A Concentration Inequality for the Covariance Matrix of an Arbitrary Subset of Random Vectors
Pith reviewed 2026-06-25 21:47 UTC · model grok-4.3
The pith
High-probability eigenvalue bounds for covariance matrices of arbitrary data-dependent subsets of i.i.d. Gaussian vectors are established.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For i.i.d. Gaussian random vectors, high-probability lower and upper bounds are proved for the minimal and maximal eigenvalues of the sample covariance matrix formed from an arbitrary, possibly data-dependent subset. These bounds are substantially sharper than those from a direct union-bound argument and permit much smaller subset proportions.
What carries the argument
A concentration inequality for the eigenvalues of the covariance matrix of an arbitrary subset that accounts for data-dependent selection.
If this is right
- The bounds extend to sub-Gaussian random vectors.
- The bounds extend to geometrically strong-mixing Gaussian sequences.
- Recovery guarantees are obtained for K-subspace clustering under a low-rank Gaussian mixture model, with clustering error decaying polynomially in the signal-to-noise ratio.
- Substantially smaller subset proportions become feasible compared with union-bound methods.
Where Pith is reading between the lines
- The approach could be applied to other adaptive procedures in high-dimensional statistics where observations are selected based on the data.
- Simulations with controlled dependence could test how far the mixing extension reaches in practice.
- Similar techniques might improve guarantees in robust estimation or outlier detection settings.
Load-bearing premise
The vectors are i.i.d. Gaussian or sub-Gaussian and the selection rule does not introduce dependence structures that invalidate the tail bounds.
What would settle it
A counterexample in which the eigenvalue bounds fail to hold with the claimed probability for a data-dependent subset selection while the vectors remain i.i.d. Gaussian would falsify the result.
Figures
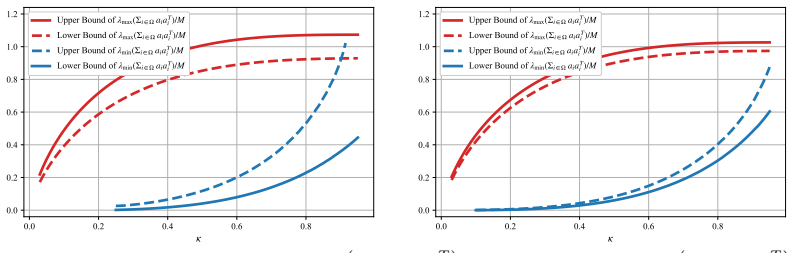
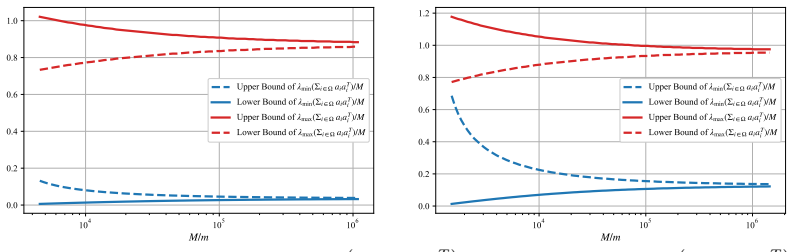
read the original abstract
Concentration inequalities for sample covariance matrices are fundamental tools in high-dimensional probability. Classical results typically assume that the selected random vectors are independent of the selection rule. In this paper, we study spectral concentration for sample covariance matrices formed from arbitrary, possibly data-dependent subsets of i.i.d. random vectors. Such data-dependent selection destroys the usual independence structure and makes standard covariance concentration bounds inapplicable. For i.i.d. Gaussian random vectors, we prove high-probability lower and upper bounds for the minimal and maximal eigenvalues of such selected covariance matrices. Compared with a direct union-bound argument, our results provide substantially sharper guarantees and allow much smaller subset proportions. We further discuss extensions from Gaussian to sub-Gaussian random vectors, and beyond independence to weakly dependent observations, with geometrically strong-mixing Gaussian sequences serving as a representative example of the latter. Finally, we apply the developed concentration inequalities to the K-subspace clustering problem under a low-rank Gaussian mixture model, where the optimal clusters are inherently data-dependent. Our results yield recovery guarantees showing that the clustering error of global minimizers decays polynomially with the signal-to-noise ratio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish high-probability lower and upper bounds on the minimal and maximal eigenvalues of sample covariance matrices formed from arbitrary (including data-dependent) subsets of i.i.d. Gaussian random vectors. The bounds are shown to be substantially sharper than those obtained from a direct union bound over all subsets of a given proportion p = k/n, with the deviation term scaling more mildly than the binomial entropy term n·h(p). Extensions to sub-Gaussian vectors and geometrically strong-mixing sequences are stated with explicit conditions, and the inequalities are applied to obtain recovery guarantees for global minimizers in K-subspace clustering under a low-rank Gaussian mixture model, where clustering error decays polynomially in the signal-to-noise ratio.
Significance. If the central bounds hold, the work fills a gap in covariance concentration results by handling data-dependent selection without assuming independence between vectors and the selection rule. This is relevant for high-dimensional statistics and clustering applications. The manuscript's explicit mixing-rate conditions for the dependent case and the direct application to clustering error bounds are strengths that make the contribution concrete and falsifiable.
minor comments (3)
- The abstract states that the Gaussian bounds are 'substantially sharper' and allow 'much smaller subset proportions,' but does not display the explicit functional form of the deviation term or the precise scaling with p; adding a one-line comparison (e.g., deviation ~ f(p) vs. n·h(p)) would clarify the improvement for readers.
- In the clustering application, the recovery guarantee is stated to decay polynomially with SNR, but the precise exponent and the dependence on the number of clusters K are not summarized in the abstract or introduction; a short statement of the rate would help assess the result's strength.
- Notation for the selected subset proportion p = k/n and the eigenvalue bounds λ_min, λ_max should be introduced once in a dedicated notation paragraph to avoid repeated definitions across sections.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and for recommending minor revision. The referee's summary accurately captures the main contributions regarding sharper concentration bounds for data-dependent subsets and the application to subspace clustering. No major comments were raised in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper establishes high-probability eigenvalue bounds for covariance matrices of arbitrary (including data-dependent) subsets of i.i.d. Gaussians via direct tail bounds on quadratic forms and rotational invariance, without fitting parameters to data or invoking self-citations for the core result. The improvement over union bounds follows from controlling dependence among overlapping subsets rather than from any definitional equivalence or renamed empirical pattern. Extensions to sub-Gaussian and mixing cases are stated with explicit assumptions that do not presuppose the target bounds. The clustering application is a downstream use of the inequality, not part of the derivation chain. No load-bearing step reduces to a self-referential fit or prior self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The random vectors are i.i.d. Gaussian (or sub-Gaussian).
Reference graph
Works this paper leans on
-
[1]
Balzano, A
L. Balzano, A. Szlam, B. Recht, and R. Nowak. K-subspaces with missing data. In2012 IEEE Statistical Signal Processing Workshop (SSP), pages 612–615. IEEE, 2012
2012
-
[2]
P. S. Bradley and O. L. Mangasarian. K-plane clustering.Journal of Global optimization, 16(1):23–32, 2000. 11
2000
-
[3]
Diakonikolas, G
I. Diakonikolas, G. Kamath, D. Kane, J. Li, A. Moitra, and A. Stewart. Robust estimators in high-dimensions without the computational intractability.SIAM Journal on Computing, 48(2):742–864, 2019
2019
-
[4]
Elhamifar and R
E. Elhamifar and R. Vidal. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(11):2765–2781, 2013
2013
-
[5]
Fickus and D
M. Fickus and D. G. Mixon. Numerically erasure-robust frames.Linear Algebra and its Applications, 437(6):1394–1407, 2012
2012
-
[6]
R. D. Gordon. Values of mills’ ratio of area to bounding ordinate and of the normal probability integral for large values of the argument.The Annals of Mathematical Statistics, 12(3):364–366, 1941
1941
-
[7]
Han and Z
B. Han and Z. Xu. Robustness properties of dimensionality reduction with gaussian random matrices.Science China Mathematics, 60(10):1753–1778, 2017
2017
-
[8]
Han and Y
F. Han and Y . Li. Moment bounds for large autocovariance matrices under dependence.Journal of Theoretical Probability, 33(3):1445–1492, 2020
2020
-
[9]
Laurent and P
B. Laurent and P. Massart. Adaptive estimation of a quadratic functional by model selection. Annals of Statistics, pages 1302–1338, 2000
2000
-
[10]
Ledoux.The Concentration of Measure Phenomenon, volume 89 ofMathematical Surveys and Monographs
M. Ledoux.The Concentration of Measure Phenomenon, volume 89 ofMathematical Surveys and Monographs. American Mathematical Society, 2001
2001
-
[11]
Li and Y
G. Li and Y . Gu. Theory of spectral method for union of subspaces-based random geometry graph. InProceedings of the 38th International Conference on Machine Learning, volume 139, pages 6337–6345. PMLR, 2021
2021
-
[12]
J. Li. Lecture 6: Stronger spectral signatures for gaussian datasets. Technical report, Robust Machine Learning, Fall 2019. https://jerryzli.github.io/robust-ml-fall19/lec6. pdf
2019
-
[13]
Lipor, D
J. Lipor, D. Hong, Y . S. Tan, and L. Balzano. Subspace clustering using ensembles of K- subspaces.Information and Inference: A Journal of the IMA, 10(1):73–107, 2021
2021
-
[14]
Y . Liu, L. Jiao, and F. Shang. An efficient matrix factorization based low-rank representation for subspace clustering.Pattern Recognition, 46(1):284–292, 2013
2013
-
[15]
Merlevède, M
F. Merlevède, M. Peligrad, and E. Rio. Bernstein inequality and moderate deviations under strong mixing conditions. InHigh Dimensional Probability V: The Luminy Volume, pages 273–293. Institute of Mathematical Statistics, 2009
2009
-
[16]
S. Park, X. Wang, and J. Lim. Estimating high-dimensional covariance and precision matrices under general missing dependence.Electronic Journal of Statistics, 15(2):4868–4915, 2021
2021
-
[17]
D. Paulin. Concentration inequalities for markov chains by marton couplings and spectral methods.Electronic Journal of Probability, 20:1–32, 2015
2015
-
[18]
Rosenblatt
M. Rosenblatt. A central limit theorem and a strong mixing condition.Proceedings of the national Academy of Sciences, 42(1):43–47, 1956
1956
-
[19]
A. M.-C. So. Handout 1: Spectrum of a Gaussian random matrix, 2022. Lecture notes for SEEM 5380: Optimization Methods for High-Dimensional Statistics at The Chinese University of Hong Kong
2022
-
[20]
Soltanolkotabi, E
M. Soltanolkotabi, E. J. Candes, et al. A geometric analysis of subspace clustering with outliers. The Annals of Statistics, 40(4):2195–2238, 2012
2012
-
[21]
Soltanolkotabi, E
M. Soltanolkotabi, E. Elhamifar, E. J. Candes, et al. Robust subspace clustering.Annals of Statistics, 42(2):669–699, 2014
2014
-
[22]
J. A. Tropp. Freedman’s inequality for matrix martingales.Electronic Communications in Probability, 16:262–270, 2011. 12
2011
-
[23]
J. A. Tropp. An introduction to matrix concentration inequalities.Foundations and Trends in Machine Learning, 8(1–2):1–230, 2015
2015
-
[24]
Vershynin.High-dimensional probability: An introduction with applications in data science, volume 47
R. Vershynin.High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018
2018
-
[25]
R. Vidal. Subspace clustering.IEEE Signal Processing Magazine, 28(2):52–68, 2011
2011
-
[26]
Vidal, Y
R. Vidal, Y . Ma, and S. Sastry. Generalized principal component analysis (GPCA).IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(12):1945–1959, 2005
1945
-
[27]
P. Wang, H. Liu, A. M.-C. So, and L. Balzano. Convergence and recovery guarantees of the K-subspaces method for subspace clustering. InInternational Conference on Machine Learning, pages 22884–22918. PMLR, 2022
2022
-
[28]
P. Wang, H. Zhang, Z. Zhang, S. Chen, Y . Ma, and Q. Qu. Diffusion models learn low- dimensional distributions via subspace clustering. In2025 IEEE 10th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pages 211–215. IEEE, 2025
2025
-
[29]
Y . Wang. Random matrices and erasure robust frames.Journal of Fourier Analysis and Applications, 24(1):1–16, 2018
2018
-
[30]
Wang and H
Y .-X. Wang and H. Xu. Noisy sparse subspace clustering. InInternational Conference on Machine Learning, pages 89–97. PMLR, 2013
2013
-
[31]
A. S. Xu, C. Yaras, P. Wang, and Q. Qu. Linearly separable features in shallow nonlinear networks: Width scales polynomially with intrinsic data dimension. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026
2026
-
[32]
Zhang, J
H. Zhang, J. Zhou, Y . Lu, M. Guo, P. Wang, L. Shen, and Q. Qu. The emergence of reproducibil- ity and consistency in diffusion models. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 60558–60590. PMLR, 2024. 13 Appendices A Proofs for Section 2 A.1 Proof of Theorem 1 Proof. For ease of exposition, let AΩ ∈R m×|Ω|...
2024
-
[33]
Actually, we only need to show it holds asκ 1 goes to 0, since there is a constant boundµ≥µ 0 for allκ 1 ≥ϵ
It remains to justify (33). Actually, we only need to show it holds asκ 1 goes to 0, since there is a constant boundµ≥µ 0 for allκ 1 ≥ϵ. Recall that µ= r 2 π Z γ 0 x2 exp − x2 2 dx= 1 3 r 2 π γ3 +o(γ 3) and (1−η)κ 1 2 = 1√ 2π Z γ 0 exp − x2 2 dx= 1√ 2π γ+o(γ). Then, we compute lim κ1→0 µ κ3 1 = lim γ→0 1 3 q 2 π γ3 q 2 π γ 1−η 3 = (1−η) 3π 6 . D Auxiliary...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.