An Ontology-Guided Multi-Anchor Graph Retrieval Framework for Traffic Legal Liability Determination
Pith reviewed 2026-06-27 09:35 UTC · model grok-4.3
The pith
An ontology-guided multi-anchor graph retrieval framework resolves the multi-dimensional retrieval bottleneck in traffic law liability determination by decomposing queries into parallel ontology-aligned anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
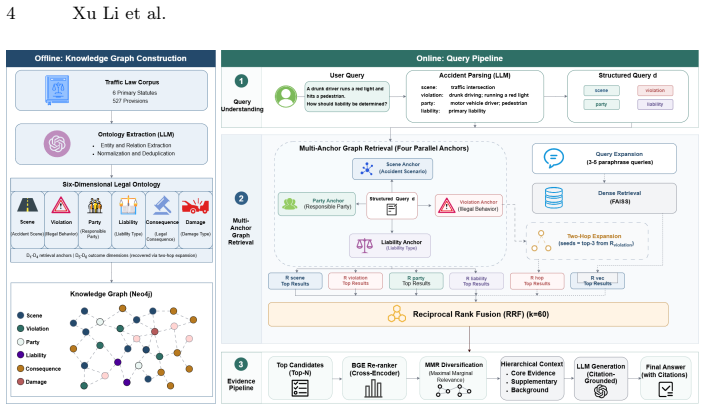
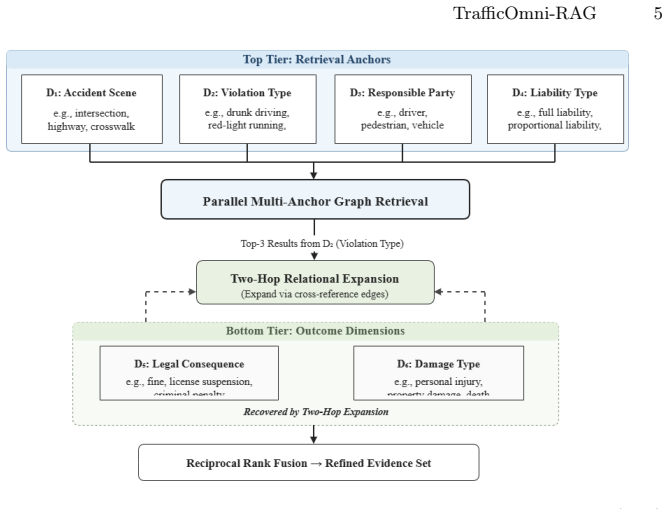
OMAGR decomposes legal queries into ontology-aligned anchors and executes parallel graph retrieval across each dimension, ensuring independent retrieval across dimensions before fusion, which resolves the multi-dimensional retrieval bottleneck that single-axis architectures cause by overlooking interdependent statutory provisions.
What carries the argument
The ontology-guided multi-anchor parallel graph retrieval mechanism that decomposes queries into independent dimensions for separate retrieval paths before fusion.
If this is right
- Traffic law liability determination can simultaneously identify interdependent provisions across multiple legal dimensions without single-path compression.
- Retrieval-augmented generation for legal tasks gains improved Context Precision and Faithfulness when retrieval runs in parallel across ontology dimensions.
- The TrafficLaw-QA dataset supplies a standardized benchmark of 200 questions and 527 provisions for testing multi-dimensional legal retrieval.
- Parallel multi-anchor retrieval offers a direction for handling complex statutory queries that single-axis methods cannot address.
Where Pith is reading between the lines
- The same decomposition strategy could extend to other rule-heavy domains such as contract review or regulatory compliance where provisions interact across categories.
- Dynamic anchor selection based on query structure might further reduce cases where initial decomposition misses a dimension.
- Graph fusion steps after parallel retrieval could be examined for their role in preserving cross-dimension links that the anchors themselves do not encode.
Load-bearing premise
Legal queries can be reliably decomposed into independent ontology-aligned anchors that capture all critical interdependencies among statutory provisions without loss of information.
What would settle it
A traffic liability query containing tightly coupled provisions across dimensions where the parallel anchors retrieve incomplete or conflicting statutes that produce an incorrect liability outcome compared with expert judgment.
Figures
read the original abstract
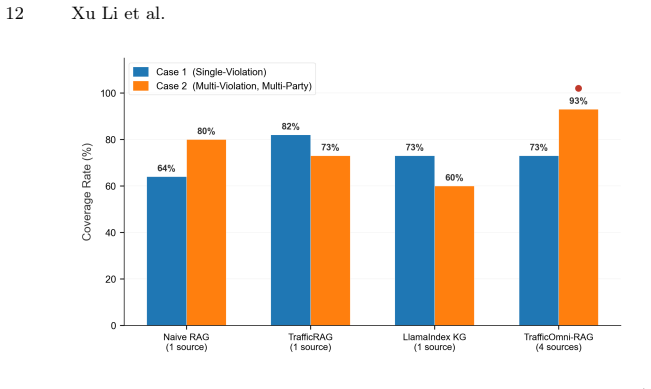
Traffic law liability determination is critical for assigning legal penalties, requiring the simultaneous identification of interdependent statutory provisions across multiple legal dimensions. However, existing retrieval-augmented generation methods suffer from a multi-dimensional retrieval bottleneck: single axis architectures compress complex legal queries into a single pathway, causing interdependent statutory dimensions to be overlooked. To address this, we propose OMAGR, an ontology-guided framework that decomposes queries into ontology-aligned anchors and executes parallel graph retrieval across each dimension, ensuring independent retrieval across dimensions before fusion. To evaluate the proposed method, we created the TrafficLaw-QA dataset, an expert-validated benchmark dataset containing 200 questions and 527 legal provisions. Results show that TrafficOmni-RAG outperforms baselines on Context Precision and Faithfulness metrics. The findings demonstrate that parallel multi-anchor retrieval effectively resolves the multi-dimensional retrieval bottleneck, offering a promising direction for traffic law liability determination research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OMAGR, an ontology-guided multi-anchor graph retrieval framework that decomposes traffic-law queries into ontology-aligned anchors, performs parallel per-dimension graph retrieval, and fuses results to address the multi-dimensional retrieval bottleneck in legal liability determination. The authors introduce the expert-validated TrafficLaw-QA dataset (200 questions, 527 provisions) and report that their TrafficOmni-RAG implementation outperforms baselines on Context Precision and Faithfulness.
Significance. If the decomposition step demonstrably preserves cross-dimension statutory interdependencies and the reported gains are reproducible with statistical support, the framework could provide a concrete direction for multi-axis legal retrieval; the new dataset is also a potentially reusable contribution.
major comments (2)
- [Abstract] Abstract: the central claim that parallel multi-anchor retrieval 'effectively resolves the multi-dimensional retrieval bottleneck' rests on the unverified assumption that query decomposition into independent ontology-aligned anchors loses no critical inter-anchor dependencies; no coverage or dependency-recall metric on the 200-question TrafficLaw-QA set is supplied to test this.
- [Abstract / Evaluation] Evaluation description: the abstract states performance gains on Context Precision and Faithfulness but supplies neither implementation details of the decomposition mapper, error bars, statistical tests, nor data-exclusion rules, leaving the quantitative support for the bottleneck-resolution claim unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that parallel multi-anchor retrieval 'effectively resolves the multi-dimensional retrieval bottleneck' rests on the unverified assumption that query decomposition into independent ontology-aligned anchors loses no critical inter-anchor dependencies; no coverage or dependency-recall metric on the 200-question TrafficLaw-QA set is supplied to test this.
Authors: We acknowledge that the central claim assumes decomposition into ontology-aligned anchors preserves interdependencies without explicit verification. The ontology is designed to map queries to distinct statutory dimensions, but we agree this requires empirical testing. In the revised manuscript we will add a dependency-recall metric (and coverage analysis) computed over the full TrafficLaw-QA set to quantify any lost cross-anchor statutory relations. revision: yes
-
Referee: [Abstract / Evaluation] Evaluation description: the abstract states performance gains on Context Precision and Faithfulness but supplies neither implementation details of the decomposition mapper, error bars, statistical tests, nor data-exclusion rules, leaving the quantitative support for the bottleneck-resolution claim unsupported.
Authors: We agree that the current abstract and evaluation lack the requested details. The revised version will expand both the abstract and evaluation sections to include the decomposition mapper implementation, error bars on all reported metrics, statistical test results, and the data-exclusion criteria applied to the 200-question set. revision: yes
Circularity Check
No circularity detected; framework and evaluation are self-contained
full rationale
The paper introduces OMAGR as a new ontology-guided multi-anchor retrieval framework and evaluates it on a newly created expert-validated TrafficLaw-QA dataset with 200 questions. No equations, fitted parameters, predictions, or self-citations are described in the provided text. The central claim rests on empirical metrics (Context Precision, Faithfulness) rather than any reduction to inputs by definition or self-reference. The decomposition step is presented as part of the proposed method without circular justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Legal queries can be decomposed into independent ontology-aligned anchors without loss of interdependencies
invented entities (1)
-
OMAGR framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (2024), https://proceedings.iclr.cc/paper_files/paper/ 2024/file/25f7be9694d7b32d5cc670927b8091e1-Paper-Conference.pdf
Asai, A., Wu, Z., Wang, Y., Sil, A., Hajishirzi, H.: Self-rag: Learning to retrieve, generate, and critique through self-reflection. In: International Conference on Learning Representations (2024), https://proceedings.iclr.cc/paper_files/paper/ 2024/file/25f7be9694d7b32d5cc670927b8091e1-Paper-Conference.pdf
2024
-
[2]
Carbonell, J., Goldstein, J.: The use of mmr, diversity-based reranking for reorder- ing documents and producing summaries. In: ACM SIGIR Conference on Research andDevelopmentinInformationRetrieval(1998).https://doi.org/10.1145/290941. 291025
-
[3]
In: Scott, D., Bel, N., Zong, C
Chalkidis, et al.: LEGAL-BERT: The muppets straight out of law school. In: Findings of the Association for Computational Linguistics: EMNLP. Associ- ation for Computational Linguistics (2020). https://doi.org/10.18653/v1/2020. findings-emnlp.261, https://aclanthology.org/2020.findings-emnlp.261/
-
[4]
Cormack,G.V.,etal.:Reciprocalrankfusionoutperformscondorcetandindividual rank learning methods. In: ACM SIGIR Conference on Research and Development in Information Retrieval. Association for Computing Machinery (2009). https:// doi.org/10.1145/1571941.1572114
-
[5]
Cui, J., Ning, M., Li, Z., Chen, B., Yan, Y., Li, H., Ling, B., Tian, Y., Yuan, L.: Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model (2024), https://arxiv.org/abs/ 2306.16092
Pith/arXiv arXiv 2024
-
[6]
In: Advances and Trends in Artificial Intelligence
Dang, et al.: Information retrieval from legal documents with ontology and graph embeddings approach. In: Advances and Trends in Artificial Intelligence. The- ory and Applications: 36th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2023, Shanghai, China, July 19–22, 2023, Proceedings, Pa...
2023
-
[7]
Edge, D., et al.: From local to global: A graph rag approach to query-focused summarization (2025), https://arxiv.org/abs/2404.16130
Pith/arXiv arXiv 2025
-
[8]
Es, et al.: RAGAs: Automated evaluation of retrieval augmented generation. In: Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Association for Computa- tional Linguistics (2024). https://doi.org/10.18653/v1/2024.eacl-demo.16, https: //aclanthology.org/2024.eacl-demo.16/
-
[9]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Gao, et al.: Enabling large language models to generate text with citations. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (2023). https://doi.org/10. 18653/v1/2023.emnlp-main.398, https://aclanthology.org/2023.emnlp-main.398/
2023
-
[10]
In: Ad- vances in Neural Information Processing Systems
Guha, N., Nyarko, J., et al.: Legalbench: A collaboratively built bench- mark for measuring legal reasoning in large language models. In: Ad- vances in Neural Information Processing Systems. Curran Associates, Inc. (2023), https://proceedings.neurips.cc/paper_files/paper/2023/file/ 89e44582fd28ddfea1ea4dcb0ebbf4b0-Paper-Datasets_and_Benchmarks.pdf Traffic...
2023
-
[11]
Huang, Q., Tao, M., Zhang, C., An, Z., Jiang, C., Chen, Z., Wu, Z., Feng, Y.: Lawyer llama technical report (2023), https://arxiv.org/abs/2305.15062
arXiv 2023
-
[12]
Billion-scalesimilaritysearchwithgpus
Johnson, J., Douze, M., Jégou, H.: Billion-scale similarity search with gpus. IEEE Transactions on Big Data (2021). https://doi.org/10.1109/TBDATA.2019.2921572
-
[13]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, et al.: Dense passage retrieval for open-domain question answer- ing. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online (Nov 2020). https://doi.org/10.18653/v1/2020.emnlp-main.550, https://aclanthology. org/2020.emnlp-main.550/
-
[14]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Lewis, P., Perez, E., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 9459–9474. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper_files/paper/ 2020/file/6b493230205f780e1bc26...
2020
-
[15]
CEUR Workshop Proceedings (2025)
Ongris, et al.: Benchmarking kg-based rag systems: A case study of legal docu- ments. CEUR Workshop Proceedings (2025)
2025
-
[16]
IEEE Transactions on Knowledge and Data Engineering36(7), 3580–3599 (2024)
Pan, et al.: Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering (2024). https://doi.org/ 10.1109/TKDE.2024.3352100
-
[17]
Association for Computational Linguistics, Singapore (2023)
Wang,etal.:Query2doc:Queryexpansionwithlargelanguagemodels.In:Proceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore (2023). https://doi.org/10. 18653/v1/2023.emnlp-main.585, https://aclanthology.org/2023.emnlp-main.585/
2023
-
[18]
Wang, et al.: Amformer-based framework for accident responsibility attribution: Interpretable analysis with traffic accident features. PLOS ONE (2025). https: //doi.org/10.1371/journal.pone.0329107
-
[19]
Xiao, et al.: C-pack: Packed resources for general chinese embeddings. In: ACM SIGIR Conference on Research and Development in Information Retrieval. Associ- ation for Computing Machinery, New York, NY, USA (2024). https://doi.org/10. 1145/3626772.3657878, https://doi.org/10.1145/3626772.3657878
-
[20]
Xiao,C.,etal.:Cail2018:Alarge-scalelegaldatasetforjudgmentprediction(2018), https://arxiv.org/abs/1807.02478
Pith/arXiv arXiv 2018
-
[21]
In: Artificial Neural Networks and Machine Learning – ICANN 2026
Xu, L., Zedong, F., Xinyi, L., Xun, H.: Trafficrag: A multimodal rag framework for trafffc accident liability determination. In: Artificial Neural Networks and Machine Learning – ICANN 2026. Springer Nature Switzerland (2026)
2026
-
[22]
Yue, S., Chen, W., Wang, S., Li, B., Shen, C., Liu, S., Zhou, Y., Xiao, Y., Yun, S., Huang, X., Wei, Z.: Disc-lawllm: Fine-tuning large language models for intelligent legal services (2023), https://arxiv.org/abs/2309.11325
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.