Hierarchical Reinforcement Learning in StarCraft Micromanagement with Influence Maps and Cluster-based Scripts
Pith reviewed 2026-06-30 05:57 UTC · model grok-4.3
The pith
A hierarchical reinforcement learning framework using influence map hashing and cluster-based scripts matches deep RL performance in StarCraft micromanagement with better sample efficiency and interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The HRL-IM/CBS framework uses influence map hashing to encode battlefield situations into compact hexadecimal codes and cluster-based scripts for adaptive unit partitioning, enabling a hierarchical multi-Q-table architecture that decomposes decisions into upper-level strategy selection and lower-level tactical execution with reward allocation for dense signals.
What carries the argument
Influence map hashing into hexadecimal codes and cluster-based scripts within a hierarchical multi-Q-table architecture for decomposing micromanagement decisions.
If this is right
- Provides transparent Q-table representations instead of black-box models.
- Generates denser learning signals through hierarchical reward allocation.
- Achieves competitive performance against deep RL baselines in asymmetric scenarios.
- Offers improved sample efficiency in multi-unit coordination tasks.
Where Pith is reading between the lines
- The encoding method may apply to other multi-agent spatial control problems beyond StarCraft.
- Interpretability of Q-tables could support strategy analysis and improvement by humans.
- The approach might be tested for generalization to symmetric battles or larger unit counts.
Load-bearing premise
The assumption that influence map hashing into hexadecimal codes plus cluster-based scripts can capture sufficient spatial and coordination information to support effective hierarchical decomposition without critical loss of state detail.
What would settle it
A new experiment in an asymmetric scenario where the method achieves substantially lower win rates than deep RL baselines would show that the state representation loses critical information.
Figures

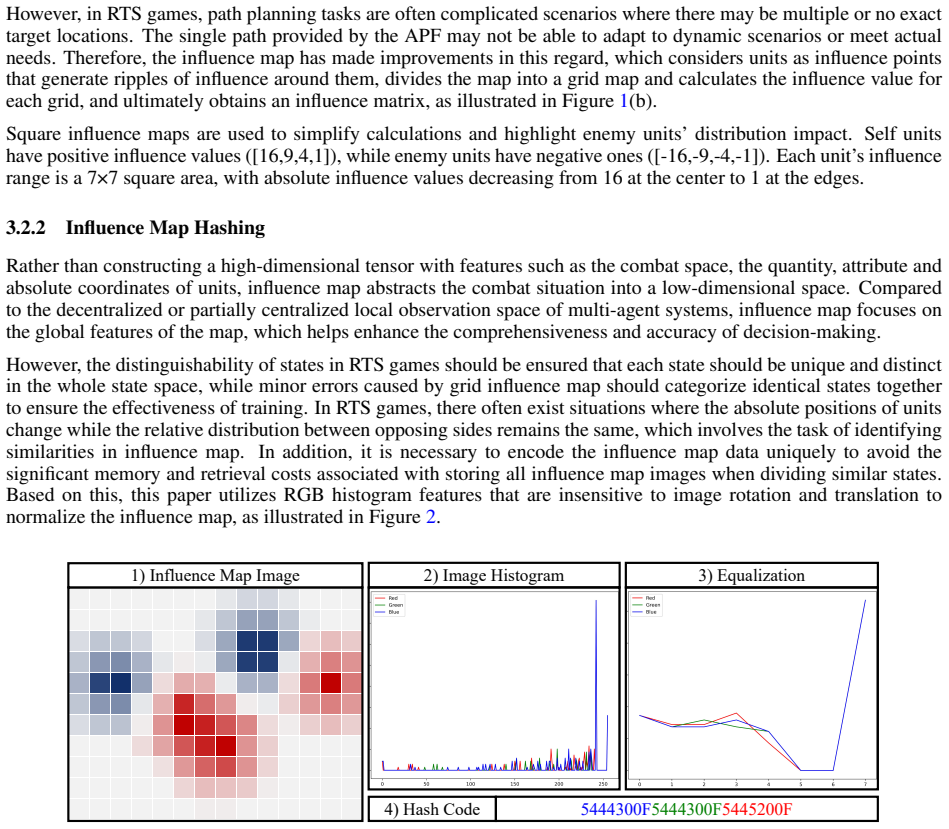
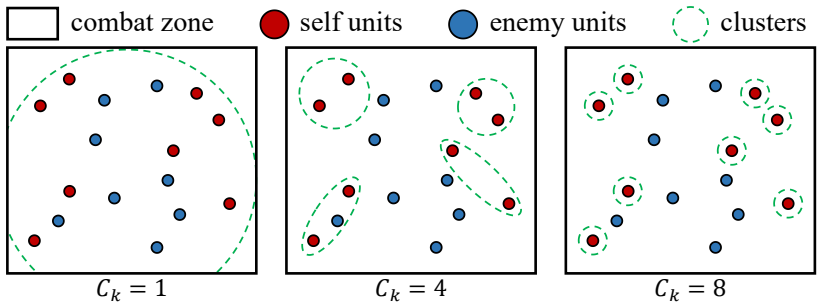
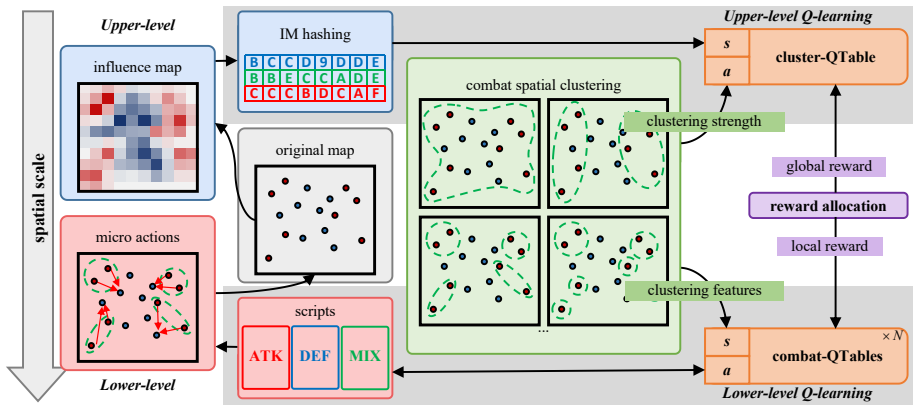
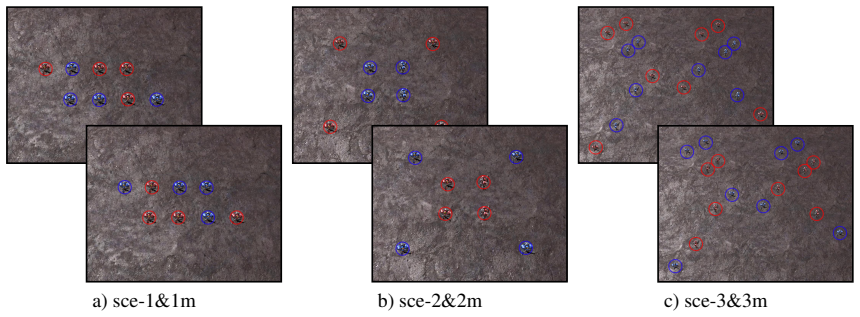
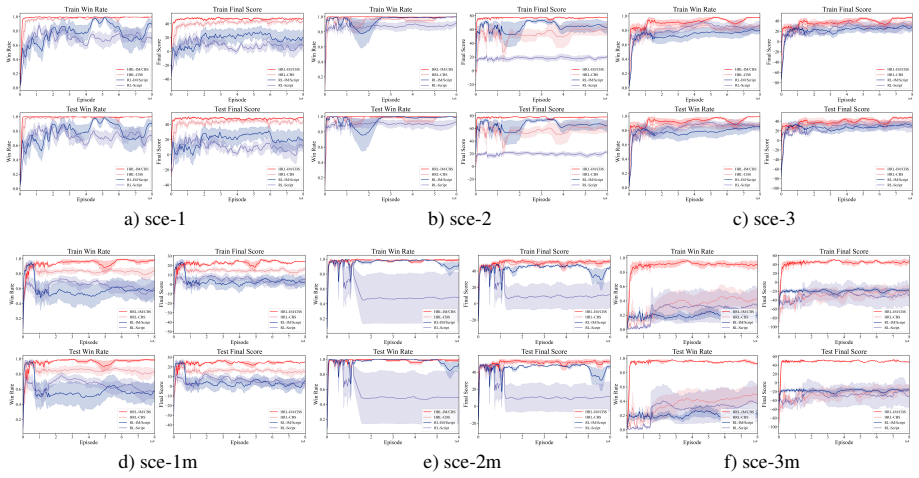
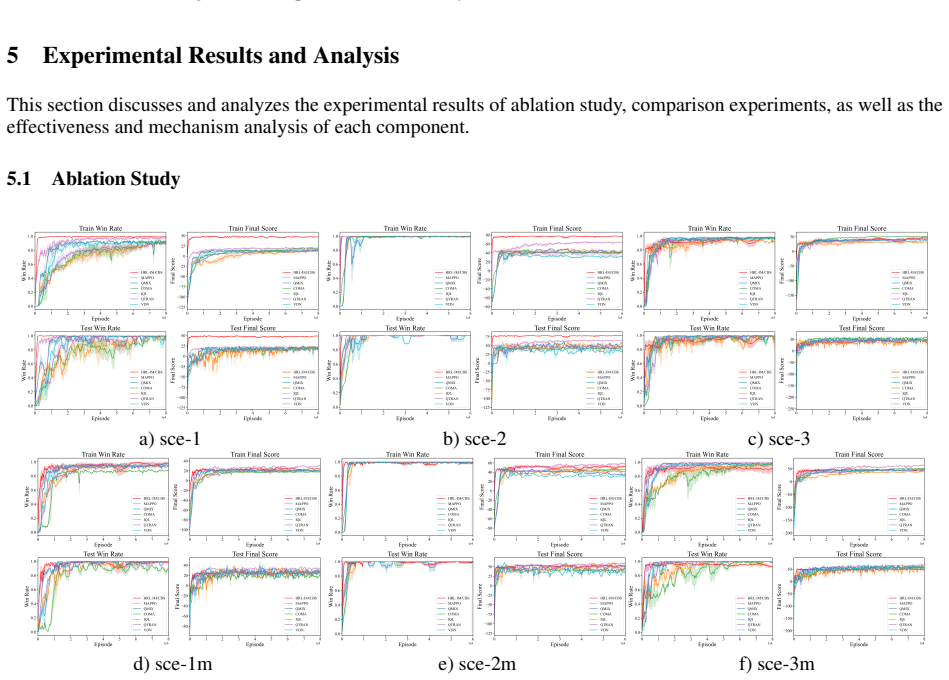
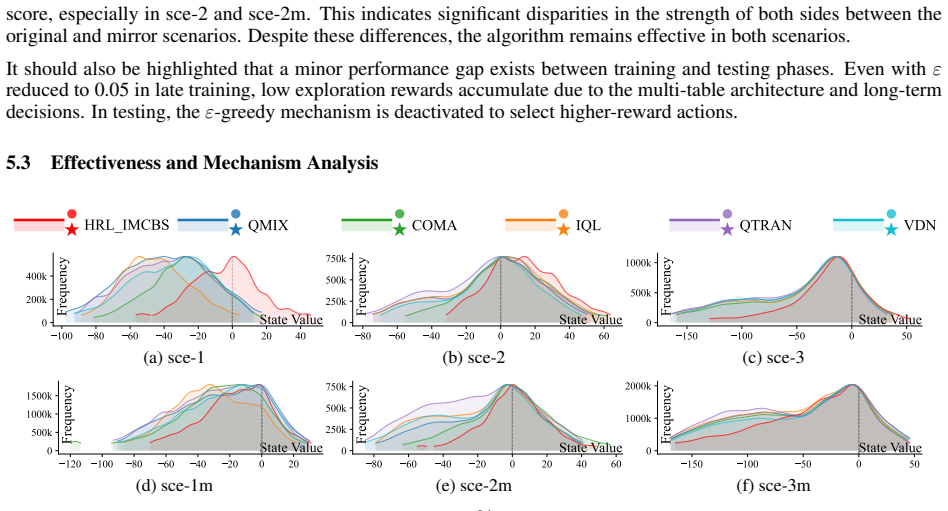
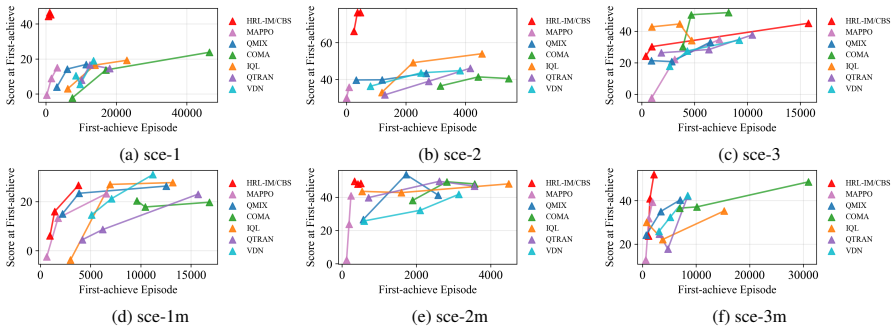
read the original abstract
Real-time strategy (RTS) games present significant AI challenges, characterized by expansive state-action spaces arising from multi-unit coordination in continuous battlefields, and sparse delayed rewards stemming from final win/lose signals. Existing approaches face a trade-off between managing the dimensionality explosion of joint actions and maintaining the interpretability of complex state representations. This complexity is further intensified by the limitation of traditional hierarchical structures in adaptively decomposing tasks into effective tactical modules. Such difficulties are compounded by the black-box nature of deep learning models and their reliance on sparse rewards, which together result in limited sample efficiency and a lack of decision-making transparency. To address these limitations, this paper proposes HRL-IM/CBS, a hierarchical reinforcement learning framework with influence map hashing and cluster-based scripts for StarCraft micromanagement. Influence map hashing encodes global battlefield situations into compact hexadecimal codes, capturing spatial control and relative advantage. Cluster-based scripts enable dynamic local coordination through adaptive unit partitioning. The hierarchical multi-Q-table architecture decomposes decision-making into upper-level clustering strategy selection and lower-level tactical execution, with reward allocation providing dense learning signals. Experiments across six asymmetric scenarios demonstrate competitive performance against deep RL baselines while offering advantages in sample efficiency and interpretability through transparent Q-table representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HRL-IM/CBS, a hierarchical reinforcement learning framework for StarCraft micromanagement. Influence maps are hashed into hexadecimal codes to encode global battlefield states capturing spatial control and relative advantage; cluster-based scripts handle dynamic local unit coordination. A multi-Q-table architecture decomposes decisions into upper-level clustering strategy selection and lower-level tactical execution, with reward allocation to provide denser signals. The abstract claims that experiments across six asymmetric scenarios demonstrate competitive performance against deep RL baselines together with advantages in sample efficiency and interpretability via transparent Q-table representations.
Significance. If the empirical claims are substantiated, the framework would supply an interpretable, sample-efficient alternative to black-box deep RL for high-dimensional RTS micromanagement tasks, directly addressing the dimensionality explosion, sparse rewards, and lack of transparency noted in the introduction.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'demonstrate[s] competitive performance against deep RL baselines' while offering 'advantages in sample efficiency' is unsupported by any quantitative results, baseline descriptions, statistical tests, ablation studies, or performance tables, rendering the primary empirical assertion unevaluable from the manuscript.
- [Abstract] Abstract (framework paragraph): the assertion that influence-map hashing 'encodes global battlefield situations into compact hexadecimal codes, capturing spatial control and relative advantage' supplies no bound on quantization error or proof that distinct local configurations map to distinct codes; without this, the precondition that the upper-level Q-table can reliably select useful decompositions is unsecured and directly undermines both the performance and interpretability claims.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying areas where the abstract could better convey the manuscript's empirical and theoretical support. We address each major comment below and outline revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'demonstrate[s] competitive performance against deep RL baselines' while offering 'advantages in sample efficiency' is unsupported by any quantitative results, baseline descriptions, statistical tests, ablation studies, or performance tables, rendering the primary empirical assertion unevaluable from the manuscript.
Authors: The full manuscript (Section 4) contains the requested elements: win-rate tables across the six scenarios, learning curves demonstrating sample efficiency gains, explicit baseline descriptions (including DQN, QMIX, and MAPPO variants), ablation studies on the influence-map and cluster-based components, and statistical significance testing. The abstract summarizes these results at a high level. To make the abstract self-contained and directly address the concern, we will revise it to include brief quantitative highlights (e.g., average win rates and training-step reductions) with pointers to the corresponding tables and figures. revision: yes
-
Referee: [Abstract] Abstract (framework paragraph): the assertion that influence-map hashing 'encodes global battlefield situations into compact hexadecimal codes, capturing spatial control and relative advantage' supplies no bound on quantization error or proof that distinct local configurations map to distinct codes; without this, the precondition that the upper-level Q-table can reliably select useful decompositions is unsecured and directly undermines both the performance and interpretability claims.
Authors: The hashing procedure discretizes the battlefield grid and quantizes influence values into a small number of discrete levels before converting to hexadecimal; this is a deterministic, lossy encoding chosen for compactness. While the manuscript does not supply a formal bound on quantization error or a proof of injectivity, the empirical results show that the resulting codes enable the upper-level Q-table to learn useful decompositions that yield competitive performance. We will add a short discussion subsection on the quantization scheme, its collision properties, and empirical evidence that distinct configurations are sufficiently distinguished for the observed learning outcomes. revision: partial
Circularity Check
No derivation chain or equations present; framework is descriptive with experimental validation
full rationale
The paper proposes HRL-IM/CBS as a hierarchical RL framework using influence map hashing and cluster-based scripts, but contains no equations, derivations, or first-principles results. Claims rest on experimental performance across scenarios rather than any mathematical reduction that could be self-referential. No load-bearing steps reduce to fitted inputs or self-citations by construction. This is the expected non-finding for a purely algorithmic/experimental paper without analytic derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
G. N. Yannakakis and J. Togelius,Artificial Intelligence and Games. Cham: Springer International Publishing, 2018
2018
-
[2]
A survey of real-time strategy game AI research and competition in StarCraft,
S. Ontañón, G. Synnaeve, A. Uriarte, F. Richoux, D. Churchill, and M. Preuss, “A survey of real-time strategy game AI research and competition in StarCraft,”IEEE Transactions on Computational Intelligence and AI in Games, vol. 5, no. 4, pp. 293–311, 2013
2013
-
[3]
Ontañón, G
S. Ontañón, G. Synnaeve, A. Uriarte, F. Richoux, D. Churchill, and M. Preuss,RTS AI Problems and Techniques. Cham: Springer International Publishing, 2024, pp. 1595–1605
2024
-
[4]
Combining influence maps with heuristic search for executing sneak-attacks in RTS games,
L. Critch and D. Churchill, “Combining influence maps with heuristic search for executing sneak-attacks in RTS games,” in2020 IEEE Conference on Games (CoG), 2020, pp. 740–743
2020
-
[5]
Evolving Action Abstractions for Real-Time Planning in Extensive-Form Games,
J. R. H. Mariño, R. O. Moraes, C. Toledo, and L. H. S. Lelis, “Evolving Action Abstractions for Real-Time Planning in Extensive-Form Games,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 2330–2337
2019
-
[6]
Hierarchical control of multi-agent reinforcement learning team in real-time strategy (RTS) games,
W. J. Zhou, B. Subagdja, A.-H. Tan, and D. W.-S. Ong, “Hierarchical control of multi-agent reinforcement learning team in real-time strategy (RTS) games,”Expert Systems with Applications, vol. 186, p. 115707, 2021
2021
-
[7]
Hierarchical Reinforcement Learning Based on Macro Actions,
H. Jiang, G. Wang, S. Li, J. Zhang, L. Yan, and X. Xu, “Hierarchical Reinforcement Learning Based on Macro Actions,”Complex & Intelligent Systems, vol. 11, no. 6, p. 247, 2025
2025
-
[8]
Semicentralized deep deterministic policy gradient in cooperative StarCraft games,
D. Xie and X. Zhong, “Semicentralized deep deterministic policy gradient in cooperative StarCraft games,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1584–1593, 2022
2022
-
[9]
Three-dimensional attention transformer for state evaluation in real-time strategy games,
Y . Ye, W. Yang, K. Qiu, and J. Zhang, “Three-dimensional attention transformer for state evaluation in real-time strategy games,” 2025, arXiv preprint arXiv:2501.03832
-
[10]
J. Hu, S. Jiang, S. A. Harding, H. Wu, and S.-w. Liao, “Rethinking the Implementation Tricks and Monotonicity Constraint in Cooperative Multi-Agent Reinforcement Learning,” 2023, arXiv preprint arXiv:2102.03479
-
[11]
Reinforcement actor-critic learning as a rehearsal in MicroRTS,
S. Manandhar and B. Banerjee, “Reinforcement actor-critic learning as a rehearsal in MicroRTS,”The Knowledge Engineering Review, vol. 39, no. e6, pp. 1–15, 2024
2024
-
[12]
Distributed scalable multi-agent reinforcement learning with intrinsic-episodic dual exploration,
S. Qi, S. Zhang, Q. Wang, J. Zhang, and X. Wang, “Distributed scalable multi-agent reinforcement learning with intrinsic-episodic dual exploration,”Future Generation Computer Systems, vol. 175, p. 108040, 2026
2026
-
[13]
State and Action Abstraction for Search and Reinforcement Learning Algorithms,
A. Dockhorn and R. Kruse, “State and Action Abstraction for Search and Reinforcement Learning Algorithms,” inArtificial Intelligence in Control and Decision-making Systems, Y . P. Kondratenko, V . Kreinovich, W. Pedrycz, A. Chikrii, and A. M. Gil-Lafuente, Eds. Cham: Springer Nature Switzerland, 2023, vol. 1087, pp. 181–198
2023
-
[14]
Kiting in RTS Games Using Influence Maps,
A. Uriarte and S. Ontañón, “Kiting in RTS Games Using Influence Maps,” inArtificial Intelligence and Interac- tive Digital Entertainment Conference, 2012, p. 6
2012
-
[15]
Developing game AI for the real-time strategy game StarCraft,
A. Mici ´c, D. Arnarsson, and V . Jónsson, “Developing game AI for the real-time strategy game StarCraft,” Ph.D. dissertation, Reykjavik University, 2011
2011
-
[16]
Connectionist Reinforcement Learning for Intelligent Unit Micro Man- agement in StarCraft,
A. Shantia, E. Begue, and M. Wiering, “Connectionist Reinforcement Learning for Intelligent Unit Micro Man- agement in StarCraft,” inProceedings of the International Joint Conference on Neural Networks (IJCNN), 2011, pp. 1794–1801
2011
-
[17]
MCTS with influence map for general video game playing,
H. Park and K.-J. Kim, “MCTS with influence map for general video game playing,” in2015 IEEE Conference on Computational Intelligence and Games (CIG), 2015, pp. 534–535
2015
-
[18]
Intelligent decision making based on the combination of deep reinforcement learning and an influence map,
X. Lu, A. Xue, P. Lio, and P. Hui, “Intelligent decision making based on the combination of deep reinforcement learning and an influence map,”Applied Sciences, vol. 12, no. 22, p. 11458, 2022
2022
-
[19]
A machine learning approach to predict the winner in StarCraft based on influence maps,
A. A. Sánchez-Ruiz and M. Miranda, “A machine learning approach to predict the winner in StarCraft based on influence maps,”Entertainment Computing, vol. 19, pp. 29–41, 2017
2017
-
[20]
A Bayesian Model for RTS Units Control Applied to StarCraft,
G. Synnaeve and P. Bessière, “A Bayesian Model for RTS Units Control Applied to StarCraft,” in2011 IEEE Conference on Computational Intelligence and Games (CIG), 2011, pp. 190–196
2011
-
[21]
An experimental survey on methods for integrating scripts into adversarial search for RTS games,
Z. Yang and S. Ontañón, “An experimental survey on methods for integrating scripts into adversarial search for RTS games,”IEEE Transactions on Games, vol. 14, no. 2, pp. 117–125, 2022. 19
2022
-
[22]
Macro action selection with deep reinforcement learning in starcraft,
S. Xu, H. Kuang, Z. Zhi, R. Hu, Y . Liu, and H. Sun, “Macro action selection with deep reinforcement learning in starcraft,” inProceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 15, 2019, pp. 94–99
2019
-
[23]
On Efficient Reinforcement Learning for Full- length Game of StarCraft II,
R.-Z. Liu, Z.-J. Pang, Z.-Y . Meng, W. Wang, Y . Yu, and T. Lu, “On Efficient Reinforcement Learning for Full- length Game of StarCraft II,”Journal of Artificial Intelligence Research, vol. 75, pp. 213–260, 2022
2022
-
[24]
Action abstractions for combinatorial multi-armed bandit tree search,
R. Moraes, J. Marino, L. Lelis, and M. Nascimento, “Action abstractions for combinatorial multi-armed bandit tree search,” inProceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertain- ment, vol. 14, 2018, pp. 74–80
2018
-
[25]
Asymmetric action abstractions for multi-unit control in adversarial real-time games,
R. O. Moraes and L. Lelis, “Asymmetric action abstractions for multi-unit control in adversarial real-time games,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, 2018
2018
-
[26]
Portfolio greedy search and simulation for large-scale combat in StarCraft,
D. Churchill and M. Buro, “Portfolio greedy search and simulation for large-scale combat in StarCraft,” in2013 IEEE Conference on Computational Inteligence in Games (CIG), 2013, pp. 1–8
2013
-
[27]
Fast heuristic search for RTS game combat scenarios,
D. Churchill, A. Saffidine, and M. Buro, “Fast heuristic search for RTS game combat scenarios,” inProceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 8, 2012, pp. 112– 117
2012
-
[28]
UCT for Tactical Assault Planning in Real-Time Strategy Games,
R. K. Balla and A. Fern, “UCT for Tactical Assault Planning in Real-Time Strategy Games,” inProceedings of the International Joint Conference on Artificial Intelligence, 2009, pp. 40–45
2009
-
[29]
Script- and cluster-based UCT for StarCraft,
N. Justesen, B. Tillman, J. Togelius, and S. Risi, “Script- and cluster-based UCT for StarCraft,” in2014 IEEE Conference on Computational Intelligence and Games, 2014, pp. 1–8
2014
-
[30]
Stratified strategy selection for unit control in real-time strategy games,
L. H. S. Lelis, “Stratified strategy selection for unit control in real-time strategy games,” inProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017, pp. 3735–3741
2017
-
[31]
Hierarchical Reinforcement Learning with Opponent Mod- eling for Distributed Multi-agent Cooperation,
Z. Liang, J. Cao, S. Jiang, D. Saxena, and H. Xu, “Hierarchical Reinforcement Learning with Opponent Mod- eling for Distributed Multi-agent Cooperation,” in2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), 2022, pp. 884–894
2022
-
[32]
Hierarchical Q-learning network for online simultaneous optimization of en- ergy efficiency and battery life of the battery/ultracapacitor electric vehicle,
B. Xu, Q. Zhou, J. Shi, and S. Li, “Hierarchical Q-learning network for online simultaneous optimization of en- ergy efficiency and battery life of the battery/ultracapacitor electric vehicle,”Journal of Energy Storage, vol. 46, p. 103925, 2022
2022
-
[33]
Hierarchical Reinforcement Learning-Based Routing Algorithm With Grouped RSU in Urban V ANETs,
Q. Yang and S.-J. Yoo, “Hierarchical Reinforcement Learning-Based Routing Algorithm With Grouped RSU in Urban V ANETs,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 8, pp. 10 131–10 146, 2024
2024
-
[34]
Deep reinforcement learning in real-time strategy games: A systematic literature review,
G. C. Barros e Sá and C. A. G. Madeira, “Deep reinforcement learning in real-time strategy games: A systematic literature review,”Applied Intelligence, vol. 55, no. 4, p. 243, 2024
2024
-
[35]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J. P. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen, V . Dalibard, D. Budden, Y . Sulsky, J. Molloy, T. L. Paine, C. Gulcehre, Z. Wang, T. Pfaff,...
2019
-
[36]
L. Han, J. Xiong, P. Sun, X. Sun, M. Fang, Q. Guo, Q. Chen, T. Shi, H. Yu, X. Wu, and Z. Zhang, “TStarBot-X: An open-sourced and comprehensive study for efficient league training in StarCraft II full game,” 2021, arXiv preprint arXiv:2011.13729
-
[37]
Accelerating deep reinforcement learning model for game strategy,
Y . Li, Y . Fang, and Z. Akhtar, “Accelerating deep reinforcement learning model for game strategy,”Neurocom- puting, vol. 408, pp. 157–168, 2020
2020
-
[38]
Intelligent Games Meeting with Multi-Agent Deep Reinforcement Learning: A Comprehensive Review,
Y . Wang, Y . Wang, F. Tian, J. Ma, and Q. Jin, “Intelligent Games Meeting with Multi-Agent Deep Reinforcement Learning: A Comprehensive Review,”Artificial Intelligence Review, vol. 58, no. 6, p. 165, 2025
2025
-
[39]
P. Peng, Y . Wen, Y . Yang, Q. Yuan, Z. Tang, H. Long, and J. Wang, “Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play StarCraft combat games,” 2017, arXiv preprint arXiv:1703.10069
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Counterfactual multi-agent policy gradients,
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, 2018
2018
-
[41]
StarCraft micromanagement with reinforcement learning and curriculum transfer learning,
K. Shao, Y . Zhu, and D. Zhao, “StarCraft micromanagement with reinforcement learning and curriculum transfer learning,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 3, no. 1, pp. 73–84, 2019. 20
2019
-
[42]
Multi-Agent Hierarchical Graph Attention Actor–Critic Reinforcement Learning,
T. Li, D. Shi, S. Jin, Z. Wang, H. Yang, and Y . Chen, “Multi-Agent Hierarchical Graph Attention Actor–Critic Reinforcement Learning,”Entropy, vol. 27, no. 1, p. 4, 2025
2025
-
[43]
Toward Explainable Reinforcement Learning and a Custom RL Benchmark for Strategic Decision- Making,
S. Panda, “Toward Explainable Reinforcement Learning and a Custom RL Benchmark for Strategic Decision- Making,” Master’s thesis, The Pennsylvania State University, 2025
2025
-
[44]
Evolving interpretable strategies for zero-sum games,
J. R. Mariño and C. F. Toledo, “Evolving interpretable strategies for zero-sum games,”Applied Soft Computing, vol. 122, p. 108860, 2022
2022
-
[45]
CODEX: A Cluster-Based Method for Explainable Reinforce- ment Learning,
T. K. Mathes, J. Inman, A. Colón, and S. Khan, “CODEX: A Cluster-Based Method for Explainable Reinforce- ment Learning,” 2023, arXiv preprint arXiv:2312.04216
-
[46]
Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games,
Y . Hou, X. Liang, J. Zhang, Q. Yang, A. Yang, and N. Wang, “Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Comparative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games,”Applied Sciences, vol. 13, no. 14, p. 8283, 2023
2023
-
[47]
Deep Reinforcement Learning for Real-Time Strategy Games Techniques and Open Challenges,
P. Endla, F. J. P, T. V , D. D. Bhavani, M. Tiwari, and T. T. V , “Deep Reinforcement Learning for Real-Time Strategy Games Techniques and Open Challenges,” inITM Web of Conferences, vol. 76. EDP Sciences, 2025, p. 01006
2025
-
[48]
OB-HPPO: An Option and Intrinsic Curiosity Based Hierar- chical Reinforcement Learning Approach for Real-Time Strategy Games,
R. Jiang, Y . Zhai, Y . Zheng, Y . Li, and Y . Liu, “OB-HPPO: An Option and Intrinsic Curiosity Based Hierar- chical Reinforcement Learning Approach for Real-Time Strategy Games,” inAdvanced Intelligent Computing Technology and Applications, D.-S. Huang, X. Zhang, and Y . Pan, Eds. Singapore: Springer Nature, 2024, pp. 443–454
2024
-
[49]
Towards a Unified Theory of State Abstraction for MDPs,
L. Li, T. J. Walsh, and M. L. Littman, “Towards a Unified Theory of State Abstraction for MDPs,” inAI&M, 2006
2006
-
[50]
Learning from Delayed Rewards,
C. J. C. H. Watkins, “Learning from Delayed Rewards,” Ph.D. dissertation, University of Cambridge, 1989
1989
-
[51]
Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning,
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[52]
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning,
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y . Yi, “QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning,” inProceedings of the 36th International Conference on Machine Learning. PMLR, 2019, pp. 5887–5896
2019
-
[53]
Multiagent Coop- eration and Competition with Deep Reinforcement Learning,
A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Korjus, J. Aru, J. Aru, and R. Vicente, “Multiagent Coop- eration and Competition with Deep Reinforcement Learning,”PLOS ONE, vol. 12, no. 4, p. e0172395, 2017
2017
-
[54]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuyls, and T. Graepel, “Value-Decomposition Networks For Cooperative Multi-Agent Learning,” 2017, arXiv preprint arXiv:1706.05296
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 611– 24 624, 2022. 21 The supplemental file presents the comprehensive experimental results of ablation study and the visualization of the distributio...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.