Journal of the American Medical Informatics Association, 17(5):514–518, 2010
2010
-
[37]
2010 i2b2/va challenge on concepts, assertions, and relations in clinical text.Journal of the American Medical Informatics Association, 18(5): 552–556, 2011
Özlem Uzuner, Brett R South, Shuying Shen, and Scott L DuVall. 2010 i2b2/va challenge on concepts, assertions, and relations in clinical text.Journal of the American Medical Informatics Association, 18(5): 552–556, 2011
2010
-
[38]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[39]
recent EP study and ablation
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623, 2023. 13 Supplementary Contents A EHRNote-ChatQA Dataset Samples 15 B EHRNote-ChatQA vs. Prior Pa...
2023
-
[43]
the diagnosis
The answer. Multi-turn Reasoning Dependency (CRITICAL): The QA sequence must simulate stepwise clinical reasoning with narrative coherence, similar to how clinicians progressively review charts. Rules: - Q1 may introduce entities directly from the discharge summaries. - Q2 and later questions must reference entities introduced in previous answers. - Later...
-
[46]
What critical finding was discovered
For the coreference expressions, questions must not include descriptive modifiers that reveal the identity, category, mechanism, location, or clinical implication of the referenced entity. Questions must refer to entities without adding informative adjectives or phrases. Once an entity name appears in an earlier answer, the original name must not appear a...
-
[48]
Given the complicated hospital course,
Editorial framing clauses that characterize the course or outcome before asking. A leading clause like "Given the complicated hospital course, ..." or "Despite the eventual procedure, ..." asserts that the course was complicated or that a procedure occurred before the answer reveals 66 it. The fix is to drop the editorial clause: "What was the outcome of ...
-
[52]
you identified
Does the question still satisfy the Multi-turn Reasoning Dependency, Entity Reuse, and Coreference Expression Restrictions rules above (i.e., it back-references prior answer entities using only generic coreference expressions, and the back-referenced entity is genuinely ambiguous without the prior turn)? If no, restore the back-reference. 67 Template Dive...
-
[76]
Procedure/Medication -> reveals -> Diagnosis/Symptom/Finding 69
-
[94]
causes" and
(any category) -> has_instruction -> Instruction The difference between "causes" and "resulted_in" in "Procedure/Medication -> causes -> Diagnosis/ Symptom/Finding" and "Procedure/Medication -> resulted_in -> Outcome/Finding" is that "causes" is used when a procedure or medication produces an adverse effect or complication, while " resulted_in" is used wh...
-
[95]
A sequence of medical expert-style multi-turn questions
-
[96]
All entities, attributes, and relationships between entities extracted from the discharge summaries required to answer each corresponding question,
-
[97]
(Sufficient but minimal)
Source locations of the extracted entities, attributes, and relationships that compose the answer content. (Sufficient but minimal)
-
[98]
the diagnosis
The answer. Multi-turn Reasoning Dependency (CRITICAL): The QA sequence must simulate stepwise clinical reasoning with narrative coherence, similar to how clinicians progressively review charts. Rules: - Q1 may introduce entities directly from the discharge summaries. - Q2 and later questions must reference entities introduced in previous answers. - Later...
-
[99]
The question must not contain entity names copied directly from the discharge summary
-
[100]
the procedure
The question must refer to entities from the previous answer using coreference expressions, such as: - "the procedure", "the diagnosis", "the complication", "the finding", "the laboratory abnormality", "the imaging result", "the organism", "the treatment", "the intervention", "the outcome"
-
[101]
What critical finding was discovered
For the coreference expressions, questions must not include descriptive modifiers that reveal the identity, category, mechanism, location, or clinical implication of the referenced entity. Questions must refer to entities without adding informative adjectives or phrases. Once an entity name appears in an earlier answer, the original name must not appear a...
-
[102]
A new condition was identified during that admission. What intervention was performed for it?
Embedding the answer category as an asserted fact in the stem (declarative presupposition). The stem states that the entity to be revealed already exists, instead of asking whether it exists or what was done in a given scope. - e.g., "A new condition was identified during that admission. What intervention was performed for it?" --- both clauses presuppose...
-
[103]
Given the complicated hospital course,
Editorial framing clauses that characterize the course or outcome before asking. A leading clause like "Given the complicated hospital course, ..." or "Despite the eventual procedure, ..." asserts that the course was complicated or that a procedure occurred before the answer reveals it. The fix is to drop the editorial clause: "What was the outcome of tha...
-
[104]
a new condition was identified
Does the stem assert as fact something that the answer is supposed to reveal (e.g., "a new condition was identified", "the specific challenge in managing his medications", "the eventual procedure", "the critical finding that was discovered")? If yes, convert that clause into a yes /no opener or a neutral scope question
-
[105]
Given the complicated hospital course,
Does the stem contain a leading editorial framing clause that characterizes the course or outcome before asking (e.g., "Given the complicated hospital course, ...", "Despite the eventual procedure, ...")? If yes, drop the editorial clause
-
[106]
Could a clinician who has NOT yet read the relevant note section ask this question without already knowing what the answer will be? If no, rewrite until the answer would still be a genuine surprise to the asker
-
[107]
you identified
Does the question still satisfy the Multi-turn Reasoning Dependency, Entity Reuse, and Coreference Expression Restrictions rules above (i.e., it back-references prior answer entities using only generic coreference expressions, and the back-referenced entity is genuinely ambiguous without the prior turn)? If no, restore the back-reference. Template Diversi...
-
[108]
Diagnosis -- is_main, status, finding_site, laterality, assertion, time(dates, times, durations, frequencies) 74
-
[149]
causes" and
(any category) -> has_instruction -> Instruction The difference between "causes" and "resulted_in" in "Procedure/Medication -> causes -> Diagnosis/ Symptom/Finding" and "Procedure/Medication -> resulted_in -> Outcome/Finding" is that "causes" is used when a procedure or medication produces an adverse effect or complication, while " resulted_in" is used wh...
-
[150]
Identify the referenced entity or concept (applies to Q2 and later questions) For Q2 and later questions, identify: - which prior entity, concept, interpretation, or clinical finding the current question references - what plausible alternative interpretations of the referenced entity or concept could lead to a coherent but incorrect answer to the current ...
-
[151]
What condition did those findings support?
For Q2 and later questions only: Referential Ambiguity Analysis Explicitly identify what the pronoun or referent could alternatively resolve to if the model lacks prior context. For example: - If Q2 asks "What condition did those findings support?" and the patient has multiple documented abnormalities (stroke signs, syncope signs, metabolic abnormalities)...
-
[152]
error-consistent paths
For Q2 and later questions only: Cross-Turn Error Path Analysis Identify the 2 most clinically plausible incorrect answers from Q(n-1). For EACH, design a distractor at Q(n) that represents the natural clinical consequence if that prior wrong answer were true. Both error-path distractors must be carried forward as high-priority distractor directions into ...
-
[153]
long-term warfarin for a suspected hypercoagulable state
Generate distractor-design guidance For each distractor type listed below, describe how a plausible incorrect answer could be constructed using: - Note-grounded details combined in ways requiring clinical knowledge to reject (Source A) - Clinically plausible alternatives not in the notes (Source B) - The multi-turn QA context, including referential ambigu...
-
[154]
Note-grounded entity substitution with clinical reasoning requirement (Source A): Replace the correct entity, or one or more of its attributes (timing, dosage, laterality, severity, site, frequency, duration), with a related entity or attribute value drawn from the notes. The substitution must require clinical knowledge to reject --- the substitute entity...
-
[155]
This type represents a competing EXPLANATION for the clinical picture --- what the diagnosis is, what caused it, what the condition is, or what the drug class strategy is for
Clinically plausible alternative approach, standard-of-care variant, or parallel pathway (Source B): Propose an alternative interpretation, diagnosis, etiology, or approach that is NOT in the notes but is clinically plausible given the patient’s presentation. This type represents a competing EXPLANATION for the clinical picture --- what the diagnosis is, ...
-
[156]
What treatment was started?
Plausible-but-absent management action, intervention, or monitoring strategy (Source B): Propose an action, order, intervention, or arrangement that is NOT documented but is clinically standard or guideline-appropriate for the patient’s conditions. This type represents a competing ACTION --- what was done about it, what could have been ordered, what agent...
-
[157]
Clinical relationship misattribution: causal, temporal, associative, or cross-admission (Source A or B): Construct a distractor that misassigns a clinical relationship --- either reversing a causal direction, misattributing an association, displacing a temporal sequence, or confusing events across admissions --- where rejecting the misattribution requires...
-
[158]
The correct elements make the distractor credible; the incorrect element requires 79 clinical knowledge to identify
Note-grounded detail with one external wrong element (Source A+B hybrid): Combine several correct clinical details from the notes with one incorrect element drawn from general medical knowledge. The correct elements make the distractor credible; the incorrect element requires 79 clinical knowledge to identify. The wrong element must not contradict any exp...
-
[159]
Cross-admission temporal displacement (Source A): For patients with multiple admissions, attribute a correct clinical fact to the wrong admission. The entities, relationships, and clinical content are all present in the notes; what makes the distractor wrong is that the detail belongs to a different admission than the one the question asks about. How this...
-
[160]
Source: State whether this is Source A (note-grounded with clinical reasoning requirement), Source B (clinically plausible external), or Source A+B hybrid
-
[161]
Explanation: A concise, specific description of how an incorrect answer choice could be constructed using that distractor type
-
[162]
This must cite: - For Source A distractors: the specific note content that grounds the distractor and what clinical knowledge is needed to reject it
Reasoning: A brief justification for why this distractor is plausible and why it cannot be eliminated by text matching alone. This must cite: - For Source A distractors: the specific note content that grounds the distractor and what clinical knowledge is needed to reject it. - For Source B distractors: the clinical basis and confirmation that this content...
-
[163]
[Minimal-pair: differs only in {specific detail}]
Minimal-pair label: If this direction is a minimal-pair distractor (differs from correct answer in exactly one clinical detail), label it: "[Minimal-pair: differs only in {specific detail}]". If it differs in multiple dimensions, label it: "[Multi-difference]". Do not write generic distractor advice. Make each explanation and reasoning specific to the con...
-
[174]
Microbiology_Test - organism_growth, result, assertion, time(dates, times, durations, frequencies)
-
[202]
Outcome/Finding -> after -> Procedure/Medication 82
-
[205]
causes" and
(any category) -> has_instruction -> Instruction The difference between "causes" and "resulted_in" in "Procedure/Medication -> causes -> Diagnosis/ Symptom/Finding" and "Procedure/Medication -> resulted_in -> Outcome/Finding" is that "causes" is used when a procedure or medication produces an adverse effect or complication, while " resulted_in" is used wh...
-
[206]
answer skeleton
Before writing the correct answer, mentally draft an "answer skeleton" --- the minimal statement that directly answers the question and nothing more. Use this skeleton as the ceiling for the correct answer. The correct answer may add at most one qualifying clause beyond the skeleton
-
[207]
After writing all 5 answer choices, verify that the correct answer is at or below the MEDIAN length of all 5 choices. If it is the longest, either: (a) Trim the correct answer by removing qualifiers, temporal context, secondary findings, or enumerations not strictly required to answer the question, OR (b) Expand at least 2 incorrect answers by adding plau...
-
[208]
INVERSE LENGTH REQUIREMENT: For approximately 1 in 5 questions, make the correct answer the SHORTEST choice, with at least 2 incorrect answers being noticeably more detailed. Achieve this by writing a concise factual correct answer and making 2+ distractors include plausible but unnecessary elaboration (additional clinical context, hedging language, multi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.