From Uniform to Learned Graph Priors: Diffusion for Structure Discovery
Pith reviewed 2026-06-27 10:45 UTC · model grok-4.3
The pith
A diffusion-parameterized prior calibrates edge posteriors in neural relational inference to produce more decisive graph structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
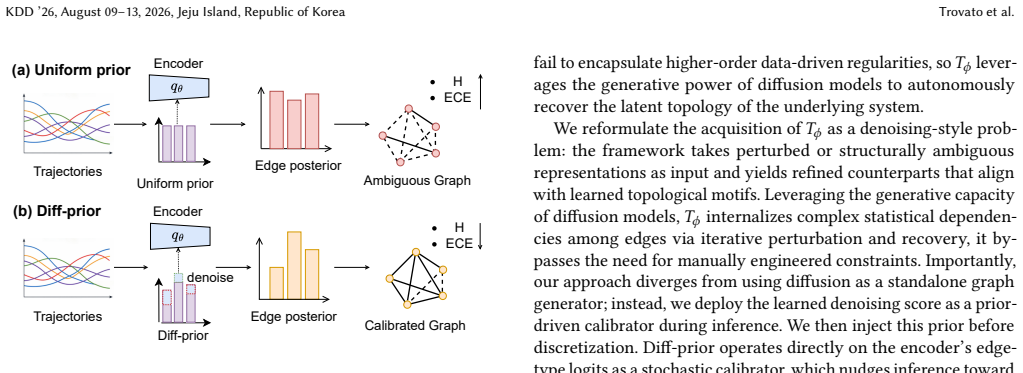
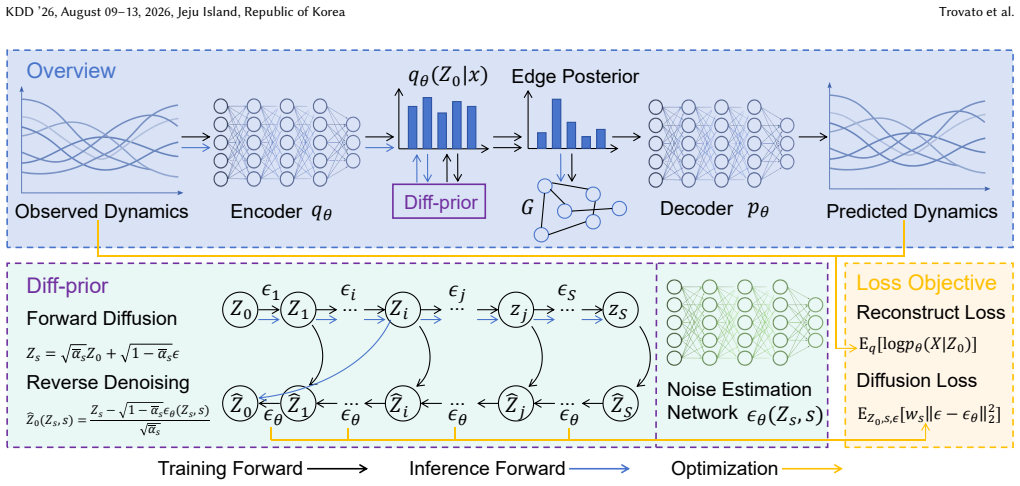
Diff-prior is a diffusion-parameterized adaptive prior used to calibrate the latent graph distribution rather than generate graphs. By reframing prior integration as a learnable denoising-style calibration, it organizes scattered edge posteriors into a more reliable overall structure. The diffusion model is trained to guide the edge posteriors towards a distribution closer to the underlying structure, operating before structural sampling as a denoising calibrator on the encoder edge distribution.
What carries the argument
Diff-prior, the diffusion model that acts as a denoising calibrator directly on the encoder edge distribution to provide structured calibration during inference.
If this is right
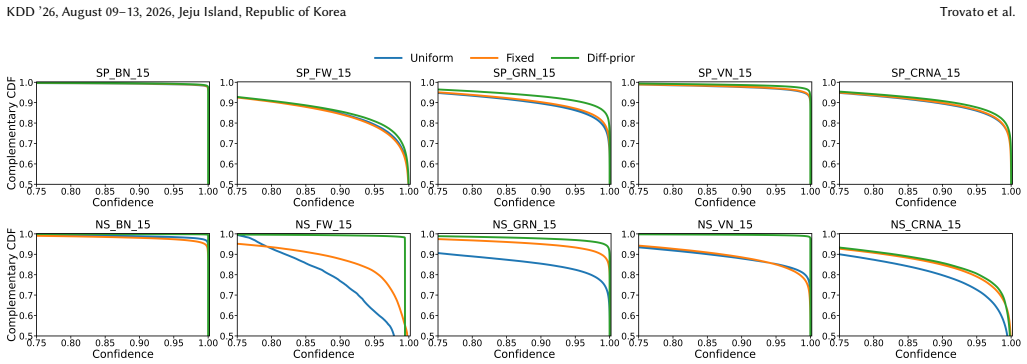
- Improves the performance of structure inference on standard benchmarks.
- Generates more decisive edge posteriors across multiple NRI-family architectures.
- Provides a generic training paradigm over structured variables.
Where Pith is reading between the lines
- This calibration could be tested by checking whether posterior entropy drops on datasets where ground-truth graphs are known in advance.
- The same denoising step might improve accuracy in downstream tasks that use the inferred graphs for prediction.
- The approach could extend to other variational models that infer discrete structures from time series.
- keywords:[
Load-bearing premise
The diffusion model trained on the encoder's edge distribution can reliably calibrate posteriors toward the true underlying graph structure without introducing systematic biases.
What would settle it
An experiment showing that the edge posterior distribution after Diff-prior calibration does not match the true graph structure more closely than the original encoder distribution on benchmark data with known interactions.
Figures
read the original abstract
Neural relational inference (NRI) methods discover interaction graphs from trajectories through variational reasoning on discrete potential edges. However, these methods typically rely on oversimplified, factorized graph priors. Such priors, typically nearing uniform distributions, treat edges as independent entities. This systemic misalignment does not match the real-world systems and yields diffuse and indecisive edge posteriors limiting the reliability of structural discovery. To address this, we propose \textit{Diff-prior}, a diffusion-parameterized adaptive prior used to calibrate latent graph distribution rather than generate graphs. Our core insight is to reframe prior integration as a learnable denoising-style calibration that organizes scattered, uncertain edge posteriors into a more reliable overall structure which can be trained by the diffusion model. Diff-prior learns an adaptive structure prior that performs structured calibration on the edge posteriors during inference, guiding it towards a distribution closer to the underlying structure. The diff-prior operates before structural sampling and acts as a denoising calibrator directly on the encoder edge distribution, which provides a generic training paradigm over structured variables. Experiments on standard benchmarks validated our framework, and the results indicate that Diff-prior improves the performance of structure inference and generates more decisive edge posteriors across multiple NRI-family architectures. The code is available on https://github.com/Hardy158118/Diffprior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Diff-prior, a diffusion-parameterized adaptive prior for neural relational inference (NRI) methods that reframes prior integration as a learnable denoising-style calibration on encoder edge posteriors. It claims this organizes uncertain posteriors into distributions closer to the underlying graph structure, yielding more decisive edge posteriors and improved structure inference performance across NRI-family architectures on standard benchmarks, with code released publicly.
Significance. If the central claim holds without circularity, the work would supply a generic paradigm for learning structured priors over discrete graph variables in unsupervised settings, addressing the mismatch between factorized uniform priors and real interaction graphs. The public code release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract (core insight paragraph): The claim that Diff-prior 'guides it towards a distribution closer to the underlying structure' rests on training the diffusion model solely on the encoder's edge distribution with no access to ground-truth graph labels. This leaves open the possibility that the model simply sharpens or reinforces the encoder's own uncertain distribution rather than correcting toward the true interaction graph, directly weakening the calibration interpretation.
- [Abstract] Abstract (experiments paragraph): The statement that 'experiments on standard benchmarks validated our framework' and that Diff-prior 'improves the performance of structure inference' is unsupported by any quantitative results, baseline comparisons, ablation studies, or controls in the provided text. Without these, the magnitude and robustness of the reported gains cannot be assessed.
minor comments (1)
- [Abstract] The abstract refers to 'NRI-family architectures' without naming the specific models tested or the precise metrics used to quantify 'more decisive edge posteriors.'
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point-by-point below and outline planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (core insight paragraph): The claim that Diff-prior 'guides it towards a distribution closer to the underlying structure' rests on training the diffusion model solely on the encoder's edge distribution with no access to ground-truth graph labels. This leaves open the possibility that the model simply sharpens or reinforces the encoder's own uncertain distribution rather than correcting toward the true interaction graph, directly weakening the calibration interpretation.
Authors: The diffusion model is trained solely on samples drawn from the encoder posterior (as correctly noted), without ground-truth graph labels. However, because the encoder is itself optimized within the end-to-end variational objective that reconstructs the observed trajectories, the posterior distribution already encodes information about plausible interaction structures present in the data. The diffusion process then learns a denoising trajectory that favors coherent graph configurations consistent with the empirical data manifold rather than arbitrary sharpening. This mechanism is detailed in Section 3.2 of the full manuscript. To prevent misinterpretation we will revise the abstract wording and add an explicit paragraph in the methods clarifying the unsupervised training dynamics and the distinction from simple sharpening. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): The statement that 'experiments on standard benchmarks validated our framework' and that Diff-prior 'improves the performance of structure inference' is unsupported by any quantitative results, baseline comparisons, ablation studies, or controls in the provided text. Without these, the magnitude and robustness of the reported gains cannot be assessed.
Authors: The abstract is a concise summary; the full manuscript (Sections 4 and 5) contains the requested quantitative results, including tables with performance metrics on standard NRI benchmarks, comparisons against multiple baselines, ablation studies, and controls across NRI-family architectures. To make the abstract self-contained we will incorporate key numerical highlights (e.g., relative improvements in edge accuracy and posterior decisiveness) while preserving length constraints. revision: yes
Circularity Check
No load-bearing circularity; empirical claims rest on benchmark results rather than definitional reduction
full rationale
The provided abstract and description contain no equations, derivations, or self-citations that reduce the claimed performance gains to a quantity defined by the method itself. Diff-prior is presented as a learnable calibration trained on encoder outputs, with improvements asserted via experiments on standard benchmarks. This matches the default expectation of no significant circularity (score 0-2) when no specific reduction by construction can be quoted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A diffusion model can be trained to learn an adaptive structure prior that improves edge posterior calibration
Reference graph
Works this paper leans on
-
[1]
Battaglia, Jessica B
Peter W. Battaglia, Jessica B. Hamrick, and Joshua B. Tenenbaum. Interaction networks for learning about objects, relations and physics.Advances in Neural Information Processing Systems (NeurIPS), 29:4502–4510, 2016
2016
-
[2]
Neural relational inference for interacting systems
Thomas Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard Zemel. Neural relational inference for interacting systems. InInternational conference on machine learning, pages 2688–2697. PMLR, 2018
2018
-
[3]
Factorised Neural Relational Inference for Multi-Interaction Systems
Ezra Webb, Ben Day, Helena Andres-Terre, and Pietro Lió. Factorised neural relational inference for multi-interaction systems.arXiv preprint arXiv:1905.08721, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[4]
A graph dynamics prior for rela- tional inference
Liming Pan, Cheng Shi, and Ivan Dokmanic. A graph dynamics prior for rela- tional inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14508–14516, 2024
2024
-
[5]
Learning latent graph structures and their uncertainty.arXiv preprint arXiv:2405.19933, 2024
Alessandro Manenti, Daniele Zambon, and Cesare Alippi. Learning latent graph structures and their uncertainty.arXiv preprint arXiv:2405.19933, 2024
-
[6]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. InInternational Conference on Learning Representations, 2017
2017
-
[7]
The concrete distribution: A continuous relaxation of discrete random variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representations, 2017
2017
-
[8]
Benchmarking structural inference methods for interacting dynamical systems with synthetic data.Advances in Neural Information Processing Systems, 37:135129–135185, 2024
Aoran Wang, Tsz Pan Tong, Andrzej Mizera, and Jun Pang. Benchmarking structural inference methods for interacting dynamical systems with synthetic data.Advances in Neural Information Processing Systems, 37:135129–135185, 2024
2024
-
[9]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017
2017
-
[10]
Graph networks as learnable physics engines for inference and control
Alvaro Sanchez-Gonzalez, Nicolas Heess, Jost Tobias Springenberg, Josh Merel, Martin Riedmiller, Raia Hadsell, and Peter Battaglia. Graph networks as learnable physics engines for inference and control. InInternational conference on machine learning, pages 4470–4479. PMLR, 2018
2018
-
[11]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
2024
-
[12]
Structural inference of dynamical systems with conjoined state space models.Advances in Neural Information Processing Systems, 37:75355–75391, 2024
Aoran Wang and Jun Pang. Structural inference of dynamical systems with conjoined state space models.Advances in Neural Information Processing Systems, 37:75355–75391, 2024
2024
-
[13]
Relational inductive biases, deep learning, and graph networks
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Learning to simulate complex physics with graph networks
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter Battaglia. Learning to simulate complex physics with graph networks. InInternational conference on machine learning, pages 8459–8468. PMLR, 2020
2020
-
[15]
Learning dynamical systems from data: An introduction to physics-guided deep learning.Proceedings of the National Academy of Sciences, 121(27):e2311808121, 2024
Rose Yu and Rui Wang. Learning dynamical systems from data: An introduction to physics-guided deep learning.Proceedings of the National Academy of Sciences, 121(27):e2311808121, 2024
2024
-
[16]
Learning to simulate unseen physical systems with graph neural networks
Ce Yang, Weihao Gao, Di Wu, and Chong Wang. Learning to simulate unseen physical systems with graph neural networks. InNeurIPS 2021 AI for Science Workshop, 2021
2021
-
[17]
Learning dynamics and structure of complex systems using graph neural networks
Zhe Li, Andreas S Tolias, and Xaq Pitkow. Learning dynamics and structure of complex systems using graph neural networks. InA causal view on dynamical systems, NeurIPS 2022 workshop, 2022
2022
-
[18]
On the relationships between graph neural networks for the simulation of physical sys- tems and classical numerical methods
Artur Toshev, Ludger Paehler, Andrea Panizza, and Nikolaus A Adams. On the relationships between graph neural networks for the simulation of physical sys- tems and classical numerical methods. InICML 2022 2nd AI for Science Workshop, 2022
2022
-
[19]
Dynamic neural relational inference
Colin Graber and Alexander G Schwing. Dynamic neural relational inference. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8513–8522, 2020
2020
-
[20]
Semi-implicit neural ordinary differ- ential equations
Hong Zhang, Ying Liu, and Romit Maulik. Semi-implicit neural ordinary differ- ential equations. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22416–22424, 2025
2025
-
[21]
Pre- dicting the dynamics of complex system via multiscale diffusion autoencoder
Ruikun Li, Jingwen Cheng, Huandong Wang, Qingmin Liao, and Yong Li. Pre- dicting the dynamics of complex system via multiscale diffusion autoencoder. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, page 1493–1504, New York, NY, USA, 2025. Association for Computing Machinery
2025
-
[22]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[23]
Autoregressive diffusion model for graph generation
Lingkai Kong, Jiaming Cui, Haotian Sun, Yuchen Zhuang, B Aditya Prakash, and Chao Zhang. Autoregressive diffusion model for graph generation. In International conference on machine learning, pages 17391–17408. PMLR, 2023
2023
-
[24]
Graphusion: Latent diffusion for graph generation.IEEE Transactions on Knowledge and Data Engineering, 36(11):6358–6369, 2024
Ling Yang, Zhilin Huang, Zhilong Zhang, Zhongyi Liu, Shenda Hong, Wentao Zhang, Wenming Yang, Bin Cui, and Luxia Zhang. Graphusion: Latent diffusion for graph generation.IEEE Transactions on Knowledge and Data Engineering, 36(11):6358–6369, 2024. Diff-prior KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea
2024
-
[25]
Structured denoising diffusion models in discrete state-spaces.Ad- vances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Ad- vances in neural information processing systems, 34:17981–17993, 2021
2021
-
[26]
Digress: Discrete denoising diffusion for graph generation
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, Volkan Cevher, and Pascal Frossard. Digress: Discrete denoising diffusion for graph generation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[27]
Pard: Permutation-invariant autoregressive diffusion for graph generation.Advances in Neural Information Processing Systems, 37:7156–7184, 2024
Lingxiao Zhao, Xueying Ding, and Leman Akoglu. Pard: Permutation-invariant autoregressive diffusion for graph generation.Advances in Neural Information Processing Systems, 37:7156–7184, 2024
2024
-
[28]
Graph diffusion transformers for multi-conditional molecular generation.Advances in Neural Information Processing Systems, 37:8065–8092, 2024
Gang Liu, Jiaxin Xu, Tengfei Luo, and Meng Jiang. Graph diffusion transformers for multi-conditional molecular generation.Advances in Neural Information Processing Systems, 37:8065–8092, 2024
2024
-
[29]
Amortized causal discovery: Learning to infer causal graphs from time-series data
Sindy Löwe, David Madras, Richard Zemel, and Max Welling. Amortized causal discovery: Learning to infer causal graphs from time-series data. InConference on Causal Learning and Reasoning, pages 509–525. PMLR, 2022
2022
-
[30]
Siyuan Chen, Jiahai Wang, and Guoqing Li. Neural relational inference with efficient message passing mechanisms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 7055–7063, 2021. A Why Use Joint Distribution Optimization This appendix explains why simplifications that drop terms treated as constants (e.g., 𝐶1, 𝐶2) in ESM–D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.