WARP-RM: A Warp-Augmented Relative Progress Reward Model for Data Curation
Pith reviewed 2026-06-29 03:52 UTC · model grok-4.3
The pith
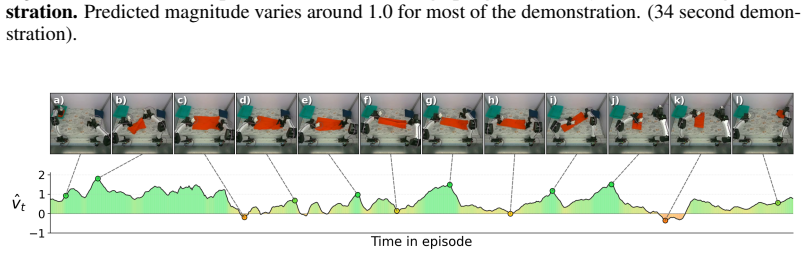
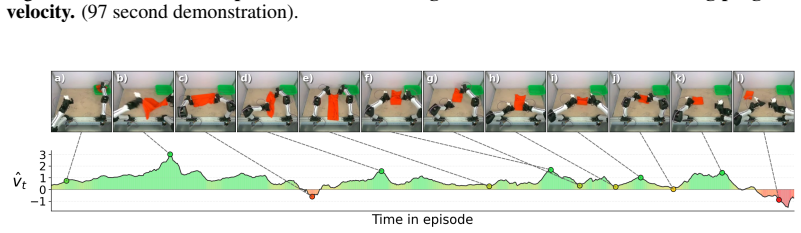
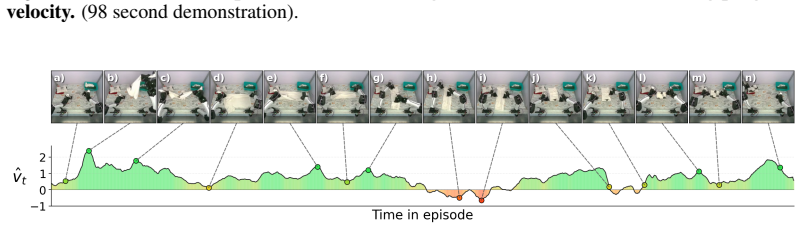
A self-supervised reward model using time-warp augmentations on demonstrations lets behavior cloning maintain 19/20 success on T-shirt folding even as training data grows more inefficient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
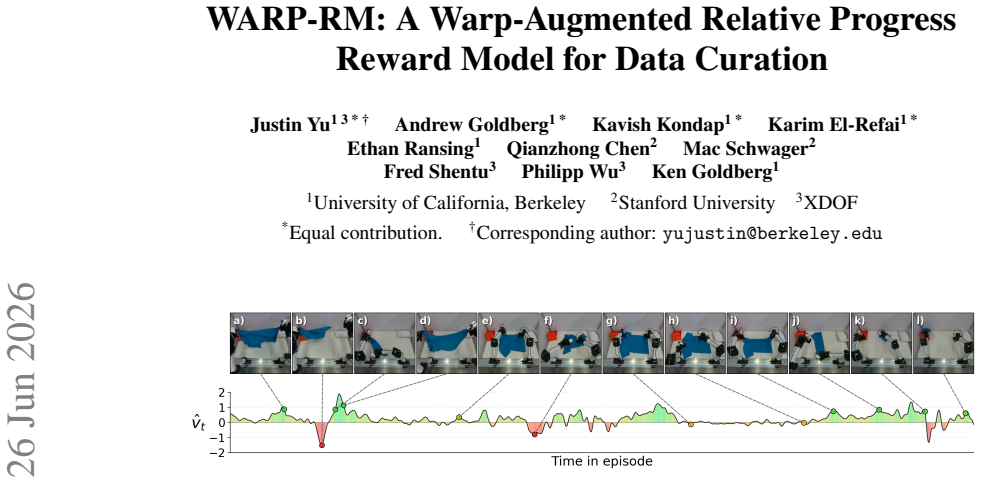
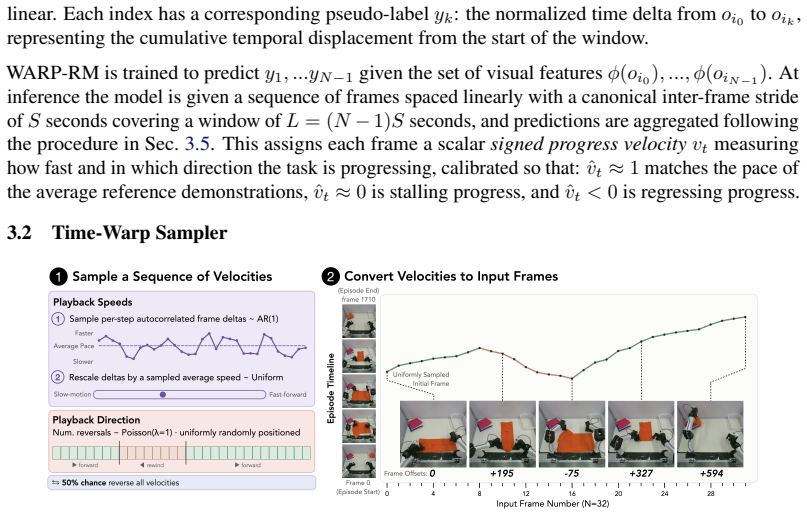
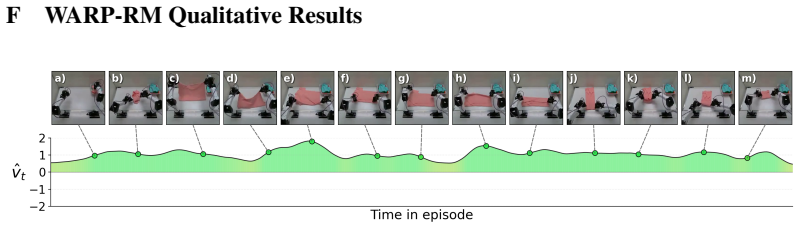
WARP generates per-frame progress targets via time-warp augmentations of demonstrations (variable playback speeds and reversals) and trains WARP-RM to predict the normalized elapsed time between input frames; aggregating these predictions across overlapping windows produces a dense signed progress signal that is then used to compute chunk-level advantage for upweighting actions in behavior cloning.
What carries the argument
WARP (Warp-Augmented Relative Progress) algorithm that creates signed relative progress targets from time-warp augmentations to train a model predicting normalized elapsed time between frames.
Load-bearing premise
Episode length is a sufficient proxy for teleoperation sub-optimality when constructing training datasets of varying quality for the T-shirt folding task.
What would settle it
A controlled experiment that varies dataset quality using a different proxy such as counted hesitations or recovery motions and finds that WARP-BC success rates drop to match those of vanilla behavior cloning would falsify the central claim.
Figures



read the original abstract
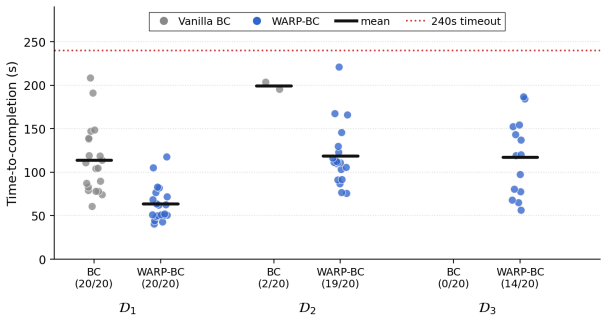
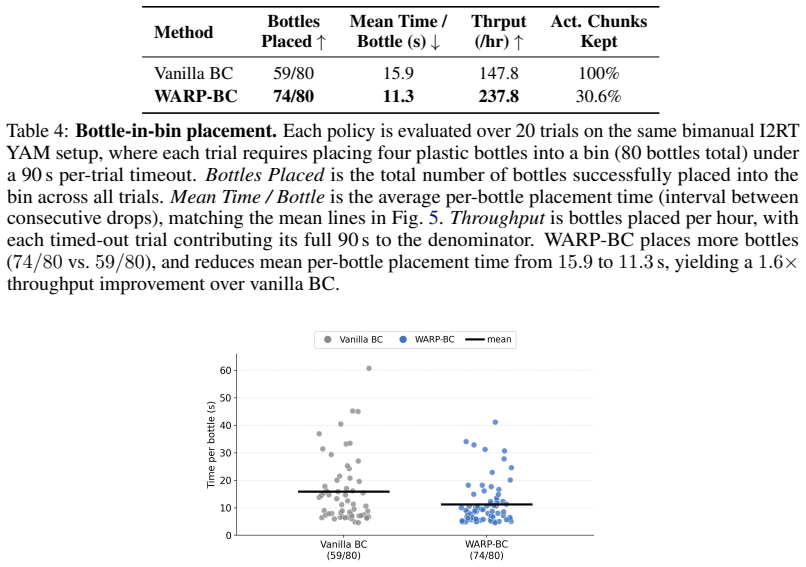
Scaling imitation learning requires large datasets, yet human teleoperation inevitably produces mixed-quality demonstrations containing hesitations and recoveries. Prior frame-level progress reward models supervise on absolute temporal progress proxies that suffer from label noise, or require costly human annotations to define subtask boundaries. We present WARP (Warp-Augmented Relative Progress), a novel fully self-supervised algorithm for learning dense, signed relative progress magnitudes directly from successful demonstrations. WARP generates per-frame progress targets via time-warp augmentations of demonstrations (variable playback speeds and reversals) and we train WARP-RM to predict the normalized elapsed time between input frames. Aggregating these predictions across overlapping windows yields a dense frame-level progress signal. We then introduce WARP-BC, which leverages these scalar reward estimates to upweight high-advantage action chunks during behavior cloning, where chunk-level advantage is obtained by aggregating per-frame rewards. We evaluate our approach on a physical bimanual robot system performing a long-horizon deformable object manipulation task: folding T-shirts from a random crumpled start. To evaluate policy robustness against suboptimal data, we construct training datasets of varying quality using episode length as a proxy for teleoperation sub-optimality. As the dataset is widened to admit more inefficiencies, WARP-BC maintains a 19/20 success rate compared to vanilla BC's collapse to 2/20, improving throughput by up to 18x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
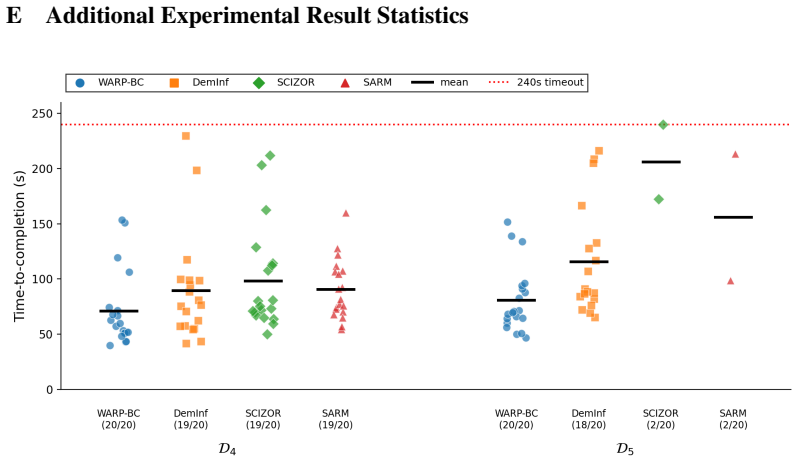
Summary. The paper presents WARP-RM, a self-supervised algorithm that learns dense signed relative progress rewards from successful demonstrations via time-warp augmentations (variable speeds and reversals), training a model to predict normalized elapsed time between frames. These rewards are aggregated to produce chunk-level advantages for upweighting actions in behavior cloning (WARP-BC). On a physical bimanual T-shirt folding task, datasets of varying quality are constructed by widening to include longer episodes (proxy for sub-optimality); WARP-BC maintains 19/20 success while vanilla BC drops to 2/20, with up to 18x throughput gains.
Significance. If the central robustness result holds under controlled conditions, the method offers a fully self-supervised route to dense progress signals that could improve data curation and policy performance in imitation learning for long-horizon deformable manipulation without requiring subtask annotations or external labels.
major comments (2)
- [Evaluation] Evaluation section: the headline robustness claim (19/20 vs 2/20 success as datasets widen) rests on episode length as a proxy for teleoperation sub-optimality (hesitations/recoveries); no validation is reported that length correlates with those behaviors rather than initial-state variation, execution speed, or task-intrinsic factors in the crumpled T-shirt setup, leaving the controlled comparison between WARP-BC and BC open to confounding.
- [Methods] Methods: the aggregation of per-frame progress predictions into chunk-level advantage (used for upweighting in BC) is described at a high level; without explicit equations or pseudocode showing the windowing, normalization, and advantage computation, it is difficult to verify that the signal isolates progress magnitude independently of the time-warp training objective.
minor comments (1)
- [Abstract] Abstract and introduction: the phrase 'normalized elapsed time between input frames' could be clarified with respect to the sign and range of the learned targets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of a fully self-supervised approach to dense progress signals in imitation learning. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline robustness claim (19/20 vs 2/20 success as datasets widen) rests on episode length as a proxy for teleoperation sub-optimality (hesitations/recoveries); no validation is reported that length correlates with those behaviors rather than initial-state variation, execution speed, or task-intrinsic factors in the crumpled T-shirt setup, leaving the controlled comparison between WARP-BC and BC open to confounding.
Authors: We acknowledge the concern that episode length serves as an indirect proxy and that explicit validation of its correlation with hesitations and recoveries (versus other factors) is not provided in the current manuscript. In the T-shirt folding setup, initial states are drawn from the same randomized distribution for all dataset widths, and the task geometry and physics remain fixed; thus longer episodes predominantly reflect additional recovery actions rather than changes in start configuration or intrinsic task difficulty. Nevertheless, to address the potential for confounding, we will add a supplementary analysis in the revision that includes (i) qualitative trajectory inspection showing increased hesitation segments in longer episodes and (ii) a simple correlation between episode length and the number of recovery actions manually annotated on a subset of demonstrations. This will strengthen the controlled comparison. revision: yes
-
Referee: [Methods] Methods: the aggregation of per-frame progress predictions into chunk-level advantage (used for upweighting in BC) is described at a high level; without explicit equations or pseudocode showing the windowing, normalization, and advantage computation, it is difficult to verify that the signal isolates progress magnitude independently of the time-warp training objective.
Authors: We agree that the aggregation procedure is currently described at a high level and would benefit from greater formality. In the revised manuscript we will insert explicit equations for (a) the sliding-window aggregation of per-frame normalized elapsed-time predictions, (b) the normalization step that converts raw predictions into signed relative progress, and (c) the subsequent computation of chunk-level advantage used for action upweighting. We will also include pseudocode that makes clear the separation between the time-warp training objective and the downstream advantage signal derived from the learned progress magnitudes. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a self-supervised method where time-warp augmentations explicitly generate per-frame progress targets (normalized elapsed time) for training WARP-RM, which are then aggregated into rewards for weighting in BC. This construction is independent and does not reduce by definition or fit to its own outputs. Dataset construction via episode length as proxy is an explicit evaluation assumption rather than a load-bearing derivation step. No self-citations, uniqueness theorems, or renamings of known results are invoked as the central justification. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Successful demonstrations contain recoverable progress signals that can be extracted via temporal augmentations without external labels.
invented entities (1)
-
WARP-RM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control. InProceedings of Robotics: ...
2025
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[4]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[5]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
- [6]
-
[7]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[8]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[9]
L. Fu, H. Huang, G. Datta, L. Y . Chen, W. C.-H. Panitch, F. Liu, H. Li, and K. Goldberg. In-context imitation learning via next-token prediction.arXiv preprint arXiv:2408.15980, 2024
arXiv 2024
-
[10]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), volume 164 ofProceedings of Machine Learning Research. PMLR, 2021. 10
2021
-
[11]
Beliaev, A
M. Beliaev, A. Shih, S. Ermon, D. Sadigh, and R. Pedarsani. Imitation learning by estimating expertise of demonstrators. InInternational Conference on Machine Learning, pages 1732–1748. PMLR, 2022
2022
-
[12]
D. S. Brown, W. Goo, and S. Niekum. Better-than-demonstrator imitation learning via automatically-ranked demonstrations. InConference on robot learning, pages 330–359. PMLR, 2020
2020
-
[13]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artifi- cial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[14]
H. Liu, S. Nasiriany, L. Zhang, Z. Bao, and Y . Zhu. Robot learning on the job: Human-in- the-loop autonomy and learning during deployment. InRobotics: Science and Systems (RSS), 2023
2023
-
[15]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel. Robocopilot: Human-in-the-loop interactive imitation learning for robot manipulation, 2025
2025
-
[16]
Q. Li, Z. Peng, and B. Zhou. Efficient learning of safe driving policy via human-ai copilot optimization.arXiv preprint arXiv:2202.10341, 2022
arXiv 2022
-
[17]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[18]
C. Agia, R. Sinha, J. Yang, R. Antonova, M. Pavone, H. Nishimura, M. Itkina, and J. Bohg. Cupid: Curating data your robot loves with influence functions. InConference on Robot Learning (CoRL), volume 305 ofProceedings of Machine Learning Research, pages 2907–2932. PMLR, 2025
2025
-
[19]
Hejna, S
J. Hejna, S. Mirchandani, A. Balakrishna, A. Xie, A. Wahid, J. Tompson, P. Sanketi, D. Shah, C. Devin, and D. Sadigh. Robot data curation with mutual information estimators. InProceed- ings of Robotics: Science and Systems (RSS), 2025
2025
-
[20]
H. Lee, T. Min, J. Kim, S. Kang, F. Liu, L. Pinto, and K. Lee. Quality over quantity: Demonstration curation via influence functions for data-centric robot learning.arXiv preprint arXiv:2603.09056, 2026
arXiv 2026
-
[21]
Zhang, Y
J. Zhang, Y . Luo, A. Anwar, S. A. Sontakke, J. J. Lim, J. Thomason, E. Bıyık, and J. Zhang. Rewind: Language-guided rewards teach robot policies without new demonstrations. In Conference on Robot Learning, 2025
2025
-
[22]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. InInternational Conference on Learning Representations, 2023
2023
-
[23]
Y . J. Ma, W. Liang, V . Somani, B. Stadie, O. Bastani, D. Jayaraman, A. Zhang, S. Sodhani, and V . Kumar. Liv: Language-image representations and rewards for robotic control. In International Conference on Machine Learning. PMLR, 2023
2023
-
[24]
Dwibedi, Y
D. Dwibedi, Y . Aytar, J. Tompson, P. Sermanet, and A. Zisserman. Temporal cycle-consistency learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 1801–1810, 2019
2019
-
[25]
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation. InInternational Conference on Learning Representations (ICLR), 2026. 11
2026
-
[26]
Y . Mao, Z. Yu, W. Mao, Y . Li, Q. Hu, Z. Lan, M. Zhu, and H. Chen. Arm: Advantage reward modeling for long-horizon manipulation.arXiv preprint arXiv:2604.03037, 2026
Pith/arXiv arXiv 2026
-
[27]
Y . Yao, C. Liu, D. Luo, Y . Zhou, and Q. Ye. Video playback rate perception for self-supervised spatio-temporal representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[28]
J. Wang, J. Jiao, and Y . Liu. Self-supervised video representation learning by pace prediction. InEuropean Conference on Computer Vision, 2020
2020
-
[29]
P. Chen, D. Huang, D. He, X. Long, R. Zeng, S. Wen, M. Tan, and C. Gan. Rspnet: Relative speed perception for unsupervised video representation learning. InThe AAAI Conference on Artificial Intelligence (AAAI), 2021
2021
-
[30]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
D. Huang, W. Hu, X. Liu, D. He, Z. Wu, X. Wu, M. Tan, and E. Ding. Ascnet: Self- supervised video representation learning with appearance-speed consistency. InThe IEEE/CVF International Conference on Computer Vision (ICCV), pages 8076–8085, 10 2021. doi: 10.1109/ICCV48922.2021.00799
-
[31]
I. R. Dave, S. Jenni, and M. Shah. No more shortcuts: Realizing the potential of tempo- ral self-supervision.Proceedings of the AAAI Conference on Artificial Intelligence, 38(2): 1481–1491, Mar. 2024. doi:10.1609/aaai.v38i2.27913. URL https://ojs.aaai.org/index. php/AAAI/article/view/27913
- [32]
-
[33]
Hejna, C
J. Hejna, C. Bhateja, Y . Jiang, K. Pertsch, and D. Sadigh. Re-mix: Optimizing data mixtures for large scale imitation learning. InConference on Robot Learning (CoRL), volume 270 of Proceedings of Machine Learning Research, pages 145–164. PMLR, 2024
2024
-
[34]
Zhang, Y
Y . Zhang, Y . Xie, H. Liu, R. Shah, M. Wan, L. Fan, and Y . Zhu. Scizor: A self-supervised approach to data curation for large-scale imitation learning. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[35]
Liang, Y
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. InProceedings of Robotics: Science and Systems (RSS), 2026
2026
-
[36]
S. Chen, C. Harrison, Y .-C. Lee, A. J. Yang, Z. Ren, L. J. Ratliff, J. Duan, D. Fox, and R. Krishna. Topreward: Token probabilities as hidden zero-shot rewards for robotics.arXiv preprint arXiv:2602.19313, 2026
arXiv 2026
-
[37]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, et al. Robo-dopamine: General process reward modeling for high-precision robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[38]
Liang, R
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. A. Cosgrove, C. D. Manning, C. Re, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. WANG, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. G...
2023
-
[39]
J. Farebrother, J. Orbay, Q. Vuong, A. A. Ta ¨ıga, Y . Chebotar, T. Xiao, A. Irpan, S. Levine, P. S. Castro, A. Faust, A. Kumar, and R. Agarwal. Stop regressing: Training value functions via classification for scalable deep rl. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pa...
-
[40]
O. Sim´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. Dinov3, 2025. URL https://arxiv.org/abs...
Pith/arXiv arXiv 2025
-
[41]
put the plastic bottles in the bin
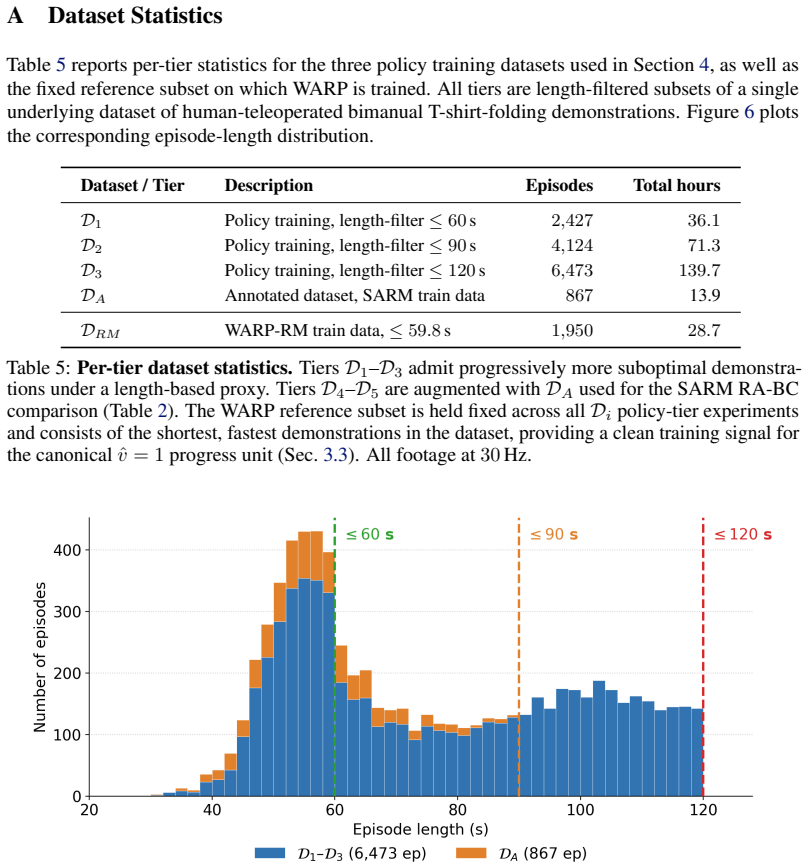
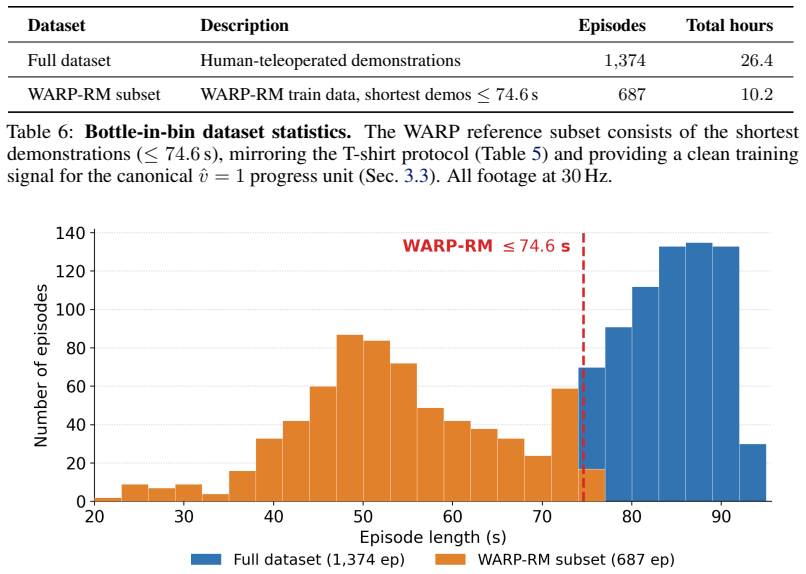
J. Grigsby and Y . Qi. A closer look at advantage-filtered behavioral cloning in high-noise datasets, 2023. URLhttps://arxiv.org/abs/2110.04698. 13 A Dataset Statistics Table 5 reports per-tier statistics for the three policy training datasets used in Section 4, as well as the fixed reference subset on which W ARP is trained. All tiers are length-filtered...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.