Multi-Legal-Bench: Evaluating LLMs on Legal Reasoning Across Jurisdictions, Languages, and Legal Traditions
Pith reviewed 2026-06-29 07:22 UTC · model grok-4.3
The pith
Multi-Legal-Bench tests five identical legal tasks across six countries and shows model rankings shift by task and jurisdiction while cross-lingual transfer tracks label-set alignment more than language family.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
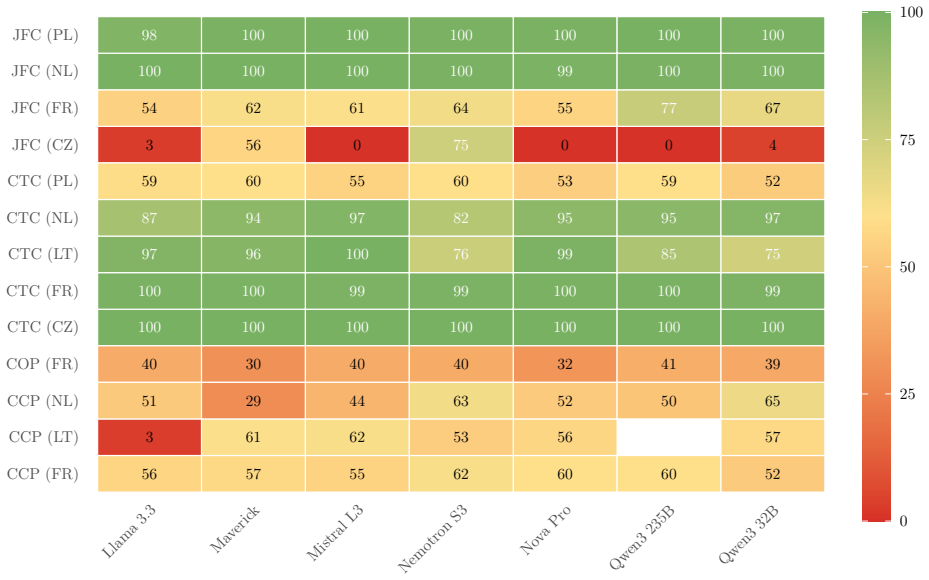
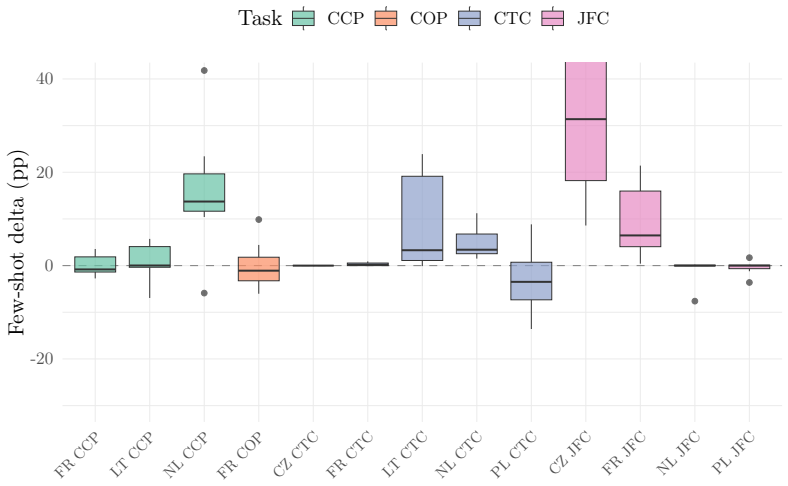
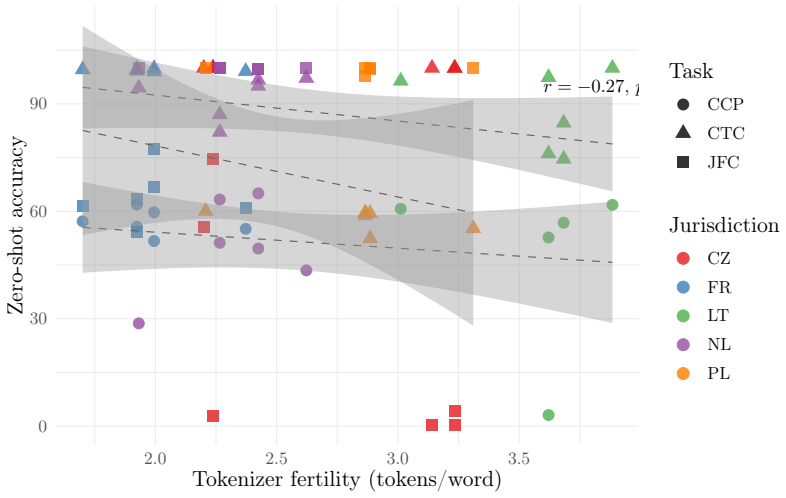
Multi-Legal-Bench defines five tasks—court-type classification, judgment form classification, case-outcome prediction, legal norm extraction, and cause category prediction—mapped to structured metadata from six national court registries and evaluates seven frontier LLMs plus smaller models under zero- and three-shot prompting. The evaluation reveals that task-dependent few-shot effects replicate across jurisdictions, model rankings vary with both task and country, cross-lingual transfer from Ukrainian to French outperforms transfer to Polish despite language-family differences, label-set alignment predicts transfer success better than language proximity, and tokenizer fertility shows no sign
What carries the argument
The sparse 5x6 task-jurisdiction matrix that maps five identical tasks to structured metadata from six national court registries.
If this is right
- Task-dependent few-shot effects hold across all tested jurisdictions.
- No single model leads in every task-jurisdiction combination.
- Cross-lingual few-shot transfer quality correlates with label-set alignment rather than language family membership.
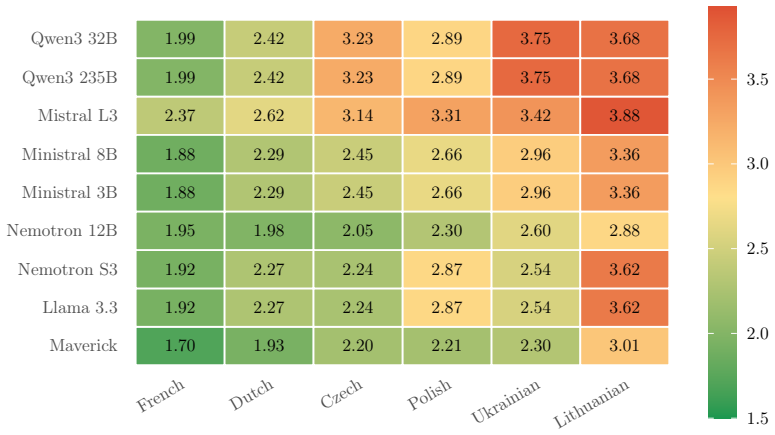
- Tokenizer fertility across a 2.3x range does not predict cross-lingual accuracy.
Where Pith is reading between the lines
- If label-set alignment drives transfer, standardizing output schemas across languages before prompting could improve few-shot results more than choosing linguistically close source languages.
- The absence of a tokenizer effect points to pretraining corpus content as the dominant factor for legal-domain cross-lingual performance.
- Jurisdiction-specific model rankings imply that general-purpose legal LLMs may underperform compared with models tuned on the target registry's metadata format.
Load-bearing premise
The five tasks remain meaningfully comparable across jurisdictions that use different legal traditions and court registries, allowing performance gaps to be attributed to model capabilities rather than differences in what the tasks actually require.
What would settle it
Re-annotating the same task in two jurisdictions so that the legal elements to be extracted or predicted become structurally equivalent and then observing that relative model accuracies do not change would indicate the original tasks were not equivalent.
Figures
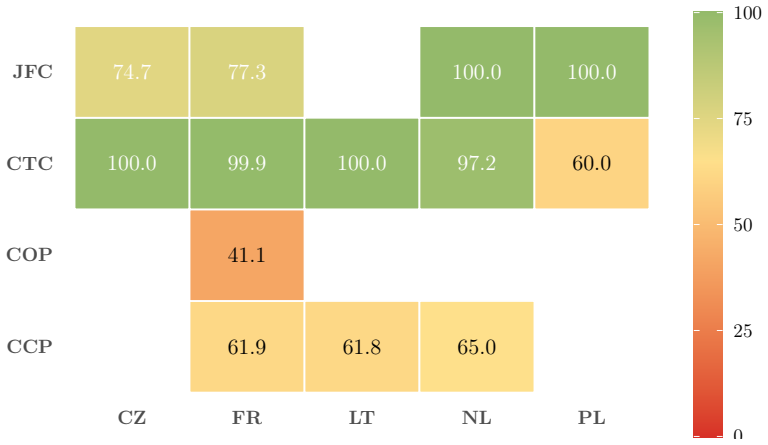
read the original abstract
Legal NLP benchmarks overwhelmingly evaluate a single language or aggregate tasks that differ fundamentally across jurisdictions, making cross-lingual comparison impossible. We introduce Multi-Legal-Bench, the first cross-jurisdictional legal benchmark that evaluates identical tasks across six countries (Ukraine, France, Netherlands, Poland, Czech Republic, Lithuania), four language families, and 134 million court decisions. The benchmark defines five tasks court-type classification, judgment form classification, case-outcome prediction, legal norm extraction, and cause category prediction mapped to structured metadata from national court registries, forming a deliberately sparse 5x6 task-jurisdiction matrix (20 of 30 cells filled). We evaluate 7 frontier LLMs under zero-shot and 3-shot prompting via AWS Bedrock, with 4 additional small/medium models (3-12B) for scaling analysis. Our results reveal that: (1) task-dependent few-shot effects discovered in Ukrainian replicate across all jurisdictions; (2) no single model dominates any language rankings shift with both task and jurisdiction; (3) cross-lingual few-shot transfer does not follow language proximity: UA->FR (Romance, -2.1 pp) transfers better than UA->PL (Slavic, -13.7 pp), with label-set alignment predicting transfer quality better than language family; and (4) tokenizer fertility, despite a 2.3x spread, does not significantly predict cross-lingual accuracy (r=-0.27, p=0.14), suggesting that model architecture and pretraining data dominate tokenizer efficiency. We release all data, prompts, and model predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multi-Legal-Bench, the first cross-jurisdictional legal benchmark evaluating five tasks (court-type classification, judgment form classification, case-outcome prediction, legal norm extraction, cause category prediction) across six countries (Ukraine, France, Netherlands, Poland, Czech Republic, Lithuania) via mappings to national court registry metadata, forming a sparse 5x6 matrix. It evaluates 11 LLMs (7 frontier via Bedrock, 4 smaller for scaling) in zero-shot and 3-shot settings and reports that (1) task-dependent few-shot effects replicate across jurisdictions, (2) no model dominates and rankings shift by task/jurisdiction, (3) cross-lingual transfer (e.g., UA->FR better than UA->PL) is predicted by label-set alignment rather than language family, and (4) tokenizer fertility (2.3x spread) does not predict accuracy (r=-0.27, p=0.14). All data, prompts, and predictions are released.
Significance. If the task mappings ensure meaningful comparability, the benchmark fills a gap in legal NLP by enabling direct cross-jurisdictional and cross-lingual comparisons on real court data from 134M decisions. The empirical findings on few-shot replication, non-language-proximity transfer, and tokenizer irrelevance are falsifiable and could inform model selection and prompting strategies in multilingual legal applications. The public release of data, prompts, and predictions is a clear strength supporting reproducibility.
major comments (1)
- [Abstract, §3] Abstract and §3 (task definition): The replication claim (1), transfer patterns (3), and tokenizer analysis (4) all treat the five tasks as comparable across jurisdictions with distinct legal traditions and registries. The manuscript states the tasks are 'mapped to structured metadata from national court registries' but provides no evidence (e.g., label cardinalities, input length distributions, or inter-registry alignment metrics) that 'cause category' or 'judgment form' operationalizations have equivalent difficulty or label-set overlap in UA vs. NL vs. FR; this assumption is load-bearing for attributing performance deltas to model capabilities rather than task inequivalence.
minor comments (1)
- [Abstract] The abstract reports specific deltas (UA->FR -2.1 pp, UA->PL -13.7 pp) and correlation (r=-0.27) without stating the exact number of examples or statistical controls used; adding these details would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment raises a valid point about the need for explicit evidence of task comparability across jurisdictions, which we address below by committing to revisions that add the requested metrics.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (task definition): The replication claim (1), transfer patterns (3), and tokenizer analysis (4) all treat the five tasks as comparable across jurisdictions with distinct legal traditions and registries. The manuscript states the tasks are 'mapped to structured metadata from national court registries' but provides no evidence (e.g., label cardinalities, input length distributions, or inter-registry alignment metrics) that 'cause category' or 'judgment form' operationalizations have equivalent difficulty or label-set overlap in UA vs. NL vs. FR; this assumption is load-bearing for attributing performance deltas to model capabilities rather than task inequivalence.
Authors: We agree that the manuscript would be strengthened by providing quantitative evidence of task equivalence to support cross-jurisdictional comparisons. While each task is defined via direct mapping to official national court registry fields (ensuring they reflect real legal metadata rather than synthetic constructs), the current version does not report label cardinalities, input length statistics, or alignment metrics. In the revised manuscript we will add a dedicated subsection (and accompanying table) in §3 that reports, for every filled cell in the 5×6 matrix: (i) number of unique labels, (ii) mean and variance of input token lengths, and (iii) any available label-set overlap statistics. This will allow readers to evaluate the degree of operational equivalence and to interpret performance differences with appropriate caution. We view this addition as directly responsive to the concern and will not alter the core empirical claims. revision: yes
Circularity Check
Pure empirical benchmark evaluation with no derivations or self-referential structure
full rationale
The paper defines a new benchmark (5 tasks mapped to court-registry metadata across 6 jurisdictions) and reports direct empirical results from LLM evaluations under zero- and few-shot prompting. No equations, fitted parameters, predictions derived from prior fits, or load-bearing self-citations appear in the abstract or described claims. All reported deltas, correlations, and replication statements are computed from model outputs on the released data rather than quantities defined in terms of those outputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five tasks can be meaningfully mapped to structured metadata from different national court registries despite varying legal traditions.
Reference graph
Works this paper leans on
-
[1]
Beatriz Canaverde, Telmo Pessoa Pires, Leonor Melo Ribeiro, and André F
URLhttps://arxiv.org/abs/2309.07445. Beatriz Canaverde, Telmo Pessoa Pires, Leonor Melo Ribeiro, and André F. T. Martins. Legal- Bench.PT: A benchmark for Portuguese law.arXiv preprint arXiv:2502.16357,
-
[2]
URL https://arxiv.org/abs/2502.16357. 13 Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Mar- tin Katz, and Nikolaos Aletras. Lexglue: A benchmark dataset for legal language understanding in english. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 4310–4330,
-
[3]
URLhttps://arxiv.org/abs/2110.00976. Nguyen Tien Dong et al. VLegal-Bench: Cognitively grounded benchmark for Vietnamese legal reasoning of large language models.arXiv preprint arXiv:2512.14554,
-
[4]
VLegal-Bench: Cognitively Grounded Benchmark for Vietnamese Legal Reasoning of Large Language Models
URL https://arxiv.org/abs/2512.14554. Yu Fan, Jingwei Ni, Jakob Merane, and Joel Niklaus. LEXam: Benchmarking legal reasoning on 340 law exams.arXiv preprint arXiv:2505.12864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/abs/2512.11297. Neel Guha, Julian Nyarko, Daniel E Ho, Christopher Ré, Adam Chilton, Aditya Narang, Alex Choi, Claudia Gruber, et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 36,
-
[7]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball
URLhttps://arxiv.org/abs/2308.11462. Dan Hendrycks, Collin Burns, Aryeh Chen, and Spencer Ball. Cuad: An expert-annotated NLP dataset for legal contract review. InProceedings of the 35th International Conference on Neural Information Processing Systems,
-
[8]
Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo
URLhttps://arxiv.org/abs/2103.06268. Faris Hijazi, Somayah AlHarbi, Abdulaziz AlHussein, Harethah Abu Shairah, Reem AlZahrani, Hebah AlShamlan, Omar Knio, and George Turkiyyah. ArabLegalEval: A multitask benchmark for assessing Arabic legal knowledge in large language models. InProceedings of the Second Arabic Natural Language Processing Conference (Arabi...
-
[9]
Antreas Ioannou, Andreas Shiamishis, Nora Hollenstein, and Nezihe Merve Gürel
URLhttps:// arxiv.org/abs/2408.07983. Antreas Ioannou, Andreas Shiamishis, Nora Hollenstein, and Nezihe Merve Gürel. Evaluating the limits of large language models in multilingual legal reasoning.arXiv preprint arXiv:2509.22472,
-
[10]
Joel Niklaus, Matthias Stürmer, and Ilias Chalkidis
URLhttps://arxiv.org/abs/2509.22472. Joel Niklaus, Matthias Stürmer, and Ilias Chalkidis. An empirical study on cross-x transfer for legal judgment prediction. InProceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics,
-
[11]
URLhttps://arxiv.org/abs/2209. 12325. Joel Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, Matthias Stürmer, and Ilias Chalkidis. Lextreme: A multi-lingual and multi-task benchmark for the legal domain. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 4973–5006,
2023
-
[12]
Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, and Mark Stevenson
URL https://arxiv.org/abs/2301.13126. Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, and Mark Stevenson. MultiLe- galPile: A 689GB multilingual legal corpus. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
-
[13]
URLhttps://arxiv.org/abs/2306.02069. Volodymyr Ovcharov. The tokenizer tax across 25 European languages: Domain invariance, cross-lingual few-shot effects, and the Ukrainian penalty.arXiv preprint arXiv:2605.24718, 2025a. URLhttps://arxiv.org/abs/2605.24718. Volodymyr Ovcharov. Tokenizer fertility and zero-shot performance on Ukrainian legal text. arXiv p...
- [14]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.