Decoupling Thought from Speech: Knowledge-Grounded Counterfactual Reasoning for Resilient Multi-Agent Argumentation
Pith reviewed 2026-06-27 11:22 UTC · model grok-4.3
The pith
Separating private planning from public execution prevents quality loss in multi-agent debates under sustained shocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
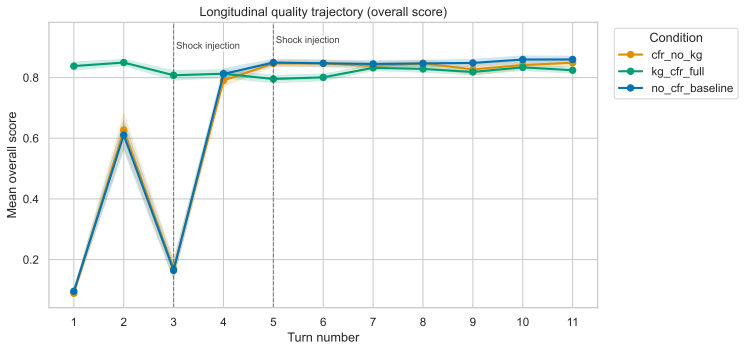
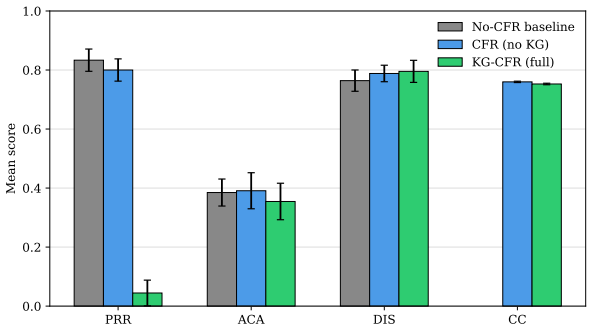
KG-CFR demonstrates that architectural decoupling between a private, retrieval-augmented planning buffer and a public execution layer enhances systemic resilience in multi-agent argumentation under sustained pressure. In the DRAU environment, this prevents judge-detected critical post-shock degradation (Δ ≤ -0.20) in more than 95% of perturbed runs while increasing argument quality to 0.822. Custom metrics show reduced semantic looping through preserved consistency with the original plan, and ablations suggest doctrinal grounding is equally vital as prospective planning.
What carries the argument
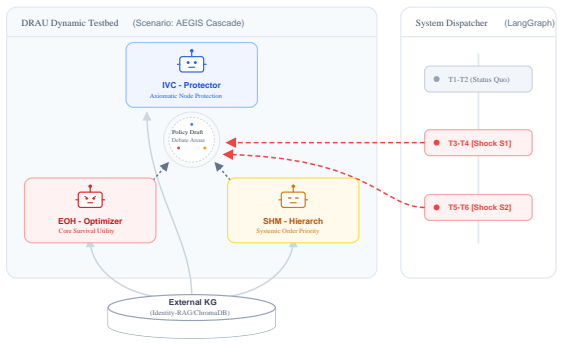
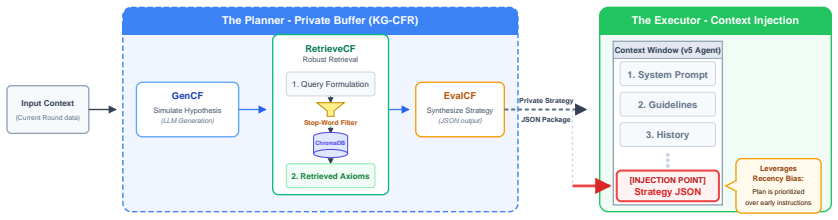
KG-CFR dual-stage architecture that enforces separation of a private retrieval-augmented planning buffer from the public execution layer.
If this is right
- Prevents judge-detected critical quality degradation in more than 95 percent of perturbed runs
- Raises overall argument quality from 0.694 to 0.822 across the tested trajectories
- Reduces semantic looping by maintaining consistency between plans and public execution
- Shows doctrinal grounding contributes to quality as much as prospective planning does
Where Pith is reading between the lines
- The private buffer approach might extend to single-agent long-horizon tasks to maintain coherence without external debate partners.
- The vector metrics for stability could diagnose drift in existing multi-agent systems before full redesigns are needed.
- If real-world uncertainties resemble the simulated shocks, similar separation could improve reliability in deployed collaborative AI tools.
Load-bearing premise
The DRAU 1v1v1 environment with stochastic shocks and the custom vector metrics for discourse divergence and plan-execution alignment provide a valid test of resilience in multi-agent argumentation.
What would settle it
Observing critical post-shock degradation (Δ ≤ -0.20) in more than 5 percent of perturbed DRAU runs under KG-CFR would show the decoupling fails to deliver the claimed resilience.
Figures
read the original abstract
Multi-agent debate frameworks have been shown to improve large language model performance in convergent tasks, but they are currently optimized in a way that heavily favors final output accuracy rather than stability of the process. During long-horizon exchanges reactive systems under sustained perturbations often experience logic degradation, argument repetition, and role drift. To structurally prevent the identity loss and maintain the process fidelity, we introduce Knowledge-Grounded Counterfactual Reasoning (KG-CFR), a dual-stage architecture that enforces a strict separation of concerns between a private, retrieval-augmented planning buffer, and a public execution layer. We assess this system in Dynamic Resource Allocation under Uncertainty (DRAU), a dedicated 1v1v1 environment, introducing diversity as distinct from standard debate settings. Over 270 completely factorial crisis simulation trajectories with stochastic environmental shocks, KG-CFR prevents judge-detected critical post-shock degradation (defined as a quality shift, $\Delta \le -0.20$) in more than 95% of perturbed runs, increasing the overall argument quality from 0.694 to 0.822. Our primary contribution is the demonstration of architectural decoupling being an important factor of systemic resilience enhancement under sustained pressure without quality loss. Furthermore, we introduce custom vector metrics for discourse divergence and plan-execution alignment that provide strong, directionally consistent evidence of operational stability. Our ablation experiments suggest that the proper doctrinal grounding can be an equally important factor for argument quality, as the prospective planning. KG-CFR, according to our initial metric evaluations, reduces semantic looping, by preserving the agent's consistency with the original plan.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Knowledge-Grounded Counterfactual Reasoning (KG-CFR) achieves resilience in multi-agent argumentation via strict architectural decoupling between a private retrieval-augmented planning buffer and a public execution layer. In the authors' custom 1v1v1 DRAU environment, over 270 factorial trajectories with stochastic shocks, the system prevents judge-detected critical post-shock quality degradation (Δ ≤ -0.20) in >95% of perturbed runs while raising average argument quality from 0.694 to 0.822; custom vector metrics for discourse divergence and plan-execution alignment are introduced as supporting evidence, with ablations indicating doctrinal grounding is comparably important to prospective planning.
Significance. If the decoupling result holds under externally validated conditions, the work would provide a concrete architectural principle for preserving process fidelity in long-horizon multi-agent LLM interactions, complementing accuracy-focused debate frameworks. The absence of comparisons to standard benchmarks or metrics, however, confines the demonstrated contribution to the authors' specific setup.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim that decoupling prevents Δ ≤ -0.20 degradation in >95% of runs rests on custom vector metrics for discourse divergence and plan-execution alignment that are defined internally and lack any comparison to established measures (e.g., cosine similarity on embeddings or NLI entailment scores); without such anchors the reported stability may be an artifact of the metric construction itself.
- [DRAU Environment / Results] DRAU Environment and Results: the 1v1v1 Dynamic Resource Allocation under Uncertainty setting is presented as a dedicated testbed for resilience under sustained pressure, yet no mapping to or comparison against existing multi-agent debate benchmarks is supplied, so the generalizability of the 0.694 → 0.822 quality lift and 95% prevention figure cannot be assessed.
- [Results] Results paragraph: numerical outcomes are reported without error bars, confidence intervals, or statistical tests, and without explicit baseline systems or ablation controls that isolate the decoupling component from the retrieval-augmented planning buffer, rendering the attribution of resilience gains to the architectural separation load-bearing but unsupported.
minor comments (2)
- [Abstract] Abstract: the phrase 'completely factorial crisis simulation trajectories' is used without definition of the factors or the factorial design.
- [Abstract / Methods] Notation: the quality metric and the threshold Δ ≤ -0.20 are introduced without an equation or explicit definition of how the judge computes quality.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim that decoupling prevents Δ ≤ -0.20 degradation in >95% of runs rests on custom vector metrics for discourse divergence and plan-execution alignment that are defined internally and lack any comparison to established measures (e.g., cosine similarity on embeddings or NLI entailment scores); without such anchors the reported stability may be an artifact of the metric construction itself.
Authors: We acknowledge the referee's concern regarding the custom metrics. Our discourse divergence and plan-execution alignment metrics are specifically designed to capture aspects of multi-agent interaction stability, such as semantic looping and consistency with the original plan under knowledge grounding, which may not be fully reflected in standard cosine similarity or NLI scores. Nevertheless, to provide external validation, we will add comparisons in the revised Evaluation section, including correlations with cosine similarity on embeddings and NLI entailment, demonstrating that our metrics align directionally with these established measures while offering additional sensitivity to the decoupling effect. revision: yes
-
Referee: [DRAU Environment / Results] DRAU Environment and Results: the 1v1v1 Dynamic Resource Allocation under Uncertainty setting is presented as a dedicated testbed for resilience under sustained pressure, yet no mapping to or comparison against existing multi-agent debate benchmarks is supplied, so the generalizability of the 0.694 → 0.822 quality lift and 95% prevention figure cannot be assessed.
Authors: DRAU is intentionally designed as a distinct environment emphasizing sustained perturbations and process fidelity in argumentation, differing from convergence-focused debate benchmarks. We will revise the manuscript to include a subsection mapping DRAU to related multi-agent debate frameworks, discussing similarities and differences in evaluation criteria, thereby providing context for the generalizability of our findings. revision: partial
-
Referee: [Results] Results paragraph: numerical outcomes are reported without error bars, confidence intervals, or statistical tests, and without explicit baseline systems or ablation controls that isolate the decoupling component from the retrieval-augmented planning buffer, rendering the attribution of resilience gains to the architectural separation load-bearing but unsupported.
Authors: The original manuscript includes ablation studies on the importance of doctrinal grounding versus prospective planning. To address the lack of statistical rigor and explicit baselines, the revised version will incorporate error bars and confidence intervals for all key metrics, apply appropriate statistical tests to the reported improvements, and introduce additional baseline systems (e.g., a coupled planning-execution variant) to more clearly isolate the contribution of the decoupling architecture. revision: yes
Circularity Check
No significant circularity; empirical demonstration is self-contained
full rationale
The paper presents an empirical architecture and evaluation in a dedicated environment rather than a mathematical derivation chain. No equations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. The custom vector metrics are introduced as measurement tools for the experimental results, but the text does not exhibit any self-definitional reduction (e.g., metrics defined such that stability is guaranteed by construction) or any other enumerated circular pattern. The central claim rests on reported experimental outcomes (quality scores, degradation rates) in the DRAU setup, which constitutes independent content rather than a closed loop reducing to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-LLM Debate: Framework, Principals, and Interventions
Estornell, A., and Y . Liu (2024) “Multi-LLM Debate: Framework, Principals, and Interventions.”Adv. Neural Inf. Process. Syst.37: 28938–28964.https://doi.org/10.52202/079017-0911
-
[3]
Scalable AI Safety via Doubly-Efficient Debate
Brown-Cohen, J., G. Irving, and G. Piliouras (2024) “Scalable AI Safety via Doubly-Efficient Debate.”Proc. Int. Conf. Mach. Learn.235: 4585–4602.https://proceedings.mlr.press/v235/brown-cohen24a.html
2024
-
[4]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chan, C.-M., et al. (2023) “ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate.” Proc. EMNLP: 4199–4218
2023
-
[5]
LLM2: Let Large Language Models Harness System 2 Reasoning
Yang, C., C. Shi, S. Li, et al. (2025) “LLM2: Let Large Language Models Harness System 2 Reasoning.”Proc. NAACL HLT: 168–177.https://doi.org/10.18653/v1/2025.naacl-short.15
-
[6]
Simulating Oxford-Style Debates with LLM-Based Multi-Agent Sys- tems
Harbar, Y ., and J. A. Chudziak (2025) “Simulating Oxford-Style Debates with LLM-Based Multi-Agent Sys- tems.”Intell. Inf. and Database Syst. (ACIIDS): 286–300
2025
-
[7]
ID-RAG: Identity Retrieval-Augmented Generation for Long-Horizon Persona Co- herence
Platnick, D., et al. (2025) “ID-RAG: Identity Retrieval-Augmented Generation for Long-Horizon Persona Co- herence.”arXiv preprint arXiv:2509.25299
arXiv 2025
-
[8]
Should We Be Going MAD? A Look at Multi-Agent Debate Strategies for LLMs
Smit, A. P., N. Grinsztajn, P. Duckworth, et al. (2024) “Should We Be Going MAD? A Look at Multi-Agent Debate Strategies for LLMs.”Proc. Int. Conf. Mach. Learn.: 45883–45905.https://proceedings.mlr. press/v235/smit24a.html
2024
-
[9]
Masłowski, J., and J. A. Chudziak (2026) “Heterogeneous Debate Engine: Identity-Grounded Cognitive Archi- tecture for Resilient LLM-Based Ethical Tutoring.”arXiv preprint arXiv:2603.27404.https://arxiv.org/ abs/2603.27404 9
arXiv 2026
-
[10]
Serial Position Effects of Large Language Models
Guo, X., and S. V osoughi (2025) “Serial Position Effects of Large Language Models.”Findings ACL: 927–953. https://doi.org/10.18653/v1/2025.findings-acl.52
-
[11]
The Hidden Cost of Structure: How Constrained Decoding Affects Language Model Performance
Schall, M., and G. de Melo (2025) “The Hidden Cost of Structure: How Constrained Decoding Affects Language Model Performance.”Proc. 15th Int. Conf. Recent Adv. Nat. Lang. Process.: 1074–1084
2025
-
[12]
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Erdogan, L. E., N. Lee, S. Kim, et al. (2025) “Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks.”OpenReview.https://openreview.net/forum?id=ybA4EcMmUZ
2025
-
[13]
IHE val: Evaluating Language Models on Following the Instruction Hierarchy
Zhang, Z., S. Li, Z. Zhang, et al. (2025) “IHEval: Evaluating Language Models on Following the Instruction Hierarchy.”Proc. NAACL HLT: 8374–8398.https://doi.org/10.18653/v1/2025.naacl-long.425
-
[14]
Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following
Zeng, J., Q. He, Q. Ren, et al. (2025) “Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following.”Findings ACL: 12479–12492.https://doi.org/10.18653/v1/2025.findings-acl.646
-
[15]
https://doi.org/10.18653/v1/2025
Levy, S., N. Mazor, L. Shalmon, et al. (2025) “More Documents, Same Length: Isolating the Challenge of Multiple Documents in RAG.”Findings EMNLP: 19539–19547.https://doi.org/10.18653/v1/2025. findings-emnlp.1064
-
[16]
Lost in the middle: How language models use long contexts,
Liu, N. F., K. Lin, J. Hewitt, et al. (2024) “Lost in the Middle: How Language Models Use Long Contexts.” Trans. Assoc. Comput. Linguist.12: 157–173.https://doi.org/10.1162/tacl_a_00638
-
[17]
Oriol, M., Q. Motger, J. Marco, and X. Franch (2025) “Multi-Agent Debate Strategies to Enhance Requirements Engineering with Large Language Models.”2025 IEEE 33rd Int. Requir . Eng. Conf. (RE): 527–534.https: //doi.org/10.1109/RE63999.2025.00063
-
[18]
URLhttps://aclanthology.org/2024.acl-long.747/
Maharana, A., D.-H. Lee, S. Tulyakov, et al. (2024) “Evaluating Very Long-Term Conversational Memory of LLM Agents.”Proc. ACL: 13851–13870.https://doi.org/10.18653/v1/2024.acl-long.747
-
[19]
An LLM Compiler for Parallel Function Calling
Kim, S., S. Moon, R. Tabrizi, et al. (2024) “An LLM Compiler for Parallel Function Calling.”Proc. Int. Conf. Mach. Learn.: 24370–24391.https://proceedings.mlr.press/v235/kim24y.html
2024
-
[20]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, N., F. Cassano, A. Gopinath, et al. (2023) “Reflexion: Language Agents with Verbal Reinforcement Learning.”Adv. Neural Inf. Process. Syst.36: 8634–8652
2023
-
[21]
Positional Biases Shift as Inputs Approach Context Window Limits
Veseli, B., J. Chibane, M. Toneva, and A. Koller (2025) “Positional Biases Shift as Inputs Approach Context Window Limits.”OpenReview.https://openreview.net/forum?id=vlUk8z8LaM
2025
-
[22]
Do RAG Systems Really Suffer From Positional Bias?
Cuconasu, F., S. Filice, G. Horowitz, et al. (2025) “Do RAG Systems Really Suffer From Positional Bias?.” Proc. EMNLP: 28022–28036.https://doi.org/10.18653/v1/2025.emnlp-main.1422
-
[23]
Li, Z., C. Li, M. Zhang, et al. (2024) “Retrieval Augmented Generation or Long-Context LLMs? A Compre- hensive Study and Hybrid Approach.”Proc. EMNLP Ind. Track: 881–893.https://doi.org/10.18653/v1/ 2024.emnlp-industry.66
-
[24]
Can We Instruct LLMs to Compensate for Position Bias?
Zhang, M., Z. Meng, and N. Collier (2024) “Can We Instruct LLMs to Compensate for Position Bias?.”Findings EMNLP: 12545–12556.https://doi.org/10.18653/v1/2024.findings-emnlp.732
-
[25]
On Verifiable Legal Reasoning: A Multi-Agent Framework with Formalized Knowledge Representations
Sadowski, A., and J. A. Chudziak (2025) “On Verifiable Legal Reasoning: A Multi-Agent Framework with Formalized Knowledge Representations.”Proc. CIKM, ACM: 2535–2545.https://doi.org/10.1145/ 3746252.3761057
arXiv 2025
-
[26]
Towards Cognitive Synergy in LLM-Based Multi-Agent Systems: In- tegrating Theory of Mind and Critical Evaluation
Kostka, A., and J. A. Chudziak (2025) “Towards Cognitive Synergy in LLM-Based Multi-Agent Systems: In- tegrating Theory of Mind and Critical Evaluation.”Proceedings of the 47th Annual Meeting of the Cognitive Science Society (CogSci 2025). 10
2025
-
[27]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Debenedetti, E., J. Zhang, M. Balunovic, et al. (2024) “AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents.”OpenReview.https://openreview.net/forum? id=m1YYAQjO3w
2024
-
[28]
Computational Argumentation Quality Assessment in Natural Language
Wachsmuth, H., N. Naderi, Y . Hou, et al. (2017) “Computational Argumentation Quality Assessment in Natural Language.”Proc. 15th Conf. EACL: 176–187
2017
-
[29]
Webis Argument Quality Corpus 2020
Gienapp, L., J. Kiesel, M. Hagen, and B. Stein (2020) “Webis Argument Quality Corpus 2020.”Zenodo.https: //doi.org/10.5281/zenodo.3780049
-
[30]
Gemini 2.5 Flash-Lite Model Card
Google DeepMind (2025) “Gemini 2.5 Flash-Lite Model Card.”Google.https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-2-5-Flash-Lite-Model-Card.pdf
2025
-
[31]
Schuirmann, D. J. (1987) “A Comparison of the Two One-Sided Tests Procedure and the Power Approach for Assessing the Equivalence of Average Bioavailability.”J. Pharmacokinet. Biopharm.15: 657–680.https: //doi.org/10.1007/BF01068419
-
[32]
Efficient Pairwise Annotation of Argument Quality
Gienapp, L., J. Kiesel, M. Hagen, and B. Stein (2020) “Efficient Pairwise Annotation of Argument Quality.” Proc. 58th Annu. Meet. ACL: 5772–5781
2020
-
[33]
A Large-Scale Dataset for Argument Quality Ranking: Construction and Analysis
Gretz, S., R. Friedman, E. Cohen-Karlik, et al. (2020) “A Large-Scale Dataset for Argument Quality Ranking: Construction and Analysis.”Proc. AAAI Conf. Artif. Intell.34: 7805–7813
2020
-
[34]
Controlling the False Discovery Rate: A Practical and Powerful Ap- proach to Multiple Testing
Benjamini, Y ., and Y . Hochberg (1995) “Controlling the False Discovery Rate: A Practical and Powerful Ap- proach to Multiple Testing.”J. R. Stat. Soc. Ser . B57: 289–300. 11
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.