CalBrief: A Pilot Diagnostic Benchmark for Evidence-Calibrated Scientific Briefing with Large Language Models
Pith reviewed 2026-06-29 02:09 UTC · model grok-4.3
The pith
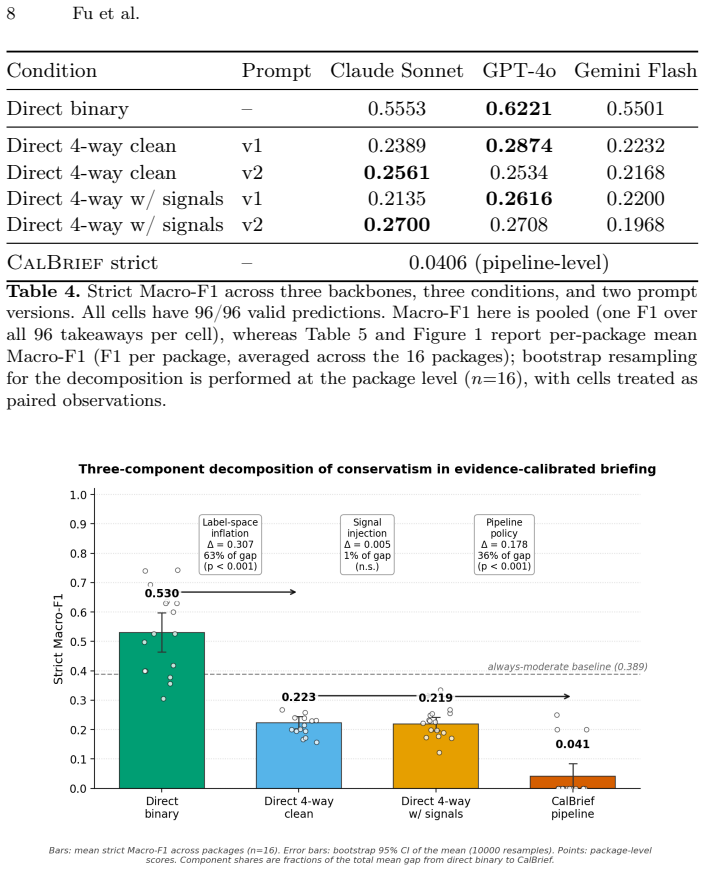
Expanding evidence strength labels from two to four categories accounts for 63% of over-conservatism in LLM scientific briefings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CalBrief demonstrates that an explicit strength-calibration policy is systematically over-conservative relative to majority and direct-LLM baselines. Controlled separation of factors shows that expanding the label space from binary {moderate, weak} to four-way {moderate, weak, uncertain, insufficient_evidence} explains approximately 63% of the conservatism gap across backbones, gap/scope signal injection explains only 1%, and the pipeline policy itself explains the remaining 36%. Four-way predictions can be collapsed post-hoc to binary labels and then match or exceed the performance of direct binary prompting.
What carries the argument
The auditable role/gap/strength framework that decomposes briefing into separate diagnostic components for role reasoning, gap identification, and evidence strength labeling.
If this is right
- Structured organization improves role and gap reasoning but does not resolve over-conservatism in strength calibration.
- Expanding the label space from binary to four-way is the dominant driver of excess caution in the tested pipelines.
- Post-hoc collapsing of four-way strength predictions to binary labels recovers performance that matches or exceeds direct binary prompting.
- Label-level strength judgment and auditable evidence organization are distinct abilities that are currently in tension.
Where Pith is reading between the lines
- Future LLM assistants could maintain parallel tracks for evidence organization and strength assessment rather than forcing both through a single policy.
- The information value of finer-grained labels suggests training regimes that reward accurate uncertainty expression even when downstream outputs remain binary.
- Extending the diagnostic to additional scientific domains would test whether the 63% attribution to label space generalizes beyond the pilot packages.
Load-bearing premise
The 16 heterogeneous evidence packages and 96 human-verified takeaways form a sufficient sample to support general claims about LLM behavior on evidence calibration across scientific domains.
What would settle it
Re-running the three-backbone diagnostic on a new collection of evidence packages and finding that label space expansion no longer accounts for the majority of the conservatism gap.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as research assistants, yet it remains unclear whether they can calibrate research takeaways to the strength and scope of the supporting evidence. We study evidence-calibrated scientific briefing: given a bounded package of related papers, a system should generate package-level takeaways with evidence strength, scope boundaries, and missing-evidence caveats. We contribute a verified pilot benchmark of 16 heterogeneous scientific evidence packages and 96 human-verified takeaways, and we use CalBrief, an auditable role/gap/strength framework, as a diagnostic probe to locate where briefing breaks down. Under a fair-schema evaluation, structured organization improves role and gap reasoning, but an explicit strength-calibration policy is systematically over-conservative and falls below majority and direct-LLM baselines. To explain why, we run a controlled diagnostic across three closed-model backbones (GPT-4o, Claude Sonnet, Gemini Flash) that separates three potential causes of conservatism. Approximately 63% of the conservatism gap is attributable to expanding the label space from binary {moderate, weak} to four-way {moderate, weak, uncertain, insufficient_evidence} (p < 0.001 across all backbones); only 1% is attributable to gap/scope signal injection (not significant); the remaining 36% arises from the pipeline policy itself. We also find that 4-way predictions can be post-hoc collapsed back to binary and then match or exceed direct binary prompting, so the extra labels carry information that strict matching hides. Label-level strength judgment and auditable evidence organization are distinct abilities currently in tension, and should be evaluated separately for LLM research assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CalBrief, a pilot benchmark of 16 heterogeneous scientific evidence packages yielding 96 human-verified takeaways, together with an auditable role/gap/strength framework used as a diagnostic probe. Through controlled variations across three LLM backbones it decomposes over-conservatism in strength labeling, attributing approximately 63% of the gap to expansion from binary to four-way labels (p < 0.001), 1% to gap/scope injection (not significant), and 36% to the pipeline policy itself; it further shows that post-hoc collapse of four-way predictions recovers or exceeds direct binary performance.
Significance. If the attribution holds, the result would usefully separate two distinct LLM capabilities—auditable evidence organization versus calibrated strength judgment—and indicate that richer label spaces carry recoverable information. The controlled diagnostic design and explicit comparison to majority and direct-LLM baselines are methodological strengths; the pilot framing appropriately tempers generalizability claims.
major comments (2)
- [Controlled diagnostic results (abstract and § on diagnostic runs)] The central quantitative claim—that label-space expansion accounts for ~63% of the conservatism gap with p < 0.001—is computed from the identical set of 16 packages that supply the 96 takeaways. No package-level variance, bootstrap intervals, cross-validation, or domain stratification is reported, so both the point estimate and the significance test remain vulnerable to selection effects or domain-specific outliers.
- [Diagnostic results and discussion of label-space effects] The fair-schema evaluation and post-hoc collapse analysis rest on the same small N; while the pilot framing is acknowledged, the manuscript still presents the 63%/1%/36% decomposition as a precise explanatory result rather than an exploratory observation whose stability cannot yet be assessed.
minor comments (1)
- [Abstract] The abstract states the benchmark is a 'pilot' yet reports precise percentages and p-values; a brief sentence clarifying that these figures are descriptive of the current sample would reduce the risk of over-interpretation.
Simulated Author's Rebuttal
We thank the referee for highlighting the statistical limitations of the pilot design. We agree that the small number of packages makes the decomposition exploratory and will revise the manuscript to frame the results more cautiously.
read point-by-point responses
-
Referee: [Controlled diagnostic results (abstract and § on diagnostic runs)] The central quantitative claim—that label-space expansion accounts for ~63% of the conservatism gap with p < 0.001—is computed from the identical set of 16 packages that supply the 96 takeaways. No package-level variance, bootstrap intervals, cross-validation, or domain stratification is reported, so both the point estimate and the significance test remain vulnerable to selection effects or domain-specific outliers.
Authors: We acknowledge that the 63%/1%/36% decomposition is derived from the same 16 packages, with the p-value obtained across backbones rather than packages and without reported package-level variance or bootstrap intervals. As a pilot benchmark we accept that the figures are point estimates from this specific set and are vulnerable to selection effects. We will revise the abstract and diagnostic-results section to state explicitly that the attribution is exploratory, to note the absence of variance estimates, and to avoid presenting the percentages as stable quantities. revision: yes
-
Referee: [Diagnostic results and discussion of label-space effects] The fair-schema evaluation and post-hoc collapse analysis rest on the same small N; while the pilot framing is acknowledged, the manuscript still presents the 63%/1%/36% decomposition as a precise explanatory result rather than an exploratory observation whose stability cannot yet be assessed.
Authors: We agree that the current wording can be read as implying more precision than the sample size supports. Although the pilot framing is already present, we will strengthen the language in the discussion of label-space effects to characterize the decomposition as an observation whose stability remains to be assessed with larger collections. Textual revisions will be made; no new experiments are planned for this pilot study. revision: yes
Circularity Check
No circularity: empirical comparisons against external human ground truth
full rationale
The paper's central claims rest on controlled empirical runs of LLMs against 96 human-verified takeaways from 16 packages. The 63% attribution is computed from direct performance differences across label-space variants, not from any parameter fitted to the target quantity or from a self-referential definition. No step matches the enumerated circularity patterns; the derivation chain is self-contained against the external benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably identify evidence strength, scope boundaries, and missing-evidence caveats in scientific paper packages
invented entities (1)
-
CalBrief auditable role/gap/strength framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cohan, A., Dernoncourt, F., Kim, D., Bui, T., Kim, S., Chang, W., Goharian, N.: A discourse-aware attention model for abstractive summarization of long documents. pp. 615–621 (01 2018). https://doi.org/10.18653/v1/N18-2097
-
[2]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Gao, T., Yen, H., Yu, J., Chen, D.: Enabling large language models to generate text with citations. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 6465–6488 (2023)
2023
-
[3]
Bmj336(7650), 924–926 (2008) 12 Fu et al
Guyatt, G.H., Oxman, A.D., Vist, G.E., Kunz, R., Falck-Ytter, Y., Alonso-Coello, P., Schünemann, H.J.: Grade: an emerging consensus on rating quality of evidence and strength of recommendations. Bmj336(7650), 924–926 (2008) 12 Fu et al
2008
-
[4]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al.: Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[6]
In: 2025 IEEE International Conference on Data Mining (ICDM)
Li, R., Zhang, H., Gehringer, E., Xiao, T., Ding, J., Chen, H.: Unveiling the merits and defects of llms in automatic review generation for scientific papers. In: 2025 IEEE International Conference on Data Mining (ICDM). pp. 1370–1379. IEEE (2025)
2025
-
[7]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Lu, Y., Dong, Y., Charlin, L.: Multi-xscience: A large-scale dataset for extreme multi-document summarization of scientific articles. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 8068–8074 (2020)
2020
-
[8]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Maynez, J., Narayan, S., Bohnet, B., McDonald, R.: On faithfulness and factuality in abstractive summarization. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 1906–1919 (2020)
1906
-
[9]
International journal of surgery8(5), 336–341 (2010)
Moher, D., Liberati, A., Tetzlaff, J., Altman, D.G., Group, P., et al.: Preferred reporting items for systematic reviews and meta-analyses: the prisma statement. International journal of surgery8(5), 336–341 (2010)
2010
-
[10]
Artificial intelligence review57(8), 200 (2024)
Ofori-Boateng, R., Aceves-Martins, M., Wiratunga, N., Moreno-Garcia, C.F.: To- wards the automation of systematic reviews using natural language processing, machine learning, and deep learning: a comprehensive review. Artificial intelligence review57(8), 200 (2024)
2024
-
[11]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Ribeiro, M.T., Wu, T., Guestrin, C., Singh, S.: Beyond accuracy: Behavioral testing of nlp models with checklist. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4902–4912 (2020)
2020
-
[12]
In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
Thorne, J., Vlachos, A., Christodoulopoulos, C., Mittal, A.: Fever: a large-scale dataset for fact extraction and verification. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). pp. 809–819 (2018)
2018
-
[13]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Wadden, D., Lin, S., Lo, K., Wang, L.L., van Zuylen, M., Cohan, A., Hajishirzi, H.: Fact or fiction: Verifying scientific claims. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 7534–7550 (2020)
2020
-
[14]
In: Findings of the Association for Computational Linguistics: EMNLP 2022
Wadden, D., Lo, K., Kuehl, B., Cohan, A., Beltagy, I., Wang, L.L., Hajishirzi, H.: Scifact-open: Towards open-domain scientific claim verification. In: Findings of the Association for Computational Linguistics: EMNLP 2022. pp. 4719–4734 (2022)
2022
-
[15]
Advances in neural information processing systems37, 115119–115145 (2024)
Wang, Y., Guo, Q., Yao, W., Zhang, H., Zhang, X., Wu, Z., Zhang, M., Dai, X., Zhang, M., Wen, Q., et al.: Autosurvey: Large language models can automatically write surveys. Advances in neural information processing systems37, 115119–115145 (2024)
2024
-
[16]
Transactions of the Association for Computational Linguistics13, 529–556 (2025)
Wen, B., Yao, J., Feng, S., Xu, C., Tsvetkov, Y., Howe, B., Wang, L.L.: Know your limits: A survey of abstention in large language models. Transactions of the Association for Computational Linguistics13, 529–556 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.