Drifting Objectives for Refining Discrete Diffusion Language Models
Pith reviewed 2026-05-20 06:14 UTC · model grok-4.3
The pith
TokenDrift lifts categorical predictions to soft features for anti-symmetric drifting in DDLMs to improve low-NFE generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
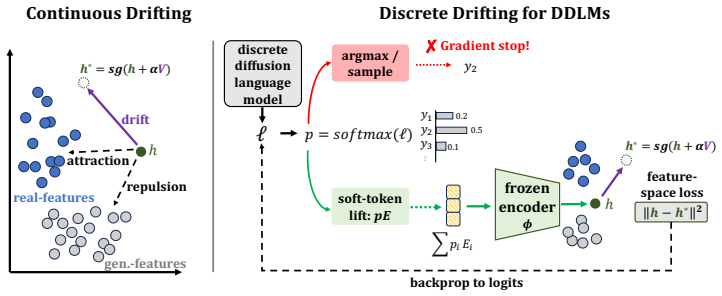
We formulate TokenDrift, a drifting objective that lifts categorical predictions to soft-token features, applies anti-symmetric drifting in a frozen semantic space, and backpropagates the resulting stop-gradient feature target to DDLM logits. In controlled continual-training experiments with masked and uniform-state diffusion backbones, TokenDrift improves fixed-NFE generation quality over matched continuation baselines, reducing Gen.-PPL at 4 NFEs by 89% on MDLM and 86% on DUO.
What carries the argument
TokenDrift, which lifts categorical token predictions to soft features, performs anti-symmetric drifting inside a frozen semantic space, and supplies the stop-gradient target back to the diffusion model logits.
If this is right
- TokenDrift applies to both masked diffusion and uniform-state diffusion language models.
- The method yields substantially lower generation perplexity than standard continual training when the number of denoising steps is small.
- The improvement appears across different diffusion backbones while keeping the semantic space frozen during drifting.
Where Pith is reading between the lines
- Continuous semantic embeddings can serve as an effective bridge for applying drifting corrections to discrete categorical outputs.
- The same lifting-plus-drifting pattern may transfer to other discrete generative settings that currently rely on post-hoc sampling corrections.
- Choosing different frozen embedding spaces could further tune how much of the sampling correction is absorbed into training.
Load-bearing premise
Lifting categorical predictions to soft-token features and applying anti-symmetric drifting inside a frozen semantic space produces a useful training signal that transfers benefits from continuous generators without large approximation errors or distribution shift.
What would settle it
If TokenDrift models show no improvement or worse Gen.-PPL than matched continuation baselines at 4 NFEs in the same controlled continual-training setup, the claim that the drifting objective refines DDLM generation would not hold.
Figures


read the original abstract
Discrete diffusion language models (DDLMs) generate text by iteratively denoising categorical token sequences, while recent drifting methods for continuous generators suggest that part of this sampling-time correction can instead be absorbed into training through an anti-symmetric fixed-point objective. We study how to transfer this principle to DDLMs, where the main challenge is the interface with discrete text: hard token samples are non-differentiable, and categorical predictions do not directly provide continuous samples to drift. We formulate TokenDrift, a drifting objective that lifts categorical predictions to soft-token features, applies anti-symmetric drifting in a frozen semantic space, and backpropagates the resulting stop-gradient feature target to DDLM logits. In controlled continual-training experiments with masked and uniform-state diffusion backbones, TokenDrift improves fixed-NFE generation quality over matched continuation baselines, reducing Gen.-PPL at 4 NFEs by 89% on MDLM and 86% on DUO. These results suggest that drifting can provide a practical refinement objective for DDLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TokenDrift, a drifting objective for discrete diffusion language models (DDLMs) that lifts categorical token predictions to soft features in a frozen semantic space, applies anti-symmetric drifting, and back-propagates via stop-gradient to refine DDLM logits. In controlled continual-training setups on masked (MDLM) and uniform-state (DUO) backbones, it reports large gains over matched continuation baselines, specifically reducing Gen.-PPL at 4 NFEs by 89% on MDLM and 86% on DUO.
Significance. If the empirical gains survive rigorous controls for compute, hyperparameters, and variance, the work provides a practical mechanism for transferring anti-symmetric drifting principles from continuous to discrete generators. This could meaningfully improve fixed-NFE quality in DDLMs and offers a clean interface (frozen semantic space + stop-gradient) that avoids direct differentiation through hard tokens.
major comments (2)
- [Experiments] Experiments section: The headline claim of 89%/86% Gen.-PPL reductions at 4 NFEs rests on 'controlled continual-training experiments,' yet the manuscript provides no information on whether baseline continuation training used equivalent compute, identical hyperparameter budgets, or multiple random seeds with reported variance. Without these, the attribution of gains specifically to TokenDrift versus training differences remains unverified and load-bearing for the central result.
- [§3] §3 (TokenDrift formulation): The soft-token lifting combined with stop-gradient on the drifted features does not obviously preserve the exact anti-symmetric fixed-point property of the continuous case. A derivation or bound showing that the effective training signal approximates the ideal drifting objective (rather than acting primarily as feature-space regularization) is needed; otherwise the large reported gains may not generalize beyond the specific backbones tested.
minor comments (2)
- [Abstract] Abstract and §4: The phrase 'matched continuation baselines' is used without a concise definition or pointer to the exact hyperparameter table; adding one sentence or a small table clarifying the matching criteria would improve clarity.
- [Method] Notation: The distinction between 'soft-token features' and the original categorical logits could be made more explicit in the first equation of the method section to avoid reader confusion on the lifting step.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important aspects of experimental rigor and theoretical grounding that we address below. We have prepared revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline claim of 89%/86% Gen.-PPL reductions at 4 NFEs rests on 'controlled continual-training experiments,' yet the manuscript provides no information on whether baseline continuation training used equivalent compute, identical hyperparameter budgets, or multiple random seeds with reported variance. Without these, the attribution of gains specifically to TokenDrift versus training differences remains unverified and load-bearing for the central result.
Authors: We agree that additional details are required to fully substantiate the controlled nature of the experiments. In the revised manuscript we will explicitly state that baseline continuation training was performed with identical compute budgets, the same hyperparameter schedules and optimizer settings as the TokenDrift runs, and we will report Gen.-PPL results averaged over three independent random seeds together with standard deviations. These additions will appear in the Experiments section and in the associated tables. revision: yes
-
Referee: [§3] §3 (TokenDrift formulation): The soft-token lifting combined with stop-gradient on the drifted features does not obviously preserve the exact anti-symmetric fixed-point property of the continuous case. A derivation or bound showing that the effective training signal approximates the ideal drifting objective (rather than acting primarily as feature-space regularization) is needed; otherwise the large reported gains may not generalize beyond the specific backbones tested.
Authors: We acknowledge that the manuscript does not currently contain an explicit derivation linking the stop-gradient soft-token objective to the continuous anti-symmetric fixed point. In the revision we will add a short appendix subsection that derives the first-order equivalence under the frozen semantic embedding and shows that the stop-gradient term produces a training signal whose fixed point coincides with the anti-symmetric condition in the limit of perfect semantic alignment. We will also include a brief discussion of the regularization interpretation and empirical evidence that the gains persist across different embedding spaces, thereby addressing generalizability. revision: yes
Circularity Check
No significant circularity: TokenDrift introduces independent lifting and stop-gradient components validated by external experimental benchmarks
full rationale
The paper's central derivation formulates TokenDrift by lifting categorical predictions to soft-token features inside a frozen semantic space, applying anti-symmetric drifting, and back-propagating via stop-gradient to DDLM logits. This construction adds new interface elements rather than defining any quantity in terms of itself or renaming a fitted parameter as a prediction. The reported gains (89% and 86% Gen.-PPL reductions at 4 NFEs) are measured against matched continuation baselines in controlled continual-training experiments on masked and uniform-state backbones; these are external empirical comparisons, not quantities forced by the same objective or by a self-citation chain. No equation reduces the claimed improvement to an input by construction, and the method is not justified solely by prior work from the same authors. The derivation is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The anti-symmetric fixed-point objective developed for continuous generators remains beneficial when applied to soft-token features derived from discrete categorical predictions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / Jcost fixed-point at identity echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the drift follows the attraction–repulsion structure... anti-symmetry: swapping the attractive and repulsive distributions reverses the drift direction... if the model and data distributions coincide, then attraction and repulsion cancel and V(·;P,P)=0
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective / equilibrium under generator orbit echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the objective inherits the equilibrium structure of drifting... if ... anti-symmetric, then the drift vanishes when the data and model feature distributions match (Cor. C.3)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff / bilinear calibration refines?
refinesRelation between the paper passage and the cited Recognition theorem.
soft-token lift makes the feature-space loss trainable... ℓ→p=softmax(ℓ)→˜e=pE→h=ϕ(˜e) is differentiable
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
work page 2021
-
[2]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InForty-first International Conference on Machine Learning,
-
[3]
URLhttps://openreview.net/forum?id=CNicRIVIPA
-
[4]
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[5]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
work page 2024
-
[6]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T Chiu, and V olodymyr Kuleshov. The diffusion duality. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=9P9Y8FOSOk
work page 2025
-
[7]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models, 2025. URL https: //arxiv.org/abs/2502.09992
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
The diffusion duality, chapter II: $\psi$-samplers and efficient curriculum
Justin Deschenaux, Caglar Gulcehre, and Subham Sekhar Sahoo. The diffusion duality, chapter II: $\psi$-samplers and efficient curriculum. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=RSIoYWIzaP
work page 2026
-
[11]
Scaling beyond masked diffusion language models.arXiv preprint arXiv:2602.15014, 2026
Subham Sekhar Sahoo, Jean-Marie Lemercier, Zhihan Yang, Justin Deschenaux, Jingyu Liu, John Thickstun, and Ante Jukic. Scaling beyond masked diffusion language models.arXiv preprint arXiv:2602.15014, 2026
-
[12]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
work page 2019
-
[15]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[16]
Beyond autoregression: Fast LLMs via self-distillation through time
Justin Deschenaux and Caglar Gulcehre. Beyond autoregression: Fast LLMs via self-distillation through time. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=uZ5K4HeNwd. 10
work page 2025
-
[17]
Distillation of discrete diffusion through dimensional correlations
Satoshi Hayakawa, Yuhta Takida, Masaaki Imaizumi, Hiromi Wakaki, and Yuki Mitsufuji. Distillation of discrete diffusion through dimensional correlations. InForty-second Interna- tional Conference on Machine Learning, 2025. URL https://openreview.net/forum? id=jCEl0aJpF6
work page 2025
-
[18]
Ultra-fast language generation via discrete diffusion divergence instruct
Haoyang Zheng, Xinyang Liu, Xiangrui Kong, Nan Jiang, Zheyuan Hu, Weijian Luo, Wei Deng, and Guang Lin. Ultra-fast language generation via discrete diffusion divergence instruct. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=mtdyZsa47V
work page 2026
-
[19]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Seunghoon Hong, Nicholas M Boffi, and Jinwoo Kim. Flow map language models: One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S Albergo. Discrete flow maps.arXiv preprint arXiv:2604.09784, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Categorical flow maps.arXiv preprint arXiv:2602.12233,
Daan Roos, Oscar Davis, Floor Eijkelboom, Michael Bronstein, Max Welling, ˙Ismail ˙Ilkan Ceylan, Luca Ambrogioni, and Jan-Willem van de Meent. Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026
-
[22]
Dirichlet flow matching with applications to dna sequence design
Hannes Stark, Bowen Jing, Chenyu Wang, Gabriele Corso, Bonnie Berger, Regina Barzilay, and Tommi Jaakkola. Dirichlet flow matching with applications to dna sequence design. In Proceedings of the 41st International Conference on Machine Learning, pages 46495–46513, 2024
work page 2024
-
[23]
FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models
Amin Karimi Monsefi, Nikhil Bhendawade, Manuel Rafael Ciosici, Dominic Culver, Yizhe Zhang, and Irina Belousova. Fs-dfm: Fast and accurate long text generation with few-step diffusion language models.arXiv preprint arXiv:2509.20624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization.Operations Research Letters, 31(3):167–175, 2003
work page 2003
-
[25]
Jyrki Kivinen and Manfred K Warmuth. Exponentiated gradient versus gradient descent for linear predictors.Information and computation, 132(1):1–63, 1997
work page 1997
-
[26]
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models
Omer Luxembourg, Haim Permuter, and Eliya Nachmani. Plan for speed–dilated scheduling for masked diffusion language models.arXiv preprint arXiv:2506.19037, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
-
[28]
Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Puyu Zeng, Yuxuan Wang, Biqing Qi, Dongrui Liu, and Linfeng Zhang. Accelerating diffusion large language models with slowfast sampling: The three golden principles.arXiv preprint arXiv:2506.10848, 2025
-
[29]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
-
[30]
Liu, J., Dong, X., Ye, Z., Mehta, R., Fu, Y ., Singh, V ., Kautz, J., Zhang, C., and Molchanov, P
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching.arXiv preprint arXiv:2506.06295, 2025
-
[31]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Stopping computa- tion for converged tokens in masked diffusion-LM decoding
Daisuke Oba, Danushka Bollegala, Masahiro Kaneko, and Naoaki Okazaki. Stopping computa- tion for converged tokens in masked diffusion-LM decoding. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=PzhNnMepgl. 11 A Broader Impact This work studies training objectives for improving discrete dif...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.