Should LLM Agents Decide in Social Simulations? Comparing Finite-State and LLM-Based Decision Policies
Pith reviewed 2026-06-27 07:55 UTC · model grok-4.3
The pith
LLM action selectors in social simulations do not reliably match the explicit finite-state policy and run hundreds of times slower.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-based action selection in an OSN simulation with 1,000 agents deviates from the reference first-order Markov model with user-type-dependent transitions, as measured by Jensen-Shannon Divergence, with alignment varying by model and prompt strategy, and execution times several hundred times higher than Markov chain sampling.
What carries the argument
The finite-state machine as a first-order Markov model with user-type-dependent transition probabilities, evaluated against LLM outputs via Jensen-Shannon Divergence with Laplace smoothing.
If this is right
- Additional guidance in prompts can introduce systematic biases in action choices.
- Alignment performance varies across different LLMs and prompting strategies.
- LLM configurations do not preserve the reference policy reliably in all cases.
- Direct Markov chain sampling is several hundred times faster than even the best LLM setups.
Where Pith is reading between the lines
- Simulation designers may need to validate LLM decisions against the intended policy before deployment to ensure dynamics match expectations.
- Finite-state models offer exact adherence and speed advantages for scenarios requiring strict policy control.
- Prompt engineering might require model-specific calibration to reduce systematic action biases.
- Deviations could alter long-term interaction patterns in ways not fully captured by per-decision divergence measures.
Load-bearing premise
The finite-state Markov model with user-type-dependent transitions fully captures the intended behavioral policy that the simulation should follow.
What would settle it
Running the same experiments and finding that Jensen-Shannon Divergence stays consistently low for multiple models and prompts without introducing biases would indicate that LLMs do preserve the policy reliably.
Figures


read the original abstract
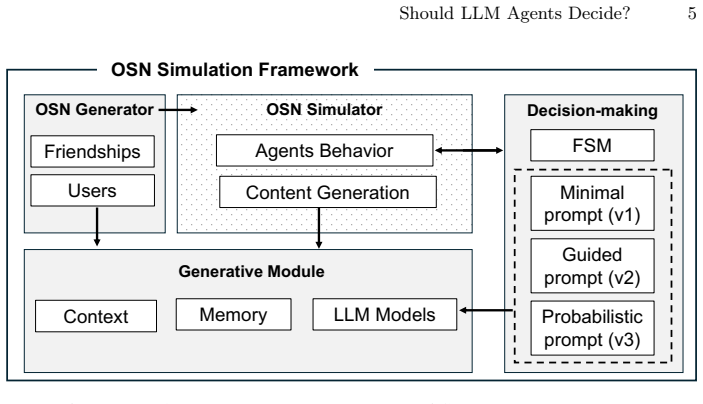
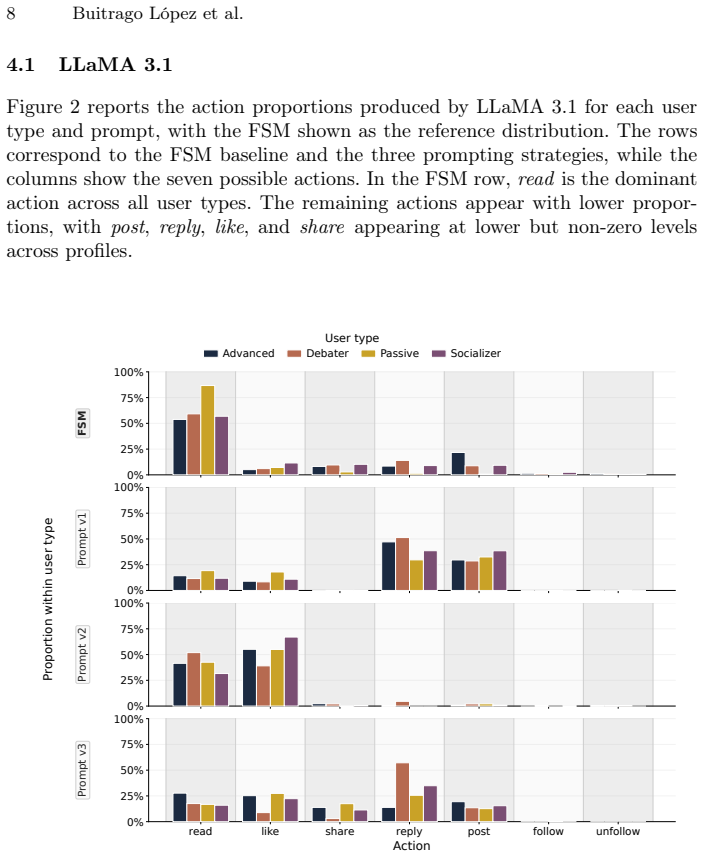
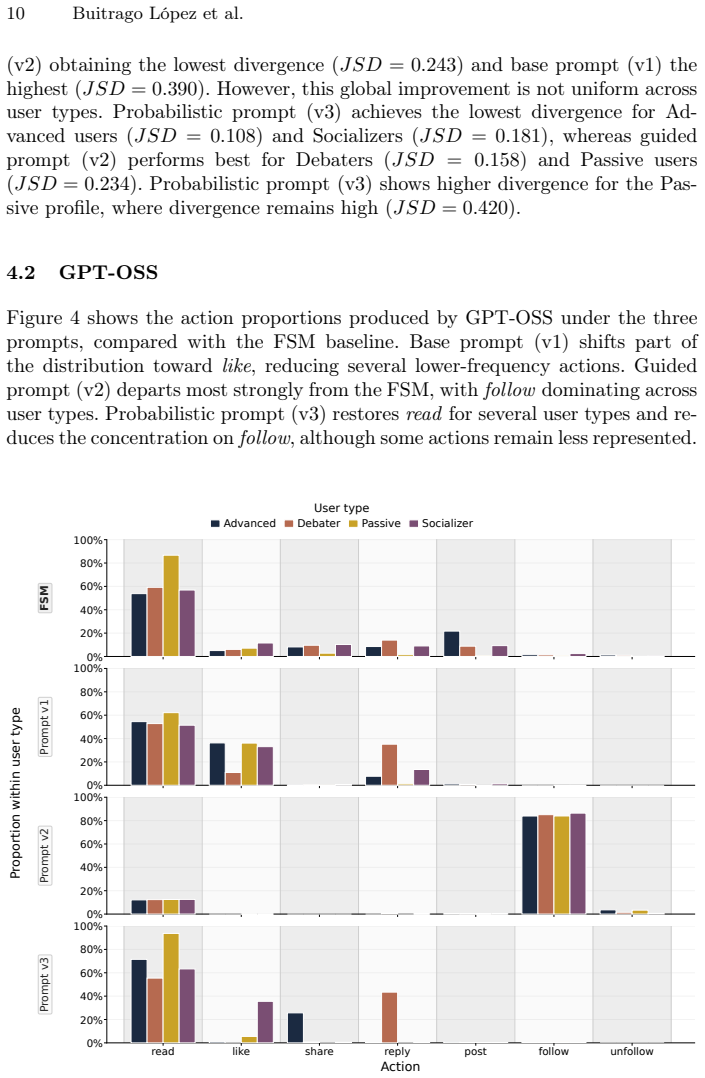
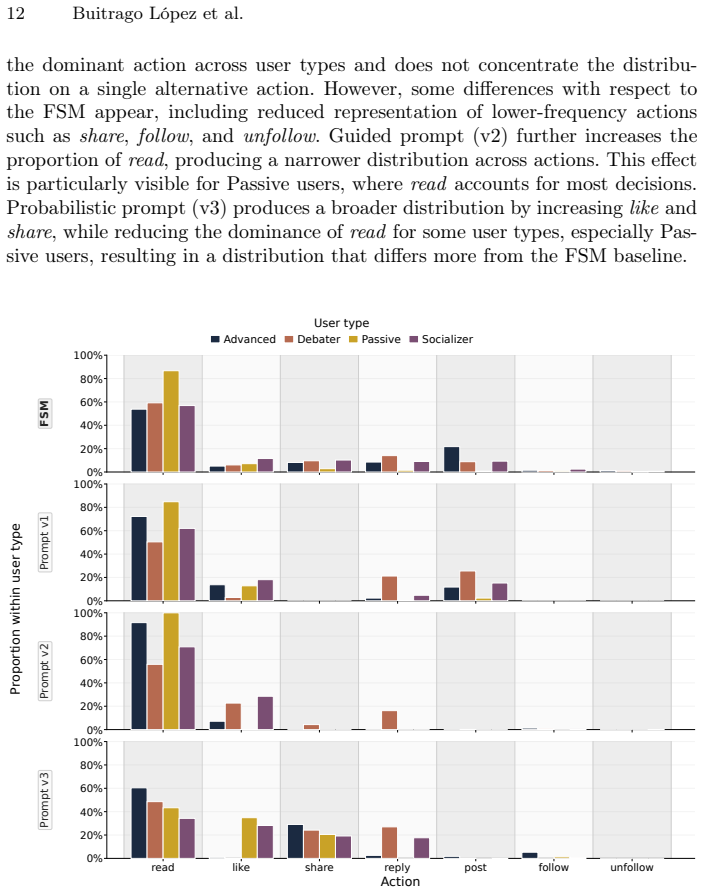
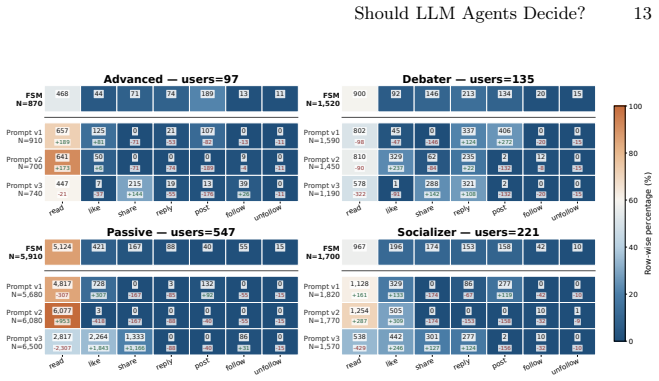
Large language models (LLMs) are increasingly used as decision-making components in social simulations. This introduces a methodological risk: the simulation may deviate from the explicit behavioral policy defined by the researcher. In online social network (OSN) simulations, action choices shape system dynamics, interaction patterns, and model interpretability. This paper evaluates whether LLM action selectors preserve an interpretable reference policy in an OSN simulation. The reference is a finite state machine implemented as a first-order Markov model, with transition probabilities depending on the user type. The evaluation uses a synthetic network with 1,000 agents and 10,000 action decisions. Three open-weight LLMs are tested: LLaMA 3.1, GPT-OSS, and Mistral 24B. Each model is evaluated under three prompting strategies: base, guided, and probabilistic. Alignment is measured using Jensen-Shannon Divergence with Laplace smoothing, and execution time is reported. Results show that LLMs can approximate the reference policy in some configurations, but do not preserve it reliably. Alignment varies across models and prompts, and additional guidance can introduce systematic action biases. Even the best-aligned LLM configurations are several hundred times slower than direct Markov chain sampling. These findings indicate that LLM-based action selection is not a direct replacement for explicit decision policies: it can alter the intended behavior while increasing computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether LLM-based action selectors preserve a reference first-order Markov policy (user-type-dependent transitions) in an OSN simulation. On a synthetic network of 1,000 agents and 10,000 decisions, three open-weight LLMs (LLaMA 3.1, GPT-OSS, Mistral 24B) are tested under base, guided, and probabilistic prompting. Alignment is quantified by Jensen-Shannon Divergence with Laplace smoothing; execution time is also reported. The central finding is that LLMs can approximate the reference policy in some configurations but do not preserve it reliably, additional guidance can introduce systematic biases, and even the best LLM setups are several hundred times slower than direct Markov sampling. The authors conclude that LLM selectors are not a direct replacement for explicit finite-state policies.
Significance. If the empirical results hold, the work supplies concrete evidence that LLM decision components risk deviating from researcher-specified behavioral policies, with direct implications for interpretability and dynamics in social simulations. The evaluation scale (1k agents, 10k decisions), use of JSD with smoothing, and explicit timing comparison are strengths that make the misalignment and cost claims falsifiable and reproducible.
major comments (2)
- [Results / Evaluation] The evaluation (results section) computes JSD on isolated per-decision action distributions but does not execute the full multi-step simulation under LLM policies and compare emergent observables (network structure, interaction sequences, or aggregate statistics) against the reference Markov chain. This leaves unverified whether the measured divergences alter the system dynamics that the abstract and introduction identify as the core motivation for preferring explicit policies.
- [Methods] The methods section does not report the exact prompting templates, the definition of the action space, or any statistical tests (e.g., confidence intervals or permutation tests) on the JSD differences across models/prompts. These omissions are load-bearing for the claims that 'additional guidance can introduce systematic action biases' and that alignment 'varies across models and prompts.'
minor comments (3)
- [Abstract / Methods] Clarify the model name 'GPT-OSS' (is this a specific open-source variant?) and provide version numbers or parameter counts for all three LLMs.
- [Results] Figure or table presenting the per-model, per-prompt JSD values and timing ratios would improve readability; currently the results are described only in prose.
- [Abstract / Results] The abstract states 'several hundred times slower'—include the exact speedup factors and hardware details in the main text for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Results / Evaluation] The evaluation computes JSD on isolated per-decision action distributions but does not execute the full multi-step simulation under LLM policies and compare emergent observables (network structure, interaction sequences, or aggregate statistics) against the reference Markov chain. This leaves unverified whether the measured divergences alter the system dynamics.
Authors: The evaluation targets per-decision policy preservation because the reference is explicitly a first-order Markov model whose transitions depend on user type and state; JSD directly quantifies whether LLM selectors implement the same conditional distributions. Any systematic deviation at this level necessarily changes the sequence of actions and therefore the emergent dynamics. We will revise the discussion to make this connection explicit and note that full multi-step runs would be a natural extension for quantifying effect sizes on observables. revision: partial
-
Referee: [Methods] The methods section does not report the exact prompting templates, the definition of the action space, or any statistical tests (e.g., confidence intervals or permutation tests) on the JSD differences across models/prompts. These omissions are load-bearing for the claims that 'additional guidance can introduce systematic action biases' and that alignment 'varies across models and prompts.'
Authors: We agree these details are necessary for reproducibility. In the revision we will (i) include the complete prompting templates in an appendix, (ii) explicitly define the action space and state representation in the methods, and (iii) report standard deviations of JSD across decisions together with a brief note on variability to support statements about model/prompt differences and guidance-induced biases. revision: yes
Circularity Check
No circularity: empirical JSD comparison to externally defined Markov reference policy
full rationale
The paper defines an independent finite-state Markov reference policy (user-type-dependent transitions) and measures LLM alignment via direct Jensen-Shannon Divergence on 10k sampled decisions. No equations reduce reported alignment scores to quantities fitted from LLM outputs, no self-citation chains support the central claim, and no ansatz or uniqueness theorem is invoked. The evaluation is a straightforward empirical benchmark against an externally specified policy; the derivation chain does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The first-order Markov model with user-type-dependent transitions constitutes the complete intended behavioral policy.
Reference graph
Works this paper leans on
-
[1]
In: Companion Proceedings of The 2019 World Wide Web Conference
Antelmi, A., Malandrino, D., Scarano, V.: Characterizing the behavioral evolution of twitter users and the truth behind the 90-9-1 rule. In: Companion Proceedings of The 2019 World Wide Web Conference. pp. 1035–1038. WWW ’19, Association for Computing Machinery (2019). https://doi.org/10.1145/3308560.3316705
-
[2]
In: Proceedings of the Fourth ACM International Conference on Web Search and Data Mining
Bakshy, E., Hofman, J.M., Mason, W.A., Watts, D.J.: Everyone’s an influencer: Quantifying influence on twitter. In: Proceedings of the Fourth ACM International Conference on Web Search and Data Mining. pp. 65–74. WSDM ’11, Association for Computing Machinery (2011). https://doi.org/10.1145/1935826.1935845
-
[3]
Information Sciences195, 1–24 (2012)
Benevenuto, F., Rodrigues, T., Cha, M., Almeida, V.: Characterizing user navi- gation and interactions in online social networks. Information Sciences195, 1–24 (2012). https://doi.org/10.1016/j.ins.2011.12.009
-
[4]
arXiv preprint arXiv:2512.22082 (2025)
Buitrago López, A., Ortega Pastor, A., Montoro Aguilera, D., Fernández Tár- raga, M., Verdú Chacón, J., Pastor-Galindo, J., Ruipérez-Valiente, J.A.: Agent- based simulation of online social networks and disinformation. arXiv preprint arXiv:2512.22082 (2025)
arXiv 2025
-
[5]
Princeton University Press (2006) 16 Buitrago López et al
Epstein, J.M.: Generative Social Science: Studies in Agent-Based Computational Modeling. Princeton University Press (2006) 16 Buitrago López et al
2006
-
[6]
Hu, T., Liakopoulos, D., Wei, X., Marculescu, R., Yadwadkar, N.J.: Sim- ulating rumor spreading in social networks using llm agents (2025), https://arxiv.org/abs/2502.01450
arXiv 2025
-
[7]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Liu, G., Rahman, S., Kreiss, E., Ghassemi, M., Gabriel, S.: Mosaic: Modeling social ai for content dissemination and regulation in multi-agent simulations. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (2025)
2025
-
[8]
López, A.B., Aguilera, D.M., Pastor-Galindo, J., Ruipérez-Valiente, J.A.: Execu- tion and assessment of agentic influence operations in simulated social networks (2026), https://arxiv.org/abs/2605.28725
Pith/arXiv arXiv 2026
-
[9]
López, A.B., Pastor, A.O., Pastor-Galindo, J., Ruipérez-Valiente, J.A.: Evaluating the realism of llm-powered social agents: A case study of reactions to spanish online news (2026), https://arxiv.org/abs/2605.28598
Pith/arXiv arXiv 2026
-
[10]
López, A.B., Pastor-Galindo, J., Ruipérez-Valiente, J.A.: Frameworks, modeling and simulations of misinformation and disinformation: A systematic literature re- view (2024), https://arxiv.org/abs/2406.09343
arXiv 2024
-
[11]
IEEE Transactions on Computational Social Systems pp
López, A.B., Pastor-Galindo, J., Ruipérez-Valiente, J.A.: Synthetic generation of online social networks through homophily. IEEE Transactions on Computational Social Systems pp. 1–12 (2026). https://doi.org/10.1109/TCSS.2026.3662883
-
[12]
arXiv preprint arXiv:2503.08709 (2025)
Nasim, M., Gilani, S.M., Qasmi, A., Naseem, U.: Simulating influence dynamics with llm agents. arXiv preprint arXiv:2503.08709 (2025)
arXiv 2025
-
[13]
Cambridge University Press, Cambridge, UK (1997)
Norris, J.R.: Markov Chains. Cambridge University Press, Cambridge, UK (1997)
1997
-
[14]
Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Gen- erative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (2023). https://doi.org/10.1145/3586183.3606763
-
[15]
IEEE Security & Privacy22(3), 24–36 (2024)
Pastor-Galindo, J., Nespoli, P., Ruipérez-Valiente, J.A.: Large-language-model- powered agent-based framework for misinformation and disinformation research: Opportunities and open challenges. IEEE Security & Privacy22(3), 24–36 (2024). https://doi.org/10.1109/MSEC.2024.3380511
-
[16]
Rossetti, G., Stella, M., Cazabet, R., Abramski, K., Cau, E., Citraro, S., Failla, A., Improta, R., Morini, V., Pansanella, V.: Y social: an llm-powered social media digital twin (2024), https://arxiv.org/abs/2408.00818
arXiv 2024
-
[17]
In: Companion Proceedings of the ACM Web Conference 2026
Taday Morocho, E.E., Cima, L., Fagni, T., Avvenuti, M., Cresci, S.: As- sessing the reliability of persona-conditioned llms as synthetic survey re- spondents. In: Companion Proceedings of the ACM Web Conference 2026. p. 320–329. WWW Companion ’26, Association for Computing Machin- ery, New York, NY, USA (2026). https://doi.org/10.1145/3774905.3795477, htt...
-
[18]
Uddin, M.M., Imran, M., Sajjad, H.: Understanding types of users on twitter (2014), https://arxiv.org/abs/1406.1335
Pith/arXiv arXiv 2014
-
[19]
arXiv preprint arXiv:2411.11581 (2024)
Yang, Z., Zhang, Z., Zheng, Z., Jiang, Y., Gan, Z., Wang, Z., Ling, Z., Chen, J., Ma, M., Dong, B., Gupta, P., Hu, S., Yin, Z., Li, G., Jia, X., Wang, L., Ghanem, B., Lu, H., Lu, C., Ouyang, W., Qiao, Y., Torr, P., Shao, J.: Oasis: Open agent social interaction simulations with one million agents. arXiv preprint arXiv:2411.11581 (2024)
arXiv 2024
-
[20]
Zhu, Y., He, Y., Haq, E.U., Tyson, G., Hui, P.: Characterizing llm-driven social network: The chirper.ai case (2026), https://arxiv.org/abs/2504.10286
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.