Unified Safe In-context Image Generation in Multimodal Diffusion Transformers via Restricting Unsafe Information Flows
Pith reviewed 2026-06-27 22:56 UTC · model grok-4.3
The pith
Restricting harmful flows over localized patches in early multimodal attention prevents unsafe DiT image outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
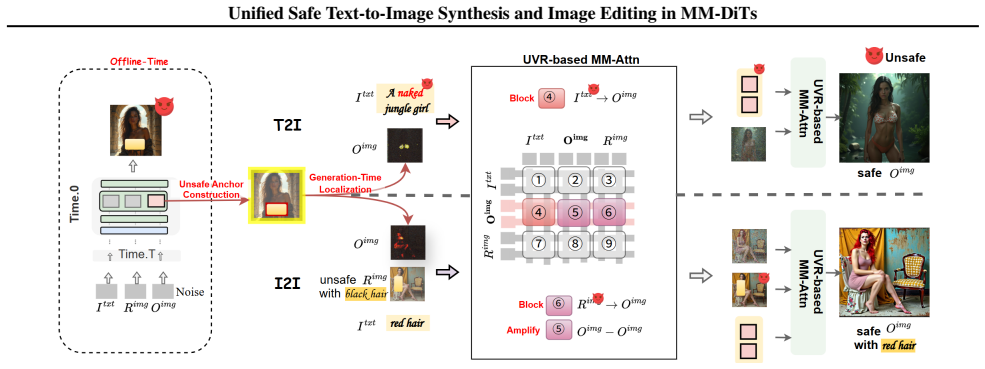
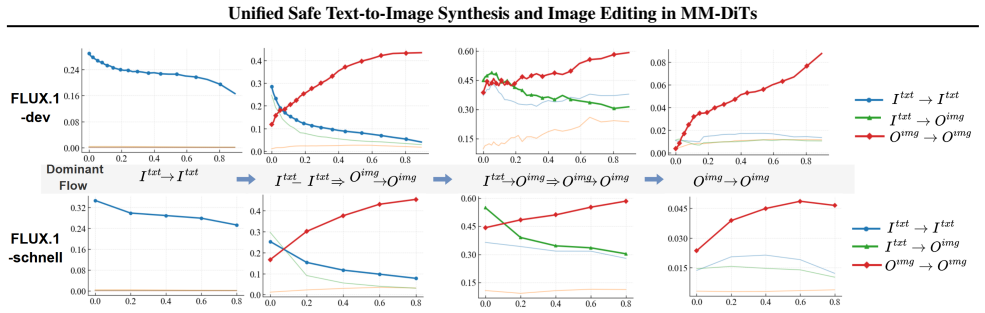
The central claim on the paper's own terms is that analysis of MM-Attn information flow reveals a task-independent start-up stage in which unsafe semantics rapidly emerge and localize in output patches, followed by task-specific amplification; explicit restriction of harmful flows over those patches via targeted attention modulation then mitigates unsafe generation in both synthesis and editing while preserving visual quality.
What carries the argument
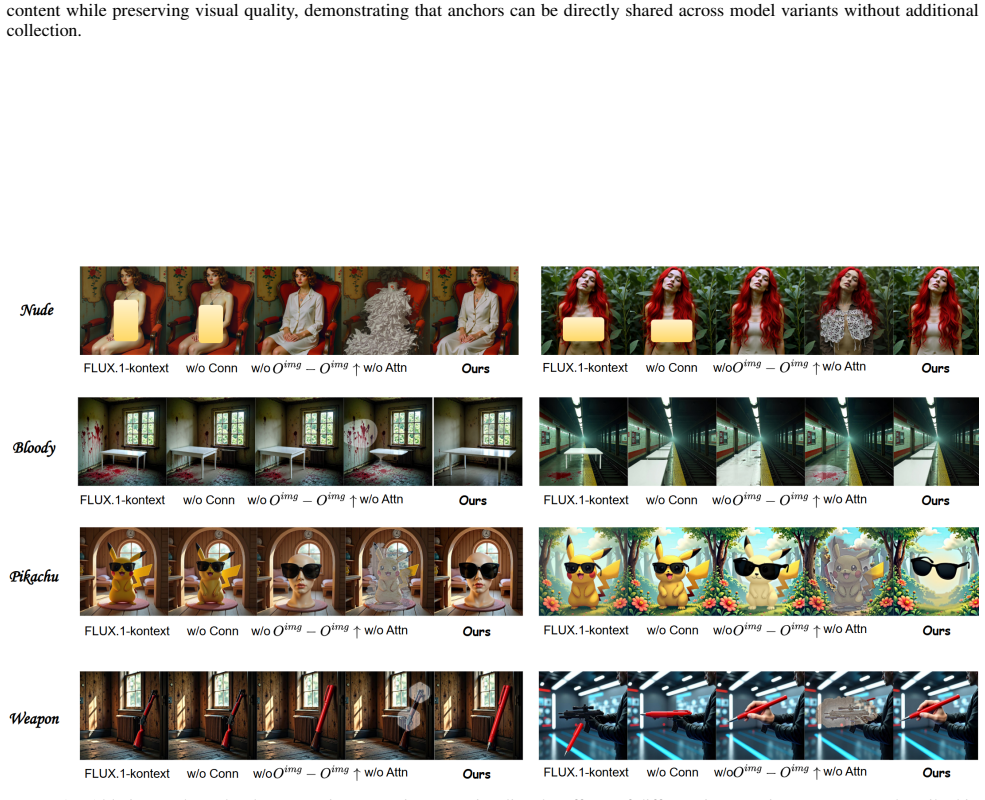
Unified Visual Safety Regulator (UVR), which localizes unsafe output patches in the MM-Attn start-up stage and restricts harmful information flow through targeted attention modulation.
If this is right
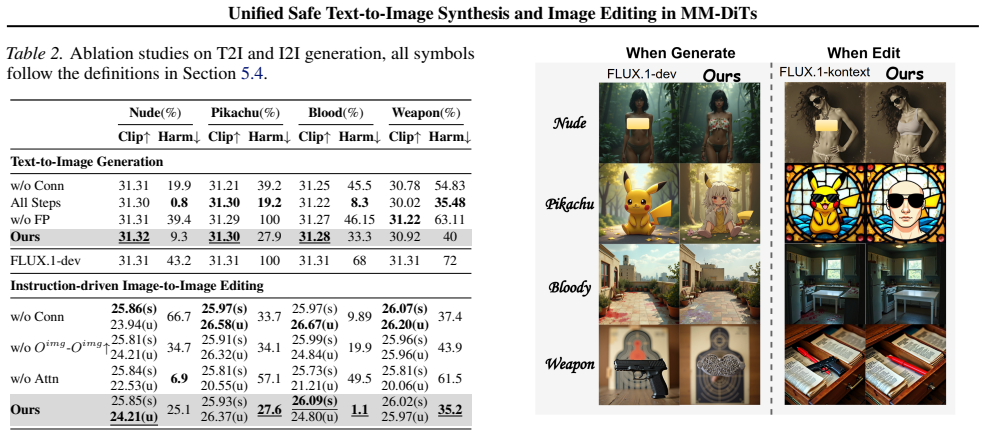
- 91% erase rate for unsafe concepts in image synthesis tasks.
- 77% erase rate for unsafe concepts in image editing tasks.
- Minimal degradation in visual quality and fidelity across tested concepts.
- Unified mitigation that applies to both text-to-image and image-to-image tasks without separate mechanisms.
- Training-free operation that avoids retraining the underlying DiT model.
Where Pith is reading between the lines
- The same start-up-stage localization might appear in other attention-based generative models and could be tested directly on them.
- Patch-level restriction opens a route to finer semantic control, such as removing only selected concepts while keeping others.
- Deployment pipelines could combine this early restriction with later filtering for layered defense.
- The attention-flow analysis might guide interpretability studies of how semantics propagate in multimodal transformers.
Load-bearing premise
Unsafe semantics emerge in a task-independent start-up stage and can be accurately localized in output patches so that restricting flow there reduces unsafe generation without substantial unintended effects on benign content.
What would settle it
An experiment in which the identified start-up-stage patches are restricted yet unsafe concepts still appear in generated images at rates comparable to the unmodulated baseline, or in which image fidelity metrics drop substantially.
Figures










read the original abstract
Diffusion transformers (DiTs) equipped with multimodal attention (MM-Attn) have become a dominant paradigm for image generation. However, preventing the generation of harmful content remains a critical challenge, particularly in image-to-image (I2I) editing tasks. Existing safety mechanisms are primarily designed for text-to-image (T2I) synthesis or U-Net-based architectures, which limits their effectiveness for unified safety mitigation in DiT-based frameworks. To bridge this gap, we propose Unified Visual Safety Regulator (UVR), a training-free safe generation framework that regulates unsafe semantics in generated images. UVR is grounded in an analysis of attention dynamics from the perspective of information flow in MM-Attn. We identify a task-independent start-up stage, during which unsafe semantics in output patches rapidly emerge and can be accurately localized, followed by task-specific semantic amplification and interference stages, where harmful signals are further propagated and entangled with benign content. Based on these observations, UVR mitigates unsafe generation through unified, targeted attention modulation and explicit restriction of harmful information flow over the identified unsafe output patches. Experiments across various concepts show that UVR achieves state-of-the-art safety performance by achieving 91% and 77% erase rate in image synthesis and editing tasks, while preserving visual quality and fidelity with minimal degradation. Code is available at https://github.com/deng12yx/UVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Unified Visual Safety Regulator (UVR), a training-free framework for mitigating unsafe content generation in multimodal diffusion transformers (DiTs) with multimodal attention (MM-Attn). Grounded in an analysis of attention dynamics, it identifies a task-independent start-up stage where unsafe semantics emerge and localize to output patches, followed by amplification and interference stages. UVR restricts harmful information flows over these patches during the start-up stage. Experiments across concepts are reported to yield 91% erase rate for image synthesis and 77% for editing tasks, with minimal degradation to visual quality and fidelity.
Significance. If the start-up stage localization proves precise and the restriction avoids unintended effects on benign content, the work would offer a unified, training-free safety mechanism for the dominant DiT paradigm, filling a gap left by T2I- or U-Net-focused methods. The training-free design and public code release support reproducibility and potential adoption.
major comments (3)
- [Abstract] Abstract: The central performance claims rest on 91% and 77% erase rates, yet the abstract (and by extension the evaluation) provides no definition of the erase-rate metric, no description of dataset construction, baselines, or statistical significance testing. These omissions are load-bearing for the SOTA assertion.
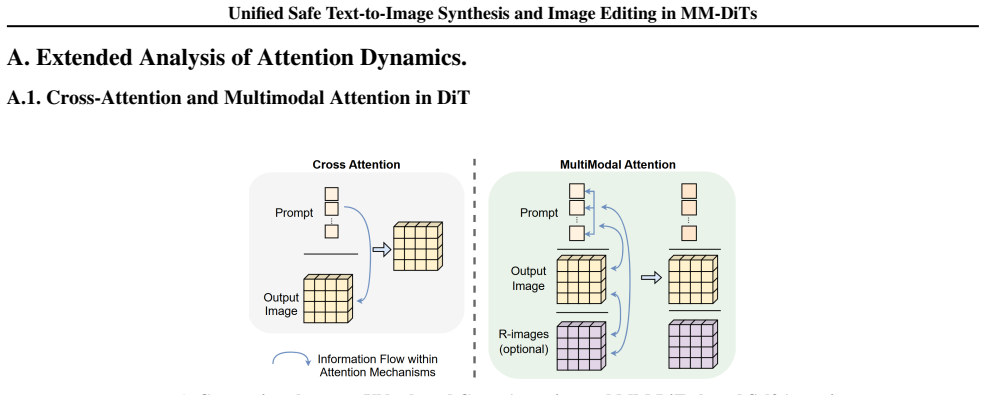
- [Analysis of Attention Dynamics] Analysis section (attention dynamics): The identification of a task-independent start-up stage and the localization of unsafe semantics to specific output patches is presented qualitatively, but no equations, attention thresholds, or semantic criteria for patch selection are supplied. Without these, it is impossible to verify whether localization avoids mixed or benign patches or whether restriction disrupts later safe-semantic amplification, directly testing the skeptic's weakest assumption.
- [Experiments] Experiments section: Claims of 'minimal degradation' in visual quality and fidelity for both synthesis and editing lack ablations isolating the effect of patch restriction on safe content, or quantitative fidelity metrics with controls. This leaves open whether the unified mitigation underperforms on editing tasks or introduces side effects beyond reported levels.
minor comments (1)
- [Abstract] The title uses 'in-context' but the abstract does not define the term or link it explicitly to the method; a brief clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims rest on 91% and 77% erase rates, yet the abstract (and by extension the evaluation) provides no definition of the erase-rate metric, no description of dataset construction, baselines, or statistical significance testing. These omissions are load-bearing for the SOTA assertion.
Authors: The erase rate metric is defined in the Experiments section as the percentage of cases where the unsafe concept is successfully erased, measured using a pre-trained safety classifier on generated images. Dataset construction involves a set of unsafe concepts (e.g., violence, nudity) with corresponding prompts for synthesis and editing tasks. Baselines include recent safety methods for DiTs and U-Nets. We report results averaged over multiple seeds for statistical reliability. We will add a definition of the erase-rate to the abstract and a brief overview of the experimental setup to make these details more accessible. revision: yes
-
Referee: [Analysis of Attention Dynamics] Analysis section (attention dynamics): The identification of a task-independent start-up stage and the localization of unsafe semantics to specific output patches is presented qualitatively, but no equations, attention thresholds, or semantic criteria for patch selection are supplied. Without these, it is impossible to verify whether localization avoids mixed or benign patches or whether restriction disrupts later safe-semantic amplification, directly testing the skeptic's weakest assumption.
Authors: Our analysis in Section 3 is grounded in visualizations of attention maps and information flow across denoising timesteps, revealing a consistent start-up stage in early steps. The patch selection is based on patches exhibiting high attention to unsafe semantic tokens. We will introduce equations formalizing the information flow stages, specify the attention threshold (e.g., patches with attention weight exceeding the mean by a factor), and criteria for identifying unsafe patches to enable precise verification and address concerns about mixed patches. revision: yes
-
Referee: [Experiments] Experiments section: Claims of 'minimal degradation' in visual quality and fidelity for both synthesis and editing lack ablations isolating the effect of patch restriction on safe content, or quantitative fidelity metrics with controls. This leaves open whether the unified mitigation underperforms on editing tasks or introduces side effects beyond reported levels.
Authors: We will add ablations applying UVR to safe/benign prompts to quantify any impact on visual quality using metrics like FID and CLIP similarity, with controls comparing to no intervention. For editing tasks, we will provide additional quantitative fidelity metrics and comparisons to demonstrate that the method does not introduce unintended side effects beyond the reported minimal degradation. revision: yes
Circularity Check
No circularity: empirical observation of attention stages grounds intervention without self-referential reduction
full rationale
The paper derives UVR from direct analysis of MM-Attn information flow, identifying a start-up stage via attention dynamics observations and applying targeted modulation. No equations, parameters, or predictions reduce to fitted inputs or self-citations; the central claim rests on empirical localization rather than any definitional loop or imported uniqueness theorem. The derivation chain is self-contained against external benchmarks of attention visualization and safety metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal attention in DiTs exhibits identifiable task-independent start-up, amplification, and interference stages for unsafe semantics.
Reference graph
Works this paper leans on
-
[1]
Open problems in machine unlearning for ai safety.arXiv preprint arXiv:2501.04952,
Barez, F., Fu, T., Prabhu, A., Casper, S., Sanyal, A., Bibi, A., O’Gara, A., Kirk, R., Bucknall, B., Fist, T., et al. Open problems in machine unlearning for ai safety.arXiv preprint arXiv:2501.04952,
-
[2]
Chen, R., Guo, H., Wang, L., Zhang, C., Nie, W., and Liu, A.-A. Trce: Towards reliable malicious concept erasure in text-to-image diffusion models.arXiv preprint arXiv:2503.07389,
-
[3]
Prompting4debugging: Red-teaming text-to- image diffusion models by finding problematic prompts
Chin, Z.-Y ., Jiang, C.-M., Huang, C.-C., Chen, P.-Y ., and Chiu, W.-C. Prompting4debugging: Red-teaming text-to- image diffusion models by finding problematic prompts. arXiv preprint arXiv:2309.06135,
-
[4]
Eraseanything: Enabling concept erasure in rectified flow transformers
Gao, D., Lu, S., Zhou, W., Chu, J., Zhang, J., Jia, M., Zhang, B., Fan, Z., and Zhang, W. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty- second International Conference on Machine Learning, 2025a. Gao, H., Pang, T., Du, C., Hu, T., Deng, Z., and Lin, M. Meta-unlearning on diffusion models: Preventing relearn- ing unlearne...
-
[5]
10 Unified Safe Text-to-Image Synthesis and Image Editing in MM-DiTs Ku, M., Li, T., Zhang, K., Lu, Y ., Fu, X., Zhuang, W., and Chen, W. Imagenhub: Standardizing the evaluation of conditional image generation models.arXiv preprint arXiv:2310.01596,
-
[6]
Labs, B. F., Batifol, S., Blattmann, A., Boesel, F., Con- sul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742,
-
[7]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[8]
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499,
-
[9]
Modifier unlocked: Jailbreaking text-to-image models through prompts
Liu, S., Ma, M., Xue, M., and Bai, G. Modifier unlocked: Jailbreaking text-to-image models through prompts. In 2025 IEEE Symposium on Security and Privacy (SP), pp. 355–372. IEEE, 2025a. Liu, S., Ma, M., Xue, M., and Bai, G. Modifier unlocked: Jailbreaking text-to-image models through prompts. In 2025 IEEE Symposium on Security and Privacy (SP), pp. 355–3...
2025
-
[10]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M ¨uller, J., Penna, J., and Rombach, R. Sdxl: Im- proving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
-
[11]
Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610,
Rando, J., Paleka, D., Lindner, D., Heim, L., and Tram `er, F. Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610,
-
[12]
Reimers, N. and Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084,
Pith/arXiv arXiv 1908
-
[13]
Re- stricting the flow: Information bottlenecks for attribution
Schulz, K., Sixt, L., Tombari, F., and Landgraf, T. Re- stricting the flow: Information bottlenecks for attribution. arXiv preprint arXiv:2001.00396,
arXiv 2001
-
[14]
Tsai, Y .-L., Hsu, C.-Y ., Xie, C., Lin, C.-H., Chen, J.-Y ., Li, B., Chen, P.-Y ., Yu, C.-M., and Huang, C.-Y . Ring-a-bell! how reliable are concept removal methods for diffusion models?arXiv preprint arXiv:2310.10012,
-
[15]
Wei, T., Zhou, Y ., Chen, D., and Pan, X. Freeflux: Un- derstanding and exploiting layer-specific roles in rope- based mmdit for versatile image editing.arXiv preprint arXiv:2503.16153,
-
[16]
Mmdt: Decoding the trustworthiness and safety of multi- modal foundation models
11 Unified Safe Text-to-Image Synthesis and Image Editing in MM-DiTs Xu, C., Zhang, J., Chen, Z., Xie, C., Kang, M., Potter, Y ., Wang, Z., Yuan, Z., Xiong, A., Xiong, Z., et al. Mmdt: Decoding the trustworthiness and safety of multi- modal foundation models. InInternational Conference on Learning Representations, volume 2025, pp. 4069–4165, 2025a. Xu, W....
2025
-
[17]
19 Unified Safe Text-to-Image Synthesis and Image Editing in MM-DiTs Table 5.Representative prompt examples from Unsafe-1K
is employed to classify an image as containing nudity if the detector assigns a confidence score higher than 0.65 to any of the following exposed-body classes: MALE GENITALIA EXPOSED, MALE BREAST EXPOSED, FEMALE BREAST EXPOSED,BUTTOCKS EXPOSED, andFEMALE GENITALIA EXPOSED. 19 Unified Safe Text-to-Image Synthesis and Image Editing in MM-DiTs Table 5.Repres...
2019
-
[18]
and 272 Prompt4Debugging (P4D) (Chin et al., 2023), is designed to evaluate the robustness of NSFW safety mechanisms in text-to-image (T2I) models. The RAB effectively identifies problematic prompts that bypass safety mechanisms, resulting in NSFW content generation. We further use the 2https://huggingface.co/datasets/jtatman/stable-diffusion-prompts- sta...
arXiv 2023
-
[19]
These problematic prompts are intended to evaluate the concept removal performance of image generation models
P4D dataset consists of prompts designed to generate nudityrelated content in generative models. These problematic prompts are intended to evaluate the concept removal performance of image generation models. Our paper utilizes this dataset directly from Huggingface4 As summarized in Table 6, the vanilla FLUX.1-dev model exhibits substantial vulnerability ...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.