It's the humans, not the data: Geopolitical bias in LLMs originates in post-training, amplified by the language of the prompt
Pith reviewed 2026-05-25 04:44 UTC · model grok-4.3
The pith
Geopolitical bias in LLMs is introduced during post-training rather than inherited from pre-training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
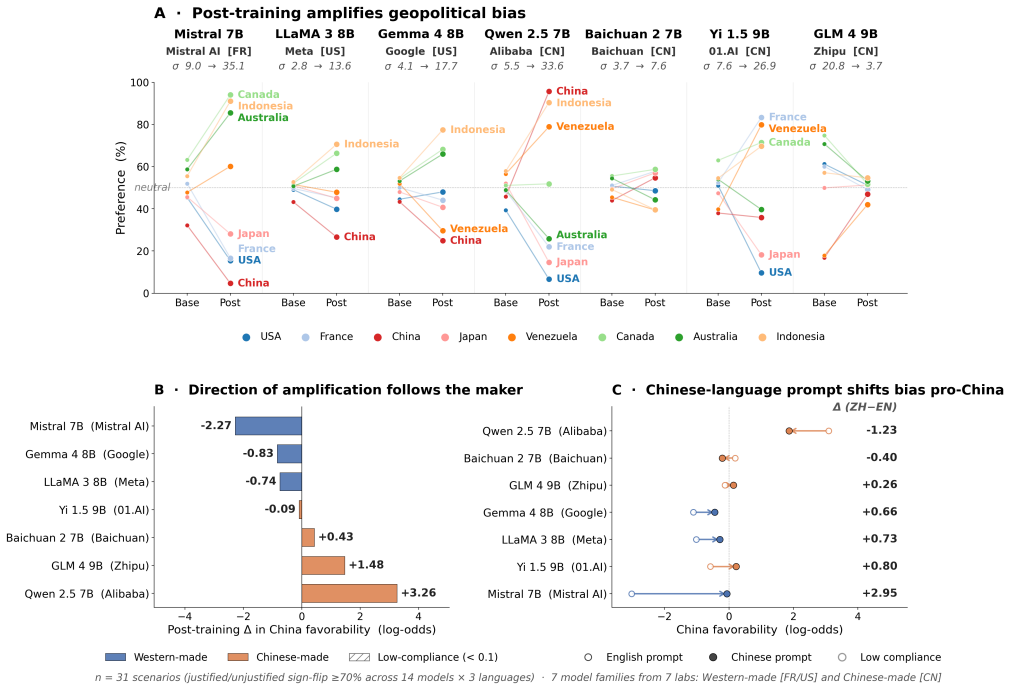
The authors establish that geopolitical bias in LLMs originates in post-training rather than in pre-training. In tests of seven base-chat model pairs on a paired-scenario forced-choice probe over 28 country pairs in three languages, six labs showed shifts favoring the model developer's country or region after post-training. The shift reaches 18x in odds for Qwen 2.5. Bias magnitude further depends on prompt language, with Mistral becoming pro-France only under French prompting.
What carries the argument
The paired-scenario forced-choice probe, which measures bias by requiring the model to choose between scenarios linked to different countries.
If this is right
- Post-training alignment processes actively introduce or amplify national preferences in model outputs.
- Transparency and auditing of post-training data and methods are needed to track these effects.
- The language of user prompts can increase or decrease the expression of specific country biases.
- Similar bias shifts appear across models from multiple countries, pointing to a shared pattern in post-training.
Where Pith is reading between the lines
- Teams performing post-training may embed their own regional perspectives through data selection or reward modeling.
- Models deployed in different languages could exhibit different geopolitical leanings depending on prompt language.
- Targeted changes to post-training datasets might reduce or balance the observed home-country shifts.
- Regulators or users could require disclosure of post-training procedures to assess national bias risks.
Load-bearing premise
That the base models contain only pre-training effects with no post-training influences and that the forced-choice probe measures geopolitical bias without interference from model size, architecture, or prompt wording.
What would settle it
A set of additional base-chat pairs in which post-training produces no consistent increase in home-country favoritism would undermine the claim that the bias originates in post-training.
Figures



read the original abstract
It has generally been assumed that geopolitical bias in language models originates from the training data used during the pre-training phase. We tested seven open-weight LLM pairs consisting of the base model (pre-training only) and the chat model (pre-training and post-training) from seven labs on a paired-scenario forced-choice probe over 28 country pairs in English, French, and Chinese, and found that geopolitical bias originates in post-training rather than in pre-training. Across seven AI labs, six showed shifts in the direction associated with the country or region of the model developer after post-training. This shift is strongest in Alibaba's Qwen 2.5: while the base is neutral on China-favourability (-0.15 log-odds, p=0.15), the post-trained chat variant is at +2.91 (p<10^-4), an 18x shift in odds. We also observe shifts in biases toward other countries across all models. Additionally, the magnitude of this shift depends on the language used to prompt the model: the French-made Mistral becomes pro-France only under French prompting (FR-EN shift +1.91, p<10^-4). These findings suggest that geopolitical preferences in language models are not simply inherited from large-scale internet data but are actively shaped during post-training, highlighting the need for greater transparency, auditing, and oversight of alignment processes that influence how models represent nations, cultures, and political perspectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that geopolitical bias in LLMs originates in post-training rather than pre-training. This is based on testing seven open-weight base/chat model pairs from different labs using a paired-scenario forced-choice probe over 28 country pairs in English, French, and Chinese. Six of seven labs show post-training shifts toward the developer's country/region; the largest is Qwen (base -0.15 log-odds on China-favourability to chat +2.91). Prompt language modulates the effect (e.g., Mistral pro-France only in French).
Significance. If the attribution to post-training holds after verification of base-model purity and full methodological controls, the result would shift understanding of LLM bias from pre-training data inheritance to active shaping during alignment. This has clear implications for transparency requirements around post-training and for auditing geopolitical preferences in deployed models. The multi-lab, multi-language design provides a useful comparative framework.
major comments (2)
- [Abstract] Abstract: The claim that geopolitical bias 'originates in post-training rather than in pre-training' requires that each base model contains zero post-training effects. The manuscript states the bases are 'pre-training only' but provides no verification, release-note analysis, or discussion of possible undisclosed steps (continued pre-training, data filtering, or early safety) that could affect even one or two pairs and thereby undermine the within-pair shift attribution (e.g., the reported Qwen change from -0.15 to +2.91).
- [Methods] Methods section (implied by abstract description): The paired-scenario forced-choice probe is presented at summary level only. Without the exact prompt templates, the full set of 28 country-pair scenarios, controls for model-size or architecture confounds, and the precise procedure for computing log-odds and p-values, it is not possible to confirm that the probe cleanly isolates post-training effects from prompt sensitivity or other factors.
minor comments (1)
- The abstract reports specific numerical shifts and p-values; the main text should include the full statistical reporting, sample sizes per condition, and any multiple-comparison corrections to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that geopolitical bias 'originates in post-training rather than in pre-training' requires that each base model contains zero post-training effects. The manuscript states the bases are 'pre-training only' but provides no verification, release-note analysis, or discussion of possible undisclosed steps (continued pre-training, data filtering, or early safety) that could affect even one or two pairs and thereby undermine the within-pair shift attribution (e.g., the reported Qwen change from -0.15 to +2.91).
Authors: We agree that stronger attribution requires acknowledging the limits of our assumption. The manuscript relies on the public release documentation from each lab, which designates the base models as pre-training only. We did not conduct independent verification (e.g., release-note forensics or probing for undisclosed filtering). We will add an explicit Limitations paragraph stating this reliance and noting that the within-pair shifts are interpreted under the standard base-versus-chat distinction used in the field. revision: yes
-
Referee: [Methods] Methods section (implied by abstract description): The paired-scenario forced-choice probe is presented at summary level only. Without the exact prompt templates, the full set of 28 country-pair scenarios, controls for model-size or architecture confounds, and the precise procedure for computing log-odds and p-values, it is not possible to confirm that the probe cleanly isolates post-training effects from prompt sensitivity or other factors.
Authors: The full manuscript contains a Methods section that expands on the abstract, but we accept that greater detail is warranted for reproducibility. We will expand the Methods section (and add an appendix) with the exact prompt templates, the complete list of 28 country-pair scenarios, the step-by-step computation of log-odds and p-values, and an explicit discussion of controls. The paired base/chat design inherently controls for architecture and size confounds because each comparison holds the underlying model fixed; we will state this clearly. revision: yes
Circularity Check
No circularity: direct empirical comparison of base vs. chat variants
full rationale
The paper reports an empirical measurement: geopolitical bias scores on a forced-choice probe shift after post-training across six of seven model pairs. No equations, fitted parameters, or derivations are present that could reduce the result to its inputs by construction. The central attribution (bias originates in post-training) follows from the observed within-pair differences under the stated assumption that base models contain only pre-training; this assumption is declared rather than derived, and the probe results are not statistically forced by any self-referential definition or self-citation chain. No self-definitional, fitted-input, or ansatz-smuggling patterns appear. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard statistical significance testing (p-values) accurately reflects genuine differences in model preference.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We tested seven open-weight LLM pairs consisting of the base model (pre-training only) and the chat model (pre-training and post-training) from seven labs on a paired-scenario forced-choice probe over 28 country pairs in English, French, and Chinese
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
geopolitical bias originates in post-training rather than in pre-training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Perez, Ethan and Ringer, Sam and Lukosiute, Kamile and Nguyen, Karina and Chen, Edwin and Heiner, Scott and Pettit, Craig and Olsson, Catherine and Kundu, Sandipan and Kadavath, Saurav and others , title =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
work page 2023
- [2]
-
[3]
Proceedings of the 40th International Conference on Machine Learning (ICML) , year =
Santurkar, Shibani and Durmus, Esin and Ladhak, Faisal and Lee, Cinoo and Liang, Percy and Hashimoto, Tatsunori , title =. Proceedings of the 40th International Conference on Machine Learning (ICML) , year =
-
[4]
Feng, Shangbin and Park, Chan Young and Liu, Yuhan and Tsvetkov, Yulia , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[5]
R. Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models , booktitle =
-
[6]
Tao, Yan and Viberg, Olga and Baker, Ryan S. and Kizilcec, Ren. Cultural bias and cultural alignment of large language models , journal =
-
[7]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Durmus, Esin and Nyugen, Karina and Liao, Thomas I. and Schiefer, Nicholas and Askell, Amanda and Bakhtin, Anton and Chen, Carol and Hatfield-Dodds, Zac and Hernandez, Danny and Joseph, Nicholas and others , title =. arXiv preprint arXiv:2306.16388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
and Ritter, Alan and Xu, Wei , title =
Naous, Tarek and Ryan, Michael J. and Ritter, Alan and Xu, Wei , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[9]
Proceedings of the First Workshop on Cross-Cultural Considerations in NLP , year =
Cao, Yong and Zhou, Li and Lee, Seolhwa and Cabello, Laura and Chen, Min and Hershcovich, Daniel , title =. Proceedings of the First Workshop on Cross-Cultural Considerations in NLP , year =
-
[10]
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in Neural Information Processing Systems 35 (NeurIPS) , year =
-
[11]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and others , title =. arXiv preprint arXiv:2204.05862 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , journal =
Casper, Stephen and Davies, Xander and Shi, Claudia and Gilbert, Thomas Krendl and Scheurer, J. Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , journal =
-
[13]
Zhang, Zhexin and Lei, Leqi and Wu, Lindong and Sun, Rui and Huang, Yongkang and Long, Chong and Liu, Xiao and Lei, Xuanyu and Tang, Jie and Huang, Minlie , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[14]
arXiv preprint arXiv:2307.15020 , year =
Xu, Liang and Li, Anqi and Zhu, Lei and Xue, Hang and Zhu, Changtai and Zhao, Kangkang and He, Haonan and Zhang, Xuanwei and Kang, Qiyue and Lan, Zhenzhong , title =. arXiv preprint arXiv:2307.15020 , year =
-
[15]
NeurIPS Datasets and Benchmarks , year =
Wang, Boxin and Chen, Weixin and Pei, Hengzhi and Xie, Chulin and Kang, Mintong and Zhang, Chenhui and Xu, Chejian and Xiong, Zidi and Dutta, Ritik and Schaeffer, Rylan and others , title =. NeurIPS Datasets and Benchmarks , year =
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Deshpande, Ameet and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
work page 2023
-
[17]
and Narayanan, Arvind , title =
Caliskan, Aylin and Bryson, Joanna J. and Narayanan, Arvind , title =. Science , volume =. 2017 , pages =
work page 2017
-
[18]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , year =
work page 2021
-
[19]
Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and others , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.