StandardE2E: A Unified Framework for End-to-End Autonomous Driving Datasets
Pith reviewed 2026-06-28 10:19 UTC · model grok-4.3
The pith
StandardE2E unifies six end-to-end driving datasets under one shared schema and PyTorch DataLoader.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
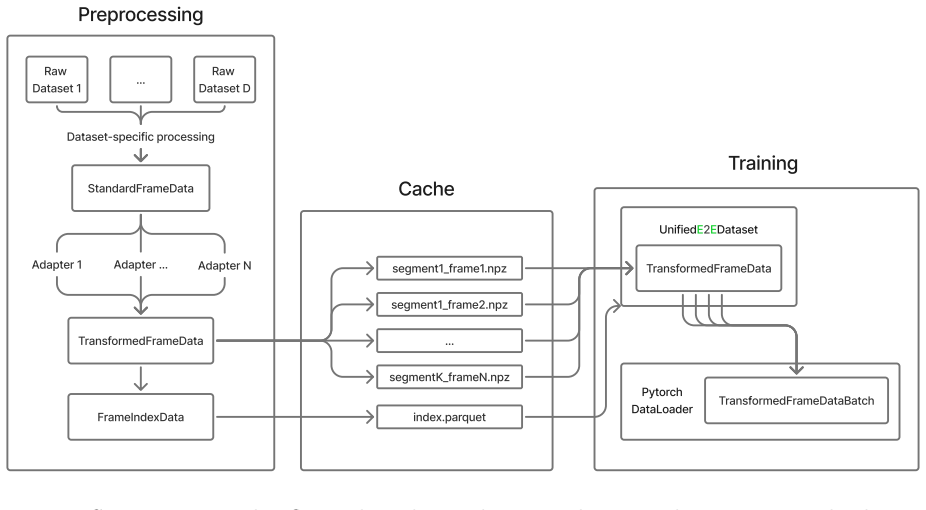
StandardE2E standardizes per-dataset preprocessing under one shared data schema, combines multiple datasets in a single PyTorch DataLoader for cross-dataset pretraining, auxiliary-task supervision, and scenario-level filtering, and reduces adding a new dataset to a single per-dataset mapping from raw frames to the canonical schema, leaving the entire downstream pipeline unchanged.
What carries the argument
The canonical data schema together with lightweight per-dataset adapters that convert raw frames into it while preserving the information required by end-to-end control, detection, forecasting, and map tasks.
If this is right
- A single DataLoader can now draw training batches from any combination of the six datasets for joint pretraining.
- Scenario-level filtering and auxiliary supervision become uniform operations rather than dataset-specific code.
- Extending the collection with a seventh dataset requires only one new mapping file and no further pipeline edits.
- Cross-dataset experiments no longer incur repeated reimplementation of coordinate transforms or modality handling.
Where Pith is reading between the lines
- Models trained on the combined collection may generalize better across sensor configurations because the schema normalizes coordinate and modality differences.
- Future dataset releases could adopt the canonical schema directly, further lowering the cost of integration.
- Benchmarking protocols that mix data sources become reproducible without hidden per-project preprocessing differences.
Load-bearing premise
A single canonical schema can be defined that preserves all information needed for the supported end-to-end tasks across the six datasets without requiring task-specific adjustments or data loss.
What would settle it
A new dataset whose raw annotations or sensor data cannot be losslessly mapped into the canonical schema for at least one of the supported auxiliary tasks, forcing either information loss or changes to the downstream pipeline.
Figures
read the original abstract
Autonomous driving has shifted from modular perception-prediction-planning stacks toward end-to-end (E2E) models that map sensor inputs directly to vehicle control, often regularized by auxiliary tasks such as 3D detection, motion forecasting, and HD-map perception. Progress is driven by a fast-growing ecosystem of sensor-rich driving datasets, yet each ships its own file formats, APIs, coordinate conventions, and modality coverage, leaving cross-dataset experimentation and even basic per-dataset preprocessing to be re-implemented per project. We present StandardE2E, a framework that provides a single unified interface over E2E driving datasets. StandardE2E (i) standardizes per-dataset preprocessing under one shared data schema; (ii) combines multiple datasets in a single PyTorch DataLoader for cross-dataset pretraining, auxiliary-task supervision, and scenario-level filtering; and (iii) reduces adding a new dataset to a single per-dataset mapping from raw frames to the canonical schema, leaving the entire downstream pipeline unchanged. The framework supports six datasets out of the box: Waymo End-to-End, Waymo Perception, Argoverse 2 Sensor, Argoverse 2 LiDAR, NAVSIM (OpenScene-v1.1), and WayveScenes101, and is released as the open-source standard-e2e Python package, available at https://github.com/stepankonev/StandardE2E.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StandardE2E, an open-source Python package providing a unified interface over six end-to-end autonomous driving datasets (Waymo End-to-End, Waymo Perception, Argoverse 2 Sensor, Argoverse 2 LiDAR, NAVSIM OpenScene-v1.1, WayveScenes101). It claims to standardize per-dataset preprocessing under one shared data schema, support combining datasets in a single PyTorch DataLoader for cross-dataset pretraining and auxiliary supervision, and reduce new-dataset integration to a single raw-to-canonical mapping that leaves downstream pipelines unchanged.
Significance. If the described schema and loader function as claimed, the framework addresses a recurring practical bottleneck in E2E driving research by eliminating repeated per-project data-handling code. The open-source release at the cited GitHub repository is a concrete strength that could enable community extensions and reproducible multi-dataset experiments.
major comments (1)
- [Abstract] Abstract and framework description: the central claim that a single canonical schema preserves all information required for the supported E2E tasks (3D detection, motion forecasting, HD-map perception) across the six datasets is asserted by construction but not supported by an explicit field-level definition of the schema or example mappings; without this, the sufficiency claim cannot be evaluated.
minor comments (2)
- The manuscript would benefit from a table or section listing the canonical schema fields and their coverage per original dataset.
- Include at least one minimal usage example (DataLoader instantiation and batch structure) to demonstrate the unified interface.
Simulated Author's Rebuttal
We thank the referee for the constructive comment. We address it point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and framework description: the central claim that a single canonical schema preserves all information required for the supported E2E tasks (3D detection, motion forecasting, HD-map perception) across the six datasets is asserted by construction but not supported by an explicit field-level definition of the schema or example mappings; without this, the sufficiency claim cannot be evaluated.
Authors: We agree that an explicit field-level definition of the canonical schema, together with concrete example mappings, is necessary to substantiate the claim that all required information for the listed tasks is preserved. In the revised manuscript we will insert a new subsection (or expanded table) that enumerates every field in the shared schema, states its type and semantics, and supplies at least one worked mapping from each of the six datasets. This material will be placed in the main body so that readers can directly verify sufficiency for 3D detection, motion forecasting, and HD-map perception. revision: yes
Circularity Check
No circularity; software framework with no derivations or fitted claims
full rationale
The manuscript describes a data standardization library and PyTorch loader. No equations, predictions, fitted parameters, or theorems are present. The central claim (a canonical schema plus unified loader) is realized by explicit per-dataset mapping code rather than derived from prior results or self-citations. All six datasets are stated to be mapped, so sufficiency is shown by construction of the implementation itself. No load-bearing self-citation or ansatz appears. This is a normal non-finding for an engineering tool paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[2]
nuPlan: A closed-loop ml-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuPlan: A closed-loop ml-based planning benchmark for autonomous vehicles. InCVPR Workshop on Autonomous Driving (ADP3), 2021
2021
-
[3]
TransFuser: Imitation with transformer-based sensor fusion for autonomous driving
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. TransFuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 45(11), 2023
2023
-
[4]
NAVSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. NAVSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[5]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, 5 and Hongyang Li. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[6]
trajdata: A unified interface to multiple human trajectory datasets
Boris Ivanovic, Guanyu Song, Igor Gilitschenski, and Marco Pavone. trajdata: A unified interface to multiple human trajectory datasets. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
2023
-
[7]
VAD: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. VAD: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
- [8]
-
[9]
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, Yu-Gang Jiang, and Jose M. Alvarez. Hydra-MDP: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[11]
PARA-Drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. PARA-Drive: Parallelized architecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[12]
Argoverse 2: Next generation datasets for self-driving perception and forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InAdvances in Neural Information Processing Systems (NeurIPS), Datase...
2021
-
[13]
Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios,
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Ekaterina Tolstaya, Sarah Tang, Brandyn White, Ben Sapp, Mingxing Tan, Jyh-Jing Hwang, and Dragomir Anguelov. WOD-E2E: Waymo open dataset for end-to-end driving in challenging long-tail scenarios.arXiv preprint arXiv:2510.26125, 2025
-
[14]
GenAD: Generative end-to-end autonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. GenAD: Generative end-to-end autonomous driving. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[15]
Jannik Zürn, Paul Gladkov, Sofía Dudas, Fergal Cotter, Sofi Toteva, Jamie Shotton, Vasiliki Simaiaki, and Nikhil Mohan. WayveScenes101: A dataset and benchmark for novel view synthesis in autonomous driving.arXiv preprint arXiv:2407.08280, 2024. 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.