MVPruner: Dynamic Token Pruning for Accelerating Multi-view Vision-Language Models in Autonomous Driving
Pith reviewed 2026-06-29 05:06 UTC · model grok-4.3
The pith
MVPruner uses two-stage pruning to cut FLOPs 87% in multi-view driving VLMs while retaining 98.5% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
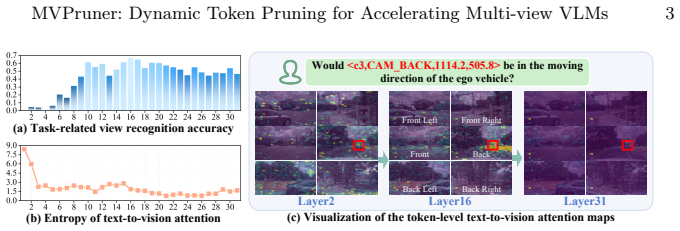
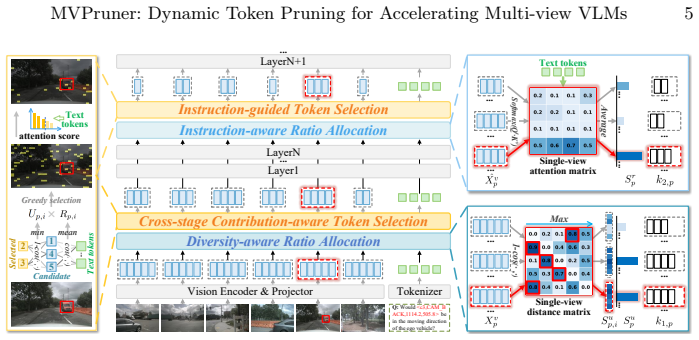
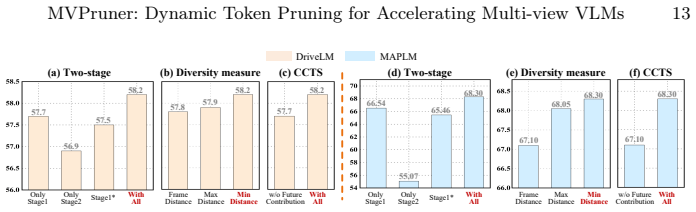
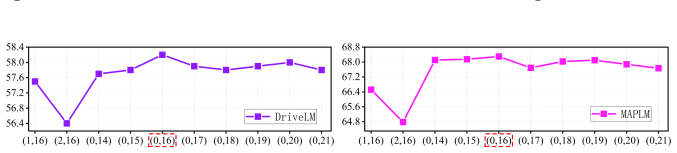
Multi-view VLMs encode task-related view priors in deeper layers and exhibit dynamic information requirements during inference. MVPruner addresses this with a two-stage adaptive token pruning method: the first stage allocates budgets based on per-view information diversity and retains tokens with consistent contribution across stages to preserve semantic capacity; the second stage allocates budgets and selects tokens guided by the instruction text to ensure task alignment. On DriveMM this yields 87.3% FLOP reduction and 4.97x prefilling speedup while retaining 98.5% accuracy on DriveLM.
What carries the argument
Two-stage adaptive token pruning that first allocates budgets by view information diversity and retains consistent contributors, then applies instruction-guided selection for task alignment.
If this is right
- DriveMM with MVPruner achieves 87.3% FLOP reduction and 4.97x prefilling speedup while retaining 98.5% accuracy on DriveLM.
- The method outperforms fixed-rate and static pruning approaches on four benchmarks by adapting to inter-view differences.
- Semantic representational capacity is preserved by retaining tokens with consistent contribution across stages.
- Pruning aligns with the model's evolving information importance and deeper view priors.
Where Pith is reading between the lines
- Similar dynamic patterns may exist in other multi-modal or video models, suggesting broader use of view- or modality-diversity allocation.
- Combining the pruning with quantization or hardware scheduling could produce additional real-time gains in vehicle systems.
- The view-prior finding might guide new model designs that explicitly separate or weight inter-view features.
- Testing across more varied driving conditions would check whether the dynamic requirements generalize beyond the reported benchmarks.
Load-bearing premise
Multi-view VLMs inherently encode task-related view priors in deeper layers and show dynamic information requirements that can be used to guide pruning.
What would settle it
If deeper-layer analysis on the same models shows no view-specific priors, or if MVPruner at the reported rates drops accuracy below 98.5% on DriveLM while fixed pruning matches the speedup.
Figures


read the original abstract
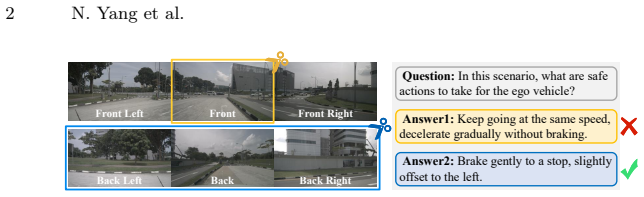
Vision-Language Models (VLMs) improve generalization and interpretability in autonomous driving but suffer from efficiency issues due to long visual token sequences, particularly in standard multi-view settings. Existing token pruning methods employ fixed pruning rate allocation and static importance metrics, ignoring dynamic inter-view importance differences and the evolving information importance during inference. Our analysis reveals that multi-view VLMs inherently encode task-related view priors in deeper layers and exhibit dynamic information requirements. Motivated by these findings, we propose MVPruner, a two-stage adaptive token pruning method that aligns pruning behavior with the model's dynamic information requirements. The first stage allocates pruning budgets based on the information diversity of each view, and retains tokens with consistent contribution across stages, ensuring semantic representational capacity. The second stage allocates budgets and selects tokens guided by instruction text to guarantee task alignment. Experimental results on four benchmarks demonstrate the superior performance of our method. For example, DriveMM equipped with MVPruner achieves 87.3% reduction in FLOPs, 4.97* speedup in prefilling phase while retaining 98.5% accuracy on DriveLM benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MVPruner, a two-stage adaptive token pruning method for multi-view VLMs in autonomous driving. Analysis of the models reveals task-related view priors encoded in deeper layers and dynamic information requirements during inference; this directly motivates stage 1 (diversity-based pruning budget allocation across views plus retention of consistently contributing tokens) and stage 2 (instruction-text-guided token selection for task alignment). Experiments on four benchmarks report that DriveMM equipped with MVPruner achieves 87.3% FLOPs reduction, 4.97× prefilling speedup, and retains 98.5% accuracy on DriveLM.
Significance. If the performance numbers prove robust under controlled evaluation, the approach targets a key efficiency bottleneck for multi-view VLMs in real-time autonomous driving. The experimental validation across multiple benchmarks is a positive element.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): The claim that the two-stage design is motivated by and aligned with inherent model properties (view priors in deeper layers; dynamic information needs) is load-bearing for the paper's novelty. The manuscript presents this as observational analysis but provides no quantified layer-wise metrics (e.g., mutual information or view-specific contribution scores) and no ablation isolating the two-stage components against a simpler adaptive baseline (single-stage diversity allocation or generic importance scoring). Without these, the reported gains could arise from generic adaptivity rather than the claimed alignment.
- [Abstract and §4] Abstract and §4 (Experiments): Performance claims (87.3% FLOPs reduction, 4.97× speedup, 98.5% accuracy retention) are stated without specification of exact baselines, number of runs, statistical significance tests, or error bars. This prevents full assessment of the superiority assertion on the four benchmarks.
minor comments (2)
- [§4] §4: Include the computational overhead of the pruning procedure itself when reporting net speedup.
- [§3.1] Notation in §3.1: Provide a precise mathematical definition of 'information diversity' used for budget allocation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the paper. We address each major point below and will revise the manuscript to incorporate additional analysis and reporting details.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The claim that the two-stage design is motivated by and aligned with inherent model properties (view priors in deeper layers; dynamic information needs) is load-bearing for the paper's novelty. The manuscript presents this as observational analysis but provides no quantified layer-wise metrics (e.g., mutual information or view-specific contribution scores) and no ablation isolating the two-stage components against a simpler adaptive baseline (single-stage diversity allocation or generic importance scoring). Without these, the reported gains could arise from generic adaptivity rather than the claimed alignment.
Authors: We agree that quantified layer-wise metrics and targeted ablations would more rigorously support the motivation. The observational analysis in §3 is based on empirical observations of attention patterns and token contributions across layers, but we will add explicit metrics such as mutual information between views and layer-wise view-specific contribution scores. We will also include ablations in §4 comparing the full two-stage MVPruner against single-stage diversity allocation and generic importance scoring baselines to isolate the contribution of the task-alignment stage. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): Performance claims (87.3% FLOPs reduction, 4.97× speedup, 98.5% accuracy retention) are stated without specification of exact baselines, number of runs, statistical significance tests, or error bars. This prevents full assessment of the superiority assertion on the four benchmarks.
Authors: We will revise the abstract and §4 to explicitly state the exact baselines used (e.g., the unpruned DriveMM model and prior token pruning methods), report results averaged over multiple runs with standard error bars, and include statistical significance tests (e.g., paired t-tests) for the key metrics on all four benchmarks. revision: yes
Circularity Check
No circularity; method is analysis-driven with external experimental validation
full rationale
The paper motivates MVPruner from its own observational analysis of view priors and dynamic requirements in multi-view VLMs, then describes a two-stage pruning method aligned with those observations. No equations, fitted parameters, or predictions are presented that reduce by construction to inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing. Performance numbers (FLOPs reduction, speedup, accuracy retention) are reported on external benchmarks (DriveLM and others) rather than derived from the motivation itself. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y.: Divprune: Diversity-based visual tokenpruningforlargemultimodalmodels.In:ProceedingsoftheComputerVision and Pattern Recognition Conference. pp. 9392–9401 (2025) 4, 10
2025
-
[2]
Token Merging: Your ViT But Faster
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461 (2022) 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
arXiv preprint arXiv:2405.17247 (2024) 1
Bordes, F., Pang, R.Y., Ajay, A., Li, A.C., Bardes, A., Petryk, S., Mañas, O., Lin, Z., Mahmoud, A., Jayaraman, B., et al.: An introduction to vision-language modeling. arXiv preprint arXiv:2405.17247 (2024) 1
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020) 1, 9
2020
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cao, X., Zhou, T., Ma, Y., Ye, W., Cui, C., Tang, K., Cao, Z., Liang, K., Wang, Z., Rehg, J.M., et al.: Maplm: A real-world large-scale vision-language benchmark for map and traffic scene understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21819–21830 (2024) 3, 9
2024
-
[6]
IEEE Transactions on Pattern Analysis and Ma- chine Intelligence (2024) 4
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence (2024) 4
2024
-
[7]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 1, 2, 4, 10
2024
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024) 8
2024
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Dhouib, M., Buscaldi, D., Vanier, S., Shabou, A.: Pact: Pruning and clustering- based token reduction for faster visual language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14582–14592 (2025) 10
2025
-
[10]
arXiv preprint arXiv:2506.06218 (2025) 3, 9
Fruhwirth-Reisinger, C., Malić, D., Lin, W., Schinagl, D., Schulter, S., Possegger, H.: Stsbench: A spatio-temporal scenario benchmark for multi-modal large lan- guage models in autonomous driving. arXiv preprint arXiv:2506.06218 (2025) 3, 9
-
[11]
arXiv preprint arXiv:2412.07689 (2024) 4, 8
Huang, Z., Feng, C., Yan, F., Xiao, B., Jie, Z., Zhong, Y., Liang, X., Ma, L.: Drivemm: All-in-one large multimodal model for autonomous driving. arXiv preprint arXiv:2412.07689 (2024) 4, 8
-
[12]
Trans- portation Research Part C: Emerging Technologies180, 105321 (2025) 1
Huang, Z., Sheng, Z., Qu, Y., You, J., Chen, S.: Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving. Trans- portation Research Part C: Emerging Technologies180, 105321 (2025) 1
2025
-
[13]
arXiv preprint arXiv:2503.10621 (2025) 1, 3, 4, 8, 9
Ishaq, A., Lahoud, J., More, K., Thawakar, O., Thawkar, R., Dissanayake, D., Ahsan, N., Li, Y., Khan, F.S., Cholakkal, H., et al.: Drivelmm-o1: A step-by-step reasoning dataset and large multimodal model for driving scenario understanding. arXiv preprint arXiv:2503.10621 (2025) 1, 3, 4, 8, 9
-
[14]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Jiang, B., Chen, S., Liao, B., Zhang, X., Yin, W., Zhang, Q., Huang, C., Liu, W., Wang, X.: Senna: Bridging large vision-language models and end-to-end au- tonomous driving. arXiv preprint arXiv:2410.22313 (2024) 4 MVPruner: Dynamic Token Pruning for Accelerating Multi-view VLMs 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
arXiv preprint arXiv:2506.24044 (2025) 1
Jiang, S., Huang, Z., Qian, K., Luo, Z., Zhu, T., Zhong, Y., Tang, Y., Kong, M., Wang, Y., Jiao, S., et al.: A survey on vision-language-action models for au- tonomous driving. arXiv preprint arXiv:2506.24044 (2025) 1
-
[16]
In: Proceedings of the European conference on computer vision (ECCV)
Kim, J., Rohrbach, A., Darrell, T., Canny, J., Akata, Z.: Textual explanations for self-driving vehicles. In: Proceedings of the European conference on computer vision (ECCV). pp. 563–578 (2018) 4
2018
-
[17]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2202.07800 (2022) 4
Liang, Y., Ge, C., Tong, Z., Song, Y., Wang, J., Xie, P.: Not all patches are what you need: Expediting vision transformers via token reorganizations. arXiv preprint arXiv:2202.07800 (2022) 4
-
[20]
Advances in neural information processing systems36, 34892–34916 (2023) 1
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 1
2023
-
[21]
IEEE Transactions on Mul- timedia27, 707–717 (2023) 1
Liu, Z., Cheng, J., Fan, J., Lin, S., Wang, Y., Zhao, X.: Multi-modal fusion based on depth adaptive mechanism for 3d object detection. IEEE Transactions on Mul- timedia27, 707–717 (2023) 1
2023
-
[22]
GPT-Driver: Learning to Drive with GPT
Mao, J., Qian, Y., Ye, J., Zhao, H., Wang, Y.: Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415 (2023) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Advances in neural infor- mation processing systems34, 13937–13949 (2021) 4
Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., Hsieh, C.J.: Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural infor- mation processing systems34, 13937–13949 (2021) 4
2021
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shao, H., Hu, Y., Wang, L., Song, G., Waslander, S.L., Liu, Y., Li, H.: Lmdrive: Closed-loop end-to-end driving with large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15120– 15130 (2024) 4
2024
-
[25]
Shao,K.,Tao,K.,Zhang,K.,Feng,S.,Cai,M.,Shang,Y.,You,H.,Qin,C.,Sui,Y., Wang, H.: When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios. arXiv preprint arXiv:2507.20198 (2025) 2, 4
-
[26]
In: European conference on computer vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European conference on computer vision. pp. 256–274. Springer (2024) 1, 3, 4, 5, 9
2024
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., et al.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2446–2454 (2020) 1
2020
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, S., Yu, Z., Jiang, X., Lan, S., Shi, M., Chang, N., Kautz, J., Li, Y., Alvarez, J.M.: Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22442–22452 (2025) 1
2025
-
[29]
IEEE Transactions on Image Processing35, 2050 – 2065 (2026) 1
Wei, H., Wang, R., Hu, H., Sun, S., Song, X., Feng, M., Guo, K., Huang, Y., Cui, H., Akhtar, N.: Monocular multi-object 3d visual language tracking. IEEE Transactions on Image Processing35, 2050 – 2065 (2026) 1
2050
-
[30]
Wen, Z., Gao, Y., Li, W., He, C., Zhang, L.: Token pruning in multimodal large lan- guage models: Are we solving the right problem? arXiv preprint arXiv:2502.11501 (2025) 2, 4 18 N. Yang et al
-
[31]
arXiv preprint arXiv:2502.11494 (2025) 4, 10
Wen, Z., Gao, Y., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., Zhang, L.: Stop looking for important tokens in multimodal language models: Duplication matters more. arXiv preprint arXiv:2502.11494 (2025) 4, 10
-
[32]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., et al.: Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. arXiv preprint arXiv:2410.17247 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
arXiv preprint arXiv:2508.13305 (2025) 1, 2, 4, 10
Xiong, M., Wen, Z., Gu, Z., Liu, X., Zhang, R., Kang, H., Yang, J., Zhang, J., Li, W., He, C., et al.: Prune2drive: A plug-and-play framework for accelerating vision-language models in autonomous driving. arXiv preprint arXiv:2508.13305 (2025) 1, 2, 4, 10
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, N., Wang, Y., Liu, Z., Li, M., An, Y., Zhao, X.: Smamba: Sparse mamba for event-based object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9229–9237 (2025) 2
2025
-
[35]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Zhang, Y., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y., Keutzer, K., et al.: Sparsevlm: Visual token sparsifica- tion for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024) 1, 2, 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
IEEE Trans- actions on Intelligent Vehicles (2024) 1, 4
Zhou, X., Liu, M., Yurtsever, E., Zagar, B.L., Zimmer, W., Cao, H., Knoll, A.C.: Vision language models in autonomous driving: A survey and outlook. IEEE Trans- actions on Intelligent Vehicles (2024) 1, 4
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.