Diffusion-Based Material Regularization for Physics-Based Inverse Rendering
Pith reviewed 2026-07-01 06:44 UTC · model grok-4.3
The pith
Treating diffusion model outputs as a similarity kernel regularizes materials during physics-based inverse rendering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
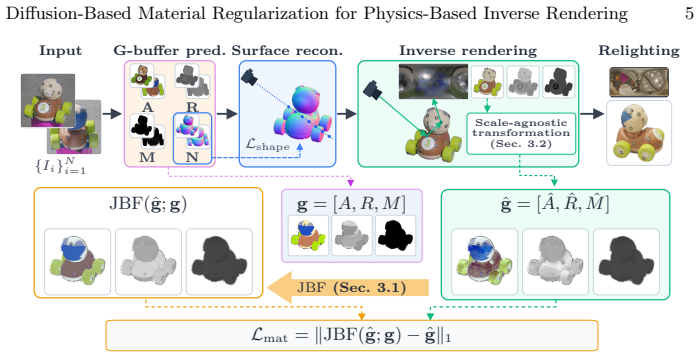
The central claim is that a regularization loss built from a diffusion model's per-pixel similarity predictions penalizes material variation only where those predictions are nearly constant, leaving the optimizer free to fit the input images elsewhere; when embedded in an end-to-end differentiable pipeline, this loss enables joint recovery of geometry, materials, and illumination that satisfies the rendering equation and supports accurate relighting.
What carries the argument
The diffusion-based material regularization loss, which uses diffusion predictions as a similarity kernel rather than as target material values.
If this is right
- Joint optimization of geometry, materials, and illumination becomes feasible from multi-view images.
- Reconstructed assets can be inserted directly into standard rendering pipelines without further adjustment.
- The assets support faithful appearance under novel lighting conditions.
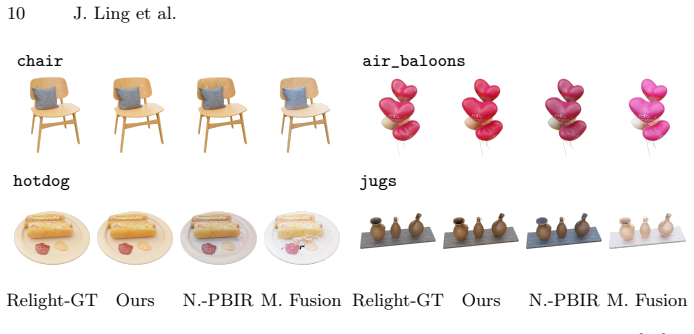
- Quantitative improvements appear on Synthetic4Relight, Stanford-ORB, and DTC-Synthetic in both reconstruction error and relighting metrics.
Where Pith is reading between the lines
- The same similarity-kernel idea could be applied to other data-driven priors such as normals or geometry.
- The approach might reduce the number of input views needed by letting the diffusion model supply additional consistency constraints.
- Because the loss is differentiable, it could be combined with other differentiable renderers or editing tools.
Load-bearing premise
The diffusion model's per-pixel predictions supply a reliable similarity kernel that does not systematically conflict with the image-formation model or introduce biases that cannot be overcome by the data term.
What would settle it
If assets reconstructed by the method produce renderings that match the training views yet deviate substantially from ground-truth images when illuminated by novel lighting on the Synthetic4Relight or Stanford-ORB test sets, the central claim would be falsified.
Figures






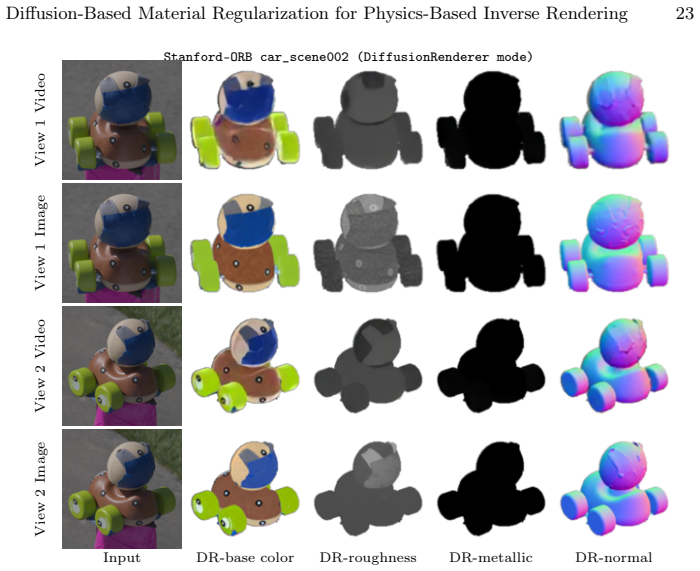
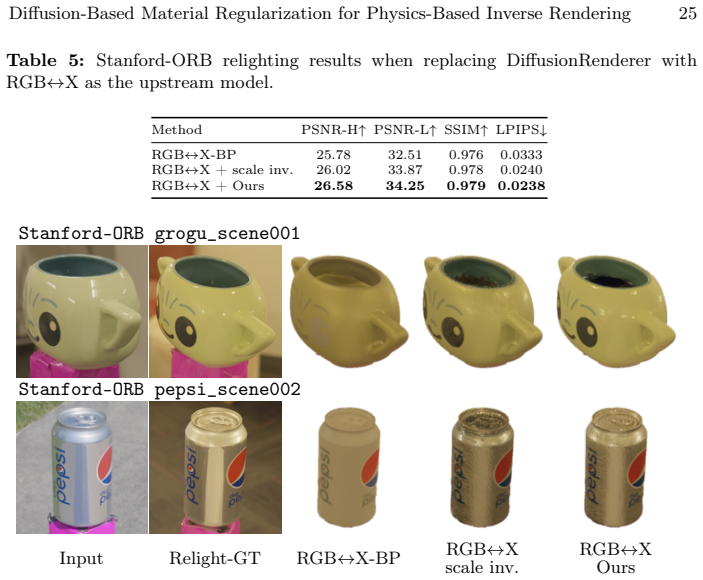
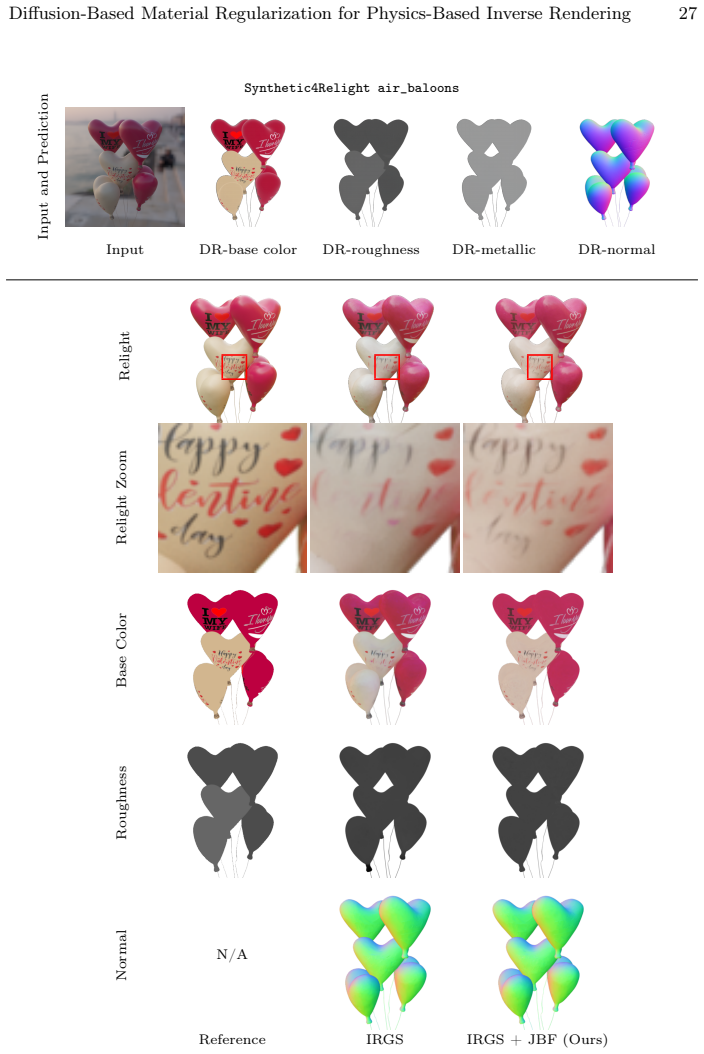


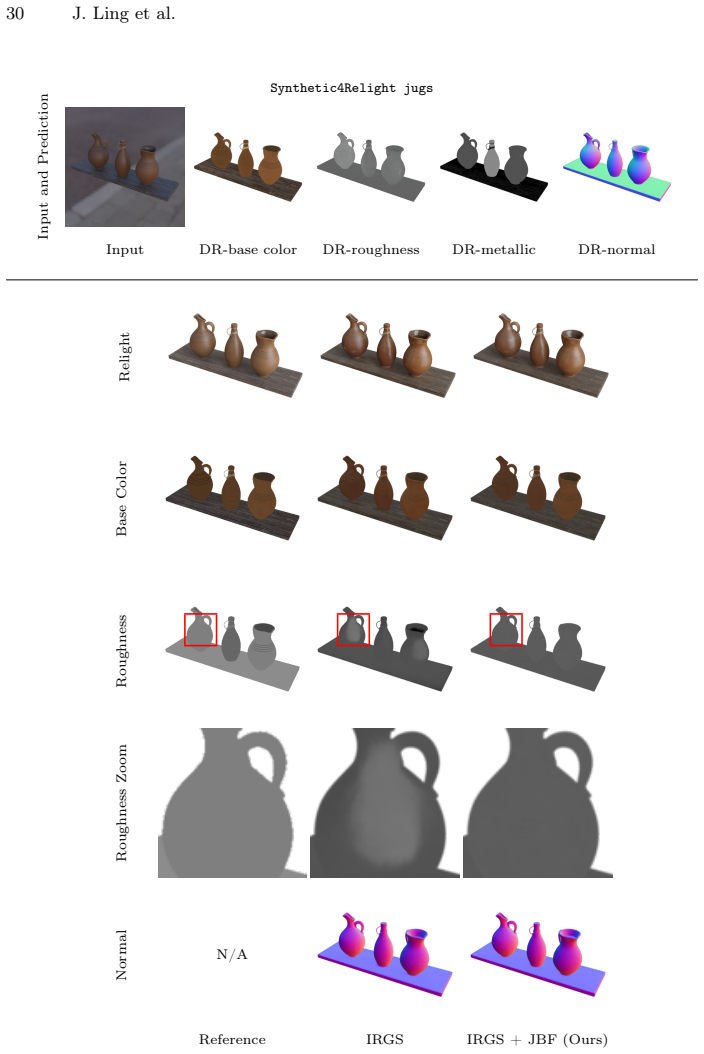
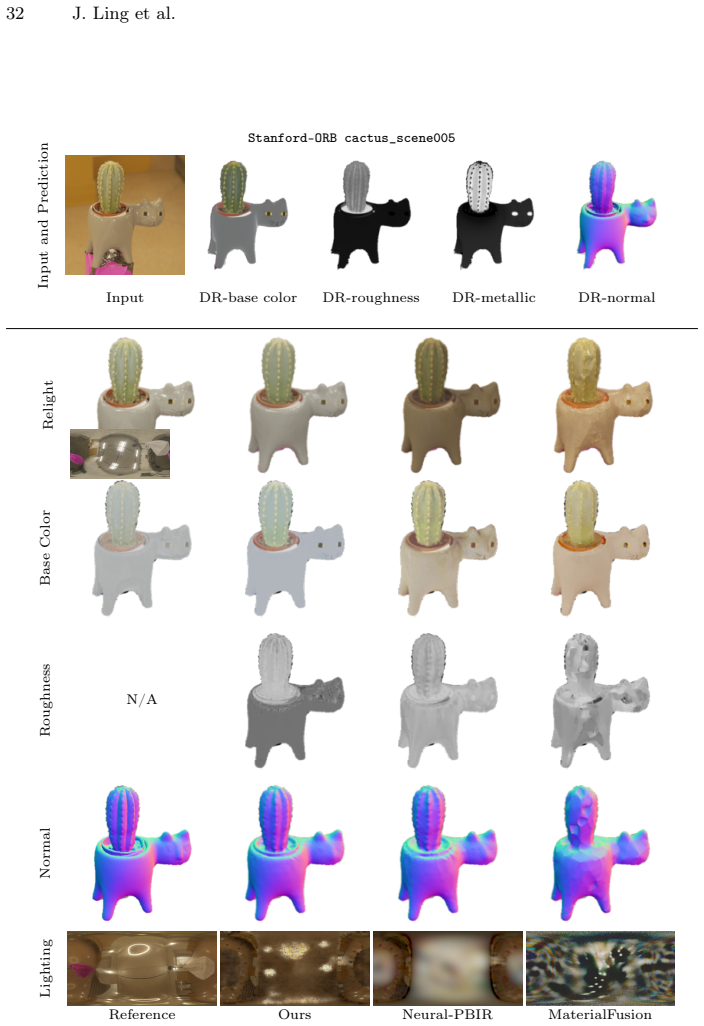


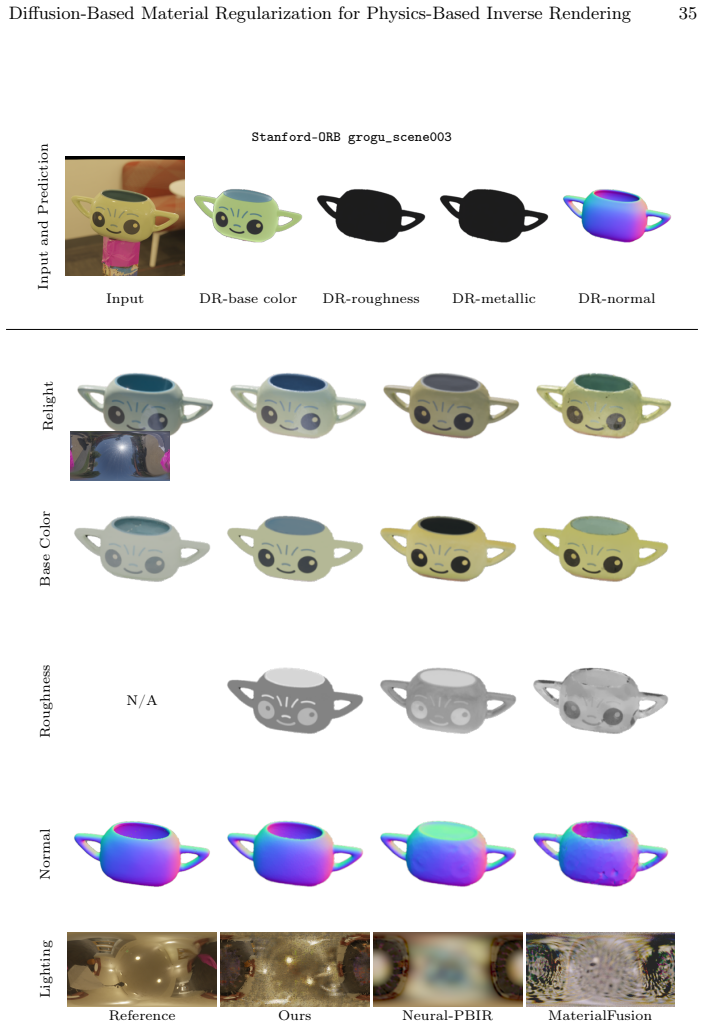

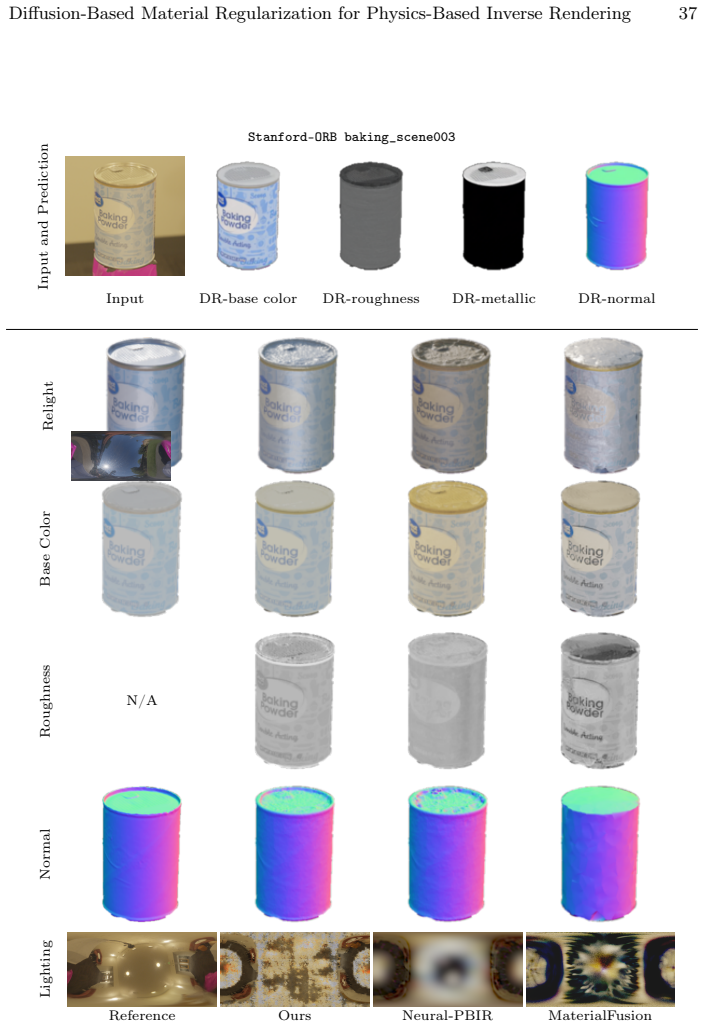

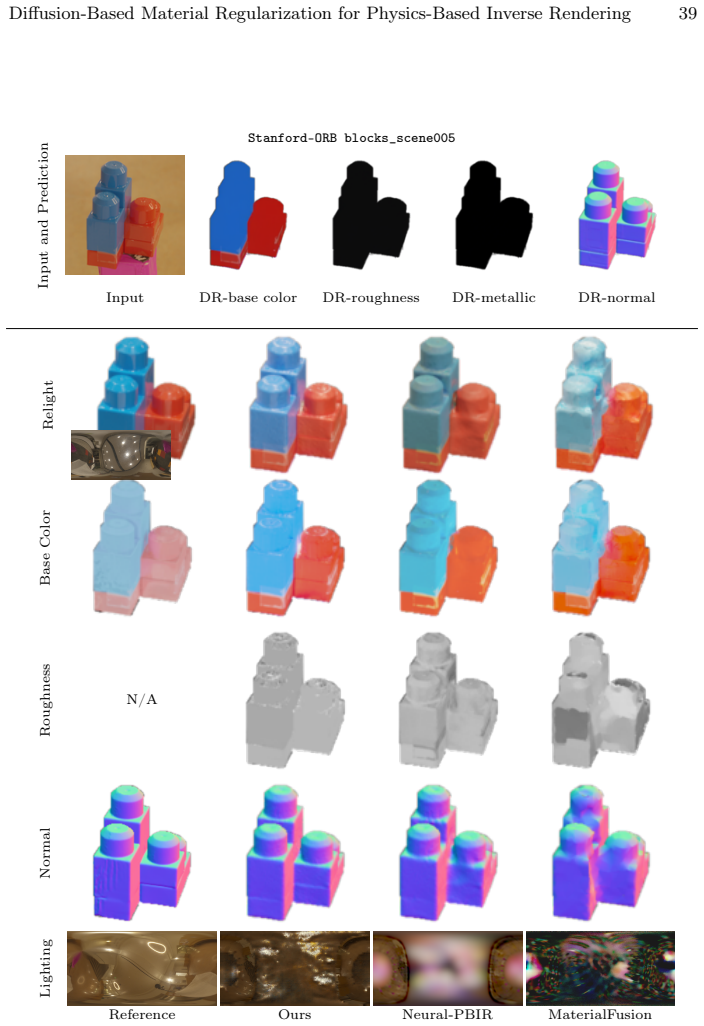
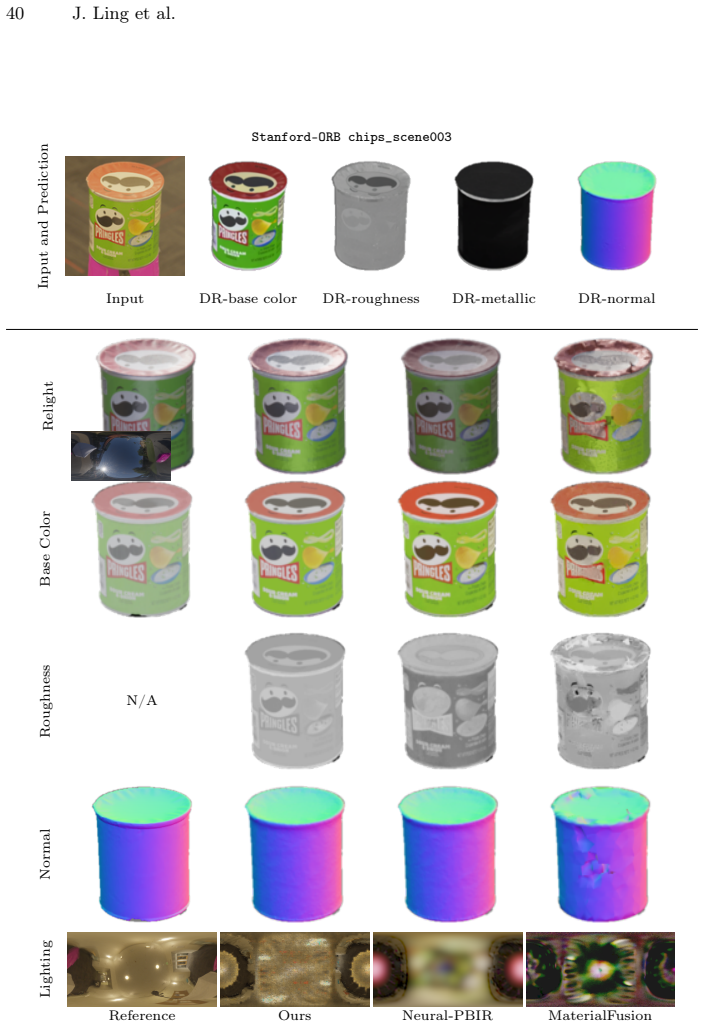

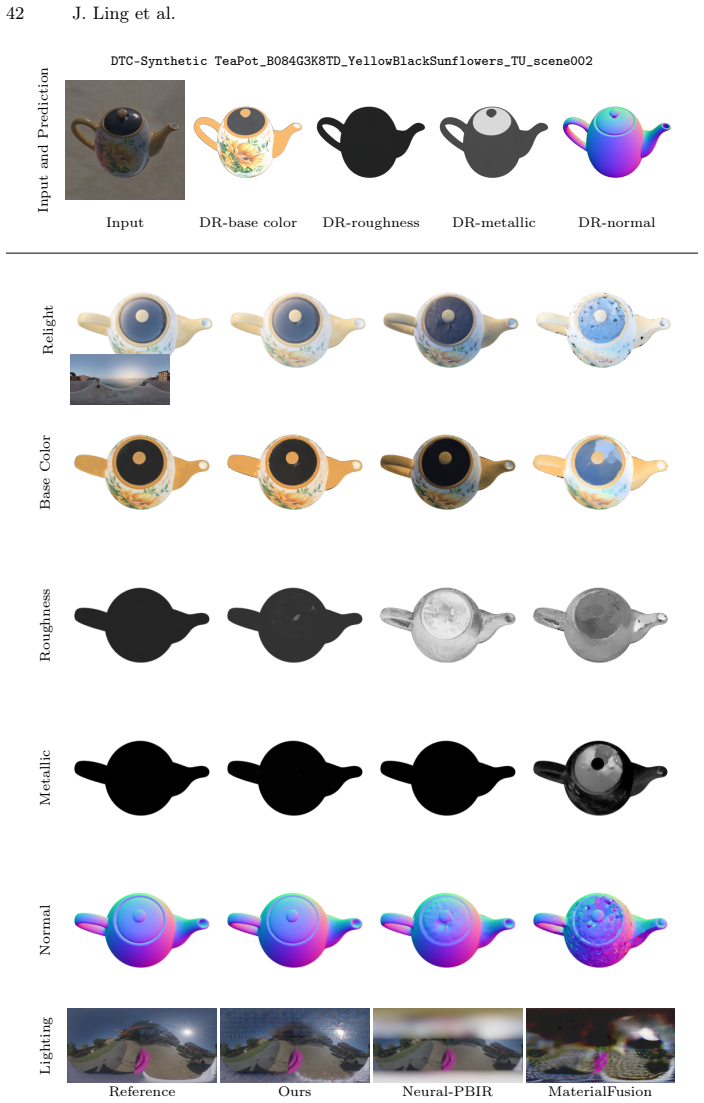
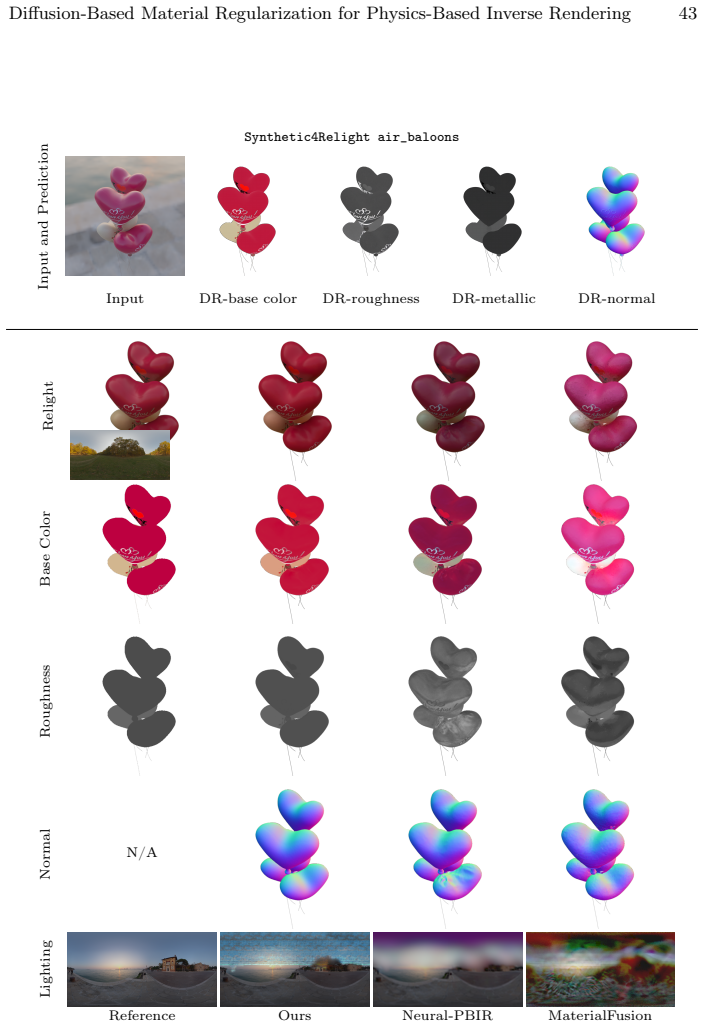


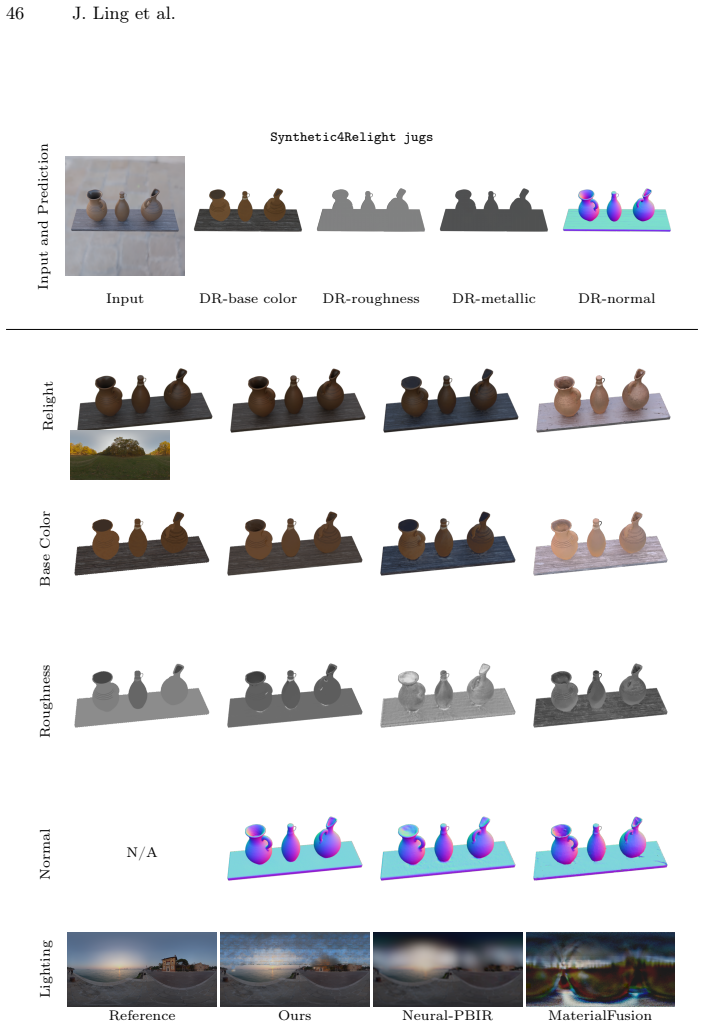
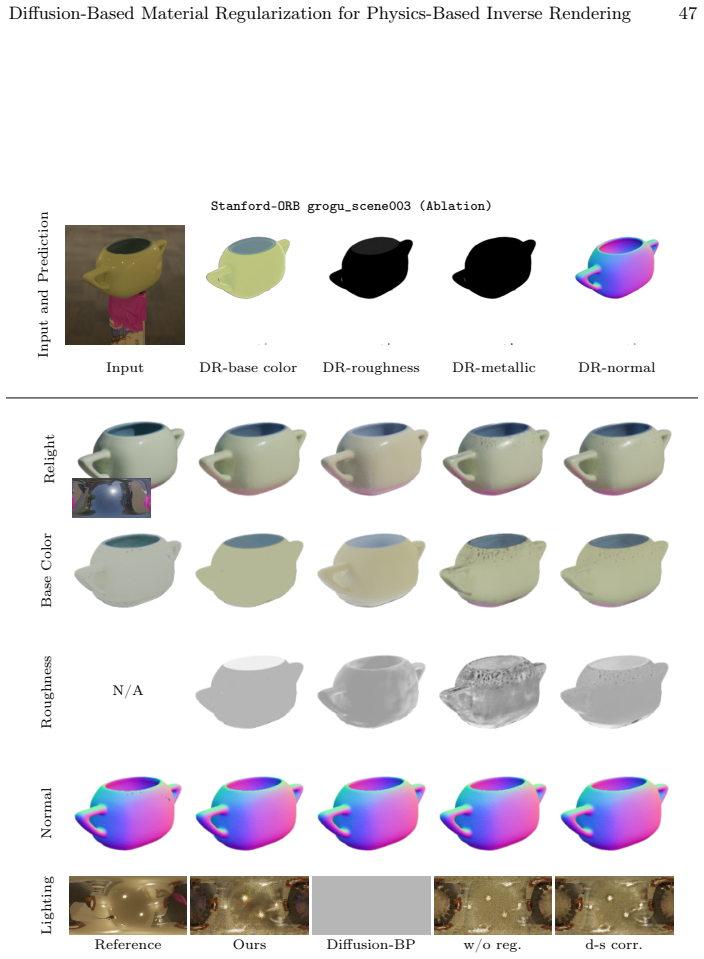
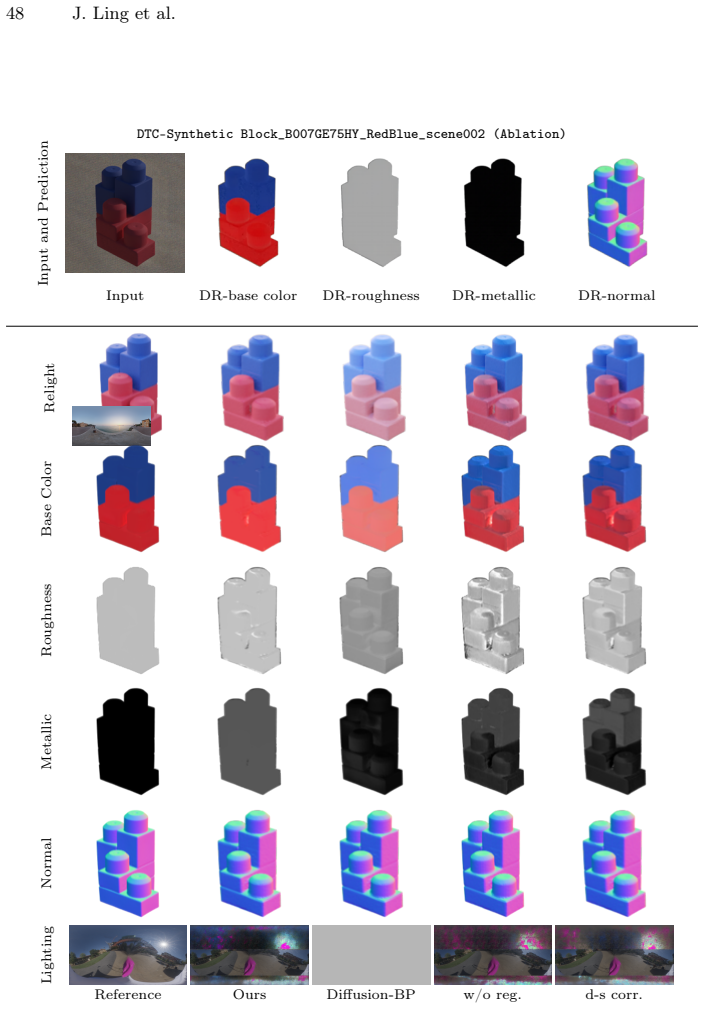
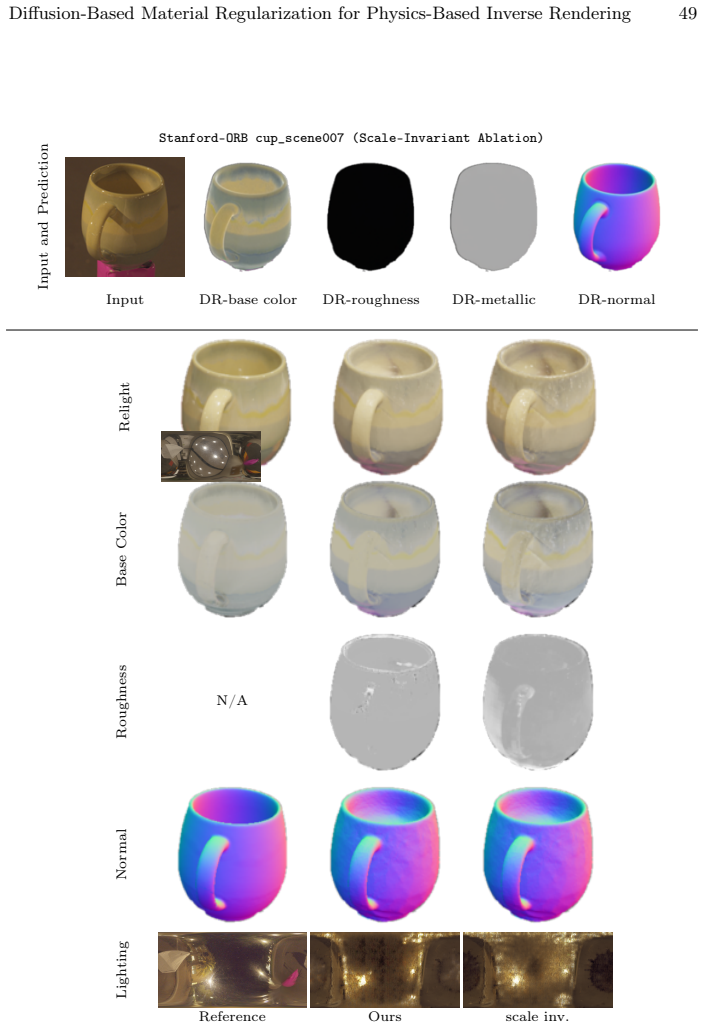
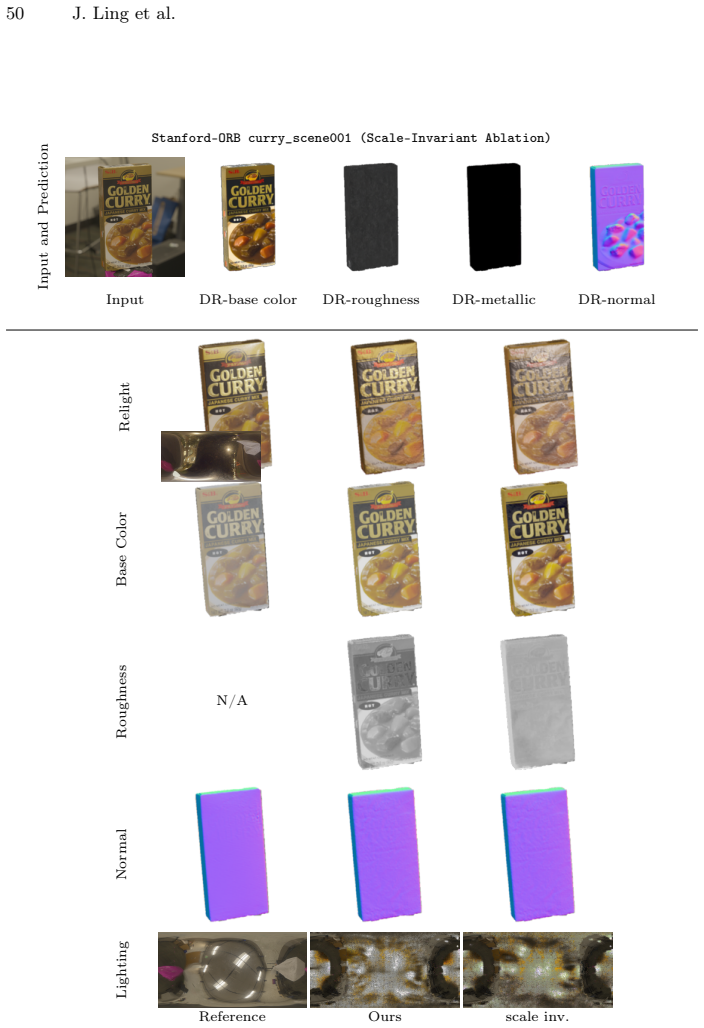
read the original abstract
Reconstructing physics-based 3D assets -- geometry, materials, and illumination -- from multi-view images is a core problem in computer graphics and vision, and a prerequisite for realistic relighting and editing. Physics-based inverse rendering offers an accurate image-formation model, but is severely underconstrained: without strong priors, illumination is baked into materials, and reconstructions generalize poorly to novel views and lighting. Data-driven diffusion models, in contrast, predict visually plausible materials, yet their predictions rarely satisfy the rendering equation and are not directly usable for physics-based rendering. We bridge these two paradigms rather than replacing either. Our key idea is to treat the predictions of a state-of-the-art diffusion model not as target material values but as a similarity kernel for optimization: we introduce a regularization loss that penalizes deviations in the optimized material over surface regions where the diffusion predictions are near-constant, while leaving the optimization free to match the input images. Built on this regularizer, our end-to-end pipeline jointly reconstructs geometry, materials, and illumination, yielding high-quality assets that drop into standard rendering pipelines and relight faithfully. On the Synthetic4Relight, Stanford-ORB, and DTC-Synthetic datasets, our method significantly outperforms state-of-the-art baselines in both reconstruction accuracy and relighting quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes treating predictions from a pretrained diffusion model as a similarity kernel (rather than hard targets) for regularizing material parameters during physics-based inverse rendering optimization. The regularization penalizes material deviations only over surface regions where diffusion outputs are near-constant, leaving the data term free to enforce consistency with the image-formation model. An end-to-end pipeline jointly optimizes geometry, materials, and illumination from multi-view images; the resulting assets are claimed to relight faithfully in standard renderers. Quantitative and qualitative improvements are reported over baselines on Synthetic4Relight, Stanford-ORB, and DTC-Synthetic.
Significance. If the regularization mechanism proves robust, the work offers a principled route to combine data-driven material priors with physical image formation without replacing either paradigm. The explicit design choice to avoid hard targets mitigates a common source of inconsistency in hybrid inverse-rendering methods and could improve generalization to novel lighting. The multi-dataset evaluation and emphasis on drop-in compatibility with existing pipelines are practical strengths.
major comments (2)
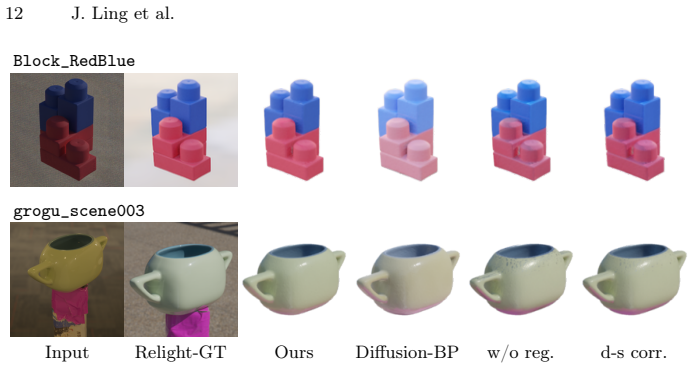
- [§3] §3 (Method), regularization loss definition: the precise condition for 'near-constant' diffusion predictions and the weighting schedule between the regularization term and the rendering loss must be stated explicitly (including any thresholds or adaptive mechanisms). Without this, it is impossible to verify that the kernel does not systematically conflict with the data term on the claimed datasets.
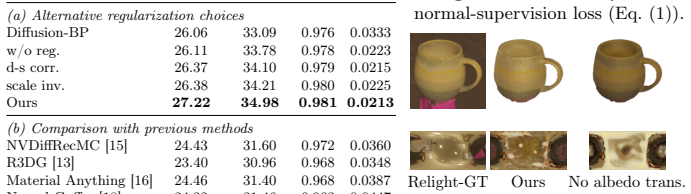
- [§4] §4 (Experiments), Table 2 and relighting metrics: the reported gains in PSNR/SSIM for novel lighting must be accompanied by per-scene variance and statistical significance tests; otherwise the cross-dataset superiority claim rests on aggregate numbers whose reliability cannot be assessed.
minor comments (2)
- [Figure 3] Figure 3 caption and §4.1: clarify whether the diffusion model is frozen throughout optimization or fine-tuned on any of the evaluation scenes.
- [§2] Related-work section: the discussion of prior diffusion-based inverse-rendering methods should cite the specific architectural differences that motivate the similarity-kernel formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. We address each major comment below and will incorporate the requested clarifications and additional analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), regularization loss definition: the precise condition for 'near-constant' diffusion predictions and the weighting schedule between the regularization term and the rendering loss must be stated explicitly (including any thresholds or adaptive mechanisms). Without this, it is impossible to verify that the kernel does not systematically conflict with the data term on the claimed datasets.
Authors: We agree that the current description in §3 is insufficiently precise. The revised manuscript will explicitly define the near-constant condition (regions where the per-pixel variance of the diffusion model outputs across an ensemble of samples falls below a fixed threshold) and will state the exact weighting schedule between the regularization term and the rendering loss, including the value of the balancing hyperparameter and whether it is held constant or adapted during optimization. revision: yes
-
Referee: [§4] §4 (Experiments), Table 2 and relighting metrics: the reported gains in PSNR/SSIM for novel lighting must be accompanied by per-scene variance and statistical significance tests; otherwise the cross-dataset superiority claim rests on aggregate numbers whose reliability cannot be assessed.
Authors: We acknowledge that aggregate metrics alone are insufficient to support the superiority claims. The revised version will augment Table 2 (and the corresponding relighting tables) with per-scene means and standard deviations, and will report the results of paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests) across scenes for each dataset. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core mechanism defines a regularization loss that treats an external pretrained diffusion model's per-pixel outputs strictly as a similarity kernel (penalizing deviations only where predictions are near-constant) while leaving the data term free to enforce rendering consistency. No equation or claim reduces a derived quantity to the authors' own fitted parameters, self-citations, or ansatzes imported from prior work by the same authors. The pipeline jointly optimizes geometry, materials, and illumination using this external kernel plus the image-formation model, with no self-definitional, fitted-input-called-prediction, or uniqueness-imported steps evident. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adams, A., Baek, J., Davis, M.A.: Fast high-dimensional filtering using the per- mutohedral lattice. Comput. Graph. Forum29(2), 753–762 (2010).https://doi. org/10.1111/J.1467-8659.2009.01645.X
-
[2]
Alzayer, H., Henzler, P., Barron, J.T., Huang, J., Srinivasan, P.P., Verbin, D.: Generative multiview relighting for 3d reconstruction under extreme illumination variation. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 10933–10942. Com- puter Vision Foundation / IEEE (2025)....
-
[3]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXVIII
Attal, B., Verbin, D., Mildenhall, B., Hedman, P., Barron, J.T., O’Toole, M., Srini- vasan, P.P.: Flash cache: Reducing bias in radiance cache based inverse render- ing. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXVIII. Lecture Notes in Com- puter Science, vol. 15086, pp. 20–3...
2024
-
[4]
Burley, B.: Physically-based shading at disney (2012)
2012
-
[5]
Chen, A., Xu, Z., Wei, X., Tang, S., Su, H., Geiger, A.: Dictionary fields: Learning a neural basis decomposition. ACM Trans. Graph.42(4), 156:1–156:12 (2023). https://doi.org/10.1145/3592135
-
[6]
CoRRabs/2302.01226(2023).https: //doi.org/10.48550/ARXIV.2302.01226
Chen, A., Xu, Z., Wei, X., Tang, S., Su, H., Geiger, A.: Factor fields: A unified framework for neural fields and beyond. CoRRabs/2302.01226(2023).https: //doi.org/10.48550/ARXIV.2302.01226
-
[7]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Chen, X., Peng, S., Yang, D., Liu, Y., Pan, B., Lv, C., Zhou, X.: Intrinsicanything: Learning diffusion priors for inverse rendering under unknown illumination. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, Septem- ber 29-October 4, 2024, Proceed...
-
[8]
CoRRabs/2507.01305(2025).https://doi.org/10
Chinchuthakun, W., Phongthawee, P., Raj, A., Jampani, V., Khungurn, P., Suwa- janakorn, S.: Diffusionlight-turbo: Accelerated light probes for free via single-pass chrome ball inpainting. CoRRabs/2507.01305(2025).https://doi.org/10. 48550/ARXIV.2507.01305
arXiv 2025
-
[9]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025
Chung, H., Choi, S., Baek, S.: Differentiable inverse rendering with interpretable basis brdfs. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 475–
2025
-
[11]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24,
Chung, H., Kim, J., Kim, S., Ye, J.C.: Parallel diffusion models of operator and image for blind inverse problems. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24,
2023
-
[12]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
pp. 6059–6069. IEEE (2023).https://doi.org/10.1109/CVPR52729.2023. 00587
-
[13]
Dong, Z., Chen, K., Lv, Z., Yu, H., Zhang, Y., Zhang, C., Zhu, Y., Tian, S., Li, Z., Moffatt, G., Christofferson, S., Fort, J., Pan, X., Yan, M., Wu, J., Ren, C.Y., Newcombe, R.A.: Digital twin catalog: A large-scale photorealistic 3d object digital twin dataset. In: 2025 IEEE/CVF Conference on Computer Vision and Diffusion-Based Material Regularization f...
2025
-
[15]
CoRRabs/2411.19322 (2024).https://doi.org/10.48550/ARXIV.2411.19322
Fischer, M., Georgiev, I., Groueix, T., Kim, V.G., Ritschel, T., Deschaintre, V.: Sama: Material-aware 3d selection and segmentation. CoRRabs/2411.19322 (2024).https://doi.org/10.48550/ARXIV.2411.19322
-
[16]
Scott Armstrong, ed.Expert Opinions in Forecasting: The Role of the Delphi Technique
Gao, J., Gu, C., Lin, Y., Li, Z., Zhu, H., Cao, X., Zhang, L., Yao, Y.: Relightable 3d gaussians: Realistic point cloud relighting with BRDF decomposition and ray tracing. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024...
-
[17]
Gu, C., Wei, X., Zeng, Z., Yao, Y., Zhang, L.: IRGS: inter-reflective gaussian splatting with 2d gaussian ray tracing. In: 2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11- 15, 2025. pp. 10943–10952. Computer Vision Foundation / IEEE (2025).https: //doi.org/10.1109/CVPR52734.2025.01022
-
[18]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Hasselgren, J., Hofmann, N., Munkberg, J.: Shape, light, and material decom- position from images using monte carlo rendering and denoising. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neu- ral Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, Ne...
2022
-
[19]
Huang, X., Wang, T., Liu, Z., Wang, Q.: Material anything: Generating materials forany3dobjectviadiffusion.In:2025IEEE/CVFConferenceonComputerVision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 26556–26565. Computer Vision Foundation / IEEE (2025).https://doi.org/10. 1109/CVPR52734.2025.02473
arXiv 2025
-
[20]
Jakob, W., Speierer, S., Roussel, N., Vicini, D.: DR.JIT: a just-in-time compiler for differentiable rendering. ACM Trans. Graph.41(4), 124:1–124:19 (2022).https: //doi.org/10.1145/3528223.3530099
-
[21]
Jin, H., Li, Y., Luan, F., Xiangli, Y., Bi, S., Zhang, K., Xu, Z., Sun, J., Snavely, N.: Neural gaffer: Relighting any object via diffusion. In: Advances in Neural In- formation Processing Systems 38: Annual Conference on Neural Information Pro- cessing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10-15, 2024 (2024)
2024
-
[22]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Jin, H., Liu, I., Xu, P., Zhang, X., Han, S., Bi, S., Zhou, X., Xu, Z., Su, H.: Tensoir: Tensorial inverse rendering. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 165–174. IEEE (2023).https://doi.org/10.1109/CVPR52729.2023.00024
-
[23]
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139:1–139:14 (2023). https://doi.org/10.1145/3592433
-
[24]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Kuang, Z., Zhang, Y., Yu, H., Agarwala, S., Wu, S., Wu, J.: Stanford-orb: A real- world 3d object inverse rendering benchmark. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Pro- cessing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, L...
2023
-
[25]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Lee, Y., Kim, K., Kim, H., Sung, M.: Syncdiffusion: Coherent montage via syn- chronized joint diffusions. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16,...
2023
-
[26]
In: Dy, J.G., Krause, A
Lehtinen, J., Munkberg, J., Hasselgren, J., Laine, S., Karras, T., Aittala, M., Aila, T.: Noise2noise: Learning image restoration without clean data. In: Dy, J.G., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018. Proceedings of Machine Learning Researc...
2018
-
[27]
Lensch, H.P.A., Kautz, J., Goesele, M., Heidrich, W., Seidel, H.: Image-based re- constructionofspatialappearanceandgeometricdetail.ACMTrans.Graph.22(2), 234–257 (2003).https://doi.org/10.1145/636886.636891
-
[28]
Liang,R.,Gojcic,Z.,Ling,H.,Munkberg,J.,Hasselgren,J.,Lin,Z.,Gao,J.,Keller, A., Vijaykumar, N., Fidler, S., Wang, Z.: Diffusionrenderer: Neural inverse and forward rendering with video diffusion models. CoRRabs/2501.18590(2025). https://doi.org/10.48550/ARXIV.2501.18590
-
[29]
CoRR abs/2509.03680(2025).https://doi.org/10.48550/ARXIV.2509.03680
Liang, R., He, K., Gojcic, Z., Gilitschenski, I., Fidler, S., Vijaykumar, N., Wang, Z.: Luxdit: Lighting estimation with video diffusion transformer. CoRR abs/2509.03680(2025).https://doi.org/10.48550/ARXIV.2509.03680
-
[30]
In: International Conference on 3D Vision, 3DV 2025, Singapore, March 25- 28, 2025
Litman, Y., Patashnik, O., Deng, K., Agrawal, A., Zawar, R., la Torre, F.D., Tul- siani, S.: Materialfusion: Enhancing inverse rendering with material diffusion pri- ors. In: International Conference on 3D Vision, 3DV 2025, Singapore, March 25- 28, 2025. pp. 802–812. IEEE (2025).https://doi.org/10.1109/3DV66043.2025. 00079
-
[31]
CoRRabs/2508.06494(2025).https://doi.org/10
Litman, Y., la Torre, F.D., Tulsiani, S.: Lightswitch: Multi-view relighting with material-guided diffusion. CoRRabs/2508.06494(2025).https://doi.org/10. 48550/ARXIV.2508.06494
arXiv 2025
-
[32]
Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface con- struction algorithm. In: Stone, M.C. (ed.) Proceedings of the 14th Annual Confer- ence on Computer Graphics and Interactive Techniques, SIGGRAPH ’87, Ana- heim, California, USA, July 27-31, 1987. pp. 163–169. ACM (1987).https: //doi.org/10.1145/37401.37422
-
[33]
Luan, F., Zhao, S., Bala, K., Dong, Z.: Unified shape and SVBRDF recovery us- ing differentiable monte carlo rendering. Comput. Graph. Forum40(4), 101–113 (2021).https://doi.org/10.1111/CGF.14344
-
[34]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Mildenhall, B., Hedman, P., Martin-Brualla, R., Srinivasan, P.P., Barron, J.T.: Nerf in the dark: High dynamic range view synthesis from noisy raw images. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 16169–16178. IEEE (2022). https://doi.org/10.1109/CVPR52688.2022.01571
-
[35]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J. (eds.) Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceed- ings, Part I. Lecture Notes in Computer Scien...
-
[36]
Munkberg, J., Wang, Z., Liang, R., Shen, T., Hasselgren, J.: Videomat: Extracting PBR materials from video diffusion models. Comput. Graph. Forum44(4) (2025). https://doi.org/10.1111/CGF.70180 Diffusion-Based Material Regularization for Physics-Based Inverse Rendering 19
-
[37]
In: NeurIPS 2023 Workshop on Deep Learning and Inverse Problems (2023)
Oscanoa, J., Alkan, C., Abraham, D., Nurdinova, A., Ennis, D., Vasanawala, S., Mardani, M., Pauly, J.M.: Variational diffusion models for MRI blind inverse prob- lems. In: NeurIPS 2023 Workshop on Deep Learning and Inverse Problems (2023)
2023
-
[38]
Petschnigg, G., Szeliski, R., Agrawala, M., Cohen, M.F., Hoppe, H., Toyama, K.: Digital photography with flash and no-flash image pairs. ACM Trans. Graph. 23(3), 664–672 (2004).https://doi.org/10.1145/1015706.1015777
-
[39]
Phongthawee, P., Chinchuthakun, W., Sinsunthithet, N., Jampani, V., Raj, A., Khungurn, P., Suwajanakorn, S.: Diffusionlight: Light probes for free by painting a chrome ball. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 98–108. IEEE (2024).https://doi.org/10.1109/CVPR52733.2024.00018
-
[40]
Schmitt, C., Donné, S., Riegler, G., Koltun, V., Geiger, A.: On joint estimation of pose, geometry and svbrdf from a handheld scanner. In: 2020 IEEE/CVF Confer- enceonComputerVisionandPatternRecognition,CVPR2020,Seattle,WA,USA, June 13-19, 2020. pp. 3490–3500. Computer Vision Foundation / IEEE (2020). https://doi.org/10.1109/CVPR42600.2020.00355
-
[41]
Sharma, P., Philip, J., Gharbi, M., Freeman, B., Durand, F., Deschaintre, V.: Materialistic: Selecting similar materials in images. ACM Trans. Graph.42(4), 154:1–154:14 (2023).https://doi.org/10.1145/3592390
-
[42]
Sun, C., Cai, G., Li, Z., Yan, K., Zhang, C., Marshall, C.S., Huang, J., Zhao, S., Dong, Z.: Neural-pbir reconstruction of shape, material, and illumination. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 18000–18010. IEEE (2023).https://doi.org/10. 1109/ICCV51070.2023.01654
arXiv 2023
-
[43]
Sun, H., Gao, Y., Xie, J., Yang, J., Wang, B.: SVG-IR: spatially-varying gaus- sian splatting for inverse rendering. In: 2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 16143–16152. Computer Vision Foundation / IEEE (2025).https: //doi.org/10.1109/CVPR52734.2025.01505
-
[44]
CoRRabs/2510.03163(2025).https://doi.org/10.48550/ARXIV.2510
Tang, J., Lavine, M., Verbin, D., Garbin, S.J., Nießner, M., Martin-Brualla, R., Srinivasan,P.P.,Henzler,P.:ROGR:relightable3dobjectsusinggenerativerelight- ing. CoRRabs/2510.03163(2025).https://doi.org/10.48550/ARXIV.2510. 03163
-
[45]
Phd thesis, EPFL (2022)
Vicini, D.A.: Efficient and Accurate Physically-Based Differentiable Rendering. Phd thesis, EPFL (2022)
2022
-
[46]
In: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W
Wang, P., Liu, L., Liu, Y., Theobalt, C., Komura, T., Wang, W.: Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W. (eds.) Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Ne...
2021
-
[47]
Wiersma, R., Philip, J., Hasan, M., Mullia, K., Luan, F., Eisemann, E., De- schaintre, V.: Uncertainty for SVBRDF acquisition using frequency analysis. In: Proceedings of the Special Interest Group on Computer Graphics and Interac- tive Techniques Conference Papers, SIGGRAPH Conference Papers ’25, Vancou- ver, BC, Canada, August 10-14, 2025. pp. 169:1–169...
-
[48]
https://doi.org/10.48550/ARXIV.2511.18900 20 J
Wu, X., Zhu, P., Lyu, J., Liu, X., Guo, J., Guo, Y., Xu, W., Lyu, C.: Matmart: Materialreconstructionof3dobjectsviadiffusion.CoRRabs/2511.18900(2025). https://doi.org/10.48550/ARXIV.2511.18900 20 J. Ling et al
-
[49]
In: ACM SIGGRAPH 2024 Conference Papers, SIGGRAPH 2024, Denver, CO, USA, 27 July 2024-1 August
Zeng, C., Dong, Y., Peers, P., Kong, Y., Wu, H., Tong, X.: Dilightnet: Fine-grained lighting control for diffusion-based image generation. In: ACM SIGGRAPH 2024 Conference Papers, SIGGRAPH 2024, Denver, CO, USA, 27 July 2024-1 August
2024
-
[50]
p. 73. ACM (2024).https://doi.org/10.1145/3641519.3657396
-
[51]
In: Burbano, A., Zorin, D., Jarosz, W
Zeng, Z., Deschaintre, V., Georgiev, I., Hold-Geoffroy, Y., Hu, Y., Luan, F., Yan, L., Hasan, M.: Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models. In: Burbano, A., Zorin, D., Jarosz, W. (eds.) ACM SIGGRAPH2024ConferencePapers,SIGGRAPH2024,Denver,CO,USA,27July 2024-1 August 2024. p. 75. ACM (2024).https://doi.or...
-
[52]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable ef- fectiveness of deep features as a perceptual metric. CoRRabs/1801.03924(2018)
Pith/arXiv arXiv 2018
-
[53]
In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
Zhang, T., Kuang, Z., Jin, H., Xu, Z., Bi, S., Tan, H., Zhang, H., Hu, Y., Hasan, M., Freeman, W.T., Zhang, K., Luan, F.: Relitlrm: Generative relightable radi- ance for large reconstruction models. In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net (2025)
2025
-
[54]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Zhang, Y., Sun, J., He, X., Fu, H., Jia, R., Zhou, X.: Modeling indirect illumination for inverse rendering. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 18622–18631. IEEE (2022).https://doi.org/10.1109/CVPR52688.2022.01809
-
[55]
In: ACM SIGGRAPH 2020 Courses
Zhao, S., Jakob, W., Li, T.M.: Physics-based differentiable rendering: A compre- hensive introduction. In: ACM SIGGRAPH 2020 Courses. pp. 14:1–14:30 (2020)
2020
-
[56]
Zhao, X., Srinivasan, P.P., Verbin, D., Park, K., Martin-Brualla, R., Henzler, P.: Illuminerf: 3d relighting without inverse rendering. In: Advances in Neural Infor- mation Processing Systems 38: Annual Conference on Neural Information Process- ing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10-15, 2024 (2024)
2024
-
[57]
In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Sin- gapore, April 24-28, 2025
Zheng, H., Chu, W., Zhang, B., Wu, Z., Wang, A., Feng, B., Zou, C., Sun, Y., Kovachki, N.B., Ross, Z.E., Bouman, K.L., Yue, Y.: Inversebench: Benchmark- ing plug-and-play diffusion priors for inverse problems in physical sciences. In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Sin- gapore, April 24-28, 2025. OpenReview...
2025
-
[58]
Zhou, Z., Chen, G., Dong, Y., Wipf, D.P., Yu, Y., Snyder, J.M., Tong, X.: Sparse- as-possible SVBRDF acquisition. ACM Trans. Graph.35(6), 189:1–189:12 (2016). https://doi.org/10.1145/2980179.2980247
-
[59]
In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Zhu, J., Zhuang, P., Koyejo, S.: HIFA: high-fidelity text-to-3d generation with advanced diffusion guidance. In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net (2024)
2024
-
[60]
Zhu, Z., Wang, B., Yang, J.: GS-ROR2: bidirectional-guided 3dgs and SDF for reflective object relighting and reconstruction. ACM Trans. Graph.45(1), 4:1–4:19 (2026).https://doi.org/10.1145/3759248
-
[61]
In: Deussen, O., Keller, A., Bala, K., Dutré, P., Fellner, D.W., Spencer, S.N
Zickler, T.E., Enrique, S., Ramamoorthi, R., Belhumeur, P.N.: Reflectance shar- ing: Image-based rendering from a sparse set of images. In: Deussen, O., Keller, A., Bala, K., Dutré, P., Fellner, D.W., Spencer, S.N. (eds.) Proceedings of the Eurographics Symposium on Rendering Techniques, Konstanz, Germany, June 29- July 1, 2005. pp. 253–264. Eurographics ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.