Intellectual Humility as a Cognitive Filter for AI-Generated Health Misinformation. An Evolutionary Perspective on Epistemic Vigilance
Pith reviewed 2026-06-28 08:41 UTC · model grok-4.3
The pith
Intellectual humility lowers credibility ratings for AI-generated pseudoscientific health dialogues but shows no link to ratings of accurate ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
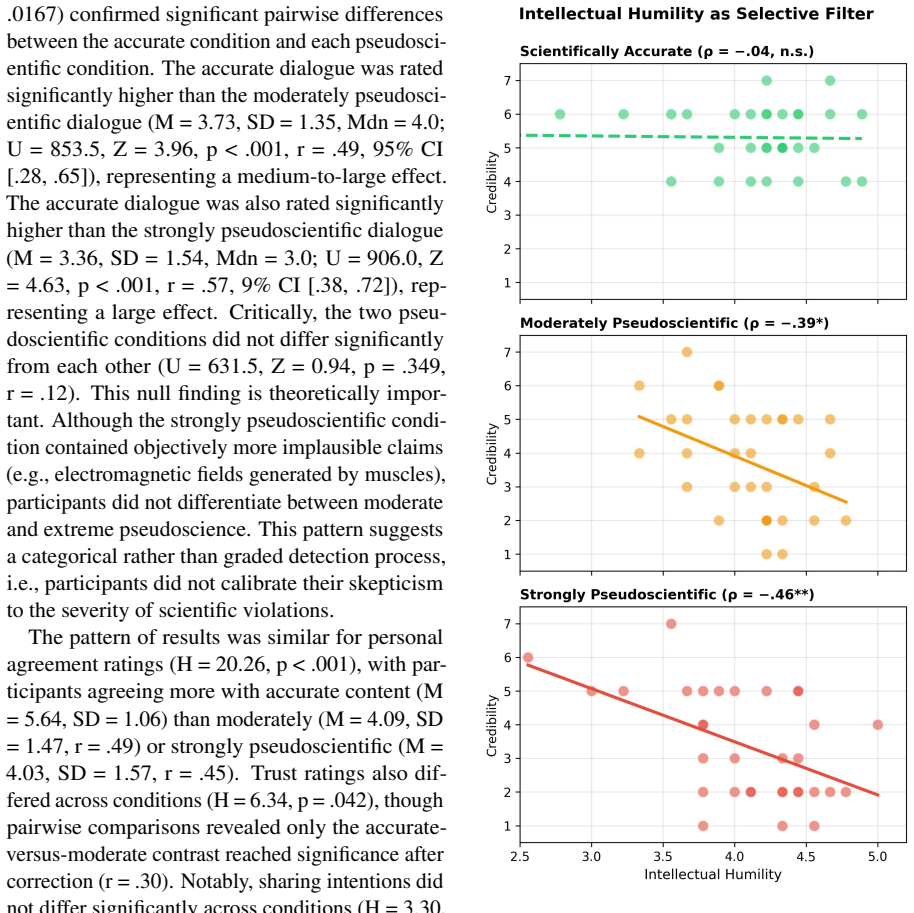
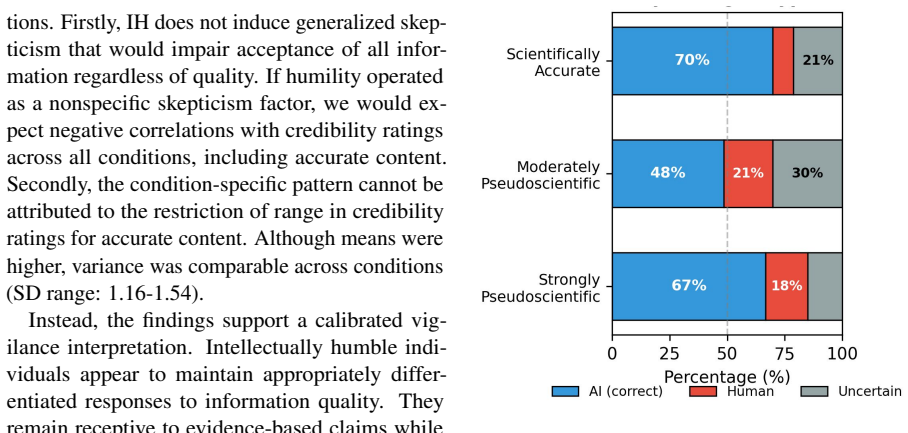
Intellectual humility functions as a selective cognitive filter. Individuals with higher humility scores rated pseudoscientific content as significantly less credible, while showing no correlation with credibility assessments of accurate content. Humility did not predict the ability to identify AI as the source of the dialogues, indicating that epistemic vigilance operates on content quality rather than source attribution. The authors propose that this filter represents an ancestral adaptation that remains effective at detecting exploitation attempts even in AI-generated material.
What carries the argument
Intellectual humility as a selective cognitive filter that reduces perceived credibility of low-quality health information while leaving judgments of accurate information unaffected.
If this is right
- Higher intellectual humility protects against accepting AI-generated health misinformation without affecting acceptance of accurate AI content.
- The filter works by evaluating content features rather than by detecting the artificial source.
- An evolved capacity for epistemic vigilance can still operate on modern AI outputs even though humans never evolved mechanisms to detect AI specifically.
- Foundation models used in health communication can be countered at the receiver end by the same humility mechanism that handles ordinary misinformation.
Where Pith is reading between the lines
- Programs that raise intellectual humility might reduce the impact of AI health misinformation across broader populations.
- The same selective filter could be tested on AI content in non-health domains such as financial advice or political claims.
- If the classification of dialogues drives the result, then studies that vary only surface features while holding scientific accuracy constant would weaken the observed pattern.
Load-bearing premise
The three dialogues were correctly classified by the researchers as scientifically accurate, moderately pseudoscientific, or strongly pseudoscientific, and any credibility differences arise from that classification rather than from other dialogue features.
What would settle it
A new sample of participants rates the same three dialogues after the accuracy labels have been swapped or withheld, and the correlation between humility scores and credibility ratings disappears or reverses.
Figures
read the original abstract
We present experimental findings from a study (N=99) examining how intellectual humility (IH), i.e., the metacognitive awareness of epistemic limitations, affects the evaluation of AI-generated health dialogues varying in scientific rigor. Participants were randomly assigned to evaluate one of three dialogues about exercise and mental health: scientifically accurate, moderately pseudoscientific, or strongly pseudoscientific. Results reveal that IH functions as a selective cognitive filter. Individuals with higher humility scores rated pseudoscientific content as significantly less credible, while showing no correlation with credibility assessments of accurate content. Crucially, humility did not predict the ability to identify AI as the source of dialogues, suggesting that epistemic vigilance operates on content quality rather than source attribution. We interpret these findings through an evolutionary lens, proposing that IH represents an ancestral adaptation for navigating informationally uncertain environments. It remains effective at detecting exploitation attempts in AI-generated content, despite humans lacking evolved mechanisms for detecting AI sources. The study contributes to understanding how foundation models might improve or undermine human epistemic defenses, especially in health communication contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from an experiment (N=99) in which participants were randomly assigned to rate the credibility of one of three AI-generated dialogues on exercise and mental health, pre-classified by the authors as scientifically accurate, moderately pseudoscientific, or strongly pseudoscientific. The central empirical claim is that intellectual humility (IH) scores correlate negatively with credibility ratings only for the pseudoscientific dialogues, show no correlation for the accurate dialogue, and do not predict participants' ability to identify the dialogues as AI-generated. The authors interpret these patterns as evidence that IH functions as a selective cognitive filter for epistemic vigilance that remains effective against AI-generated health content, framed through an evolutionary lens.
Significance. If the reported selective correlations hold after proper validation of the stimulus materials and full reporting of statistical analyses, the study would offer evidence that trait-level intellectual humility can help individuals discount low-quality AI-generated health information without impairing evaluation of accurate content. This would contribute to HCI and health-communication literatures on human-AI epistemic interactions and could inform design of AI systems that support rather than undermine user vigilance. The evolutionary interpretation remains speculative and is not directly tested by the data.
major comments (2)
- [Abstract / Methods (stimulus construction)] The assignment of the three dialogues to the accurate, moderately pseudoscientific, and strongly pseudoscientific conditions is load-bearing for the selective-filter claim, yet the manuscript provides no description of the classification procedure, rubric, expert review, inter-rater agreement, or quantitative content analysis confirming differences in false claims or evidential quality (see Abstract and any Methods section on stimulus construction).
- [Abstract / Results] The abstract asserts that higher IH scores produced significantly lower credibility ratings for pseudoscientific content with no correlation for accurate content, but supplies no statistical details, effect sizes, confidence intervals, demographic information, exclusion criteria, or checks for confounds such as dialogue length or emotional valence, preventing evaluation of whether the data support the central claim.
minor comments (1)
- [Discussion] The evolutionary framing in the Discussion would benefit from explicit separation between the empirical findings and the interpretive claims, as the data do not test ancestral adaptations.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on stimulus validation and statistical transparency. Both points identify areas where the manuscript can be strengthened for clarity and replicability. We address each below and commit to revisions that provide the requested details without altering the core findings or interpretations.
read point-by-point responses
-
Referee: [Abstract / Methods (stimulus construction)] The assignment of the three dialogues to the accurate, moderately pseudoscientific, and strongly pseudoscientific conditions is load-bearing for the selective-filter claim, yet the manuscript provides no description of the classification procedure, rubric, expert review, inter-rater agreement, or quantitative content analysis confirming differences in false claims or evidential quality (see Abstract and any Methods section on stimulus construction).
Authors: We agree that explicit documentation of the stimulus classification is essential for evaluating the selective-filter claim. The full manuscript describes the dialogues but does not include the full rubric, expert review process, or inter-rater statistics. In revision we will add a dedicated subsection in Methods detailing the classification procedure, the rubric criteria for scientific accuracy versus pseudoscience, any expert consultation, inter-rater agreement metrics, and quantitative indicators of evidential quality differences across conditions. revision: yes
-
Referee: [Abstract / Results] The abstract asserts that higher IH scores produced significantly lower credibility ratings for pseudoscientific content with no correlation for accurate content, but supplies no statistical details, effect sizes, confidence intervals, demographic information, exclusion criteria, or checks for confounds such as dialogue length or emotional valence, preventing evaluation of whether the data support the central claim.
Authors: We accept that the abstract and results reporting require greater statistical detail for independent evaluation. The manuscript reports the key correlations but omits effect sizes, CIs, and explicit confound checks in the abstract. We will revise the abstract to include the relevant statistics (r values, p values, effect sizes, CIs) and will expand the Methods and Results sections to report participant demographics, exclusion criteria, and any post-hoc checks for dialogue length, emotional valence, or other potential confounds. revision: yes
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper reports an empirical experiment (N=99) measuring participant ratings of AI-generated dialogues on credibility and AI source detection, correlated with intellectual humility scores. No equations, fitted parameters, predictions, or derivations appear in the provided text or abstract. The central claim rests on observed selective correlations between IH and credibility ratings for pseudoscientific vs. accurate content, which are independent measurements from participants rather than quantities defined by the paper's own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The dialogue classification is a methodological premise but does not reduce any result to a self-defined input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The intellectual humility scale used produces valid and reliable scores that capture the intended metacognitive trait
- domain assumption Expert or researcher classification correctly distinguishes the three dialogues by level of scientific rigor
Reference graph
Works this paper leans on
-
[1]
Current Issues in Personality Psychology , author=
Intellectual humility: an old problem in a new psychological perspective , volume=. Current Issues in Personality Psychology , author=. 2022 , pages=
2022
-
[2]
All That ' s `Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Clark, Elizabeth and August, Tal and Serrano, Sofia and Haduong, Nikita and Gururangan, Suchin and Smith, Noah A. All That ' s `Human' Is Not Gold: Evaluating Human Evaluation of Generated Text. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing...
-
[3]
Haselton, Martie G. and Buss, David M. , title =. Journal of Personality and Social Psychology , volume =. 2000 , ISSN =. doi:10.1037/0022-3514.78.1.81 , number =
-
[4]
Jakesch, Maurice and Hancock, Jeffrey T. and Naaman, Mor , year =. Human heuristics for AI-generated language are flawed , volume =. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.2208839120 , number =
-
[5]
K\". Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry , volume =. 2021 , month = Jan, pages =. doi:10.1016/j.chb.2020.106553 , journal =
-
[6]
Social Psychological and Personality Science , publisher =
Koetke, Jonah and Schumann, Karina and Porter, Tenelle , title =. Social Psychological and Personality Science , publisher =. 2021 , month = Jan, pages =. doi:10.1177/1948550620988242 , number =
-
[7]
Krumrei-Mancuso, Elizabeth J. and Rouse, Steven V. , year =. The Development and Validation of the Comprehensive Intellectual Humility Scale , volume =. Journal of Personality Assessment , publisher =. doi:10.1080/00223891.2015.1068174 , number =
-
[8]
Leary, Mark R. and Diebels, Kate J. and Davisson, Erin K. and Jongman-Sereno, Katrina P. and Isherwood, Jennifer C. and Raimi, Kaitlin T. and Deffler, Samantha A. and Hoyle, Rick H. , year =. Cognitive and Interpersonal Features of Intellectual Humility , volume =. Personality and Social Psychology Bulletin , publisher =. doi:10.1177/0146167217697695 , number =
-
[9]
doi:10.4159/9780674977860 , publisher =
Hugo Mercier and Dan Sperber , title =. doi:10.4159/9780674977860 , publisher =
-
[10]
Porter, Brian and Machery, Edouard , year =. AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably , volume =. Scientific Reports , publisher =. doi:10.1038/s41598-024-76900-1 , number =
-
[11]
Epistemic Vigilance , volume =
Sperber, Dan and Clement, Fabrice and Heintz, Christophe and Mascaro, Olivier and Mercier, Hugo and Origgi, Gloria and Wilson, Deirdre , year =. Epistemic Vigilance , volume =. Mind `I&' Language , publisher =. doi:10.1111/j.1468-0017.2010.01394.x , number =
-
[12]
Public Health and Online Misinformation: Challenges and Recommendations , volume =
Swire-Thompson, Briony and Lazer, David , year =. Public Health and Online Misinformation: Challenges and Recommendations , volume =. Annual Review of Public Health , publisher =. doi:10.1146/annurev-publhealth-040119-094127 , number =
-
[13]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[14]
Publications Manual , year = "1983", publisher =
1983
-
[15]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[16]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[17]
Dan Gusfield , title =. 1997
1997
-
[18]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[19]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.