Evaluating the Realism of LLM-powered Social Agents: A Case Study of Reactions to Spanish Online News
Pith reviewed 2026-06-29 12:53 UTC · model grok-4.3
The pith
Off-the-shelf LLMs are poor proxies for real audience reactions to Spanish online news.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
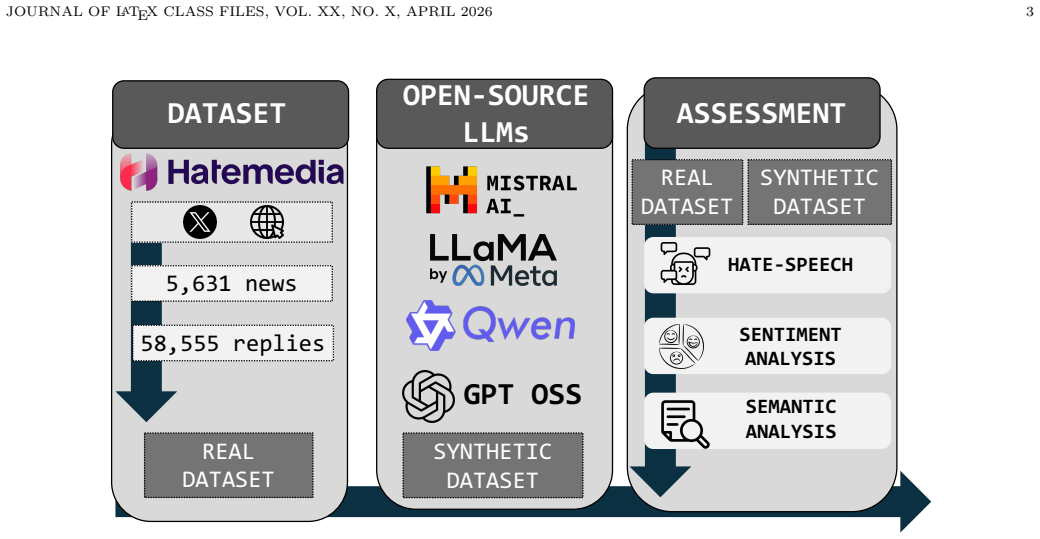
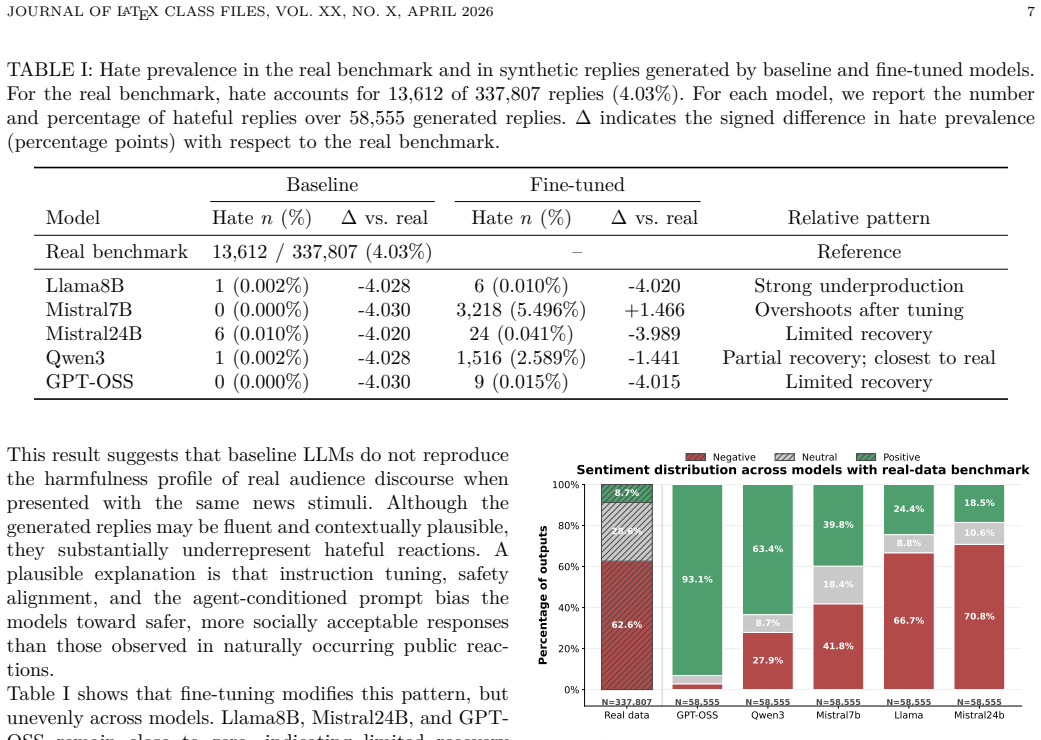
Pairing 5,631 news items with 58,555 real reactions from the Hatemedia dataset and generating matched synthetic reactions with five LLMs shows that off-the-shelf models strongly underproduce hate speech, introduce model-specific sentiment biases, and remain distributionally distant from human replies. Fine-tuning improves fidelity unevenly, with Qwen3 providing the most balanced approximation while Mistral7B achieves stronger sentiment and semantic alignment but overshoots hate prevalence.
What carries the argument
Three-metric comparison of hate speech detection, sentiment scoring, and semantic alignment between real and LLM-generated reactions on the Hatemedia dataset, run on both off-the-shelf and fine-tuned versions of five models.
Load-bearing premise
The three metrics of hate speech, sentiment, and semantic alignment together capture the essential realism of reactive social discourse, and the Hatemedia dataset is a representative sample of typical Spanish online news audience behavior.
What would settle it
A new collection of real audience reactions to the same news items that shows the same low hate speech rates and sentiment distributions as the off-the-shelf LLM outputs would falsify the claim that those models are poor proxies.
Figures

read the original abstract
LLM-powered social agents are increasingly used to simulate online social behavior, yet their realism remains difficult to validate. Existing work has largely relied on general-purpose benchmarks, while less attention has been paid to short, reactive discourse such as audience replies to online news. In this paper, we evaluate whether LLM-generated reactions to Spanish online news reproduce measurable properties of real audience discourse. Using the Hatemedia dataset, we pair 5,631 news items with 58,555 real audience reactions, and generate a matched synthetic dataset using five LLMs under a shared experimental setting. We compare real and synthetic reactions across three dimensions: hate speech, sentiment, and semantic alignment, considering both off-the-shelf and fine-tuned generation. Results show that off-the-shelf models are poor proxies for real audience reactions: they strongly underproduce hate speech, introduce model-specific sentiment biases, and remain distributionally distant from human replies. Fine-tuning improves fidelity unevenly. Qwen3 provides the most balanced approximation, while Mistral7B achieves the strongest sentiment and semantic alignment but overshoots hate prevalence. Plausible synthetic replies do not necessarily reproduce the distributional properties of public discourse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether LLM-generated reactions to Spanish online news reproduce properties of real audience discourse using the Hatemedia dataset (5,631 news items paired with 58,555 real reactions) and a matched synthetic dataset generated by five LLMs. It compares the two across hate speech detection, sentiment scoring, and semantic alignment for both off-the-shelf and fine-tuned models, concluding that off-the-shelf LLMs underproduce hate speech, introduce model-specific sentiment biases, and remain distributionally distant from human replies, while fine-tuning improves fidelity unevenly (Qwen3 most balanced overall).
Significance. If the central empirical comparison holds, the work provides a useful case study on the limitations of LLM-powered social agents for simulating short reactive discourse in a non-English setting, with the matched real-synthetic design offering a controlled basis for the claims. The explicit focus on hate speech and distributional properties is a strength relative to general-purpose benchmarks.
major comments (3)
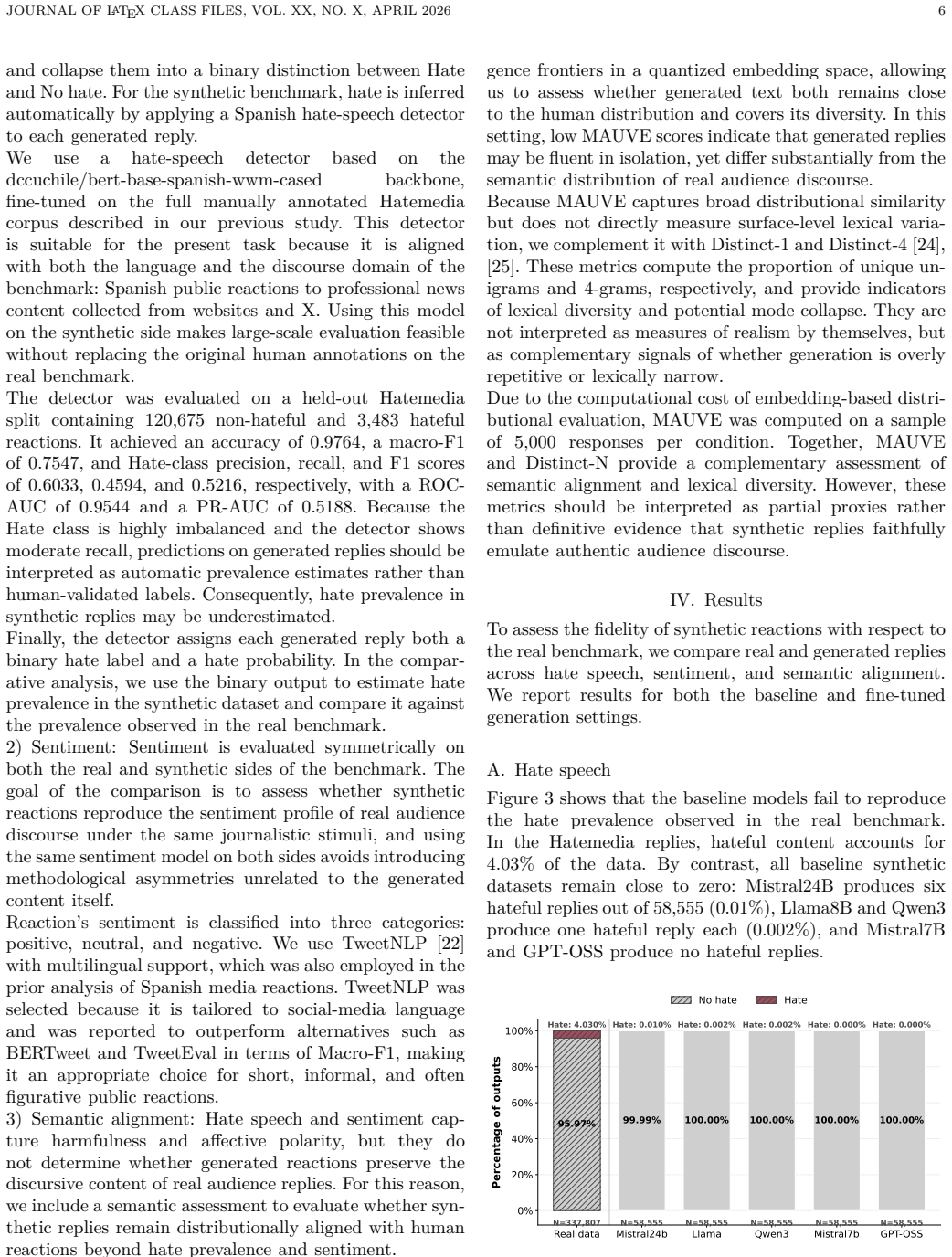
- [Methods and Results] Methods and Results sections: No statistical tests, confidence intervals, or error bars are reported for the differences in hate speech prevalence, sentiment distributions, or semantic alignment scores between real and synthetic reactions. This is load-bearing for the central claim that off-the-shelf models 'strongly underproduce hate speech' and are 'distributionally distant,' as the observed gaps could reflect sampling variability without significance assessment.
- [Evaluation framework] Evaluation framework (implicit in §3–4): The paper assumes without validation that the three metrics (hate speech detection, sentiment scoring, semantic alignment) jointly suffice to characterize the realism of reactive discourse. No comparison is made to other potentially relevant dimensions such as reply-length distribution, lexical diversity, or pragmatic function; if these differ systematically, the headline conclusion that models are poor proxies could be incomplete even if the reported metrics hold.
- [Dataset description] Dataset description: The Hatemedia sample is presented as representative of typical Spanish online news audience behavior without external corroboration (e.g., comparison to other Spanish news-comment datasets or demographic checks). This assumption underpins generalization of the finding that LLMs are poor proxies for real audience reactions.
minor comments (2)
- [Abstract and Methods] The abstract and methods would benefit from explicit mention of the exact prompting strategy and temperature settings used for generation to improve reproducibility.
- [Figures and Tables] Figure captions and table legends should clarify whether the reported percentages for hate speech are raw counts or normalized rates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we address each major comment point by point, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods and Results] Methods and Results sections: No statistical tests, confidence intervals, or error bars are reported for the differences in hate speech prevalence, sentiment distributions, or semantic alignment scores between real and synthetic reactions. This is load-bearing for the central claim that off-the-shelf models 'strongly underproduce hate speech' and are 'distributionally distant,' as the observed gaps could reflect sampling variability without significance assessment.
Authors: We agree that formal statistical assessment is necessary to support the claims. In the revised version we will add bootstrap-derived 95% confidence intervals for hate-speech prevalence and mean sentiment scores, together with chi-squared tests for distributional differences and appropriate pairwise tests for semantic alignment scores. Error bars will be included on all relevant bar and distribution plots. revision: yes
-
Referee: [Evaluation framework] Evaluation framework (implicit in §3–4): The paper assumes without validation that the three metrics (hate speech detection, sentiment scoring, semantic alignment) jointly suffice to characterize the realism of reactive discourse. No comparison is made to other potentially relevant dimensions such as reply-length distribution, lexical diversity, or pragmatic function; if these differ systematically, the headline conclusion that models are poor proxies could be incomplete even if the reported metrics hold.
Authors: The three metrics were chosen because they map directly onto the hate-speech and sentiment phenomena that the Hatemedia corpus was constructed to study. We nevertheless accept that the evaluation is incomplete without additional dimensions. The revision will add a dedicated limitations paragraph and a supplementary figure comparing reply-length distributions and type-token ratios between real and synthetic replies. revision: partial
-
Referee: [Dataset description] Dataset description: The Hatemedia sample is presented as representative of typical Spanish online news audience behavior without external corroboration (e.g., comparison to other Spanish news-comment datasets or demographic checks). This assumption underpins generalization of the finding that LLMs are poor proxies for real audience reactions.
Authors: We will expand the dataset section to cite two additional Spanish news-comment corpora and to state explicitly the outlets and time window covered by Hatemedia, thereby clarifying the scope of generalization rather than claiming broad representativeness. revision: yes
Circularity Check
No circularity: direct empirical comparison to external Hatemedia dataset with no fitted predictions or self-referential derivations.
full rationale
The paper performs an empirical evaluation by pairing real audience reactions from the Hatemedia dataset with LLM-generated reactions and measuring differences on three external metrics (hate speech detection, sentiment scoring, semantic alignment). No equations, parameters fitted to subsets then re-predicted, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the derivation chain. The central claims rest on observable distributional differences between real and synthetic data rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hatemedia dataset reactions constitute a valid ground-truth distribution for Spanish online news audience behavior
- domain assumption Hate speech, sentiment, and semantic alignment metrics together measure realism of reactive discourse
Forward citations
Cited by 1 Pith paper
-
Should LLM Agents Decide in Social Simulations? Comparing Finite-State and LLM-Based Decision Policies
LLM action selection approximates but does not reliably preserve a reference first-order Markov policy in OSN simulations and runs several hundred times slower.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei,...
2020
-
[2]
On the opportunities and risks of foundation models,
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. S. Chatterji, A. S. Chen, K. A. Creel, J. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. X, APRIL 2026 1...
2026
-
[3]
Defending against neural fake news,
R. Zellers, A. Holtzman, H. Rashkin, Y. Bisk, A. Farhadi, F. Roesner, and Y. Choi, “Defending against neural fake news,” in Advances in Neural Information Processing Systems 32, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, Eds. Curran Associates, Inc., 2019, pp. 9054–9065. [Online]. A vailable: http://papers.nips. cc/...
2019
-
[4]
The spread of low-credibility content by social bots,
C. Shao, G. L. Ciampaglia, O. Varol, K. Yang, A. Flammini, and F. Menczer, “The spread of low-credibility content by social bots,” Nature Communications, vol. 9, no. 4787, 2018
2018
-
[5]
Bots increase exposure to negative and inflammatory content in online social systems,
M. Stella, E. Ferrara, and M. D. Domenico, “Bots increase exposure to negative and inflammatory content in online social systems,” Proceedings of the National Academy of Sciences, vol. 115, no. 49, pp. 12 435–12 440, 2018
2018
-
[6]
Llm-assisted topic modeling for hate speech characterization,
A. B. López, J. Pastor-Galindo, and J. A. Ruipérez-Valiente, “Llm-assisted topic modeling for hate speech characterization,” Expert Systems, Oct. 2024. [Online]. A vailable: http://dx.doi. org/10.22541/au.172966882.21215291/v1
-
[7]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, ser. UIST ’23. New York, NY, USA: Association for Computing Machinery, 2023. [Online]. A vailable: https://doi.org/10.1145/3...
-
[8]
Synthetic generation of online social networks through homophily,
A. López Buitrago, J. Pastor‐Galindo, and J. A. Ruipérez‐Valiente, “Synthetic generation of online social networks through homophily,” IEEE Transactions on Computational Social Systems, pp. 1–12, 2026
2026
-
[9]
Understanding news-related user comments and their effects: A systematic review,
E. Kubin, P. Merz, M. Wahba, C. Davis, K. Gray, and C. von Sikorski, “Understanding news-related user comments and their effects: A systematic review,” Frontiers in Communication, vol. 9, p. 1447457, 2024
2024
-
[10]
Content analyses of user comments in journalism: A systematic literature review spanning communication studies and computer science,
J. Reimer, M. Häring, W. Loosen, W. Maalej, and L. Merten, “Content analyses of user comments in journalism: A systematic literature review spanning communication studies and computer science,” Digital Journalism, vol. 9, no. 9, pp. 1294–1314, 2021
2021
-
[11]
Exploring the evolution of sentiment in spanish pandemic tweets: A data analysis based on a fine-tuned bert architecture,
C. Miranda, G. S. Torres, and D. S. Morillo, “Exploring the evolution of sentiment in spanish pandemic tweets: A data analysis based on a fine-tuned bert architecture,” Data, vol. 8, p. 96, 2023. [Online]. A vailable: https: //api.semanticscholar.org/CorpusID:258977706
2023
-
[12]
IEEE Access8, 189069– 189088 (2020).https://doi.org/10.1109/ACCESS.2020.3031572
J. Pastor-Galindo, M. Zago, P. Nespoli, S. L. Bernal, A. H. Celdrán, M. G. Pérez, J. A. Ruipérez-Valiente, G. M. Pérez, and F. G. Mármol, “Spotting political social bots in twitter: A use case of the 2019 spanish general election,” IEEE Trans. on Netw. and Serv. Manag., vol. 17, no. 4, p. 2156–2170, Dec. 2020. [Online]. A vailable: https://doi.org/10.1109...
-
[13]
J. Piao, Y. Yan, J. Zhang, N. Li, J. Yan, X. Lan, Z. Lu, Z. Zheng, J. Y. Wang, D. Zhou et al., “Agentsociety: Large-scale simula- tion of llm-driven generative agents advances understanding of human behaviors and society,” arXiv preprint arXiv:2502.08691, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Z. Yang, Z. Zhang, Z. Zheng, Y. Jiang, Z. Gan, Z. Wang, Z. Ling, J. Chen, M. Ma, B. Dong, P. Gupta, S. Hu, Z. Yin, G. Li, X. Jia, L. Wang, B. Ghanem, H. Lu, C. Lu, W. Ouyang, Y. Qiao, P. Torr, and J. Shao, “Oasis: Open agent social interaction simulations with one million agents,” 2025. [Online]. A vailable:https://arxiv.org/abs/2411.11581
-
[15]
MOSAIC: Modeling social AI for content dissemination and regulation in multi-agent simulations,
G. Liu, V. T. Le, S. Rahman, E. Kreiss, M. Ghassemi, and S. Gabriel, “MOSAIC: Modeling social AI for content dissemination and regulation in multi-agent simulations,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V. Peng, Eds. Suzhou, China: Association for Co...
2025
-
[16]
Characterizing LLM-driven Social Network: The Chirper.ai Case
Y. Zhu, Y. He, E.-U. Haq, G. Tyson, and P. Hui, “Characterizing llm-driven social network: The chirper.ai case,” 2026. [Online]. A vailable:https://arxiv.org/abs/2504.10286
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Botsim: Llm-powered malicious social botnet simulation,
B. Qiao, K. Li, W. Zhou, S. Li, Q. Lu, and S. Hu, “Botsim: Llm-powered malicious social botnet simulation,”
-
[18]
A vailable: https://arxiv.org/abs/2412.13420
[Online]. A vailable: https://arxiv.org/abs/2412.13420
-
[19]
Y social: an llm-powered social media digital twin,
G. Rossetti, M. Stella, R. Cazabet, K. Abramski, E. Cau, S. Citraro, A. Failla, R. Improta, V. Morini, and V. Pansanella, “Y social: an llm-powered social media digital twin,” 2024. [Online]. A vailable: https://arxiv.org/abs/2408.00818
-
[20]
Generative exaggeration in llm social agents: Consistency, bias, and toxicity,
J. Nudo, M. E. Pandolfo, E. Loru, M. Samory, M. Cinelli, and W. Quattrociocchi, “Generative exaggeration in llm social agents: Consistency, bias, and toxicity,” Online Social Networks and Media, vol. 51, p. 100344, 2026. [Online]. A vailable: https://www.sciencedirect.com/science/article/pii/ S246869642500045X
2026
-
[21]
Agent-based simulation of online social networks and disinformation,
A. B. López, A. O. Pastor, D. M. Aguilera, M. F. Tárraga, J. V. Chacón, J. Pastor-Galindo, and J. A. Ruipérez-Valiente, “Agent-based simulation of online social networks and disinformation,” 2025. [Online]. A vailable: https://arxiv.org/abs/2512.22082
-
[22]
“i’m in the bluesky tonight
A. Failla and G. Rossetti, ““i’m in the bluesky tonight”: insights from a year worth of social data,” PloS one, vol. 19, no. 11, p. e0310330, 2024
2024
-
[23]
TweetNLP: Cutting- edge natural language processing for social media,
J. Camacho-collados, K. Rezaee, T. Riahi, A. Ushio, D. Loureiro, D. Antypas, J. Boisson, L. Espinosa Anke, F. Liu, and E. Martínez Cámara, “TweetNLP: Cutting- edge natural language processing for social media,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, W. Che and E. Shutova, Eds. Abu ...
2022
-
[24]
Mauve: Measuring the gap between neural text and human text using divergence frontiers,
K. Pillutla, S. Swayamdipta, R. Zellers, J. Thickstun, S. Welleck, Y. Choi, and Z. Harchaoui, “Mauve: Measuring the gap between neural text and human text using divergence frontiers,” Ad- vances in Neural Information Processing Systems, vol. 34, pp. 4816–4828, 2021
2021
-
[25]
Benchmarking linguistic diversity of large language models,
Y. Guo, G. Shang, and C. Clavel, “Benchmarking linguistic diversity of large language models,” Transactions of the Asso- ciation for Computational Linguistics, vol. 13, pp. 1507–1526, 2025
2025
-
[26]
A diversity-promoting objective function for neural conversation models,
J. Li, M. Galley, C. Brockett, J. Gao, and W. B. Dolan, “A diversity-promoting objective function for neural conversation models,” in Proceedings of the 2016 conference of the North American chapter of the association for computational linguis- tics: human language technologies, 2016, pp. 110–119. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. X, APRIL 2026 1...
2016
-
[27]
He is currently an Associate Professor of Computer Science and Artificial Intelligence at the University of Murcia
in telematics from Universidad Carlos III of Madrid while conducting research with Institute IMDEA Networks in the area of ap- plied data science. He is currently an Associate Professor of Computer Science and Artificial Intelligence at the University of Murcia
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.