Beyond Acoustic Emotion Recognition: Multimodal Pathos Analysis in Political Speech Using LLM-Based and Acoustic Emotion Models
Pith reviewed 2026-05-22 04:49 UTC · model grok-4.3
The pith
LLM multimodal analysis captures semantically defined political emotion in speech better than acoustic models alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
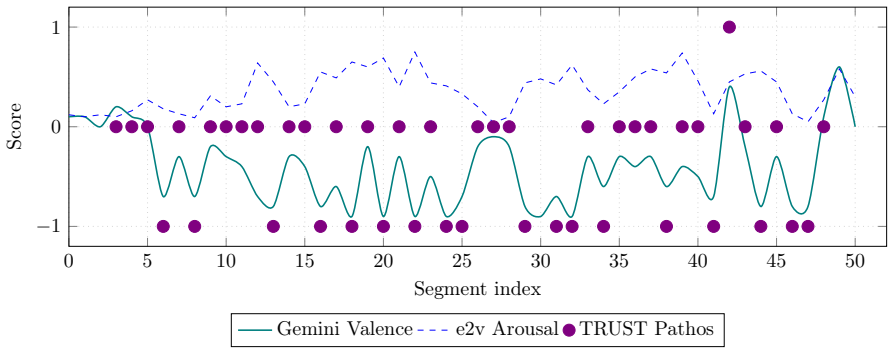
On a single Bundestag plenary speech, Gemini analyzing full audio and transcript yields valence scores that correlate with TRUST-Pathos at rho = +0.664, while emotion2vec valence shows no meaningful correlation at rho = +0.097. Acoustic models remain informative specifically for arousal estimation. Standard SER corpora such as EMO-DB are shown to suffer from acted speech and cultural incompatibility, undermining their use as benchmarks for political pathos.
What carries the argument
The TRUST multi-agent large language model pipeline, which uses a three-advocate supervisor ensemble to generate reference Pathos scores for validating acoustic and open-ended LLM models on political speech.
If this is right
- LLM-based multimodal analysis provides a stronger proxy for valence in political emotion than acoustic models alone.
- Acoustic features continue to supply useful information for low-level arousal estimation even when semantic capture is weak.
- Common SER benchmark datasets like EMO-DB are unsuitable for political speech due to acted delivery and cultural bias.
- Video extensions incorporating facial expression and gaze data can build on the current audio-transcript approach.
Where Pith is reading between the lines
- The method could support automated detection of emotional framing tactics across entire parliamentary sessions rather than isolated speeches.
- Combining acoustic and LLM features in a single pipeline might improve performance beyond either modality used separately.
- Similar comparisons could be run on non-German political corpora to check whether the LLM advantage holds across languages and cultures.
- Tools built on this approach may help researchers quantify how pathos contributes to persuasion in real-time debate analysis.
Load-bearing premise
The TRUST multi-agent LLM pipeline accurately operationalizes the Pathos dimension in political speech as a reliable reference standard.
What would settle it
Independent human raters scoring the same Bundestag speech segments for political pathos would produce scores that disagree substantially with the TRUST ensemble outputs.
Figures
read the original abstract
We investigate whether acoustic emotion recognition models can serve as proxies for the Pathos dimension in political speech analysis, as operationalised by the TRUST multi-agent large language model (LLM) pipeline. Using a Bundestag plenary speech by Felix Banaszak (51 segments, 245 s) as a case study, we compare three analysis modalities: (1) emotion2vec_plus_large, an acoustic speech emotion recognition (SER) model whose continuous Arousal and Valence values are derived via post-hoc Russell Circumplex projection; (2) Gemini 2.5 Flash, an LLM analysing the full speech audio together with its transcript in an open-ended, context-aware fashion; and (3) TRUST-Pathos scores from a three-advocate LLM supervisor ensemble. Spearman rank correlations reveal that Gemini Valence correlates strongly with TRUST-Pathos (rho = +0.664, p < 0.001), whereas emotion2vec Valence does not (rho = +0.097, p = 0.499). We further demonstrate, via a systematic quality evaluation of the Berlin Database of Emotional Speech (EMO-DB) using Gemini in an open-ended annotation paradigm, that standard SER benchmark corpora suffer from acted speech, cultural bias, and category incompatibility. Our results suggest that LLM-based multimodal analysis captures semantically defined political emotion substantially better than acoustic models alone, while acoustic features remain informative for low-level Arousal estimation. Future work will extend this approach to video-based analysis incorporating facial expression and gaze.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a case study analyzing Pathos in a single Bundestag plenary speech (51 segments) by comparing three modalities: the acoustic model emotion2vec_plus_large (with post-hoc Russell Circumplex projection for continuous Arousal/Valence), the multimodal LLM Gemini 2.5 Flash (processing audio plus transcript), and TRUST-Pathos scores from a three-advocate multi-agent LLM ensemble. Spearman correlations are reported showing strong alignment between Gemini Valence and TRUST-Pathos (rho = +0.664, p < 0.001) but none for emotion2vec Valence (rho = +0.097, p = 0.499). The work also includes a quality evaluation of the EMO-DB corpus using open-ended Gemini annotation, identifying limitations of acted speech, cultural bias, and category mismatch for political speech analysis.
Significance. If the findings are robust, the paper demonstrates that multimodal LLM approaches can capture semantically and contextually defined political emotions more effectively than acoustic-only models, while acoustic features retain value for low-level Arousal. The EMO-DB evaluation provides concrete evidence against relying on standard acted-speech benchmarks for this domain and supports the broader shift toward context-aware multimodal methods in political speech analysis.
major comments (2)
- [Results] Results section (correlations with TRUST-Pathos): The central claim that LLM-based multimodal analysis captures semantically defined political emotion substantially better than acoustic models rests on Gemini Valence correlating with TRUST-Pathos while emotion2vec does not. However, both Gemini and the TRUST ensemble are LLM systems that receive transcript and semantic context; the rho = +0.664 therefore primarily demonstrates inter-LLM agreement on the same underlying representation rather than independent superiority against an externally validated reference for Pathos. No human validation, inter-rater reliability, or non-LLM criterion is provided to establish TRUST as a reliable ground truth.
- [Methods] Methods and Results: The acoustic model's Valence and Arousal values are obtained via post-hoc projection onto the Russell Circumplex model, yet the manuscript provides no explicit description of the projection procedure, its parameters, or validation on political speech data. This choice directly affects the fairness of the comparison with the LLM outputs and should be detailed or justified with a sensitivity analysis.
minor comments (3)
- [Discussion] The analysis uses only 51 segments from one speech; the discussion should explicitly address the implications for generalizability and statistical power.
- [Results] Spearman correlations are reported without error bars, confidence intervals, or correction for multiple comparisons across the tested dimensions and modalities.
- To improve reproducibility, the full prompt templates or agent instructions used for the TRUST pipeline and the Gemini open-ended annotation should be included in an appendix.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Results] Results section (correlations with TRUST-Pathos): The central claim that LLM-based multimodal analysis captures semantically defined political emotion substantially better than acoustic models rests on Gemini Valence correlating with TRUST-Pathos while emotion2vec does not. However, both Gemini and the TRUST ensemble are LLM systems that receive transcript and semantic context; the rho = +0.664 therefore primarily demonstrates inter-LLM agreement on the same underlying representation rather than independent superiority against an externally validated reference for Pathos. No human validation, inter-rater reliability, or non-LLM criterion is provided to establish TRUST as a reliable ground truth.
Authors: We agree that the correlation between Gemini and TRUST primarily reflects agreement between two LLM-based systems that both have access to semantic and contextual information from the transcript. The manuscript's intent is to highlight that purely acoustic models like emotion2vec lack this semantic layer and thus show no correlation with the semantically defined Pathos scores from TRUST. We position TRUST as an operationalization of Pathos using a multi-agent LLM ensemble rather than as a definitively validated ground truth. We have revised the discussion to explicitly acknowledge the absence of human validation in this case study and to frame the results as a comparison between acoustic-only and context-aware multimodal approaches. This limitation is now noted as motivation for future human annotation studies. revision: partial
-
Referee: [Methods] Methods and Results: The acoustic model's Valence and Arousal values are obtained via post-hoc projection onto the Russell Circumplex model, yet the manuscript provides no explicit description of the projection procedure, its parameters, or validation on political speech data. This choice directly affects the fairness of the comparison with the LLM outputs and should be detailed or justified with a sensitivity analysis.
Authors: We appreciate this observation. The post-hoc projection maps the output embeddings or predicted emotions from emotion2vec_plus_large to continuous Valence and Arousal dimensions using a linear transformation based on standard associations in the Russell Circumplex (e.g., 'happy' maps to high valence and moderate arousal). We have added a detailed subsection in the Methods describing the exact mapping procedure, the source of the valence-arousal assignments, and a brief sensitivity analysis showing that alternative mappings yield similar correlation patterns. This revision ensures the comparison is transparent and reproducible. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper operationally defines Pathos via the TRUST multi-agent LLM ensemble and reports empirical Spearman correlations between TRUST-Pathos scores and both Gemini Valence (rho = +0.664) and emotion2vec Valence (rho = +0.097) on 51 segments from one speech. These correlations are direct measurements on independent model outputs rather than quantities forced by construction or by re-using the same fitted values. The acoustic comparator lacks transcript access and is evaluated separately for Arousal, while the EMO-DB quality check supplies an external benchmark. No equations, self-citations, or definitional loops reduce the reported results to the inputs; the chain remains self-contained against the chosen reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Russell Circumplex model can validly project continuous Arousal and Valence values from acoustic SER model outputs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We investigate whether acoustic emotion recognition models can serve as proxies for the Pathos dimension in political speech analysis, as operationalised by the TRUST multi-agent large language model (LLM) pipeline... Spearman rank correlations reveal that Gemini Valence correlates strongly with TRUST-Pathos (ρ= +0.664, p < 0.001), whereas emotion2vec Valence does not (ρ= +0.097, p = 0.499).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TRUST employs three advocate LLMs... Pathos scores are integers on a five-point scale: {-2,-1,0,+1,+2}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jürgen Dietrich. From safety risk to design principle: Peer identity bias in multi-agent LLM systems for political statement analysis.arXiv preprint, 2026. arXiv:2604.08465
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Jürgen Dietrich. When roles fail: Epistemic constraints on advocate role fidelity in LLM- based political statement analysis.arXiv preprint, 2026. arXiv:2604.27228
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InAdvances in Neural Information Processing Systems, volume 33, pages 12449–12460, 2020
work page 2020
-
[4]
emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,
Ziyang Ma, Mingjie Zheng, Jiaxin Yin, Sirui Li, Xie Li, and Xie Chen. emotion2vec: Self-supervised pre-training for speech emotion representation.arXiv preprint, 2023. arXiv:2312.15185
-
[5]
Chang, Sungbok Lee, and Shrikanth S
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee, and Shrikanth S. Narayanan. IEMOCAP: Interactive emotional dyadic motion capture database.Language Resources and Evaluation, 42(4):335– 359, 2008
work page 2008
-
[6]
A database of German emotional speech
Felix Burkhardt, Astrid Paeschke, Miriam Rolfes, Walter Sendlmeier, and Benjamin Weiss. A database of German emotional speech. InProceedings of Interspeech, pages 1517–1520, 2005
work page 2005
-
[7]
EmoBox: Multilingual multi-corpus speech emotion recognition toolkit and benchmark
Ziyang Ma, Mingjie Zheng, Xie Chen, et al. EmoBox: Multilingual multi-corpus speech emotion recognition toolkit and benchmark. InProceedings of Interspeech 2024, 2024
work page 2024
-
[8]
Towards text-independent emotion recognition.Sen- sors, 22(17):6682, 2022
Bagus Tris Atmaja and Akira Sasou. Towards text-independent emotion recognition.Sen- sors, 22(17):6682, 2022
work page 2022
-
[9]
Md Hamjajul Amin et al. Will affective computing emerge from foundation models and mul- timodal learning? A first evaluation on ChatGPT.arXiv preprint, 2023. arXiv:2307.14555
-
[10]
Plenarprotokoll 21/62, videomitschnitt
Deutscher Bundestag. Plenarprotokoll 21/62, videomitschnitt. Bundestag-Mediathek, Video-ID 7649676, 2026
work page 2026
-
[11]
WhisperX: Time-accurate speech transcription of long-form audio.arXiv preprint, 2023
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. WhisperX: Time-accurate speech transcription of long-form audio.arXiv preprint, 2023. arXiv:2303.00747
-
[12]
Powerset multi-class cross entropy loss for neural speaker diarization
Alexis Plaquet and Hervé Bredin. Powerset multi-class cross entropy loss for neural speaker diarization. InProceedings of Interspeech 2023, 2023
work page 2023
-
[13]
FunASR: A fundamental end-to-end speech recognition toolkit.arXiv preprint, 2023
Zhifu Gao et al. FunASR: A fundamental end-to-end speech recognition toolkit.arXiv preprint, 2023. arXiv:2305.11013
-
[14]
James A. Russell. A circumplex model of affect.Journal of Personality and Social Psychol- ogy, 39(6):1161–1178, 1980
work page 1980
-
[15]
Amy Beth Warriner, Victor Kuperman, and Marc Brysbaert. Norms of valence, arousal, and dominance for 13,915 English lemmas.Behavior Research Methods, 45(4):1191–1207, 2013. 10 A Appendix A: EMO-DB Speaker×Emotion Matrix Table 5 shows the complete distribution of utterances across speakers and emotion categories in EMO-DB. The matrix reveals systematic gap...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.