Brain-to-Image Retrieval and Reconstruction via Multimodal EEG Alignment
Pith reviewed 2026-06-30 19:00 UTC · model grok-4.3
The pith
EEG signals during natural image viewing can be aligned to multimodal CLIP embeddings for 86% top-1 retrieval accuracy and 0.903 CLIP-score reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
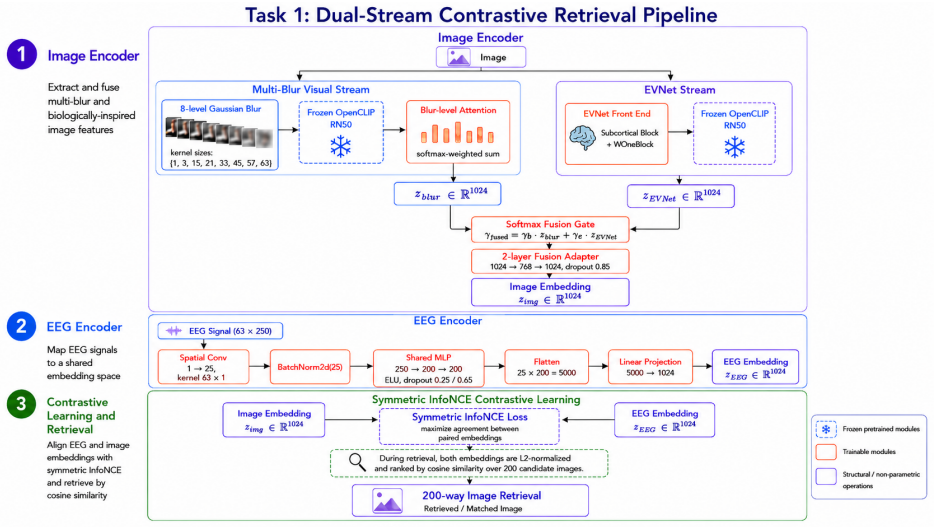
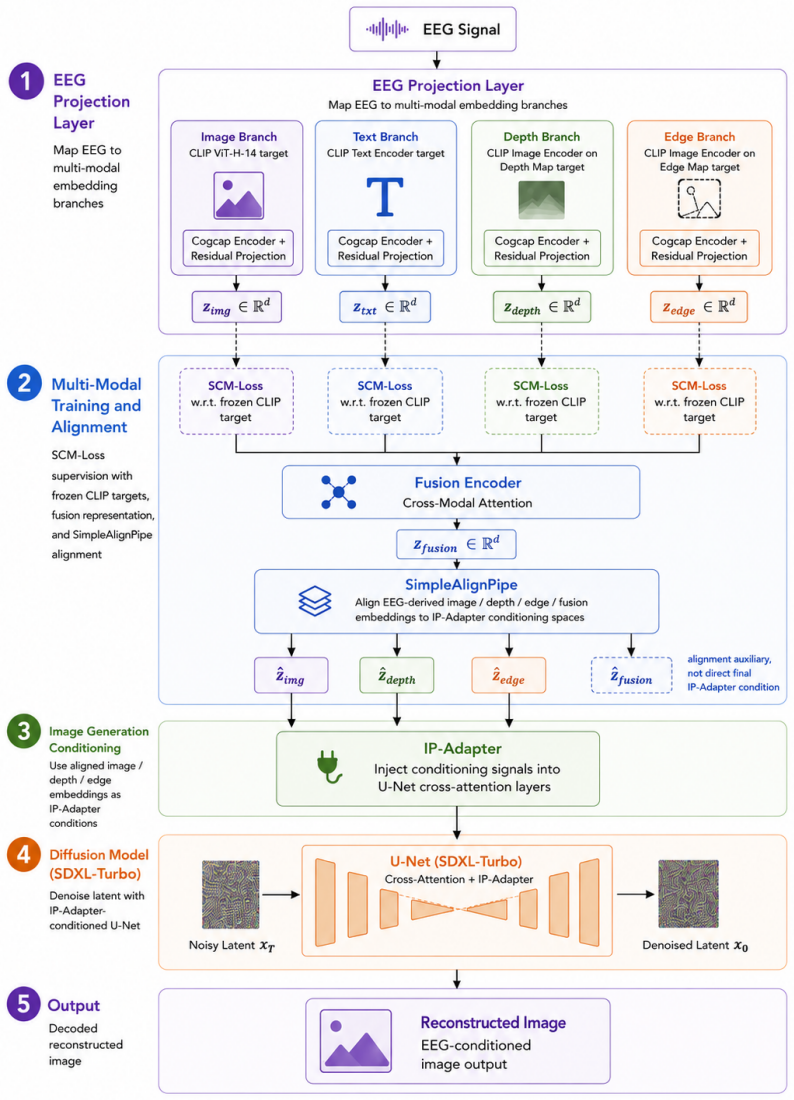
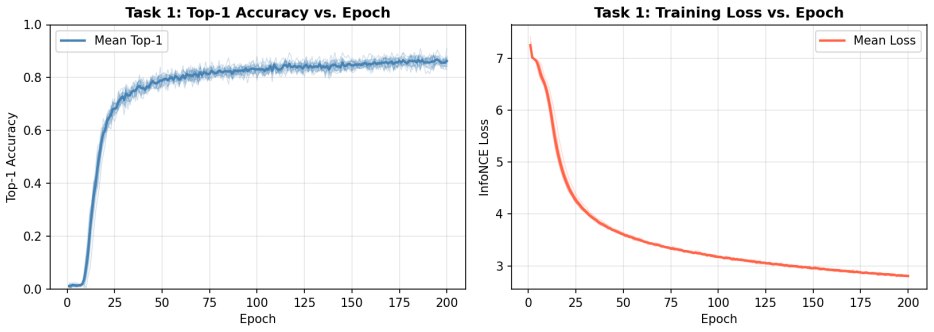
We present a brain-to-image system that decodes visual stimuli from EEG signals recorded during natural image viewing. For retrieval we implement a multi-level blurring approach improved with biologically inspired EVNet features and trained with the InfoNCE loss, reaching 86.30% top-1 and 98.55% top-5 accuracy. For reconstruction we implement CognitionCapturerPro, which aligns EEG representations to multi-modal CLIP embeddings including image, text, depth, and edge, and synthesizes images with SDXL-Turbo conditioned via IP-Adapter, reaching 0.903 CLIP score with ViT-H-14.
What carries the argument
CognitionCapturerPro, the alignment network that maps EEG segments to a joint space of image, text, depth, and edge CLIP embeddings so that those embeddings can directly condition a diffusion generator.
If this is right
- The retrieval model can rank the correct image among 200 candidates at 86.30% top-1 and 98.55% top-5 accuracy.
- The reconstruction model produces images whose CLIP embeddings match the stimulus at 0.903 with ViT-H-14 and 0.870 with ViT-L/14 while attaining 0.409 SSIM.
- Both pipelines remain stable when averaged over ten random seeds on the same subject.
- The system operates on EEG collected during ordinary image viewing without added physiological constraints.
Where Pith is reading between the lines
- If the same alignment holds for additional subjects without recalibration, the approach could scale to subject-independent brain-to-image interfaces.
- Pairing the retrieval and reconstruction stages in a single loop could support real-time visual feedback from brain signals.
Load-bearing premise
EEG segments recorded during natural image viewing contain sufficiently rich and stable visual representations that can be aligned to multi-modal CLIP embeddings without subject-specific recalibration or additional physiological constraints.
What would settle it
Applying the trained models to EEG recorded from a second subject without recalibration and obtaining top-1 retrieval accuracy near the random baseline of 0.5% would demonstrate that the representations are not stable enough for the claimed alignment.
Figures


read the original abstract
We present a brain-to-image system that decodes visual stimuli from EEG signals recorded during natural image viewing. Our system addresses two tasks: (1) EEG-to-image retrieval, which ranks the correct stimulus image among 200 candidates given an EEG segment, and (2) EEG-to-image reconstruction, which generates an image consistent with the perceived stimulus. For retrieval, we implement a multi-level blurring approach improved with biologically inspired EVNet features and trained with the InfoNCE loss. Evaluated over 10 random seeds for a single subject, the retrieval model achieves a mean final-epoch Top-1 accuracy of 86.30% and Top-5 accuracy of 98.55%. For reconstruction, we implement CognitionCapturerPro, which aligns EEG representations to multi-modal CLIP embeddings, including image, text, depth, and edge embeddings, and synthesizes images with SDXL-Turbo conditioned via IP-Adapter. Averaged over 10 seeds, the reconstruction model achieves a CLIP score of 0.903 using ViT-H-14, a CLIP score of 0.870 using ViT-L/14, and an SSIM of 0.409. These results demonstrate the feasibility of decoding rich visual representations from EEG signals using modern multi-modal alignment and generative modeling techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a brain-to-image decoding system that performs two tasks on EEG signals recorded during natural image viewing: (1) retrieval of the correct image among 200 candidates using multi-level blurring, EVNet features, and InfoNCE loss; and (2) reconstruction via CognitionCapturerPro, which aligns EEG to multi-modal CLIP embeddings (image, text, depth, edge) and conditions SDXL-Turbo through IP-Adapter. All metrics are reported for a single subject averaged over 10 random seeds: retrieval reaches 86.30% Top-1 and 98.55% Top-5 accuracy; reconstruction reaches CLIP scores of 0.903 (ViT-H-14) and 0.870 (ViT-L/14) with SSIM 0.409.
Significance. If the single-subject empirical results prove robust and generalize, the work would demonstrate that modern multimodal contrastive alignment and generative models can extract usable visual information from EEG, offering a concrete technical path for non-invasive brain-to-image interfaces. The explicit use of multiple CLIP modalities (image/text/depth/edge) and the biologically inspired EVNet component constitute clear engineering contributions that could be built upon once subject-independence is established.
major comments (2)
- [Abstract] Abstract: All reported performance numbers (retrieval Top-1 86.30%, reconstruction CLIP 0.903) are obtained from a single subject with per-subject training; the absence of any cross-subject, leave-one-subject-out, or multi-subject evaluation directly undermines the central premise that EEG segments contain sufficiently rich and stable visual representations alignable to CLIP embeddings without subject-specific recalibration.
- [Abstract] Abstract (and implied Methods/Experiments): No information is supplied on dataset size, number of trials per subject, train-test split protocol, or any statistical testing; without these controls the claim that the multi-level blurring + InfoNCE pipeline and CognitionCapturerPro alignment succeed cannot be evaluated for overfitting or reproducibility.
minor comments (1)
- [Abstract] Abstract: The phrase "evaluated over 10 random seeds for a single subject" should be accompanied by standard deviations or confidence intervals for the reported means to allow assessment of stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the single-subject scope and the need for greater transparency on experimental controls. We respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: All reported performance numbers (retrieval Top-1 86.30%, reconstruction CLIP 0.903) are obtained from a single subject with per-subject training; the absence of any cross-subject, leave-one-subject-out, or multi-subject evaluation directly undermines the central premise that EEG segments contain sufficiently rich and stable visual representations alignable to CLIP embeddings without subject-specific recalibration.
Authors: We agree the reported results use single-subject, per-subject training. The central premise of the work is to demonstrate technical feasibility of multimodal contrastive alignment and generative decoding from EEG using current methods; single-subject evaluation is a standard first step in EEG visual decoding literature to isolate the signal before tackling inter-subject variability. We will revise the abstract to explicitly note the single-subject design and add a limitations paragraph outlining the path toward subject-independent models. revision: yes
-
Referee: [Abstract] Abstract (and implied Methods/Experiments): No information is supplied on dataset size, number of trials per subject, train-test split protocol, or any statistical testing; without these controls the claim that the multi-level blurring + InfoNCE pipeline and CognitionCapturerPro alignment succeed cannot be evaluated for overfitting or reproducibility.
Authors: We will update the abstract to include key dataset statistics (number of trials, single-subject scope) and explicitly state the 10-seed averaging protocol. The methods section already details the train-test splits and evaluation; we will add a short reproducibility subsection summarizing these controls. revision: yes
Circularity Check
No circularity: empirical ML pipeline reports trained-model metrics without self-referential derivation
full rationale
The paper presents a standard supervised learning system (multi-level blurring + EVNet + InfoNCE for retrieval; CognitionCapturerPro + multi-modal CLIP alignment + SDXL-Turbo for reconstruction) and directly reports performance numbers obtained by training and evaluating on the EEG-image pairs. No mathematical derivation chain, first-principles claim, or uniqueness theorem is asserted that reduces to the inputs by construction. No self-citations, ansatzes, or fitted-parameter renamings appear in the provided text. The reported accuracies are the expected output of the training procedure itself, not a circular reduction of an independent prediction.
Axiom & Free-Parameter Ledger
free parameters (2)
- InfoNCE temperature and other contrastive hyperparameters
- Alignment weights across CLIP modalities and IP-Adapter conditioning strength
axioms (1)
- domain assumption EEG signals recorded during natural image viewing contain stable, decodable visual information sufficient for alignment to CLIP embeddings
Reference graph
Works this paper leans on
-
[1]
Wenchao Liu, Hongwei Li, Zhouyang Xu, Lin Ma, and Haifeng Li. Leveraging visual blur perception characteristics for eeg decoding.Proceedings of the AAAI Conference on Artificial Intelligence, 40(21):17580–17588, Mar. 2026. doi: 10.1609/aaai.v40i21.38813. URLhttps: //ojs.aaai.org/index.php/AAAI/article/view/38813
-
[2]
Lucas Piper, Arlindo L. Oliveira, and Tiago Marques. Explicitly modeling subcortical vision with a neuro-inspired front-end improves cnn robustness, 2025. URLhttps://arxiv.org/ abs/2506.03089
-
[3]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding, 2019. URLhttps://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Kaifan Zhang, Lihuo He, Junjie Ke, Yuqi Ji, Lukun Wu, Lizi Wang, and Xinbo Gao. Cognition- capturerpro: Towards high-fidelity visual decoding from eeg/meg via multi-modal information and asymmetric alignment, 2026. URLhttps://arxiv.org/abs/2603.12722
-
[5]
arXiv preprint arXiv:2311.17042 , year=
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023. URLhttps://arxiv.org/abs/2311.17042
-
[6]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023. URLhttps://arxiv.org/abs/ 2308.06721
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M
Alessandro T. Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M. Cichy. A large and rich eeg dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022. 13 ISSN 1053-8119. doi: https://doi.org/10.1016/j.neuroimage.2022.119754. URLhttps://www. sciencedirect.com/science/article/pii/S1053811922008758
-
[8]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612,
-
[10]
doi: 10.1109/TIP.2003.819861
-
[11]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C.J. Burges, L. Bottou, and K. Wein- berger, editors,Advances in Neural Information Processing Systems, volume 25. Curran As- sociates, Inc., 2012. URLhttps://proceedings.neurips.cc/paper_files/paper/2012/ file/c399862d3b...
2012
-
[12]
Unsupervised learning of visual features by contrasting cluster assignments, 2021
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments, 2021. URLhttps://arxiv.org/abs/2006.09882
-
[13]
Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks, 2020. URLhttps://arxiv.org/abs/1905.11946
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 2818–2829. IEEE, 2023. doi: 10.1109/cvpr52729.2023. 00276...
-
[15]
Cox, and James J
Joel Dapello, Tiago Marques, Martin Schrimpf, Franziska Geiger, David D. Cox, and James J. DiCarlo. Simulating a primary visual cortex at the front of CNNs improves robustness to image perturbations. InAdvances in Neural Information Processing Systems, 2020
2020
-
[16]
A simple framework for contrastive learning of visual representations, 2020
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations, 2020. URLhttps://arxiv.org/abs/2002. 05709
2020
-
[17]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
LAION-5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmar- czyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text model...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Visual decoding and reconstruction via eeg embeddings with guided diffusion, 2024
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Visual decoding and reconstruction via eeg embeddings with guided diffusion, 2024. URLhttps: //arxiv.org/abs/2403.07721
-
[21]
H. W. Kuhn. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1-2):83–97, 1955. doi: https://doi.org/10.1002/nav.3800020109. URLhttps: //onlinelibrary.wiley.com/doi/abs/10.1002/nav.3800020109. Appendix A: Team Contribution Statement •Chi Kit WONG: Participated in the coding work for Task 1 and Task 2, presented the Task...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.