Structured Adaptive Tensor Prediction for Streaming Data
Pith reviewed 2026-06-27 16:51 UTC · model grok-4.3
The pith
Tensor-on-Matrix regression tracks streaming matrix data with lower error and fixed-time recovery under sparsity and low-rank structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
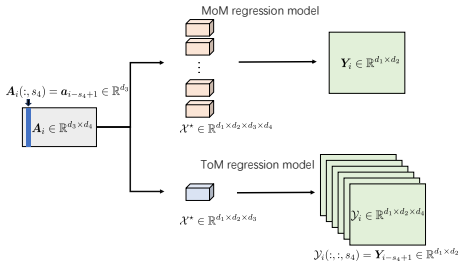
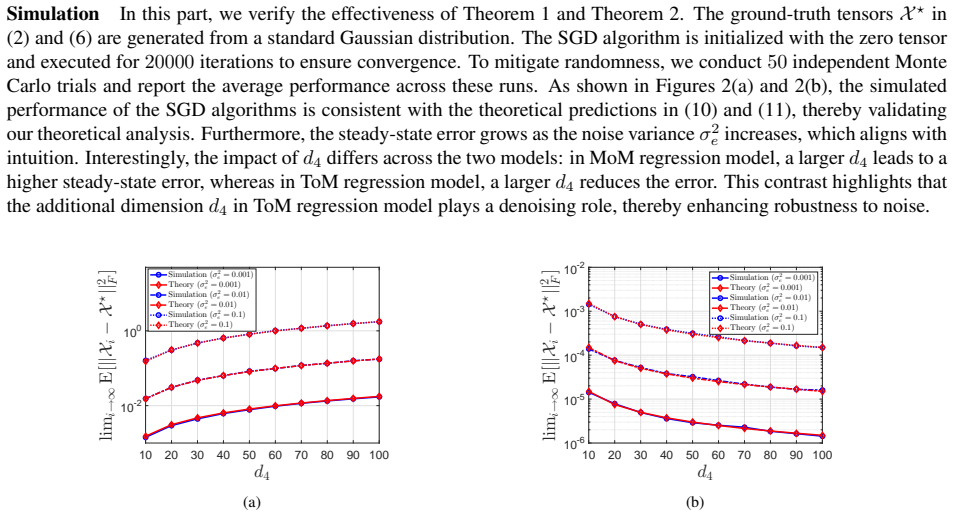
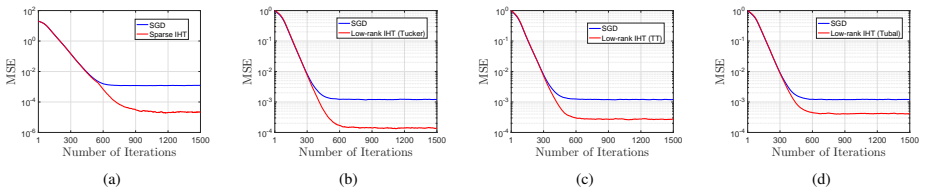
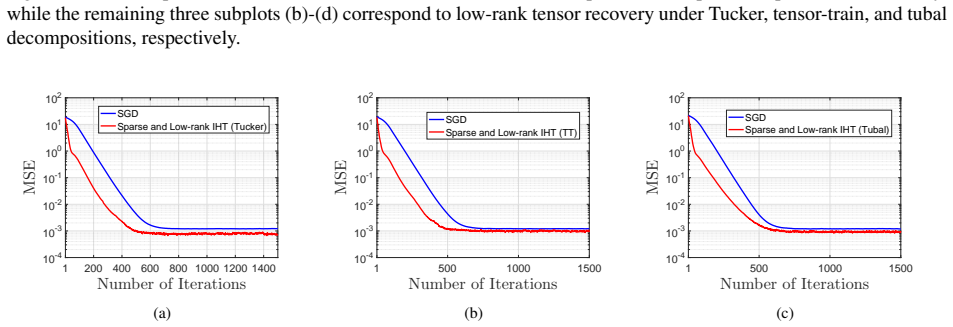
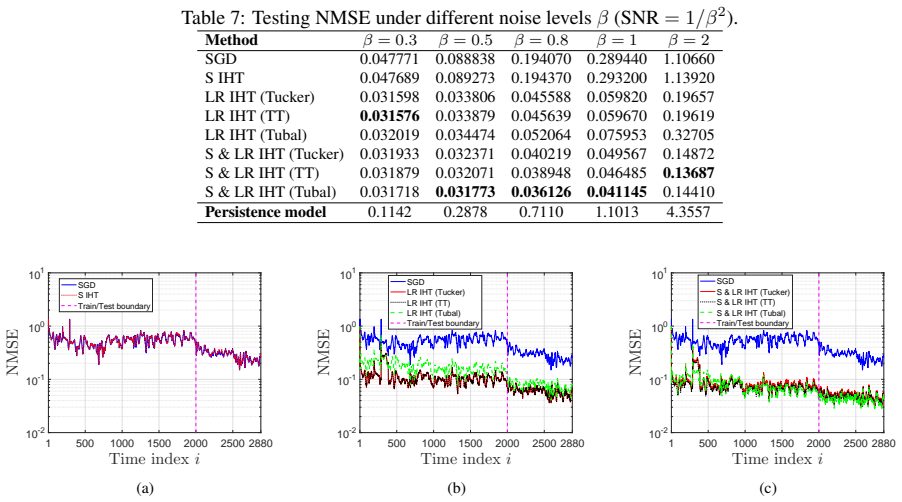
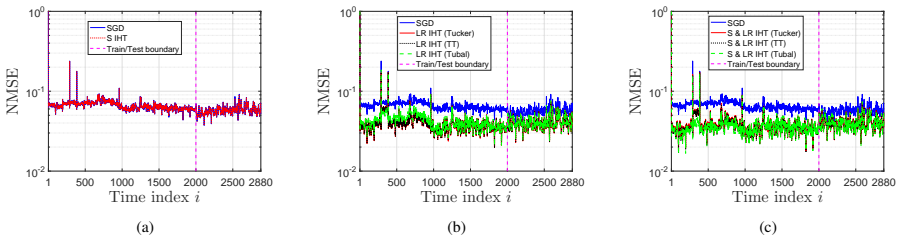
We develop an adaptive tensor regression framework that includes Matrix-on-Matrix and Tensor-on-Matrix formulations for streaming matrix-valued prediction. Stochastic gradient descent algorithms enable online learning. Stacking multiple responses across time into higher-order tensors improves performance; the Tensor-on-Matrix model achieves lower steady-state error and stronger denoising capability than Matrix-on-Matrix. We characterize the tracking behavior of stochastic gradient descent under time-varying dynamics and establish fixed-time recovery guarantees for Tensor-on-Matrix under general low-dimensional structures, including sparsity, low-rankness, and their joint sparse-low-rank mode
What carries the argument
The Tensor-on-Matrix formulation that stacks multiple matrix responses across time into a higher-order tensor to exploit temporal structure during regression.
If this is right
- Stacking responses across time into higher-order tensors improves performance over direct matrix modeling.
- The Tensor-on-Matrix model attains lower steady-state error than the Matrix-on-Matrix model.
- The Tensor-on-Matrix model provides stronger denoising capability than the Matrix-on-Matrix model.
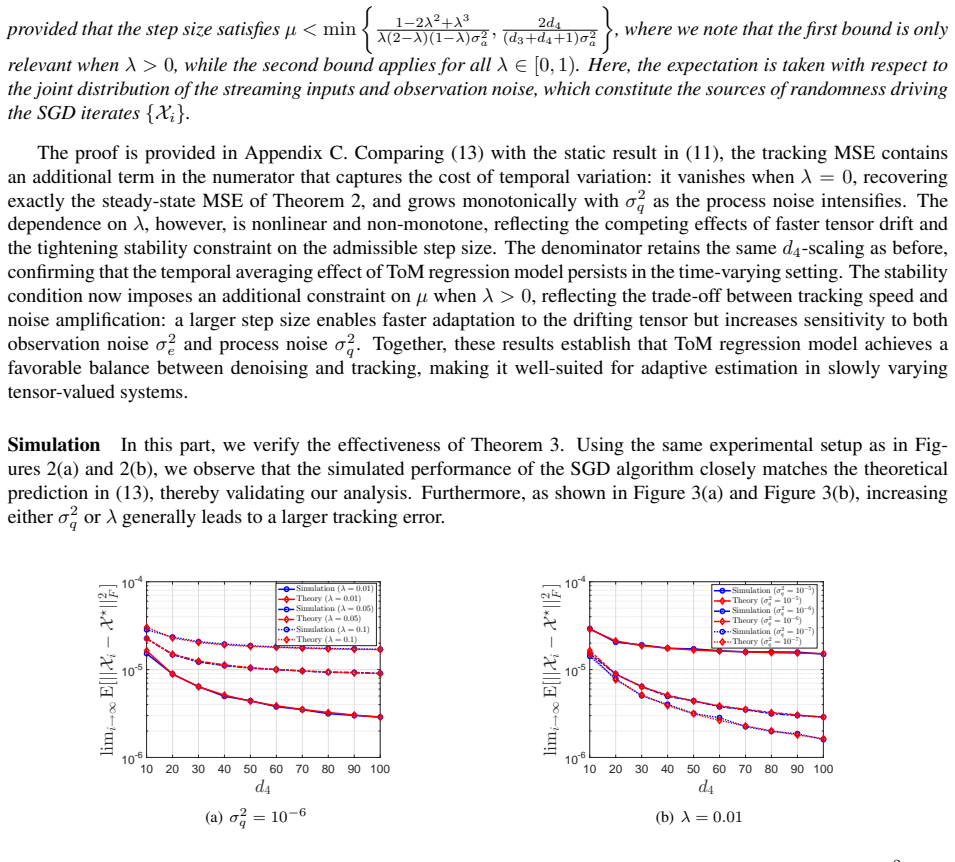
- Stochastic gradient descent tracks the time-varying dynamics of the data.
- Fixed-time recovery guarantees hold under sparsity, low-rankness, and joint sparse-low-rank models.
Where Pith is reading between the lines
- The same stacking idea might apply directly to higher-order tensor outputs without first reducing to matrices.
- The tracking analysis could inform adaptive methods for other non-stationary structured data where low-dimensional assumptions hold only approximately.
- Deployment on geophysics datasets would test whether the reported denoising gains persist when noise statistics deviate from the analysis assumptions.
Load-bearing premise
The streaming matrix data must admit low-dimensional structures such as sparsity or low-rankness, and the time-varying dynamics must permit the stochastic gradient descent tracking analysis.
What would settle it
An experiment on matrix time series known to lack sparsity and low-rank structure where the Tensor-on-Matrix recovery error fails to converge to the claimed rate within the fixed-time bound would falsify the guarantees.
Figures
read the original abstract
Matrix-valued time series arise in a wide range of applications, such as spatio-temporal data from medical imaging and geophysics. Existing methods are mainly designed for static settings and lack adaptability to streaming and time-varying environments. Adaptive filtering techniques have also been largely limited to data with scalar or vector values, leaving adaptive forecasting for matrix-valued time series inadequately understood. To bridge these gaps, we develop an adaptive tensor regression framework that includes Matrix-on-Matrix (MoM) and Tensor-on-Matrix (ToM) formulations for streaming matrix-valued prediction. The two formulations differ in whether to directly model matrix-valued outputs or to exploit temporal structure via higher-order tensor representations. For the proposed tensor regression framework, we develop stochastic gradient descent (SGD) algorithms for online learning. We show that stacking multiple responses across time into higher-order tensors improves performance; in particular, the ToM achieves lower steady-state error and stronger denoising capability than MoM, motivating our focus on the ToM model. We further characterize the tracking behavior of SGD under time-varying dynamics. From a statistical perspective, we establish fixed-time recovery guarantees for ToM under general low-dimensional structures, including sparsity, low-rankness, and their joint sparselow-rank models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an adaptive tensor regression framework with Matrix-on-Matrix (MoM) and Tensor-on-Matrix (ToM) formulations for streaming matrix-valued prediction. It introduces SGD algorithms for online learning, shows that ToM outperforms MoM in steady-state error and denoising by stacking responses into higher-order tensors, characterizes SGD tracking under time-varying dynamics, and establishes fixed-time recovery guarantees for ToM under sparsity, low-rankness, and joint sparse-low-rank structures.
Significance. If the fixed-time recovery guarantees can be made rigorous with explicit controls on parameter variation, the work would advance online tensor methods for applications such as medical imaging and geophysics by bridging adaptive filtering with structured tensor regression; the MoM/ToM comparison and SGD tracking analysis are concrete contributions that could be built upon.
major comments (2)
- [Abstract] Abstract (statistical perspective paragraph): the fixed-time recovery guarantees for ToM under sparsity/low-rankness are stated without an explicit modulus of continuity or bound on the rate of change of the low-dimensional factors (or on the noise model); this assumption is load-bearing for both the SGD tracking characterization and the recovery claim, as the skeptic note correctly isolates.
- [Statistical recovery section] The derivation of the recovery guarantees (statistical recovery section) supplies no explicit error bounds, dataset details, or step-by-step steps from the abstract-level claim; without these the central statistical result cannot be verified for gaps or post-hoc choices.
minor comments (1)
- [Abstract] Abstract: 'joint sparselow-rank models' is missing a hyphen or space.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments below and will make the indicated revisions to improve clarity and verifiability of the fixed-time recovery claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (statistical perspective paragraph): the fixed-time recovery guarantees for ToM under sparsity/low-rankness are stated without an explicit modulus of continuity or bound on the rate of change of the low-dimensional factors (or on the noise model); this assumption is load-bearing for both the SGD tracking characterization and the recovery claim, as the skeptic note correctly isolates.
Authors: We agree that the abstract would benefit from an explicit reference to the rate-of-change assumption. The analysis relies on a standard bounded-variation condition (modulus of continuity) on the low-dimensional factors together with a noise model that is stated in the main text; this condition is necessary for the SGD tracking result to hold. In the revision we will add one sentence to the abstract that names this assumption and points to the precise statement in the statistical recovery section. revision: yes
-
Referee: [Statistical recovery section] The derivation of the recovery guarantees (statistical recovery section) supplies no explicit error bounds, dataset details, or step-by-step steps from the abstract-level claim; without these the central statistical result cannot be verified for gaps or post-hoc choices.
Authors: The section derives the fixed-time bounds under the stated structural assumptions, but we acknowledge that the presentation could be more self-contained. We will expand the section to display the explicit error bounds obtained from the analysis, include a short step-by-step outline of the main proof steps, and clarify that the result is purely theoretical (hence no dataset details appear). These additions will make the derivation easier to verify without altering the claims. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The abstract and claims present a new adaptive tensor regression framework (MoM/ToM) with SGD algorithms, performance comparisons, tracking characterization, and fixed-time recovery guarantees under explicit low-dimensional structure assumptions (sparsity, low-rankness). No equations, predictions, or central results are shown to reduce by construction to fitted parameters, self-definitions, or self-citation chains from the same paper. The statistical guarantees rest on stated premises about data structure rather than tautological re-derivation of inputs. This matches the default expectation of non-circularity for most papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matrix completion methods for the total electron content video reconstruction.The Annals of Applied Statistics, 16(3):1333–1358, 2022
Hu Sun, Zhijun Hua, Jiaen Ren, Shasha Zou, Yuekai Sun, and Yang Chen. Matrix completion methods for the total electron content video reconstruction.The Annals of Applied Statistics, 16(3):1333–1358, 2022
2022
-
[2]
Complete global total electron content map dataset based on a video imputation algorithm vista.Scientific Data, 10(1):236, 2023
Hu Sun, Yang Chen, Shasha Zou, Jiaen Ren, Yurui Chang, Zihan Wang, and Anthea Coster. Complete global total electron content map dataset based on a video imputation algorithm vista.Scientific Data, 10(1):236, 2023
2023
-
[3]
A machine learning-based framework for high resolution mapping of pm2
Hossein Bagheri. A machine learning-based framework for high resolution mapping of pm2. 5 in tehran, iran, using maiac aod data.Advances in space Research, 69(9):3333–3349, 2022
2022
-
[4]
Tensor decompositions for hyperspectral data processing in remote sensing: A comprehensive review.IEEE Geoscience and Remote Sensing Magazine, 11(1):26–72, 2023
Minghua Wang, Danfeng Hong, Zhu Han, Jiaxin Li, Jing Yao, Lianru Gao, Bing Zhang, and Jocelyn Chanussot. Tensor decompositions for hyperspectral data processing in remote sensing: A comprehensive review.IEEE Geoscience and Remote Sensing Magazine, 11(1):26–72, 2023
2023
-
[5]
Survey of encoding and decoding of visual stimulus via fmri: an image analysis perspective.Brain imaging and behavior, 8(1):7–23, 2014
Mo Chen, Junwei Han, Xintao Hu, Xi Jiang, Lei Guo, and Tianming Liu. Survey of encoding and decoding of visual stimulus via fmri: an image analysis perspective.Brain imaging and behavior, 8(1):7–23, 2014
2014
-
[6]
Dynamic origin–destination matrix prediction with line graph neural networks and kalman filter.Transportation Research Record, 2674(8):491–503, 2020
Xi Xiong, Kaan Ozbay, Li Jin, and Chen Feng. Dynamic origin–destination matrix prediction with line graph neural networks and kalman filter.Transportation Research Record, 2674(8):491–503, 2020
2020
-
[7]
Vector autoregressions.Journal of Economic perspectives, 15(4):101–115, 2001
James H Stock and Mark W Watson. Vector autoregressions.Journal of Economic perspectives, 15(4):101–115, 2001. 29
2001
-
[8]
Regularized estimation in high- dimensional vector auto-regressive models using spatio-temporal information.Statistica Sinica, 33:1271–1294, 2023
Zhenzhong Wang, Abolfazl Safikhani, Zhengyuan Zhu, and David S Matteson. Regularized estimation in high- dimensional vector auto-regressive models using spatio-temporal information.Statistica Sinica, 33:1271–1294, 2023
2023
-
[9]
Autoregressive models for matrix-valued time series.Journal of Econo- metrics, 222(1):539–560, 2021
Rong Chen, Han Xiao, and Dan Yang. Autoregressive models for matrix-valued time series.Journal of Econo- metrics, 222(1):539–560, 2021
2021
-
[10]
Hu Sun, Zuofeng Shang, and Yang Chen. Matrix autoregressive model with vector time series covariates for spatio-temporal data.arXiv preprint arXiv:2305.15671, 2023
-
[11]
Multi-linear tensor autoregressive models.arXiv preprint arXiv:2110.00928, 2021
Zebang Li and Han Xiao. Multi-linear tensor autoregressive models.arXiv preprint arXiv:2110.00928, 2021
-
[12]
High-dimensional low-rank tensor autoregressive time series modeling
Di Wang, Yao Zheng, and Guodong Li. High-dimensional low-rank tensor autoregressive time series modeling. Journal of Econometrics, 238(1):105544, 2024
2024
-
[13]
Store: sparse tensor response regression and neuroimaging analysis.Journal of Machine Learning Research, 18(135):1–37, 2017
Will Wei Sun and Lexin Li. Store: sparse tensor response regression and neuroimaging analysis.Journal of Machine Learning Research, 18(135):1–37, 2017
2017
-
[14]
Tensor-on-tensor regression.Journal of Computational and Graphical Statistics, 27(3):638–647, 2018
Eric F Lock. Tensor-on-tensor regression.Journal of Computational and Graphical Statistics, 27(3):638–647, 2018
2018
-
[15]
Convex regularization for high-dimensional multiresponse tensor regression.The Annals of Statistics, 47(3):1554–1584, 2019
Garvesh Raskutti, Ming Yuan, and Han Chen. Convex regularization for high-dimensional multiresponse tensor regression.The Annals of Statistics, 47(3):1554–1584, 2019
2019
-
[16]
Reduced-rank tensor-on-tensor regression and tensor-variate analysis of variance.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2282–2296, 2022
Carlos Llosa-Vite and Ranjan Maitra. Reduced-rank tensor-on-tensor regression and tensor-variate analysis of variance.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2282–2296, 2022
2022
-
[17]
Tensor-on-tensor regression: Riemannian optimization, over-parameterization, statistical-computational gap and their interplay.The Annals of Statistics, 52(6):2583–2612, 2024
Yuetian Luo and Anru R Zhang. Tensor-on-tensor regression: Riemannian optimization, over-parameterization, statistical-computational gap and their interplay.The Annals of Statistics, 52(6):2583–2612, 2024
2024
-
[18]
Zhen Qin and Zhihui Zhu. Computational and statistical guarantees for tensor-on-tensor regression with tensor train decomposition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(11):10577–10587, 2025
2025
-
[19]
A survey on concept drift adaptation.ACM computing surveys (CSUR), 46(4):1–37, 2014
Jo ˜ao Gama, Indr˙e ˇZliobait˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. A survey on concept drift adaptation.ACM computing surveys (CSUR), 46(4):1–37, 2014
2014
-
[20]
An overview on concept drift learning.IEEE access, 7:1532–1547, 2018
Adriana Sayuri Iwashita and Joao Paulo Papa. An overview on concept drift learning.IEEE access, 7:1532–1547, 2018
2018
-
[21]
Survey of distance measures for quantifying concept drift and shift in numeric data.Knowledge and Information Systems, pages 1–25, 2018
Igor Goldenberg and Geoffrey I Webb. Survey of distance measures for quantifying concept drift and shift in numeric data.Knowledge and Information Systems, pages 1–25, 2018
2018
-
[22]
Pearson Education India, 2008
Simon S Haykin.Adaptive filter theory. Pearson Education India, 2008
2008
-
[23]
John Wiley & Sons, 2011
Ali H Sayed.Adaptive filters. John Wiley & Sons, 2011
2011
-
[24]
Adaptive switching circuits
ME Hoff and B Widrow. Adaptive switching circuits. In1960 IRE WESCON Convention Recor, pages 96–104, 1960
1960
-
[25]
Kazuhiko Ozeki and Tetsuo Umeda. An adaptive filtering algorithm using an orthogonal projection to an affine subspace and its properties.Electronics and Communications in Japan (Part I: Communications), 67(5):19–27, 1984
1984
-
[26]
Some theorems in least squares.Biometrika, 37(1/2):149–157, 1950
Ronald L Plackett. Some theorems in least squares.Biometrika, 37(1/2):149–157, 1950
1950
-
[27]
A new approach to linear filtering and prediction problems
Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960
1960
-
[28]
Proportionate normalized least-mean-squares adaptation in echo cancelers.IEEE Transac- tions on speech and audio processing, 8(5):508–518, 2002
Donald L Duttweiler. Proportionate normalized least-mean-squares adaptation in echo cancelers.IEEE Transac- tions on speech and audio processing, 8(5):508–518, 2002. 30
2002
-
[29]
An improved pnlms algorithm
Jacob Benesty and Steven L Gay. An improved pnlms algorithm. In2002 IEEE international conference on acoustics, speech, and signal processing, volume 2, pages II–1881. IEEE, 2002
2002
-
[30]
Sparse lms for system identification
Yilun Chen, Yuantao Gu, and Alfred O Hero. Sparse lms for system identification. In2009 IEEE international conference on acoustics, speech and signal processing, pages 3125–3128. IEEE, 2009
2009
-
[31]
Yuantao Gu, Jian Jin, and Shunliang Mei.l 0 norm constraint lms algorithm for sparse system identification.IEEE Signal Processing Letters, 16(9):774–777, 2009
2009
-
[32]
Improving the performance of the pnlms algorithm usingl1 norm regularization.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(7):1280–1290, 2016
Rajib Lochan Das and Mrityunjoy Chakraborty. Improving the performance of the pnlms algorithm usingl1 norm regularization.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(7):1280–1290, 2016
2016
-
[33]
Rls algorithm with convex regularization.IEEE Signal Processing Letters, 18(8):470–473, 2011
Ender M Eksioglu and A Korhan Tanc. Rls algorithm with convex regularization.IEEE Signal Processing Letters, 18(8):470–473, 2011
2011
-
[34]
A proportionate recursive least squares algorithm and its performance analysis
Zhen Qin, Jun Tao, and Yili Xia. A proportionate recursive least squares algorithm and its performance analysis. IEEE Transactions on Circuits and Systems II: Express Briefs, 68(1):506–510, 2020
2020
-
[35]
Proportionate rls with l1 norm regularization: Performance analysis and fast implementation.Digital Signal Processing, 122:103366, 2022
Zhen Qin, Jun Tao, Yili Xia, and Le Yang. Proportionate rls with l1 norm regularization: Performance analysis and fast implementation.Digital Signal Processing, 122:103366, 2022
2022
-
[36]
Variable step-size convex regularized prls algorithms.Signal Pro- cessing, 214:109251, 2024
Yu Wang, Zhen Qin, Jun Tao, and Yili Xia. Variable step-size convex regularized prls algorithms.Signal Pro- cessing, 214:109251, 2024
2024
-
[37]
J. A. Chambers, O. Tanrikulu, and A. G. Constantinides. Least mean mixed-norm adaptive filtering.Electronics Letters, 30(19):1574–1575, 1994
1994
-
[38]
P. Petrus. Robust huber adaptive filter.IEEE Transactions on Signal Processing, 47(4):1129–1133, 1999
1999
-
[39]
N. R. Yousef and A. H. Sayed. Steady-state and tracking analyses of the sign algorithm without the explicit use of the independence assumption.IEEE Signal Processing Letters, 7(11):307–309, 2000
2000
-
[40]
T. Shao, Y . R. Zheng, and J. Benesty. An affine projection sign algorithm robust against impulsive interferences. IEEE Signal Processing Letters, 17(4):327–330, 2010
2010
-
[41]
Generalized correntropy for robust adaptive filtering.IEEE Transactions on Signal Processing, 64(13):3376–3387, 2016
Badong Chen, Lei Xing, Haiquan Zhao, Nanning Zheng, Jos ´e C Prı, et al. Generalized correntropy for robust adaptive filtering.IEEE Transactions on Signal Processing, 64(13):3376–3387, 2016
2016
-
[42]
Constrained maximum correntropy adaptive filtering.Signal Processing, 140:116–126, 2017
Siyuan Peng, Badong Chen, Lei Sun, Wee Ser, and Zhiping Lin. Constrained maximum correntropy adaptive filtering.Signal Processing, 140:116–126, 2017
2017
-
[43]
Maximum versoria criterion-based robust adaptive filtering algori- thm.IEEE Transactions on Circuits and Systems II: Express Briefs, 64(10):1252–1256, 2017
Fuyi Huang, Jiashu Zhang, and Sheng Zhang. Maximum versoria criterion-based robust adaptive filtering algori- thm.IEEE Transactions on Circuits and Systems II: Express Briefs, 64(10):1252–1256, 2017
2017
-
[44]
Maximum correntropy criterion with variable center
Badong Chen, Xin Wang, Yingsong Li, and Jose C Principe. Maximum correntropy criterion with variable center. IEEE Signal Processing Letters, 26(8):1212–1216, 2019
2019
-
[45]
Proportionate recursive maximum correntropy criterion adaptive filtering algorithms and their performance analysis.Digital Signal Processing, 139:104073, 2023
Zhen Qin, Jun Tao, Le Yang, and Ming Jiang. Proportionate recursive maximum correntropy criterion adaptive filtering algorithms and their performance analysis.Digital Signal Processing, 139:104073, 2023
2023
-
[46]
Mandic and Vanessa Su Lee Goh.Complex Valued Nonlinear Adaptive Filters: Noncircularity, Widely Linear and Neural Models
Danilo P. Mandic and Vanessa Su Lee Goh.Complex Valued Nonlinear Adaptive Filters: Noncircularity, Widely Linear and Neural Models. John Wiley & Sons, 2009
2009
-
[47]
Yili Xia, Clive Cheong Took, and Danilo P. Mandic. An augmented affine projection algorithm for the filtering of noncircular complex signals.Signal Processing, 90(6):1788–1799, 2010
2010
-
[48]
Principe, and Simon Haykin.Kernel Adaptive Filtering: A Comprehensive Introduction
Weifeng Liu, Jose C. Principe, and Simon Haykin.Kernel Adaptive Filtering: A Comprehensive Introduction. John Wiley & Sons, 2011
2011
-
[49]
Yili Xia and Danilo P. Mandic. Widely linear adaptive frequency estimation of unbalanced three-phase power systems.IEEE Transactions on Instrumentation and Measurement, 61(1):74–83, 2011. 31
2011
-
[50]
Adaptive strategies for parameter estimation of box–jenkins systems.IET Signal Processing, 8(9):968–980, 2014
Muhammad Asif Zahoor Raja and Naveed Ishtiaq Chaudhary. Adaptive strategies for parameter estimation of box–jenkins systems.IET Signal Processing, 8(9):968–980, 2014
2014
-
[51]
Zhen Qin, Jun Tao, Xiaoyan Wang, Xinwei Luo, and Xiao Han. Direct adaptive equalization based on fast sparse recursive least squares algorithms for multiple-input multiple-output underwater acoustic communications.The Journal of the Acoustical Society of America, 145(4):EL277–EL283, 2019
2019
-
[52]
Zhen Qin, Jun Tao, and Xiao Han. Sparse direct adaptive equalization based on proportionate recursive least squares algorithm for multiple-input multiple-output underwater acoustic communications.The Journal of the Acoustical Society of America, 148(4):2280–2287, 2020
2020
-
[53]
Adaptive sparse channel estima- tion for ris-assisted mmwave massive mimo systems.IEEE Transactions on Vehicular Technology, 2025
Shuying Shao, Tiejun Lv, Siying Du, Jie Zeng, Fangqing Tan, and Zhipeng Lin. Adaptive sparse channel estima- tion for ris-assisted mmwave massive mimo systems.IEEE Transactions on Vehicular Technology, 2025
2025
-
[54]
Naylor, Jingjing Cui, and Mike Brookes
Patrick A. Naylor, Jingjing Cui, and Mike Brookes. Adaptive algorithms for sparse echo cancellation.Signal Processing, 86(6):1182–1192, 2006
2006
-
[55]
Proportionate adaptive algorithms for network echo cancellation.IEEE Transactions on Signal Processing, 54(5):1794–1803, 2006
Hongyang Deng and Milos Doroslovacki. Proportionate adaptive algorithms for network echo cancellation.IEEE Transactions on Signal Processing, 54(5):1794–1803, 2006
2006
-
[56]
Loizou, Chia-Hsiang Lee, and Wei-Jen Chen
Jwu-Sheng Hu, Philipos C. Loizou, Chia-Hsiang Lee, and Wei-Jen Chen. A robust adaptive speech enhancement system for vehicular applications.IEEE Transactions on Consumer Electronics, 52(3):1069–1077, 2006
2006
-
[57]
Loizou, and Yang Liang
Wen Jin, Yao Hu, Philipos C. Loizou, and Yang Liang. Speech enhancement using harmonic emphasis and adaptive comb filtering.IEEE Transactions on Audio, Speech, and Language Processing, 18(2):356–368, 2009
2009
-
[58]
Yili Xia and Danilo P. Mandic. Widely linear adaptive frequency estimation of unbalanced three-phase power systems.IEEE Transactions on Instrumentation and Measurement, 61(1):74–83, 2011
2011
-
[59]
Douglas, and Danilo P
Yili Xia, Scott C. Douglas, and Danilo P. Mandic. Adaptive frequency estimation in smart grid applications: Exploiting noncircularity and widely linear adaptive estimators.IEEE Signal Processing Magazine, 29(5):44–54, 2012
2012
-
[60]
A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters.IEEE Transactions on Signal Processing, 47(10):2677–2684, 2002
Osamu Hoshuyama, Akihiko Sugiyama, and Akihiro Hirano. A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters.IEEE Transactions on Signal Processing, 47(10):2677–2684, 2002
2002
-
[61]
Wolfgang Herbordt, Walter Kellermann, and Richard Ainsworth. Multichannel bin-wise robust frequency-domain adaptive filtering and its application to adaptive beamforming.IEEE Transactions on Audio, Speech, and Lan- guage Processing, 15(4):1340–1351, 2007
2007
-
[62]
Adaptive signal processing.Englewood Cliffs, NJ: Prentice Hall, 1985
Widrow Bernard and D Stearns Samuel. Adaptive signal processing.Englewood Cliffs, NJ: Prentice Hall, 1985
1985
-
[63]
Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006
2006
-
[64]
Robust uncertainty principles: Exact signal reconstruc- tion from highly incomplete frequency information.IEEE Transactions on information theory, 52(2):489–509, 2006
Emmanuel J Cand `es, Justin Romberg, and Terence Tao. Robust uncertainty principles: Exact signal reconstruc- tion from highly incomplete frequency information.IEEE Transactions on information theory, 52(2):489–509, 2006
2006
-
[65]
An introduction to compressive sampling.IEEE signal processing magazine, 25(2):21–30, 2008
Emmanuel J Cand `es and Michael B Wakin. An introduction to compressive sampling.IEEE signal processing magazine, 25(2):21–30, 2008
2008
-
[66]
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization.SIAM review, 52(3):471–501, 2010
Benjamin Recht, Maryam Fazel, and Pablo A Parrilo. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization.SIAM review, 52(3):471–501, 2010
2010
-
[67]
Low rank tensor recovery via iterative hard threshold- ing.Linear Algebra and its Applications, 523:220–262, 2017
Holger Rauhut, Reinhold Schneider, and ˇZeljka Stojanac. Low rank tensor recovery via iterative hard threshold- ing.Linear Algebra and its Applications, 523:220–262, 2017
2017
-
[68]
Quantum state tomography for matrix product density operators.IEEE Transactions on Information Theory, 70(7):5030–5056, 2024
Zhen Qin, Casey Jameson, Zhexuan Gong, Michael B Wakin, and Zhihui Zhu. Quantum state tomography for matrix product density operators.IEEE Transactions on Information Theory, 70(7):5030–5056, 2024. 32
2024
-
[69]
Robust low-rank tensor train recovery.IEEE Transactions on Signal Processing, 73:2022–2038, 2025
Zhen Qin and Zhihui Zhu. Robust low-rank tensor train recovery.IEEE Transactions on Signal Processing, 73:2022–2038, 2025
2022
-
[70]
Simultaneously structured models with application to sparse and low-rank matrices.IEEE Transactions on Information Theory, 61(5):2886– 2908, 2015
Samet Oymak, Amin Jalali, Maryam Fazel, Yonina C Eldar, and Babak Hassibi. Simultaneously structured models with application to sparse and low-rank matrices.IEEE Transactions on Information Theory, 61(5):2886– 2908, 2015
2015
-
[71]
Generalized low-rank plus sparse tensor estimation by fast riemannian optimization.Journal of the American Statistical Association, 118(544):2588–2604, 2023
Jian-Feng Cai, Jingyang Li, and Dong Xia. Generalized low-rank plus sparse tensor estimation by fast riemannian optimization.Journal of the American Statistical Association, 118(544):2588–2604, 2023
2023
-
[72]
Fourier low-rank and sparse tensor for efficient tensor completion
Jingyang Li, Jiuqian Shang, and Yang Chen. Fourier low-rank and sparse tensor for efficient tensor completion. arXiv preprint arXiv:2505.11261, 2025
-
[73]
Enhancing sparsity by reweightedℓ 1 minimization
Emmanuel J Candes, Michael B Wakin, and Stephen P Boyd. Enhancing sparsity by reweightedℓ 1 minimization. Journal of Fourier analysis and applications, 14(5):877–905, 2008
2008
-
[74]
IEEE Signal Processing Letters, 16(9):774–777, 2009
Yuantao Gu, Jian Jin, and Shunliang Mei.l {0}norm constraint lms algorithm for sparse system identification. IEEE Signal Processing Letters, 16(9):774–777, 2009
2009
-
[75]
Nonconvex low-rank tensor completion from noisy data.Advances in neural information processing systems, 32, 2019
Changxiao Cai, Gen Li, H Vincent Poor, and Yuxin Chen. Nonconvex low-rank tensor completion from noisy data.Advances in neural information processing systems, 32, 2019
2019
-
[76]
On polynomial time methods for exact low-rank tensor completion.Foundations of Computational Mathematics, 19(6):1265–1313, 2019
Dong Xia and Ming Yuan. On polynomial time methods for exact low-rank tensor completion.Foundations of Computational Mathematics, 19(6):1265–1313, 2019
2019
-
[77]
Sparse tensor additive regression.Journal of machine learning research, 22(64):1–43, 2021
Botao Hao, Boxiang Wang, Pengyuan Wang, Jingfei Zhang, Jian Yang, and Will Wei Sun. Sparse tensor additive regression.Journal of machine learning research, 22(64):1–43, 2021
2021
-
[78]
Scaling and scalability: Provable nonconvex low-rank tensor estimation from incomplete measurements.Journal of Machine Learning Research, 23(163):1–77, 2022
Tian Tong, Cong Ma, Ashley Prater-Bennette, Erin Tripp, and Yuejie Chi. Scaling and scalability: Provable nonconvex low-rank tensor estimation from incomplete measurements.Journal of Machine Learning Research, 23(163):1–77, 2022
2022
-
[79]
An optimal statistical and computational framework for generalized tensor estimation.The Annals of Statistics, 50(1):1–29, 2022
Rungang Han, Rebecca Willett, and Anru R Zhang. An optimal statistical and computational framework for generalized tensor estimation.The Annals of Statistics, 50(1):1–29, 2022
2022
-
[80]
Guaranteed nonconvex factorization approach for tensor train recovery.Journal of Machine Learning Research, 25(383):1–48, 2024
Zhen Qin, Michael B Wakin, and Zhihui Zhu. Guaranteed nonconvex factorization approach for tensor train recovery.Journal of Machine Learning Research, 25(383):1–48, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.