PEIRA: Learning Predictive Encoders through Inter-View Regressor Alignment
Pith reviewed 2026-05-20 13:37 UTC · model grok-4.3
The pith
PEIRA defines a non-contrastive SSL objective as the trace of the optimal linear regressor between views to guarantee stable nontrivial equilibria aligned with canonical correlation subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PEIRA defines a non-contrastive SSL objective through the trace of the optimal linear regressor that predicts representations of one view from the other. Its only stable equilibria are the nontrivial global minimizers, which recover the same leading nonlinear canonical correlation subspaces recovered by the earlier stability analysis, with regularization selecting the effective dimension of the learned representations.
What carries the argument
The trace of the optimal linear regressor between inter-view representations, used as an explicit objective that forces alignment with canonical correlation subspaces and prevents collapse.
If this is right
- Stability analysis of the regressor-based predictor explains why self-distillation avoids collapse without explicit negative samples.
- Regularization alone can control the effective dimensionality of the representation without extra hyperparameters.
- PEIRA supplies a theoretically grounded loss that replaces heuristic self-distillation in non-contrastive pipelines.
- The same regressor-trace objective can be applied to other predictive architectures that map multiple views.
Where Pith is reading between the lines
- Extending the linear-regressor analysis to kernel or deep versions of canonical correlation analysis could produce nonlinear variants of PEIRA.
- The stability guarantees may help diagnose collapse modes observed in other non-contrastive methods on different data modalities.
- Replacing the linear regressor with a small neural network inside the objective might preserve the theoretical properties while increasing expressivity.
Load-bearing premise
The analyzed variant of the Joint Embedding Predictive Architecture that uses a regularized linear regressor to predict representations across views accurately captures the essential dynamics of practical non-contrastive SSL methods such as SimSiam, BYOL, I-JEPA or DINO.
What would settle it
Compute the leading nonlinear canonical correlation subspaces on a dataset independently, train PEIRA, and check whether the learned representations align with those subspaces or collapse when regularization strength is varied.
Figures

read the original abstract
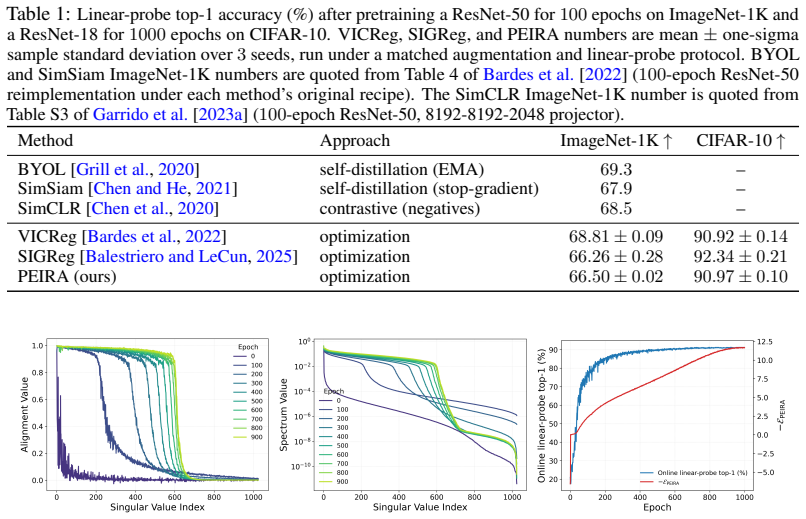
Non-contrastive self-supervised learning (SSL) is an effective framework for predictive representation learning, but popular (and in practice effective) methods such as SimSiam, BYOL, I-JEPA or DINO, which rely on a form of self-distillation to train a teacher-student network, remain poorly understood as they typically do not minimize a well-defined objective. We analyze the dynamics of a variant of the Joint Embedding Predictive Architecture (JEPA) using a regularized linear regressor to predict the learned representations of two views of the data from one another, and fully characterize its stability: non-collapsed stable equilibria align with leading nonlinear canonical correlation subspaces, while collapsed equilibria may also be stable attractors. Motivated by this result, we introduce PEIRA, a non-contrastive SSL method with an explicit objective defined through the trace of the optimal linear regressor. We show that its only stable equilibria are nontrivial global minimizers and recover the same canonical correlation subspaces, with regularization selecting the effective dimension. Experiments on ImageNet-1K and CIFAR-10 show PEIRA is competitive with VICReg and LeJEPA baselines, and qualitative empirical results support the theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the dynamics of a regularized linear regressor variant of the Joint Embedding Predictive Architecture (JEPA) for non-contrastive SSL, fully characterizing its stability to show that non-collapsed stable equilibria align with leading nonlinear canonical correlation subspaces. It then introduces PEIRA, which explicitly defines an objective as the trace of the optimal linear regressor between two views, proving that its only stable equilibria are nontrivial global minimizers recovering the same CCA subspaces (with regularization selecting effective dimension). Experiments report competitive downstream accuracy on ImageNet-1K and CIFAR-10 versus VICReg and LeJEPA, with qualitative results supporting the theory.
Significance. If the stability analysis and equilibrium characterization hold, the work offers a concrete theoretical bridge between popular non-contrastive methods (SimSiam, BYOL, I-JEPA, DINO) and CCA, explaining collapse avoidance and providing an explicit, optimizable objective. The explicit regressor-trace formulation and the claim that regularization controls dimension are notable strengths that could inform future SSL design. Competitive empirical results indicate practical relevance, though stronger direct validation of the CCA-subspace recovery would increase impact.
major comments (2)
- [§4] §4 (stability analysis of the JEPA variant): the proof that only nontrivial global minimizers are stable assumes the linear regressor is optimal at each step, but the derivation does not explicitly bound the deviation when the encoder is updated simultaneously; this leaves open whether the claimed stability carries over to the joint optimization used in PEIRA.
- [§5] §5 (experiments): downstream accuracy on ImageNet-1K and CIFAR-10 is reported, but no quantitative metric (e.g., principal-angle distance or average canonical correlation with the top-k nonlinear CCA directions computed on a controlled synthetic dataset) is given to test whether SGD trajectories actually reach the analyzed CCA equilibria rather than succeeding via unrelated mechanisms.
minor comments (2)
- [Abstract] The abstract states that 'qualitative empirical results support the theory' without naming the visualizations or datasets used; a one-sentence clarification would improve readability.
- [§2] Notation for the two views (x, x') and the encoder outputs (z, z') is introduced gradually; consolidating the definitions in §2 would reduce forward references.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the recognition of the theoretical contributions linking non-contrastive SSL to CCA and the identification of areas where additional clarification and validation would strengthen the manuscript. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4] §4 (stability analysis of the JEPA variant): the proof that only nontrivial global minimizers are stable assumes the linear regressor is optimal at each step, but the derivation does not explicitly bound the deviation when the encoder is updated simultaneously; this leaves open whether the claimed stability carries over to the joint optimization used in PEIRA.
Authors: We thank the referee for this precise observation. The analysis in Section 4 characterizes the equilibria and stability under the assumption that the linear regressor is at its optimum for fixed encoders, corresponding to the exact objective whose critical points we analyze. In PEIRA the loss is defined directly as the trace of this optimal regressor (computable in closed form for the linear case), so the gradient with respect to the encoders is well-defined. In the practical joint optimization we approximate the optimum via a few inner steps or small learning-rate regimes. We will revise Section 4 to include a brief discussion of the approximation error under standard small-step-size conditions for the encoders, showing that the stability conclusions carry over in the continuous-time limit. This addresses the concern without altering the core claims. revision: yes
-
Referee: [§5] §5 (experiments): downstream accuracy on ImageNet-1K and CIFAR-10 is reported, but no quantitative metric (e.g., principal-angle distance or average canonical correlation with the top-k nonlinear CCA directions computed on a controlled synthetic dataset) is given to test whether SGD trajectories actually reach the analyzed CCA equilibria rather than succeeding via unrelated mechanisms.
Authors: We agree that a direct quantitative test of CCA-subspace recovery would provide stronger empirical corroboration of the theory. The reported results emphasize practical downstream performance together with qualitative visualizations that are consistent with the predicted alignment. In the revised manuscript we will add controlled synthetic experiments (data generated from known nonlinear CCA structures) and report quantitative metrics including principal angles and average canonical correlations between the learned subspaces and the top-k ground-truth nonlinear CCA directions. These additions will appear in a new subsection of the experiments and directly address whether optimization reaches the analyzed equilibria. revision: yes
Circularity Check
Objective defined via trace of optimal regressor between representations carries moderate definitional dependence but central CCA equivalence holds independently
specific steps
-
self definitional
[Section 3 (PEIRA objective definition)]
"we introduce PEIRA, a non-contrastive SSL method with an explicit objective defined through the trace of the optimal linear regressor"
The loss is the trace of the regressor that is optimal for the very representations being optimized, so any equilibrium analysis begins from a quantity that is already a direct function of the current encoder outputs rather than an external target.
full rationale
The paper defines PEIRA's objective explicitly as the trace of the optimal linear regressor between the two view representations. This makes the loss value depend directly on the current features by construction, which is the source of the noted moderate burden. However, the stability analysis then derives that equilibria correspond to nonlinear CCA subspaces without reducing the CCA claim itself to a tautology or self-citation; the derivation uses standard linear algebra on the regressor coefficients. No load-bearing self-citation or imported uniqueness theorem is required for the core result. The assumption that the linear-regressor JEPA variant captures practical SSL dynamics is stated as an approximation rather than proven by construction. Overall the derivation chain remains self-contained against external CCA benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter
axioms (1)
- domain assumption The variant of JEPA with a regularized linear regressor models the essential dynamics of self-distillation based non-contrastive SSL methods.
Reference graph
Works this paper leans on
- [1]
-
[2]
M. Arbel and J. Mairal. Amortized implicit differentiation for stochastic bilevel optimization . In International Conference on Learning Representations (ICLR), Nov. 2022. URL https://hal.archives-ouvertes.fr/hal-03455458. working paper or preprint
work page 2022
-
[3]
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, and N. Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619--15629, 2023
work page 2023
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
R. Balestriero and Y. LeCun. Contrastive and non-contrastive self-supervised learning recover global and local spectral embedding methods. Advances in Neural Information Processing Systems, 35: 0 26671--26685, 2022
work page 2022
-
[6]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
R. Balestriero and Y. LeCun. LeJEPA : Provable and scalable self-supervised learning without the heuristics, 2025. URL https://arxiv.org/abs/2511.08544
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
I. Barb a lat. Syst\`emes d'\'equations diff\'erentielles d'oscillations non lin\'eaires. Revue de Math \'e matiques Pures et Appliqu \'e es , 4: 0 267--270, 1959
work page 1959
- [8]
- [9]
-
[10]
R. Bhatia. Matrix analysis. Springer Science & Business Media, 2013
work page 2013
- [11]
-
[12]
Emerging Properties in Self-Supervised Vision Transformers
M. Caron, H. Touvron, I. Misra, H. J \'e gou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [13]
-
[14]
J. Chapman, L. Wells, and A. L. Aguila. Unconstrained stochastic CCA : Unifying multiview and self-supervised learning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=PHLVmV88Zy
work page 2024
-
[15]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597--1607. PmLR, 2020
work page 2020
-
[16]
X. Chen and K. He. Exploring simple siamese representation learning. In Proc. CVPR, 2021
work page 2021
-
[17]
R. Chill. On the ojasiewicz--simon gradient inequality. Journal of Functional Analysis, 201 0 (2): 0 572--601, 2003
work page 2003
- [18]
-
[19]
J. B. Conway. A course in functional analysis. Springer, 2019
work page 2019
-
[20]
M. Dagr \'e ou, P. Ablin, S. Vaiter, and T. Moreau. A framework for bilevel optimization that enables stochastic and global variance reduction algorithms. Advances in Neural Information Processing Systems, 35: 0 26698--26710, 2022
work page 2022
- [21]
-
[22]
A. Ermolov, A. Siarohin, E. Sangineto, and N. Sebe. Whitening for self-supervised representation learning. In International conference on machine learning, pages 3015--3024. PMLR, 2021
work page 2021
-
[23]
P. M. Feehan and M. Maridakis. ojasiewicz--simon gradient inequalities for analytic and morse--bott functions on banach spaces. Journal f \"u r die reine und angewandte Mathematik (Crelles Journal) , 2020 0 (765): 0 35--67, 2020
work page 2020
-
[24]
K. Fukumizu, F. R. Bach, and A. Gretton. Statistical consistency of kernel canonical correlation analysis. J. Mach. Learn. Res., 8: 0 361--383, May 2007. ISSN 1532-4435. URL http://dl.acm.org/citation.cfm?id=1248659.1248673
-
[25]
Closed-Form Last Layer Optimization
A. Galashov, N. Da Costa, L. Xu, P. Hennig, and A. Gretton. Closed-form last layer optimization. arXiv preprint arXiv:2510.04606, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Q. Garrido, R. Balestriero, L. Najman, and Y. LeCun. Rankme: assessing the downstream performance of pretrained self-supervised representations by their rank. In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org, 2023 a
work page 2023
-
[27]
Q. Garrido, Y. Chen, A. Bardes, L. Najman, and Y. LeCun. On the duality between contrastive and non-contrastive self-supervised learning. In The Eleventh International Conference on Learning Representations, 2023 b . URL https://openreview.net/forum?id=kDEL91Dufpa
work page 2023
-
[28]
I. Gohberg, S. Goldberg, and M. A. Kaashoek. Spectral Theory of Compact Self Adjoint Operators, pages 171--191. Birkh \"a user Basel, Basel, 2003. ISBN 978-3-0348-7980-4. doi:10.1007/978-3-0348-7980-4_4. URL https://doi.org/10.1007/978-3-0348-7980-4_4
-
[29]
The "something something" video database for learning and evaluating visual common sense
R. Goyal, S. E. Kahou, V. Michalski, J. Materzyńska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic. The "something something" video database for learning and evaluating visual common sense, 2017. URL https://arxiv.org/abs/1706.04261
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
R. D. Grigorieff. A note on von neumann's trace inequalitv. Mathematische Nachrichten, 151 0 (1): 0 327--328, 1991
work page 1991
-
[31]
J.-B. Grill, F. Strub, F. Altch \'e , C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33: 0 21271--21284, 2020
work page 2020
-
[32]
P. Habets. Stabilit \'e asymptotique pour des probl \`e mes de perturbations singuli \`e res. In Stability Problems, pages 2--18. Springer, 1974
work page 1974
-
[33]
D. R. Hardoon, S. Szedmak, and J. Shawe-Taylor. Canonical correlation analysis: An overview with application to learning methods. Neural Computation, 16 0 (12): 0 2639--2664, 2004. doi:10.1162/0899766042321814
-
[34]
K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick. Momentum contrast for unsupervised visual representation learning. In Proc. CVPR, 2020
work page 2020
-
[35]
Deep Learning Scaling is Predictable, Empirically
J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y. Yang, and Y. Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [36]
-
[37]
M. Huh, B. Cheung, T. Wang, and P. Isola. The platonic representation hypothesis. arXiv preprint arXiv:2405.07987, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Y. Jia, F. Nie, and C. Zhang. Trace ratio problem revisited. IEEE Transactions on Neural Networks, 20 0 (4): 0 729--735, 2009
work page 2009
-
[39]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[40]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman. The kinetics human action video dataset, 2017. URL https://arxiv.org/abs/1705.06950
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[42]
H. O. Lancaster. The structure of bivariate distributions. The Annals of Mathematical Statistics, 29 0 (3): 0 719--736, 1958
work page 1958
-
[43]
Y. LeCun. A path towards autonomous machine intelligence. OpenReview, Jun 2022
work page 2022
-
[44]
J. D. Lee, M. Simchowitz, M. I. Jordan, and B. Recht. Gradient descent only converges to minimizers. In Conference on Learning Theory, pages 1246--1257. PMLR, 2016
work page 2016
-
[45]
E. Littwin, O. Saremi, M. Advani, V. Thilak, P. Nakkiran, C. Huang, and J. Susskind. How jepa avoids noisy features: The implicit bias of deep linear self distillation networks. Advances in Neural Information Processing Systems, 37: 0 91300--91336, 2024
work page 2024
-
[46]
S. Lojasiewicz. Sur les trajectoires du gradient d'une fonction analytique. Seminari di geometria, 1983: 0 115--117, 1982
work page 1983
- [47]
-
[48]
Nonparametric Canonical Correlation Analysis
T. Michaeli, W. Wang, and K. Livescu. Nonparametric canonical correlation analysis. arXiv preprint arXiv:1511.04839, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
D. Morales-Brotons, T. Vogels, and H. Hendrikx. Exponential moving average of weights in deep learning: Dynamics and benefits. Transactions on Machine Learning Research, 2024. URL https://openreview.net/forum?id=2M9CUnYnBA
work page 2024
- [50]
-
[51]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [52]
-
[53]
B. Shi, W. Su, and M. I. Jordan. On learning rates and schr \"o dinger operators. Journal of Machine Learning Research, 24 0 (379): 0 1--53, 2023
work page 2023
-
[54]
O. Sim \'e oni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al. DINOv3 . arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
V. Sobal, W. Zhang, K. Cho, R. Balestriero, T. G. Rudner, and Y. LeCun. Learning from reward-free offline data: A case for planning with latent dynamics models. arXiv preprint arXiv:2502.14819, 2025
-
[56]
L. Sun, S. Ji, and J. Ye. A least squares formulation for a class of generalized eigenvalue problems in machine learning. In Proceedings of the 26th annual international conference on machine learning, pages 977--984, 2009
work page 2009
-
[57]
R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction. The MIT Press, 2 edition, 2018. ISBN 9780262039246
work page 2018
-
[58]
Y. Tang, Z. D. Guo, P. H. Richemond, B. A. Pires, Y. Chandak, R. Munos, M. Rowland, M. G. Azar, C. Le Lan, C. Lyle, et al. Understanding self-predictive learning for reinforcement learning. In International Conference on Machine Learning, pages 33632--33656. PMLR, 2023
work page 2023
- [59]
-
[60]
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
B. Terver, T.-Y. Yang, J. Ponce, A. Bardes, and Y. LeCun. What drives success in physical planning with joint-embedding predictive world models?, 2026 b . URL https://arxiv.org/abs/2512.24497
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
G. Teschl. Ordinary differential equations and dynamical systems. Graduate Studies in Mathematics, 140: 0 08854--8019, 2000
work page 2000
-
[62]
Y. Tian, X. Chen, and S. Ganguli. Understanding self-supervised learning dynamics without contrastive pairs. In International Conference on Machine Learning, pages 10268--10278. PMLR, 2021
work page 2021
-
[63]
T. T. Truong. Some convergent results for backtracking gradient descent method on banach spaces, 2020
work page 2020
-
[64]
H. Wang, S. Yan, D. Xu, X. Tang, and T. Huang. Trace ratio vs. ratio trace for dimensionality reduction. In 2007 IEEE Conference on Computer Vision and Pattern Recognition, pages 1--8. IEEE, 2007
work page 2007
-
[65]
M. Wang, E. X. Fang, and H. Liu. Stochastic compositional gradient descent: algorithms for minimizing compositions of expected-value functions. Mathematical Programming, 161 0 (1--2): 0 419--449, 2017
work page 2017
- [66]
- [67]
-
[68]
Y. You, I. Gitman, and B. Ginsburg. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[69]
J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny. Barlow twins: Self-supervised learning via redundancy reduction. In International Conference on Machine Learning, pages 12310--12320. PMLR, 2021
work page 2021
- [70]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.