Dataset Biases and Shortcut Learning in Motion-Based AI-Generated Video Detection
Pith reviewed 2026-07-02 13:50 UTC · model grok-4.3
The pith
Motion-based detectors for AI videos rely on shortcuts from less movement in synthetic clips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
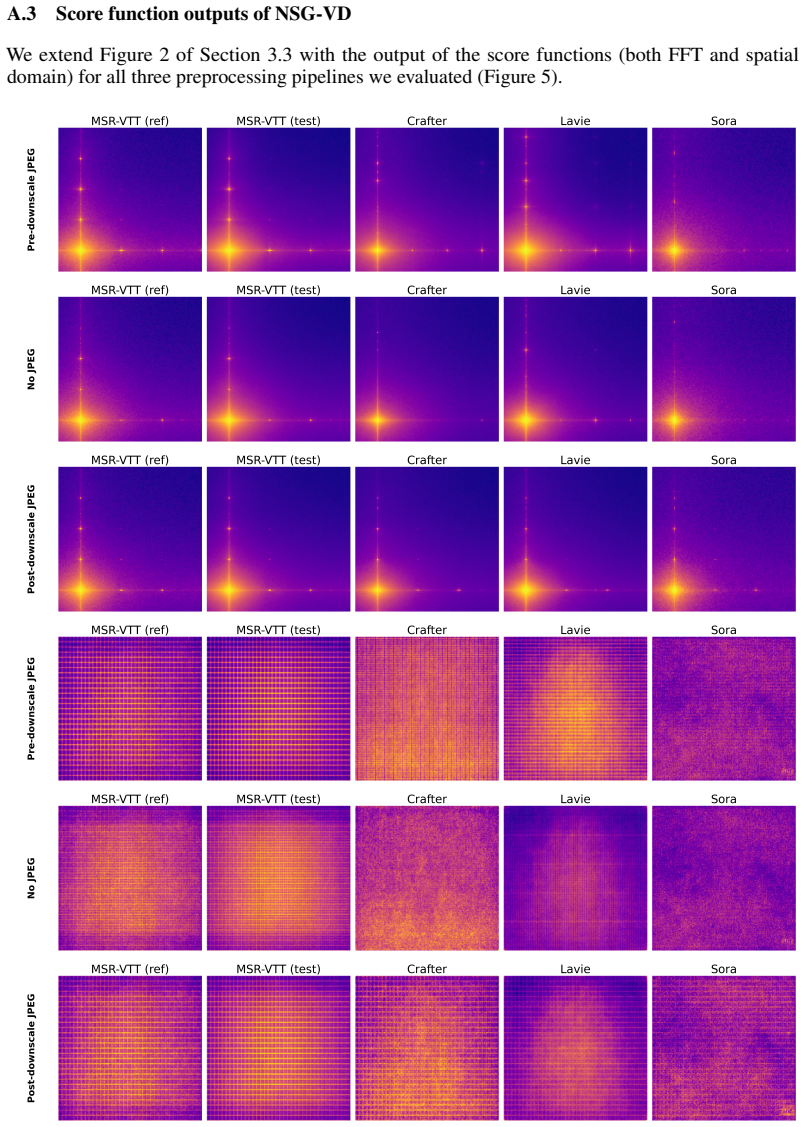
Motion-based detectors for AI-generated videos exploit the fact that synthetic clips in standard datasets display reduced inter-frame movement compared with real videos, plus preprocessing differences; once these dataset biases are removed through rebalancing or simple spatial augmentations, detection performance drops to near-random levels for all tested motion-based models, while an existing frequency-based detector retains strong results on every dataset.
What carries the argument
The motion bias in which AI-generated videos exhibit less inter-frame movement than real videos, together with preprocessing and sampling biases that the detectors latch onto.
If this is right
- Reported high accuracy of motion-based detectors does not indicate they have learned general synthetic-video cues.
- Evaluation must use datasets that lack the motion bias to measure true detection ability.
- Frequency-based methods appear more stable when motion statistics are equalized.
- Future datasets need to be built without systematic differences in inter-frame movement or preprocessing.
Where Pith is reading between the lines
- Similar motion or preprocessing shortcuts may exist in detectors for other media types such as images or audio.
- Detection systems intended for real-world use should be validated on multiple independently sourced datasets rather than single benchmarks.
- Methods that ignore temporal motion entirely might generalize better when new generative models alter movement patterns.
Load-bearing premise
Rebalancing the datasets and applying spatial augmentations remove only the intended motion and preprocessing biases without introducing new unaccounted factors that cause the performance drops.
What would settle it
Running the same detectors on a fresh dataset in which real and AI-generated videos are forced to have statistically matched motion statistics between frames.
Figures
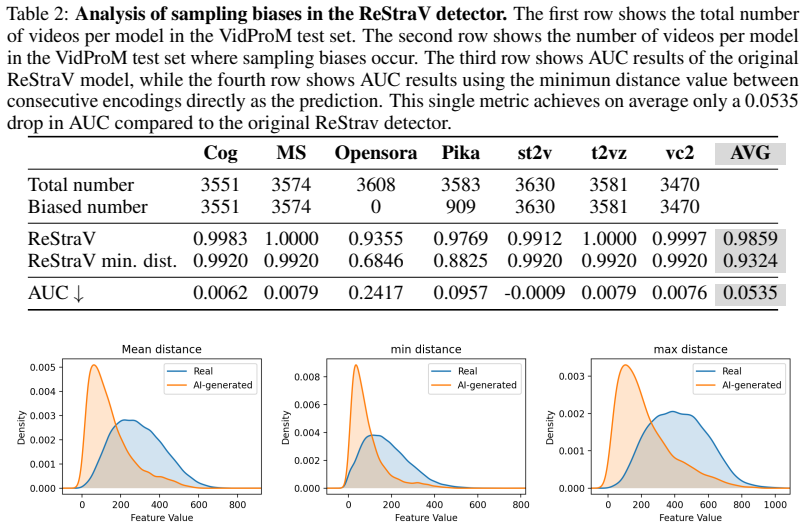
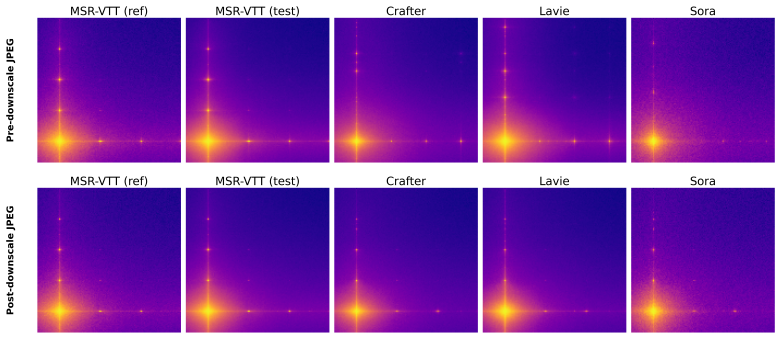
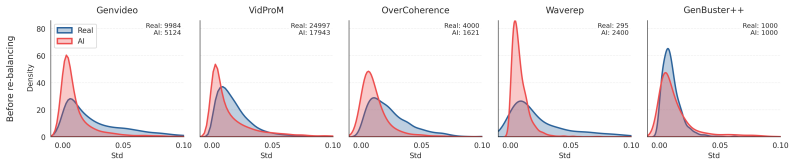
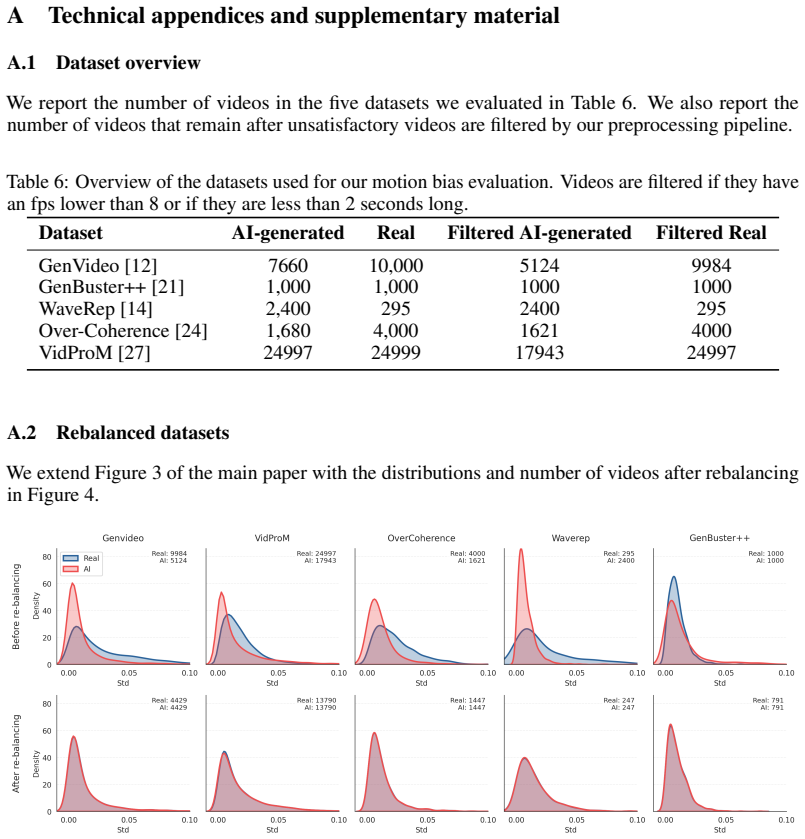
read the original abstract
The visual quality of AI-generated videos has improved drastically in recent years, making it increasingly difficult for humans to distinguish between real and synthetic media. In this work, we evaluate the robustness and applicability of four state-of-the-art motion-based AI-generated video detectors. We identify significant preprocessing and sampling biases in these methods and demonstrate that they account for a substantial portion of their reported performance. Furthermore, we find that these detectors are highly sensitive to motion patterns specific to their evaluation datasets, where AI-generated videos generally exhibit less inter-frame movement than real videos. We show that for all detectors, performance collapses to near-random levels when evaluated on a dataset that does not contain this motion bias. Additionally, through dataset rebalancing and the application of simple spatial augmentations, we observe severe performance degradation across all evaluated models. In contrast, we find that an existing frequency-based detector maintains strong performance across all evaluated datasets, suggesting that frequency-based approaches may offer a more generalizable path forward for AI-generated video detection. We hope that our work raises awareness towards these vulnerabilities and encourages the development of more representative, unbiased datasets and more robust evaluation protocols.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates four state-of-the-art motion-based detectors for AI-generated videos and identifies significant preprocessing, sampling, and motion biases (AI videos exhibit less inter-frame movement than real ones). It claims that these biases account for much of the reported performance, with accuracy collapsing to near-random levels on a rebalanced dataset lacking the motion bias and after simple spatial augmentations; by contrast, an existing frequency-based detector maintains strong performance across all datasets.
Significance. If the central empirical claims hold after addressing experimental controls, the work is significant for demonstrating shortcut learning in motion-based video detectors and for providing evidence that frequency-based methods may be more robust and generalizable. This could influence future detector design and evaluation protocols in the field, though the current presentation lacks sufficient detail to fully substantiate the attribution of performance drops.
major comments (2)
- [Experimental description] Experimental description section: The central claim that rebalancing and spatial augmentations isolate removal of the inter-frame motion bias (without introducing new confounders) is load-bearing, yet no verification is reported that other video statistics (frame-wise frequency content, compression artifacts, or content distribution) remain unchanged pre- and post-intervention; without such controls or comparisons, the performance collapse cannot be cleanly attributed to motion bias removal alone.
- [Abstract and results] Abstract and results: The reported collapse to near-random performance after rebalancing lacks accompanying details on dataset sizes, exact construction of the unbiased dataset, or statistical tests (e.g., significance of accuracy differences), which are needed to assess the reliability and magnitude of the observed degradation across models.
minor comments (1)
- [Abstract] The abstract refers to 'four state-of-the-art motion-based' detectors but does not name them explicitly; adding the specific model names would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Experimental description] Experimental description section: The central claim that rebalancing and spatial augmentations isolate removal of the inter-frame motion bias (without introducing new confounders) is load-bearing, yet no verification is reported that other video statistics (frame-wise frequency content, compression artifacts, or content distribution) remain unchanged pre- and post-intervention; without such controls or comparisons, the performance collapse cannot be cleanly attributed to motion bias removal alone.
Authors: We agree that additional verification is needed to strengthen the attribution of performance changes specifically to motion bias removal. In the revised manuscript, we will add quantitative comparisons of frame-wise frequency content, compression artifacts, and content distribution (e.g., via histograms or statistical distances) before and after the rebalancing and spatial augmentations. This will be included in a new subsection under Experiments, with discussion of any observed differences and their potential impact. revision: yes
-
Referee: [Abstract and results] Abstract and results: The reported collapse to near-random performance after rebalancing lacks accompanying details on dataset sizes, exact construction of the unbiased dataset, or statistical tests (e.g., significance of accuracy differences), which are needed to assess the reliability and magnitude of the observed degradation across models.
Authors: We acknowledge that these details are necessary for assessing reliability. The revised manuscript will include: (1) exact sizes of all datasets (original and rebalanced), (2) a precise description of the unbiased dataset construction (including sampling criteria for motion statistics), and (3) statistical tests (e.g., McNemar's test or bootstrap confidence intervals) for the accuracy differences, reported with p-values. These will appear in the Results section and an expanded appendix with tables. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential constructions
full rationale
The paper is an empirical comparison of motion-based detectors across original, rebalanced, and augmented datasets. All claims rest on observed accuracy differences (e.g., collapse to near-random levels after interventions). No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the abstract or described methodology. The central result (performance degradation after rebalancing/augmentations) is a direct experimental outcome, not a reduction by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Introducing veo 3, our video generation model with expanded creative controls – including native audio and extended videos.https://deepmind.google/models/ veo/, 2025
Google DeepMind. Introducing veo 3, our video generation model with expanded creative controls – including native audio and extended videos.https://deepmind.google/models/ veo/, 2025
2025
-
[5]
Sora 2 is here.https://openai.com/index/sora-2/, 2025
OpenAI. Sora 2 is here.https://openai.com/index/sora-2/, 2025
2025
-
[6]
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly. As good as a coin toss: Human detection of ai-generated images, videos, audio, and audiovisual stimuli.arXiv preprint arXiv:2403.16760, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, and Yang Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, page 3403–3417, New York, NY , USA, 2023. Association for Computing Machine...
-
[8]
Typology of risks of generative text-to- image models
Charlotte Bird, Eddie Ungless, and Atoosa Kasirzadeh. Typology of risks of generative text-to- image models. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’23, page 396–410, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9798400702310. doi: 10.1145/3600211.3604722. URL https://doi.org/10.1145/ 3600211.3604722
-
[9]
Synthetic human memories: Ai-edited images and videos can implant false memories and distort recollection
Pat Pataranutaporn, Chayapatr Archiwaranguprok, Samantha WT Chan, Elizabeth Loftus, and Pattie Maes. Synthetic human memories: Ai-edited images and videos can implant false memories and distort recollection. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20, 2025
2025
-
[10]
Tall: Thumbnail layout for deepfake video detection
Yuting Xu, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. Tall: Thumbnail layout for deepfake video detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 22658–22668, 2023
2023
-
[11]
Lips don’t lie: A generalisable and robust approach to face forgery detection
Alexandros Haliassos, Konstantinos V ougioukas, Stavros Petridis, and Maja Pantic. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5039–5049, 2021
2021
-
[12]
Haoxing Chen, Yan Hong, Zizheng Huang, Zhuoer Xu, Zhangxuan Gu, Yaohui Li, Jun Lan, Huijia Zhu, Jianfu Zhang, Weiqiang Wang, et al. Demamba: Ai-generated video detection on million-scale genvideo benchmark.arXiv preprint arXiv:2405.19707, 2024. 10
-
[13]
Ai-generated video detection via spatial-temporal anomaly learning
Jianfa Bai, Man Lin, Gang Cao, and Zijie Lou. Ai-generated video detection via spatial-temporal anomaly learning. InPattern Recognition and Computer Vision: 7th Chinese Conference, PRCV 2024, Urumqi, China, October 18–20, 2024, Proceedings, Part X, page 460–470, Berlin, Heidel- berg, 2024. Springer-Verlag. ISBN 978-981-97-8791-3. doi: 10.1007/978-981-97-8...
-
[14]
Seeing what matters: Generalizable ai-generated video detection with forensic- oriented augmentation
Riccardo Corvi, Davide Cozzolino, Ekta Prashnani, Shalini De Mello, Koki Nagano, and Luisa Verdoliva. Seeing what matters: Generalizable ai-generated video detection with forensic- oriented augmentation. InThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems, 2025. URLhttps://openreview.net/forum?id=dOGXKBL7IE
2025
-
[15]
Physics-driven spatiotemporal modeling for ai-generated video detection
Shuhai Zhang, Zihao Lian, Jiahao Yang, Daiyuan Li, Guoxuan Pang, Feng Liu, Bo Han, Shutao Li, and Mingkui Tan. Physics-driven spatiotemporal modeling for ai-generated video detection. InAdvances in Neural Information Processing Systems, 2025
2025
-
[16]
Towards a universal synthetic video detector: From face or background manipulations to fully ai- generated content
Rohit Kundu, Hao Xiong, Vishal Mohanty, Athula Balachandran, and Amit K Roy-Chowdhury. Towards a universal synthetic video detector: From face or background manipulations to fully ai- generated content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28050–28060, 2025
2025
-
[17]
Text-vision embedding for generalized diffusion generated videos detection
Jinchuan Li, Jinlin Guo, Yun Cao, Zeyu Zhang, and Kangwei Liu. Text-vision embedding for generalized diffusion generated videos detection. InPattern Recognition and Computer Vision: 8th Chinese Conference, PRCV 2025, Shanghai, China, October 15–18, 2025, Proceedings, Part XIII, page 121–134, Berlin, Heidelberg, 2026. Springer-Verlag. ISBN 978-981-95-5633-...
-
[18]
Turns out i’m not real: Towards robust detection of ai-generated videos, 2024
Qingyuan Liu, Pengyuan Shi, Yun-Yun Tsai, Chengzhi Mao, and Junfeng Yang. Turns out i’m not real: Towards robust detection of ai-generated videos, 2024. URL https://arxiv.org/ abs/2406.09601
-
[19]
On learning multi-modal forgery representation for diffusion generated video detection.Advances in Neural Information Processing Systems, 37:122054–122077, 2024
Xiufeng Song, Xiao Guo, Jiache Zhang, Qirui Li, Lei Bai, Xiaoming Liu, Guangtao Zhai, and Xiaohong Liu. On learning multi-modal forgery representation for diffusion generated video detection.Advances in Neural Information Processing Systems, 37:122054–122077, 2024
2024
-
[20]
Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl
Kyoungjun Park, Yifan Yang, Juheon Yi, Shicheng Zheng, Yifei Shen, Dongqi Han, Caihua Shan, Muhammad Muaz, and Lili Qiu. Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl. InICLR 2026, April 2026
2026
-
[21]
BusterX++: Towards Unified Cross-Modal AI-Generated Content Detection and Explanation with MLLM
Haiquan Wen, Tianxiao Li, Zhenglin Huang, Yiwei He, and Guangliang Cheng. Busterx++: Towards unified cross-modal ai-generated content detection and explanation with mllm.arXiv preprint arXiv:2507.14632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
D3: Training-free ai-generated video detection using second-order features
Chende Zheng, Ruiqi Suo, Chenhao Lin, Zhengyu Zhao, Le Yang, Shuai Liu, Minghui Yang, Cong Wang, and Chao Shen. D3: Training-free ai-generated video detection using second-order features. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12852–12862, October 2025
2025
-
[23]
AI-generated video detection via perceptual straightening
Christian Internò, Robert Geirhos, Markus Olhofer, Sunny Liu, Barbara Hammer, and David Klindt. AI-generated video detection via perceptual straightening. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=LsmUgStXby
2026
-
[24]
Training-free detection of text-to-video generations via over-coherence
Jonathan Brokman, Oren Rachmil, Omer Hofman, Roy Betser, Amit Giloni, Roman Vainshtein, and Hisashi Kojima. Training-free detection of text-to-video generations via over-coherence. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3993–4003, March 2026
2026
-
[25]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[26]
Expanding language-image pretrained models for general video recognition
Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. InEuropean conference on computer vision, pages 1–18. Springer, 2022
2022
-
[27]
Vidprom: A million-scale real prompt-gallery dataset for text-to- video diffusion models.Advances in Neural Information Processing Systems, 37:65618–65642, 2024
Wenhao Wang and Yi Yang. Vidprom: A million-scale real prompt-gallery dataset for text-to- video diffusion models.Advances in Neural Information Processing Systems, 37:65618–65642, 2024
2024
-
[28]
A possible pitfall in the experimental analysis of tampering detection algorithms
Giuseppe Cattaneo and Gianluca Roscigno. A possible pitfall in the experimental analysis of tampering detection algorithms. In2014 17th International Conference on Network-Based Information Systems, pages 279–286. IEEE, 2014
2014
-
[29]
Miguel Bordallo López, Elhocine Boutellaa, and Abdenour Hadid. Comments on the “kinship face in the wild” data sets.IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(11):2342–2344, 2016. doi: 10.1109/TPAMI.2016.2522416
-
[30]
criminality from face
Kevin W Bowyer, Michael C King, Walter J Scheirer, and Kushal Vangara. The “criminality from face” illusion.IEEE Transactions on Technology and Society, 1(4):175–183, 2020
2020
-
[31]
Mostafa, Fernando Pérez-González, and Miguel Masciopinto
Aya A. Mostafa, Fernando Pérez-González, and Miguel Masciopinto. Exploring the pitfalls of black boxes in media forensics: A case study in source camera identification.IEEE Access, 13: 76528–76547, 2025. doi: 10.1109/ACCESS.2025.3563784
-
[32]
Fake or jpeg? revealing common biases in generated image detection datasets
Patrick Grommelt, Louis Weiss, Franz-Josef Pfreundt, and Janis Keuper. Fake or jpeg? revealing common biases in generated image detection datasets. InEuropean Conference on Computer Vision, pages 80–95. Springer, 2024
2024
-
[33]
Combating dataset misalignment for robust ai-generated image detection in the real world
Hyeongjun Choi, Inho Jung, and Simon S Woo. Combating dataset misalignment for robust ai-generated image detection in the real world. InProceedings of the 4th Workshop on Security Implications of Deepfakes and Cheapfakes, pages 15–20, 2025
2025
-
[34]
Real-time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398, 2024
Bar Cavia, Eliahu Horwitz, Tal Reiss, and Yedid Hoshen. Real-time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398, 2024
-
[35]
A bias-free training paradigm for more general ai-generated image detection
Fabrizio Guillaro, Giada Zingarini, Ben Usman, Avneesh Sud, Davide Cozzolino, and Luisa Verdoliva. A bias-free training paradigm for more general ai-generated image detection. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18685–18694, 2025
2025
-
[36]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016
2016
-
[37]
Training- free detection of generated videos via spatial-temporal likelihoods
Omer Ben Hayun, Roy Betser, Meir Yossef Levi, Levi Kassel, and Guy Gilboa. Training- free detection of generated videos via spatial-temporal likelihoods. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. URL https: //arxiv.org/abs/2603.15026
-
[38]
Perceptual straightening of natural videos.Nature neuroscience, 22(6):984–991, 2019
Olivier J Hénaff, Robbe LT Goris, and Eero P Simoncelli. Perceptual straightening of natural videos.Nature neuroscience, 22(6):984–991, 2019
2019
-
[39]
The kinetics human action video dataset
Andrew Zisserman, Joao Carreira, Karen Simonyan, Will Kay, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, and Mustafa Suleyman. The kinetics human action video dataset. 2017
2017
-
[40]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 12 A Technical appendices and supplementary material A...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.