HPP: Hierarchical Programmatic Probing for Long Video Understanding by Decoupling Perception and Reasoning
Pith reviewed 2026-06-26 14:18 UTC · model grok-4.3
The pith
Decoupling semantic perception from temporal reasoning via programmatic probing improves long video understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
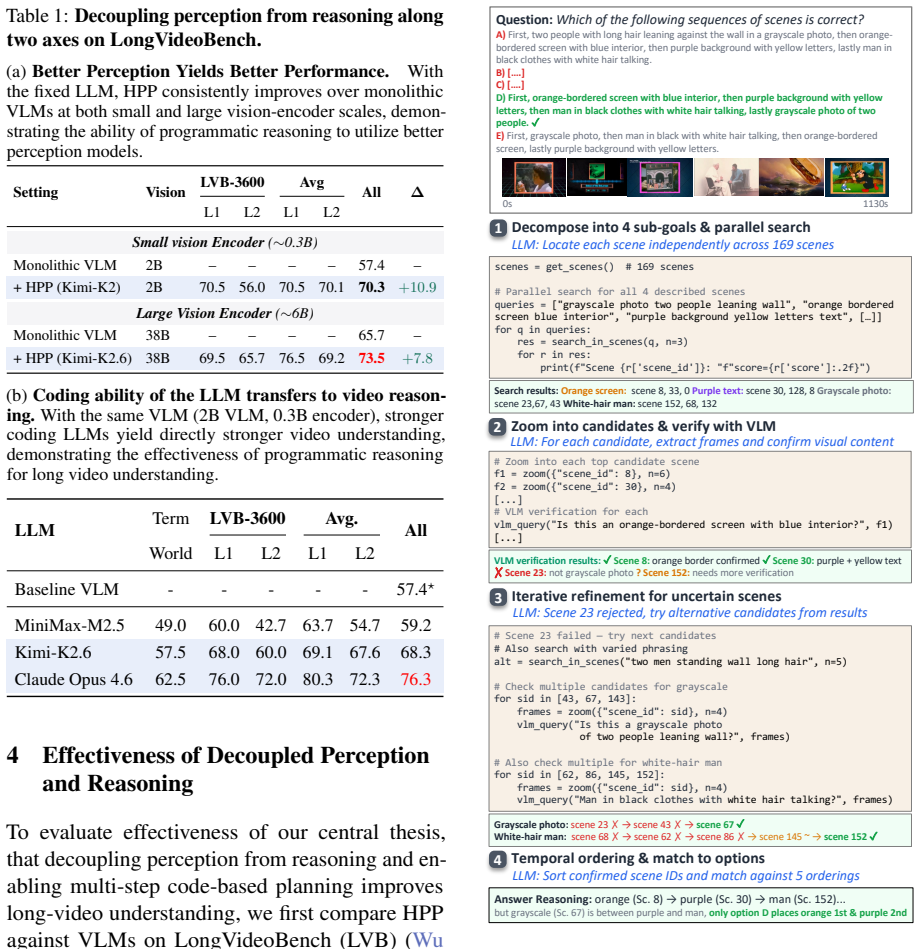
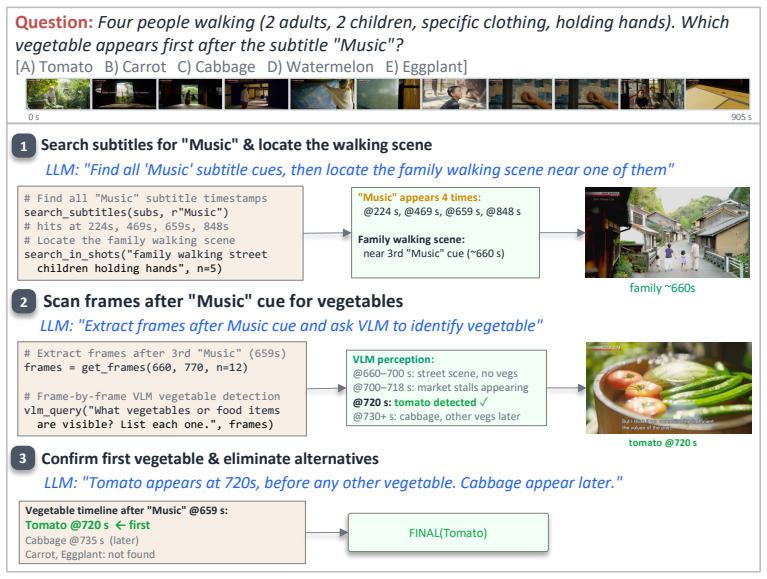
Long video understanding improves when semantic perception is decoupled from higher-order temporal reasoning by recasting the problem as iterative, programmatic exploration of a hierarchically segmented video, with a coding-capable LLM planning multi-step strategies in an interactive coding environment and calling a VLM only for localized perception as needed.
What carries the argument
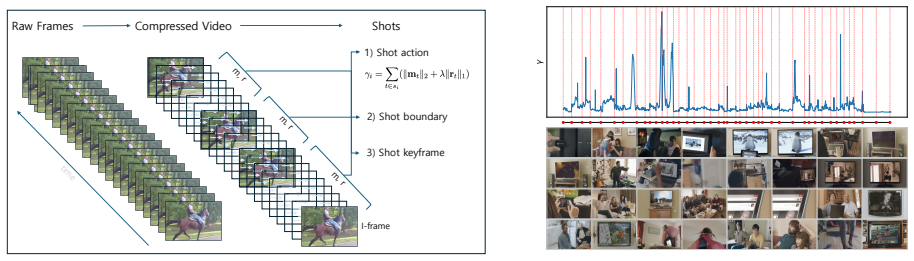
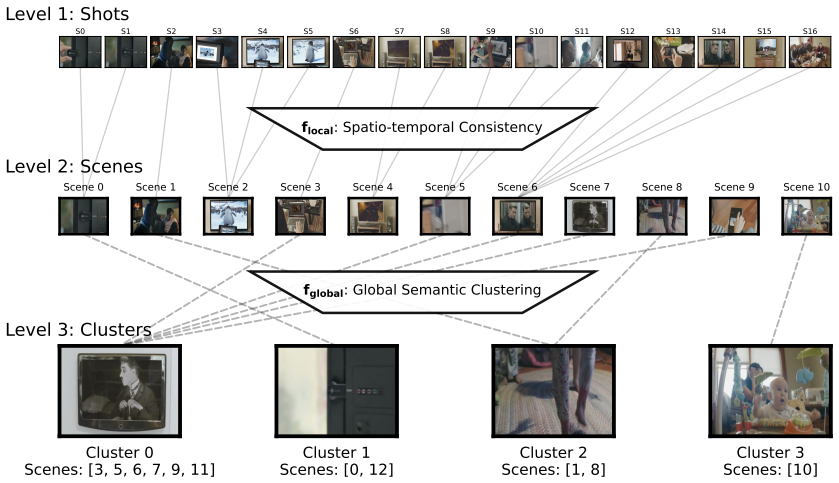
Hierarchical Programmatic Probing (HPP) framework, in which the LLM executes probing strategies via code on an information-density-aware hierarchical video segmentation.
If this is right
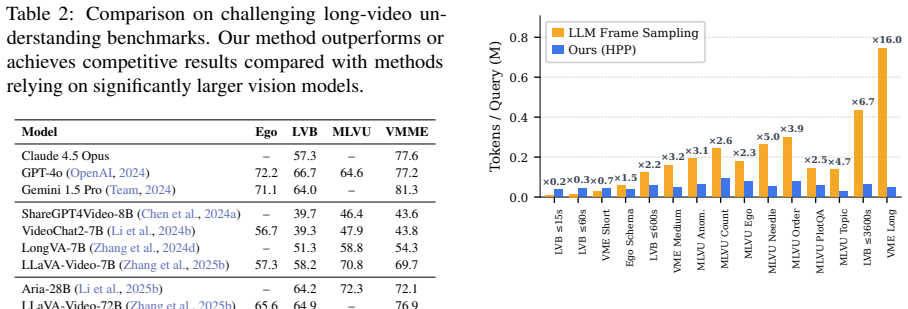
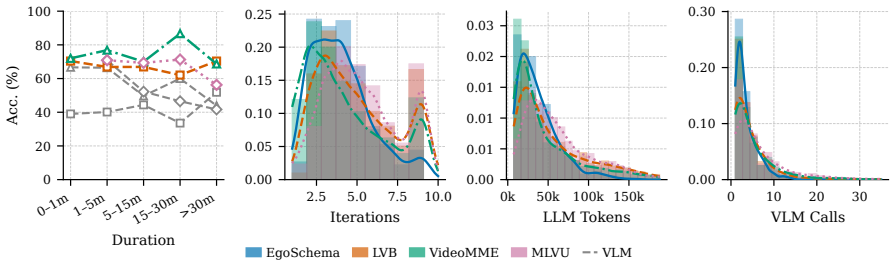
- Substantial performance gains appear on LongVideoBench tasks that require fine-grained perception combined with long-range relational reasoning.
- The same gains hold across EgoSchema, VideoMME, and MLVU, showing the approach generalizes across long-video benchmarks.
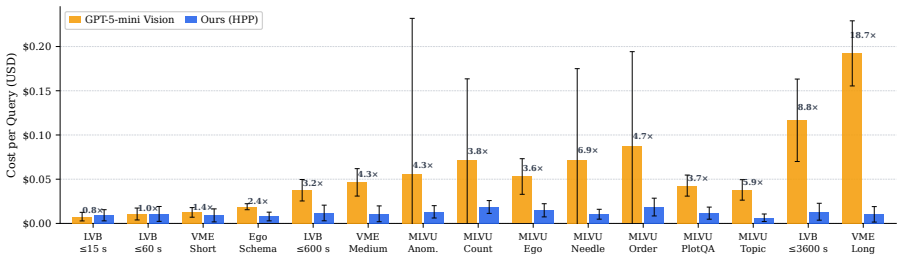
- Probing remains tractable because hierarchical segmentation, late-interaction retrieval, and structured functions limit the scope of each VLM call.
- VLMs are used only for on-demand localized perception, avoiding the latent bottleneck of joint perception-plus-reasoning inside one forward pass.
Where Pith is reading between the lines
- The same separation of planning code from perception calls could extend to other long-sequence multimodal tasks such as audio or document analysis.
- If the LLM's coding reliability improves, the external VLM component might become unnecessary for some benchmarks.
- The information-density segmentation could be replaced by learned boundaries without changing the overall probing architecture.
- Interactive code environments may support more complex agent behaviors beyond the three probing functions defined here.
Load-bearing premise
A coding-capable LLM can reliably plan and execute multi-step probing strategies in an interactive coding environment without hitting its own capacity limits.
What would settle it
Running HPP on LongVideoBench produces no accuracy gain or lower scores than a standard VLM baseline that processes the full video in one pass.
Figures

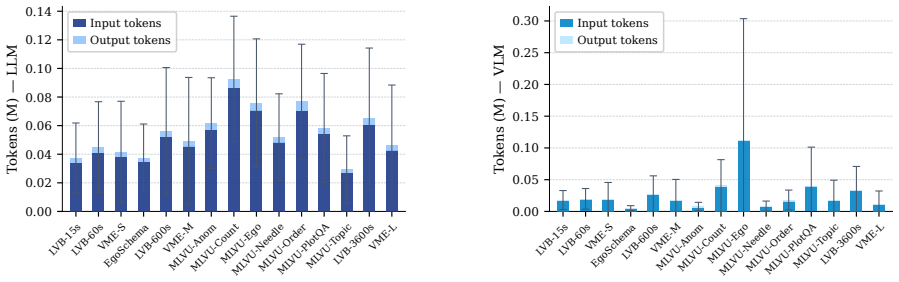
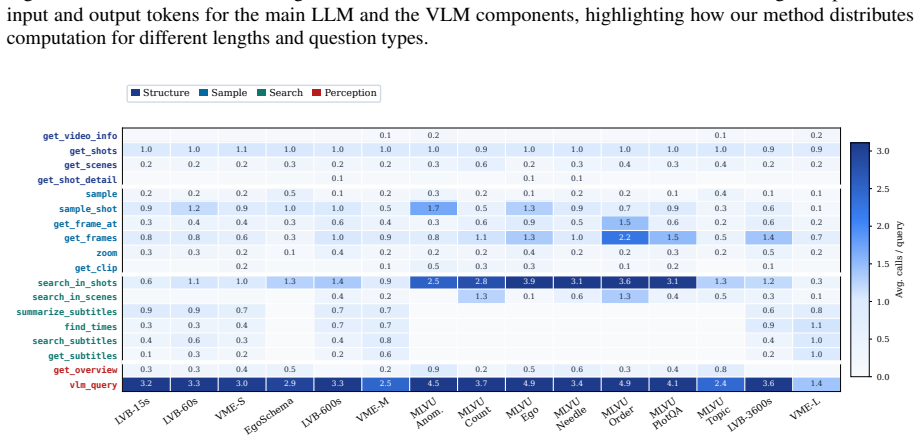
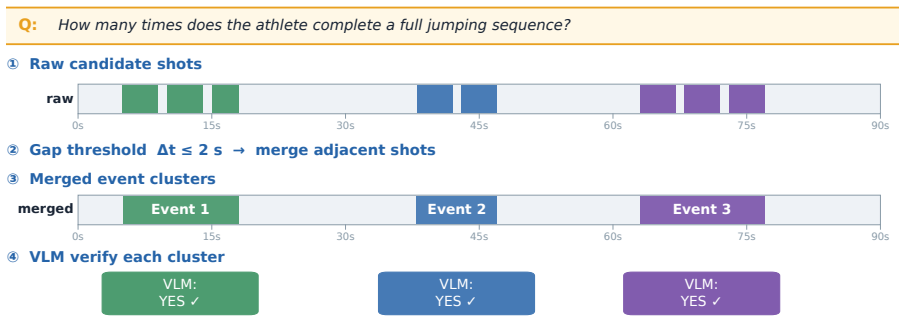
read the original abstract
Understanding long videos requires fine-grained perception and multi-step, higher-order reasoning over complex, long-range spatio-temporal dynamics. Vision-language models (VLMs) encode video frames into visual tokens and attempt to perform both perception and multi-step planning latently, within a single forward pass. This coupled formulation, however, is bottlenecked by the LLM's limited capacity to discover and execute multi-step strategies in its latent representations. To address this bottleneck, we propose Hierarchical Programmatic Probing (HPP), a framework that decouples semantic perception from higher-order temporal reasoning by reformulating long video understanding as iterative, programmatic exploration of a hierarchically segmented video. Specifically, a coding-capable LLM plans and executes a multi-step strategy in an interactive coding environment, probing the video for information and invoking a VLM for localized perception on demand. To make probing tractable over long videos, we introduce three components: information-density-aware hierarchical segmentation, late-interaction semantic retrieval, and structured probing functions for coarse-to-fine temporal localization. We validate HPP on LongVideoBench, which requires both fine-grained perception and long-range relational reasoning, and show that decoupling the two via iterative programmatic probing yields substantial gains. Further results on EgoSchema, VideoMME, and MLVU demonstrate the effectiveness of our approach across diverse long-video benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Hierarchical Programmatic Probing (HPP) to improve long-video understanding. It claims that standard VLMs are limited because they must perform both fine-grained semantic perception and multi-step temporal reasoning within a single latent forward pass. HPP decouples these by reformulating the task as iterative programmatic exploration: a coding-capable LLM plans and executes multi-step strategies inside an interactive coding environment, invoking a VLM only for localized perception queries on demand. Three supporting components are introduced—information-density-aware hierarchical segmentation, late-interaction semantic retrieval, and structured probing functions for coarse-to-fine localization. The approach is evaluated on LongVideoBench (requiring both perception and long-range reasoning) plus EgoSchema, VideoMME, and MLVU, with the central claim that the decoupling yields substantial gains.
Significance. If the reported gains are reproducible and the LLM-driven planning proves reliable across diverse videos, the work would constitute a meaningful engineering advance for long-video tasks. Explicitly separating perception (delegated to VLM) from higher-order strategy execution (handled by code) directly targets a known capacity bottleneck in current VLMs and supplies a falsifiable, interactive alternative to purely latent reasoning.
minor comments (1)
- [Abstract] Abstract: the phrase 'substantial gains' is used without any numerical values or table references; adding a brief quantitative statement (e.g., accuracy deltas on LongVideoBench) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their review and for acknowledging the potential significance of decoupling perception from reasoning via programmatic probing in long-video VLMs. The report does not enumerate any specific major comments, so we have no point-by-point rebuttals to provide.
Circularity Check
No significant circularity; engineering framework with external validation
full rationale
The paper's central claim is an engineering reformulation of long-video tasks as iterative LLM-driven programmatic probing with three explicit components (hierarchical segmentation, semantic retrieval, structured functions). No equations, fitted parameters, or self-referential definitions appear in the provided text. Validation is performed on external benchmarks (LongVideoBench, EgoSchema, etc.) rather than by construction from inputs. No load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is therefore self-contained and independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A coding-capable LLM can plan and execute multi-step probing strategies without the latent capacity bottleneck of standard VLMs
Reference graph
Works this paper leans on
-
[1]
Yu Ai, Ce Xu, and Yansong Bai. 2023. Key frame extraction method based on video compressed domain feature fusion. In Proceedings of the 2023 6th International Conference on Artificial Intelligence and Pattern Recognition, pages 439--444
2023
-
[2]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. 2016. Neural module networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 39--48
2016
-
[3]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In Proceedings of the IEEE international conference on computer vision, pages 5803--5812
2017
-
[4]
Anthropic . 2025. Claude code: Subagents — modular ai workflows with isolated agent contexts. https://docs.anthropic.com/en/docs/claude-code/sub-agents. Accessed: 2026-03-02
2025
-
[5]
Anthropic . 2026 a . https://www.anthropic.com/claude/opus Claude opus 4.6 . Accessed: 2026-03-01
2026
-
[6]
Anthropic . 2026 b . Introducing claude opus 4.6. https://www.anthropic.com/news/claude-opus-4-6. Accessed: 2026-05-26
2026
-
[9]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025 a . Qwen3-vl technical report. arXiv preprint arXiv: 2511.21631
Pith/arXiv arXiv 2025
-
[10]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025 b . Qwen2.5-vl technical report. arXiv preprint arXiv: 2502.13923
Pith/arXiv arXiv 2025
-
[11]
Beauchemin and John L
Steven S. Beauchemin and John L. Barron. 1995. The computation of optical flow. ACM computing surveys (CSUR), 27(3):433--466
1995
-
[12]
Lisa M Brown, Rogerio Feris, and Sharathchandra Pankanti. 2014. Temporal non-maximum suppression for pedestrian detection using self-calibration. In 2014 22nd International Conference on Pattern Recognition, pages 2239--2244. IEEE
2014
-
[13]
Peter J Burt and Edward H Adelson. 1987. The laplacian pyramid as a compact image code. In Readings in computer vision, pages 671--679. Elsevier
1987
-
[16]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, and 1 others. 2024 b . Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling . arXiv preprint arXiv:2412.05271
Pith/arXiv arXiv 2024
-
[18]
Zhaoyang Chu, Jiarui Hu, Xingyu Jiang, Pengyu Zou, Han Li, Chao Peng, Peter O'Hearn, Earl T Barr, Mark Harman, Federica Sarro, and 1 others. 2026. Terminalworld: Benchmarking agents on real-world terminal tasks. arXiv preprint arXiv:2605.22535
Pith/arXiv arXiv 2026
-
[21]
Gao, Chen Sun, Zhenheng Yang, and Ramakant Nevatia
J. Gao, Chen Sun, Zhenheng Yang, and Ramakant Nevatia. 2017 a . https://api.semanticscholar.org/CorpusID:31663499 Tall: Temporal activity localization via language query . 2017 IEEE International Conference on Computer Vision (ICCV), pages 5277--5285
2017
-
[22]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017 b . Tall: Temporal activity localization via language query . In Proceedings of the IEEE international conference on computer vision, pages 5267--5275
2017
-
[23]
Google . 2026. Video understanding. https://ai.google.dev/gemini-api/docs/video-understanding. Gemini API Documentation, Google AI for Developers
2026
-
[24]
Tanmay Gupta and Aniruddha Kembhavi. 2023. Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14953--14962
2023
-
[25]
Shaunak Halbe, Bhagyashree Puranik, Jayakrishnan Unnikrishnan, Kushan Thakkar, Vimal Bhat, and Toufiq Parag. 2026. Virtue: Versatile video retrieval through unified embeddings. arXiv preprint arXiv:2601.12193
Pith/arXiv arXiv 2026
-
[28]
Ronghang Hu, Jacob Andreas, Trevor Darrell, and Kate Saenko. 2018. Explainable neural computation via stack neural module networks. In Proceedings of the European conference on computer vision (ECCV), pages 53--69
2018
-
[29]
Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Kate Saenko. 2017. Learning to reason: End-to-end module networks for visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 804--813
2017
-
[30]
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. 2024. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14271--14280
2024
-
[31]
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. 2025. https://arxiv.org/abs/2501.05874 VideoRAG: Retrieval-Augmented Generation over Video Corpus . Preprint, arXiv:2501.05874
arXiv 2025
-
[32]
Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, and 1 others. 2025. Storm: Token-efficient long video understanding for multimodal llms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5830--5841
2025
-
[33]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. https://openreview.net/forum?id=VTF8yNQM66 Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[34]
Yang Jin, Zhicheng Sun, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, and 1 others. 2024. Video-lavit: unified video-language pre-training with decoupled visual-motional tokenization. In Proceedings of the 41st International Conference on Machine Learning, pages 22185--22209
2024
-
[35]
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Judy Hoffman, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. 2017. Inferring and executing programs for visual reasoning. In Proceedings of the IEEE international conference on computer vision, pages 2989--2998
2017
-
[36]
Kumara Kahatapitiya, Kanchana Ranasinghe, Jongwoo Park, and Michael S Ryoo. 2025. Language repository for long video understanding. In Findings of the Association for Computational Linguistics: ACL 2025, pages 5627--5646
2025
-
[37]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39--48
2020
-
[38]
Jie Lei, Tamara L Berg, and Mohit Bansal. 2021. Detecting moments and highlights in videos via natural language queries . Advances in Neural Information Processing Systems, 34:11846--11858
2021
-
[39]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
Pith/arXiv arXiv 2024
-
[40]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2025 a . https://openreview.net/forum?id=zKv8qULV6n LL a VA -onevision: Easy visual task transfer . Transactions on Machine Learning Research
2025
-
[41]
Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Guoyin Wang, Bei Chen, and Junnan Li. 2025 b . Aria: An Open Multimodal Native Mixture-of-Experts Model . arXiv preprint arXiv:2410.05993
arXiv 2025
-
[45]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, and 1 others. 2024 b . Mvbench: A comprehensive multi-modal video understanding benchmark . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195--22206
2024
-
[46]
Lei Li, Yuanxin Liu, Linli Yao, Peiyuan Zhang, Chenxin An, Lean Wang, Xu Sun, Lingpeng Kong, and Qi Liu. 2025 c . Temporal reasoning transfer from text to video. In International Conference on Learning Representations, volume 2025, pages 74070--74102
2025
-
[47]
Yanwei Li, Chengyao Wang, and Jiaya Jia. 2024 c . Llama-vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, pages 323--340. Springer
2024
-
[48]
Less is more, but where? dynamic token compression via llm-guided keyframe prior
Yulin Li, GUI Haokun, Ziyang Fan, Junjie Wang, Bin Kang, BIN CHEN, and Zhuotao Tian. Less is more, but where? dynamic token compression via llm-guided keyframe prior. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[49]
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. 2023 a . https://doi.org/10.48550/arXiv.2311.10122 Video-llava: Learning united visual representation by alignment before projection . Conference on Empirical Methods in Natural Language Processing
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.10122 2023
-
[50]
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. 2023 b . Univtg: Towards unified video-language temporal grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2794--2804
2023
-
[51]
Bingbin Liu, Serena Yeung, Edward Chou, De-An Huang, Li Fei-Fei, and Juan Carlos Niebles. 2018. https://api.semanticscholar.org/CorpusID:52953290 Temporal modular networks for retrieving complex compositional activities in videos . In European Conference on Computer Vision
2018
-
[52]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36
2023
-
[53]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157--173
2024
-
[54]
Xinfang Liu, Xiushan Nie, Zhifang Tan, Jie Guo, and Yilong Yin. 2021. A survey on natural language video localization. arXiv preprint arXiv:2104.00234
arXiv 2021
-
[55]
Xuyang Liu, Yiyu Wang, Junpeng Ma, and Linfeng Zhang. 2025. Video compression commander: Plug-and-play inference acceleration for video large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1910--1924
2025
-
[56]
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. 2019. Dvc: An end-to-end deep video compression framework. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11006--11015
2019
-
[57]
Yongdong Luo, Xiawu Zheng, Guilin Li, Shukang Yin, Haojia Lin, Chaoyou Fu, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, and 1 others. 2026. Video-rag: Visually-aligned retrieval-augmented long video comprehension. Advances in Neural Information Processing Systems, 38:168008--168033
2026
-
[58]
Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, and Jianfei Cai. 2025. Drvideo: Document retrieval based long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18936--18946
2025
-
[59]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585--12602
2024
-
[60]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. 2023. Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems, 36
2023
-
[61]
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Georgia Gkioxari. 2025. Visual agentic ai for spatial reasoning with a dynamic api. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19446--19455
2025
-
[62]
MiniMax . 2026. Minimax m2.7: Model self-improvement, driving productivity innovation through technological breakthroughs. https://www.minimax.io/models/text/m27. Accessed: 2026-05-26
2026
-
[63]
Hans Georg Musmann, Peter Pirsch, and H-J Grallert. 2005. Advances in picture coding. Proceedings of the IEEE, 73(4):523--548
2005
-
[64]
OpenAI. 2024. https://arxiv.org/abs/2410.21276 GPT-4o System Card . Preprint, arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[65]
OpenAI . 2026 a . https://openai.com/index/introducing-gpt-5-3-codex/ Introducing gpt‑5.3‑codex . OpenAI Blog. Accessed: 2026-03-01
2026
-
[66]
OpenAI . 2026 b . Openai api pricing. https://openai.com/api/pricing/. Accessed: 2026-03-11
2026
-
[67]
https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf Qwen3-coder-next technical report
Qwen Team . https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf Qwen3-coder-next technical report . Technical report. Accessed: 2026-02-03
2026
-
[68]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In ICML
2021
-
[69]
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. 2024. Am-radio: Agglomerative vision foundation model reduce all domains into one. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12490--12500
2024
-
[70]
Arun Reddy, Alexander Martin, Eugene Yang, Andrew Yates, Kate Sanders, Kenton Murray, Reno Kriz, Celso M De Melo, Benjamin Van Durme, and Rama Chellappa. 2025. Video-colbert: Contextualized late interaction for text-to-video retrieval. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19691--19701
2025
-
[72]
Philip Schroeder, Nathaniel W Morgan, Hongyin Luo, and James Glass. 2025. Thread: Thinking deeper with recursive spawning. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8418--8442
2025
-
[78]
Guangyu Sun, Archit Singhal, Burak Uzkent, Mubarak Shah, Chen Chen, and Garin Kessler. 2025. From frames to clips: Training-free adaptive key clip selection for long-form video understanding. arXiv preprint arXiv:2510.02262
arXiv 2025
-
[79]
D \' dac Sur \' s, Sachit Menon, and Carl Vondrick. 2023. Vipergpt: Visual inference via python execution for reasoning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11888--11898
2023
-
[80]
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. 2025. Dycoke: Dynamic compression of tokens for fast video large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18992--19001
2025
-
[81]
Gemini Team. 2024. https://arxiv.org/abs/2403.05530 Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context . Preprint, arXiv:2403.05530
Pith/arXiv arXiv 2024
-
[82]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y. Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, and 307 others. 2026. Kimi k2.5: Visual agentic intelligence. arXiv preprint arXiv: 2602.02276
Pith/arXiv arXiv 2026
-
[83]
Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402--419. Springer
2020
-
[84]
Chen, Zhiwei Xiong, and Jiebo Luo
Hongya Wang, Zhengjun Zha, X. Chen, Zhiwei Xiong, and Jiebo Luo. 2020. https://api.semanticscholar.org/CorpusID:222278500 Dual path interaction network for video moment localization . Proceedings of the 28th ACM International Conference on Multimedia
2020
-
[85]
Jiapeng Wang, Chengyu Wang, Kunzhe Huang, Jun Huang, and Lianwen Jin. 2024 a . Videoclip-xl: Advancing long description understanding for video clip models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16061--16075
2024
-
[86]
Jinpeng Wang, Yixiao Ge, Rui Yan, Yuying Ge, Kevin Qinghong Lin, Satoshi Tsutsui, Xudong Lin, Guanyu Cai, Jianping Wu, Ying Shan, and 1 others. 2023 a . All in one: Exploring unified video-language pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6598--6608
2023
-
[87]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, and 56 others. 2025 a . Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXi...
Pith/arXiv arXiv 2025
-
[89]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. 2025 b . Videoagent: Long-form video understanding with large language model as agent . In European Conference on Computer Vision, pages 58--76. Springer
2025
-
[90]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, and 1 others. 2023 b . Internvid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942
Pith/arXiv arXiv 2023
-
[91]
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Chenting Wang, Guo Chen, Baoqi Pei, Ziang Yan, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, and Limin Wang. 2024 c . Internvideo2: Scaling foundation models for multimodal video understanding. arXiv preprint arXiv: 2403.15377
arXiv 2024
-
[92]
Ying Wang, Yanlai Yang, and Mengye Ren. 2023 c . Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos. arXiv preprint arXiv:2312.05269
arXiv 2023
-
[93]
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. 2025 c . Videotree: Adaptive tree-based video representation for llm reasoning on long videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3272--3283
2025
-
[94]
Aming Wu and Yahong Han. 2018. https://api.semanticscholar.org/CorpusID:51606449 Multi-modal circulant fusion for video-to-language and backward . In International Joint Conference on Artificial Intelligence
2018
-
[95]
a henb \
Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R Manmatha, Alexander J Smola, and Philipp Kr \"a henb \"u hl. 2018. Compressed video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6026--6035
2018
-
[97]
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. 2021. Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv preprint arXiv:2109.14084
arXiv 2021
-
[98]
Yi Xu, Philipp Jettkant, and Laura Ruis. 2026. The depth ceiling: On the limits of large language models in discovering latent planning. arXiv preprint arXiv:2604.06427
Pith/arXiv arXiv 2026
-
[99]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. 2025 a . Visionzip: Longer is better but not necessary in vision language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19792--19802
2025
-
[100]
Yukang Yang, Declan Campbell, Kaixuan Huang, Mengdi Wang, Jonathan Cohen, and Taylor Webb. 2025 b . Emergent symbolic mechanisms support abstract reasoning in large language models. arXiv preprint arXiv:2502.20332
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.