Function-Vector Heads Are Two Populations: Writers and Cancellers in In-Context Learning
Pith reviewed 2026-06-29 21:30 UTC · model grok-4.3
The pith
Function-vector heads split into writers that raise the correct logit and cancellers that lower it under sign-preserving analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
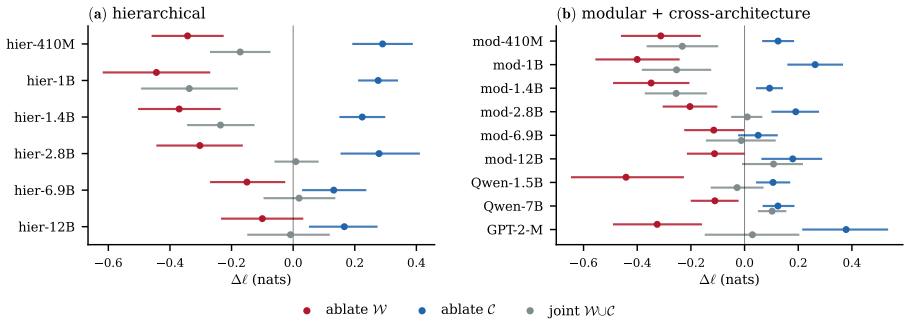
Under a sign-preserving criterion the FV population splits into two opposing groups: writers push the rule-correct logit up, cancellers push it down, and ablating both together moves the readout less than the sum of the two. The split is causal and reproducible. It holds in all but two of the fifteen (model, task) cells we test, spanning three architectures and six Pythia scales, and a sign-shuffle null rejects the single-class account in all but one of the six main cells.
What carries the argument
Sign-preserving refined direct logit attribution, validated head-by-head with path patching, that separates positive and negative causal contributions to the rule-correct logit.
If this is right
- Magnitude-only ranking of heads surfaces whichever group dominates locally and misses the opposing population.
- Any function vector or ablation built from magnitude ranking alone silently averages a promoting and a suppressing mechanism.
- Zero-ablating cancellers alone recovers +0.13 to +0.29 nats on the correct label and shifts accuracy by +2 to +7 percentage points.
- Cancellers produce larger causal effects than magnitude-matched non-FV control heads.
- The split is invisible to standard magnitude-based identification of function-vector heads.
Where Pith is reading between the lines
- Separate identification of cancellers could enable more targeted interventions that improve in-context performance without removing helpful heads.
- The opposing populations suggest that in-context rule learning relies on a balance between promotion and active suppression rather than pure addition of evidence.
- Similar sign splits may exist in other classes of attention heads identified only by magnitude in mechanistic interpretability work.
Load-bearing premise
The refined direct logit attribution with path-patching validation correctly isolates causal sign contributions without introducing selection artifacts that would create an artificial split.
What would settle it
A sign-shuffle null test that fails to reject the single-class account across multiple (model, task) cells, or path-patching results that contradict the sign assignments from the attribution method.
Figures


read the original abstract
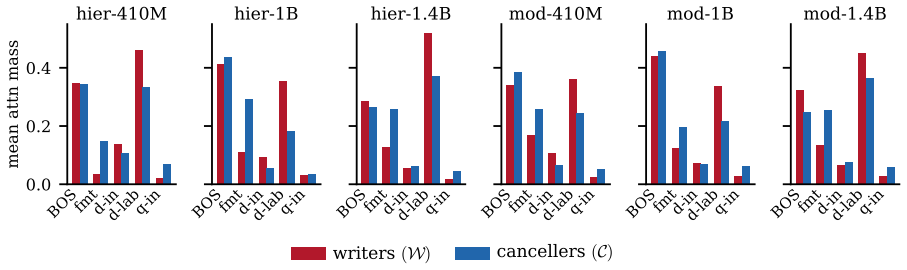
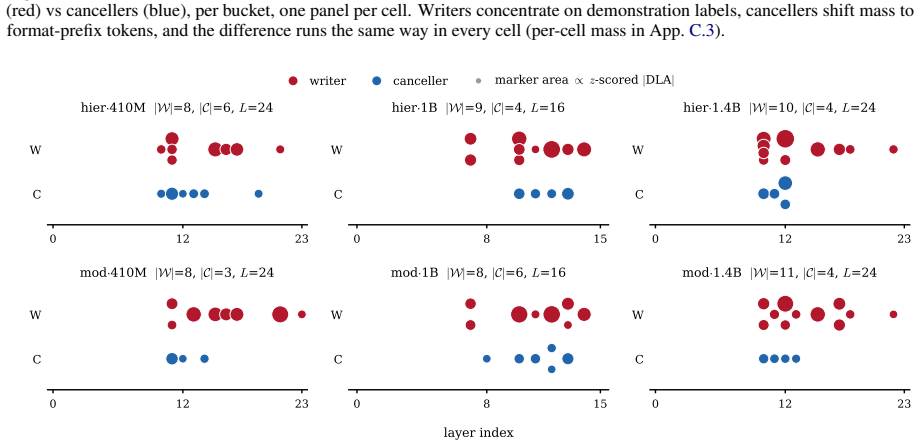
Function-vector (FV) heads are identified by the magnitude of their causal contribution to in-context rule tasks, and the resulting top set is treated as a single functional class. We show this hides a sign structure. Under a sign-preserving criterion (refined direct logit attribution, validated head by head with path patching) the FV population splits into two opposing groups: writers push the rule-correct logit up, cancellers push it down, and ablating both together moves the readout less than the sum of the two. The split is causal and reproducible. It holds in all but two of the fifteen (model, task) cells we test, spanning three architectures and six Pythia scales, and a sign-shuffle null rejects the single-class account in all but one of the six main cells. It is also invisible to magnitude-only ranking, which surfaces whichever group locally dominates and misses the other, so any function vector or ablation built that way silently averages a promoting and a suppressing mechanism. Cancellers are not attention sinks, induction heads, or copy-suppression heads, and their causal effect is larger than that of magnitude-matched non-FV controls. Zero-ablating them recovers $+0.13$ to $+0.29$ nats on the correct label in every main cell, and shifts accuracy by $+2$ to $+7$ pp in the same direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that function-vector (FV) heads, previously treated as a single class based on magnitude of causal contribution to in-context rule tasks, actually split into two opposing populations under a sign-preserving criterion: writers that increase the rule-correct logit and cancellers that decrease it. Using refined direct logit attribution validated head-by-head with path patching, joint ablation of both groups shows sub-additive effects on the readout compared to the sum of individual ablations. The split is reported as causal and reproducible across 13/15 (model, task) cells spanning three architectures and six Pythia scales, with a sign-shuffle null test rejecting the single-class account in 5/6 main cells. Cancellers are distinguished from attention sinks or induction heads, show larger effects than magnitude-matched non-FV controls, and zero-ablating them yields +0.13 to +0.29 nats and +2 to +7 pp accuracy gains.
Significance. If the result holds, the finding refines mechanistic understanding of in-context learning by demonstrating that magnitude-based FV identification averages promoting and suppressing mechanisms, which any downstream function vector or ablation would silently combine. Strengths include the empirical scope (held-out tasks, multiple scales and architectures, reproducible split in 13/15 cells) and the use of a sign-shuffle null test to support the two-population account over a single class. The concrete effect sizes and the observation that the split is invisible to magnitude-only ranking provide falsifiable, actionable distinctions for future interpretability work.
major comments (3)
- [Results describing the sign-preserving criterion and null test] The central claim that the writer/canceller split is genuine (rather than an artifact of magnitude pre-selection, the logit-difference functional, or the post-hoc sign criterion) requires a control applying the identical sign-assignment pipeline to magnitude-matched non-FV heads or to sign-shuffled versions of the FV heads before patching. No such control is reported, yet the sub-additivity of joint ablation and the null-test rejection are load-bearing for distinguishing the two-population model from selection artifacts.
- [Path-patching validation and effect-size reporting] The manuscript reports consistent results across 15 cells and rejection of the null in 5/6 main cells but provides no quantitative details on path-patching validation strength (e.g., effect sizes or success rates per head), error bars on the reported nats/accuracy shifts, or exact exclusion criteria for heads. This is load-bearing for the reliability of the sign assignments that define the split.
- [Reporting of the 15 (model, task) cells] While the split holds in 13/15 cells, the per-cell breakdown (including which two cells fail and the exact quantitative metrics per cell) is not detailed enough to evaluate whether the two failures are systematic or whether the effect sizes are uniformly above noise; this weakens the cross-architecture reproducibility claim.
minor comments (2)
- [Abstract and results summary] Clarify the distinction between the 15 cells and the 6 main cells (e.g., which tasks or models define the main set) so readers can interpret the null-test rejection rate.
- [Methods] The term 'refined direct logit attribution' is introduced without an explicit equation or pointer to its precise definition; add a methods equation for the sign criterion to make the labeling procedure fully reproducible.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below with clarifications based on the reported analyses and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Results describing the sign-preserving criterion and null test] The central claim that the writer/canceller split is genuine (rather than an artifact of magnitude pre-selection, the logit-difference functional, or the post-hoc sign criterion) requires a control applying the identical sign-assignment pipeline to magnitude-matched non-FV heads or to sign-shuffled versions of the FV heads before patching. No such control is reported, yet the sub-additivity of joint ablation and the null-test rejection are load-bearing for distinguishing the two-population model from selection artifacts.
Authors: The manuscript reports a sign-shuffle null test that applies the sign-assignment pipeline to sign-shuffled versions of the FV heads before patching, rejecting the single-class account in 5/6 main cells. We further show that cancellers exhibit larger causal effects than magnitude-matched non-FV controls. While these elements address the core concern, we will add an explicit application of the full sign-assignment pipeline to non-FV heads in the revision for completeness. revision: partial
-
Referee: [Path-patching validation and effect-size reporting] The manuscript reports consistent results across 15 cells and rejection of the null in 5/6 main cells but provides no quantitative details on path-patching validation strength (e.g., effect sizes or success rates per head), error bars on the reported nats/accuracy shifts, or exact exclusion criteria for heads. This is load-bearing for the reliability of the sign assignments that define the split.
Authors: We agree that quantitative details on path-patching validation would improve reliability assessment. In the revised manuscript we will report per-head effect sizes and success rates from path patching, add error bars to the nats and accuracy shifts, and state the exact exclusion criteria for heads. revision: yes
-
Referee: [Reporting of the 15 (model, task) cells] While the split holds in 13/15 cells, the per-cell breakdown (including which two cells fail and the exact quantitative metrics per cell) is not detailed enough to evaluate whether the two failures are systematic or whether the effect sizes are uniformly above noise; this weakens the cross-architecture reproducibility claim.
Authors: We will expand the manuscript or supplementary materials with a full per-cell breakdown table, explicitly identifying the two cells where the split does not hold and providing the quantitative metrics for all 15 cells to permit evaluation of reproducibility and effect sizes relative to noise. revision: yes
Circularity Check
No circularity: empirical split measured on held-out tasks
full rationale
The manuscript identifies FV heads via magnitude of causal contribution, then applies a sign-preserving criterion (refined DLA + head-by-head path patching) to split them into writers and cancellers on held-out in-context tasks. All reported results are direct measurements across 15 (model, task) cells, with sign-shuffle null tests; no equations, fitted parameters, or self-citations reduce the observed sub-additivity or accuracy shifts to inputs by construction. The derivation chain consists of independent empirical steps against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , eprint=
2023
-
[2]
Workshop on Attributing Model Behavior at Scale (NeurIPS) , year=
Copy Suppression: Comprehensively Understanding an Attention Head , author=. Workshop on Attributing Model Behavior at Scale (NeurIPS) , year=
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[4]
Transformer Circuits Thread , year=
In-context Learning and Induction Heads , author=. Transformer Circuits Thread , year=
-
[5]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2022
-
[6]
International Conference on Learning Representations (ICLR) , year=
Function Vectors in Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
In-Context Learning Creates Task Vectors , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
2023
-
[8]
How does
Hanna, Michael and Liu, Ollie and Variengien, Alexandre , booktitle=. How does. 2023 , eprint=
2023
-
[9]
International Conference on Learning Representations (ICLR) , year=
Progress Measures for Grokking via Mechanistic Interpretability , author=. International Conference on Learning Representations (ICLR) , year=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
Localizing Model Behavior with Path Patching
Localizing Model Behavior with Path Patching , author=. arXiv preprint arXiv:2304.05969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
BlackBoxNLP Workshop at EMNLP , year=
Attribution Patching Outperforms Automated Circuit Discovery , author=. BlackBoxNLP Workshop at EMNLP , year=
-
[13]
arXiv preprint arXiv:2312.10091 , year=
Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models , author=. arXiv preprint arXiv:2312.10091 , year=
-
[14]
International Conference on Machine Learning (ICML) , year=
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author=. International Conference on Machine Learning (ICML) , year=
-
[15]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[17]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in. 2022 , eprint=
2022
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Extracting Latent Steering Vectors from Pretrained Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
2022
-
[20]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[21]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.