Multi-scale Object-Aware Gaze Estimation via Geometric Reasoning
Pith reviewed 2026-06-30 07:29 UTC · model grok-4.3
The pith
A two-stage framework uses object-level representations and geometric constraints to reformulate gaze target estimation as hierarchical semantic reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
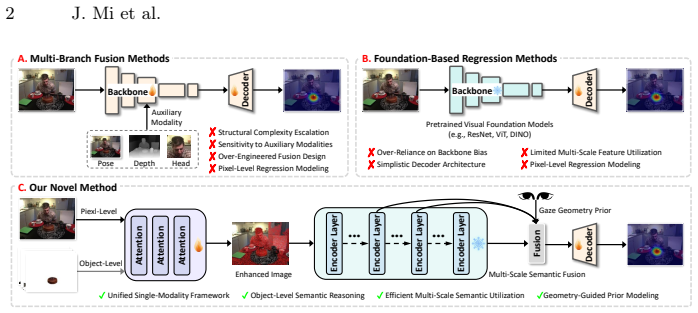
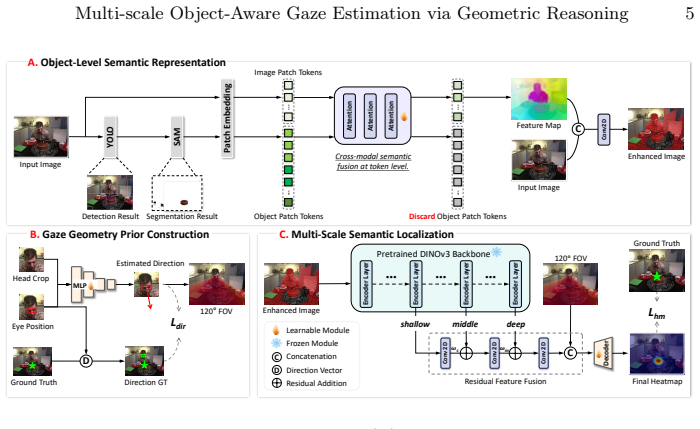
The authors state that modeling gaze target estimation as a hierarchical reasoning process, with object-level representations aligned during feature encoding, followed by multi-scale feature fusion and geometric constraints from head pose and gaze direction, enables fine-grained localization and object-level discrimination that direct pixel regression cannot achieve.
What carries the argument
Two-stage framework that inserts object-level representations into feature encoding to align image features with discrete semantic entities, then fuses multi-scale features under geometric constraints from head pose and gaze direction.
If this is right
- Predictions become stable and semantically consistent rather than varying across arbitrary image regions.
- Fine-grained localization improves through multi-scale fusion combined with head pose and gaze direction constraints.
- Object-level discrimination allows the model to select specific semantic entities as attentional targets.
- Performance reaches the reported AUC values on GazeFollow, VideoAttentionTarget, ChildPlay, and GOO-Real while using only 7.1M parameters.
Where Pith is reading between the lines
- The method could be tested for robustness by measuring how errors in upstream object detection affect final gaze accuracy.
- Small model size suggests possible extension to video streams or embedded devices, though the paper evaluates only static images.
- The hierarchical structure may apply to other tasks that require distinguishing discrete entities under geometric constraints, such as hand-object interaction prediction.
Load-bearing premise
Explicitly representing the gazed object as a distinct semantic entity through object-level representations during feature encoding will produce stable and semantically consistent predictions.
What would settle it
An ablation that removes the object-level representation step and measures whether AUC on GazeFollow falls to the level of prior direct-mapping baselines would test the necessity of the semantic alignment.
Figures


read the original abstract
Gaze target estimation aims to predict the semantic object an observer fixates upon within an image, a task deeply rooted in the object-oriented nature of human gaze. Observers tend to select a specific semantic entity as the attentional target, rather than responding randomly across arbitrary regions of the image. However, existing methods typically model this task as a direct mapping from global features to gaze heatmaps, essentially treating it as a pixel-level regression problem. This approach fails to explicitly represent the gazed object as a distinct entity, making it difficult to produce stable and semantically consistent predictions in complex scenes. To address this, we propose a two-stage gaze estimation framework guided by object semantics, reformulating gaze target estimation as a hierarchical reasoning process. Our method incorporates object-level representations during feature encoding to align image features with discrete semantic entities, then introduces multi-scale feature fusion and geometric constraints from head pose and gaze direction for fine-grained localization and object-level discrimination. Extensive experiments on GazeFollow, VideoAttentionTarget, ChildPlay, and GOO-Real demonstrate that our method achieves AUC of 0.961, 0.948, 0.987, and 0.977 respectively, delivering strong performance across all benchmarks while maintaining a compact parameter size of 7.1M.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-stage gaze target estimation framework that reformulates the task as hierarchical reasoning guided by object semantics. It incorporates object-level representations during feature encoding to align image features with discrete semantic entities, followed by multi-scale feature fusion and geometric constraints derived from head pose and gaze direction. Experiments on GazeFollow, VideoAttentionTarget, ChildPlay, and GOO-Real report AUC scores of 0.961, 0.948, 0.987, and 0.977 respectively, with a model size of 7.1M parameters.
Significance. If the central premise holds—that explicit object-level representations during encoding yield stable, semantically consistent predictions superior to pixel-level regression—the work could advance gaze estimation in complex scenes by emphasizing object-oriented attention. The compact parameter count is a noted strength, but the absence of derivation details, ablations, or error analysis in the provided description limits assessment of whether the reported AUC gains are attributable to the proposed components.
major comments (2)
- [Abstract] Abstract: the claim that incorporating 'object-level representations during feature encoding' produces stable semantic predictions is load-bearing, yet no description is given of the upstream object detector/segmenter architecture, its training, or how false positives, negatives, or boundary errors propagate through multi-scale fusion and geometric constraints. Without this, the hierarchical reasoning premise cannot be evaluated.
- [Abstract] Abstract: performance numbers (AUC 0.961/0.948/0.987/0.977) are stated without accompanying baseline comparisons, ablation studies on the object-representation stage, or error analysis, making it impossible to determine whether the data support the superiority claim over existing pixel-level methods.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each major comment below, clarifying the content of the full paper while noting where revisions to the abstract may be appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that incorporating 'object-level representations during feature encoding' produces stable semantic predictions is load-bearing, yet no description is given of the upstream object detector/segmenter architecture, its training, or how false positives, negatives, or boundary errors propagate through multi-scale fusion and geometric constraints. Without this, the hierarchical reasoning premise cannot be evaluated.
Authors: The abstract is a concise summary and does not include implementation specifics. The full manuscript details the object detector in Section 3.1 as a pre-trained instance segmentation network (Mask R-CNN) initialized on COCO and fine-tuned on gaze datasets, with the multi-scale fusion and geometric constraints described in Sections 3.2–3.3. Sensitivity to detection errors is examined via controlled ablations in Section 5.3. We will revise the abstract to briefly note the use of a standard pre-trained detector. revision: partial
-
Referee: [Abstract] Abstract: performance numbers (AUC 0.961/0.948/0.987/0.977) are stated without accompanying baseline comparisons, ablation studies on the object-representation stage, or error analysis, making it impossible to determine whether the data support the superiority claim over existing pixel-level methods.
Authors: The reported AUC values summarize results from the complete experimental section. The manuscript contains direct baseline comparisons in Table 2, ablations isolating the object-representation stage in Table 4, and error analysis in Section 5.2. These elements collectively support the claims regarding improvements over pixel-level regression approaches. The abstract format precludes including all supporting data; we do not believe a revision to embed tables or full ablations in the abstract is necessary. revision: no
Circularity Check
No circularity; empirical framework with external benchmark validation
full rationale
The abstract and reader's summary describe a two-stage framework that incorporates object-level representations, multi-scale fusion, and geometric constraints, then reports AUC scores on four independent public benchmarks (GazeFollow, VideoAttentionTarget, ChildPlay, GOO-Real). No equations, fitted parameters, or self-citations are referenced that would reduce any reported result to an input by construction. The central claim is an empirical assertion about the benefit of object semantics, which is tested against external data rather than defined into existence. The unspecified object detector is a methodological gap but does not create a definitional loop or fitted-input prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Human-Robot Interaction6(1), 25–63 (2017)
Admoni, H., Scassellati, B.: Social eye gaze in human-robot interaction: a review. Journal of Human-Robot Interaction6(1), 25–63 (2017)
2017
-
[2]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Arreghini, S., Abbate, G., Giusti, A., Paolillo, A.: Predicting the intention to in- teract with a service robot: the role of gaze cues. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 993–999. IEEE (2024)
2024
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bao, J., Liu, B., Yu, J.: Escnet: Gaze target detection with the understanding of 3d scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14126–14135 (2022)
2022
-
[4]
ACM Computing Surveys56(5), 1–41 (2023)
Beyan, C., Vinciarelli, A., Bue, A.D.: Co-located human–human interaction anal- ysis using nonverbal cues: A survey. ACM Computing Surveys56(5), 1–41 (2023)
2023
-
[5]
Frontiers in psychology10, 560 (2019)
Cañigueral, R., Hamilton, A.F.d.C.: The role of eye gaze during natural social interactions in typical and autistic people. Frontiers in psychology10, 560 (2019)
2019
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[7]
Controlling Decision Drift in Multimodal Sentiment Analysis with Missing Modalities
Chen, C., Cao, Y., Liu, X., Song, M., Zhang, G., Yu, X.: Controlling decision drift in multimodal sentiment analysis with missing modalities. arXiv preprint arXiv:2605.16889 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
IEEE Transactions on Multimedia (2025)
Chen, W., Chai, Y., Wu, X.J., Zhu, H., Yu, Q., Du, Z.M., Han, F., Gao, W., Zheng, C., Fan, H.: Privileged information-guided multitask mutualistic transformer for gaze prediction. IEEE Transactions on Multimedia (2025)
2025
-
[9]
IEEE Transactions on Circuits and Systems for Video Technology32(3), 1390–1402 (2021)
Chen, W., Xu, H., Zhu, C., Liu, X., Lu, Y., Zheng, C., Kong, J.: Gaze estimation via the joint modeling of multiple cues. IEEE Transactions on Circuits and Systems for Video Technology32(3), 1390–1402 (2021)
2021
-
[10]
In: Proceedings of the European conference on computer vision (ECCV)
Chong, E., Ruiz, N., Wang, Y., Zhang, Y., Rozga, A., Rehg, J.M.: Connecting gaze, scene, and attention: Generalized attention estimation via joint modeling of gaze and scene saliency. In: Proceedings of the European conference on computer vision (ECCV). pp. 383–398 (2018)
2018
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chong, E., Wang, Y., Ruiz, N., Rehg, J.M.: Detecting attended visual targets in video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5396–5406 (2020) 16 J. Mi et al
2020
-
[12]
IEEE Transactions on Intelli- gent Transportation Systems17(7), 2051–2062 (2016)
Deng, T., Yang, K., Li, Y., Yan, H.: Where does the driver look? top-down-based saliency detection in a traffic driving environment. IEEE Transactions on Intelli- gent Transportation Systems17(7), 2051–2062 (2016)
2051
-
[13]
(No Title) (2014)
Diederik, K.: Adam: A method for stochastic optimization. (No Title) (2014)
2014
-
[14]
Neuroscience & biobehavioral reviews24(6), 581–604 (2000)
Emery, N.J.: The eyes have it: the neuroethology, function and evolution of social gaze. Neuroscience & biobehavioral reviews24(6), 581–604 (2000)
2000
-
[15]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Fan, L., Chen, Y., Wei, P., Wang, W., Zhu, S.C.: Inferring shared attention in social scene videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6460–6468 (2018)
2018
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fan, L., Wang, W., Huang, S., Tang, X., Zhu, S.C.: Understanding human gaze communication by spatio-temporal graph reasoning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5724–5733 (2019)
2019
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fang, Y., Tang, J., Shen, W., Shen, W., Gu, X., Song, L., Zhai, G.: Dual atten- tion guided gaze target detection in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11390–11399 (2021)
2021
-
[18]
In: Proceedings of the European conference on computer vision (ECCV)
Fischer, T., Chang, H.J., Demiris, Y.: Rt-gene: Real-time eye gaze estimation in natural environments. In: Proceedings of the European conference on computer vision (ECCV). pp. 334–352 (2018)
2018
-
[19]
Psychological bulletin133(4), 694 (2007)
Frischen, A., Bayliss, A.P., Tipper, S.P.: Gaze cueing of attention: visual attention, social cognition, and individual differences. Psychological bulletin133(4), 694 (2007)
2007
-
[20]
In: International Conference on Multimedia Modeling
Guan, J., Yin, L., Sun, J., Qi, S., Wang, X., Liao, Q.: Enhanced gaze following via object detection and human pose estimation. In: International Conference on Multimedia Modeling. pp. 502–513. Springer (2019)
2019
-
[21]
Advances in Neural Information Processing Systems37, 15646–15673 (2024)
Gupta,A.,Tafasca,S.,Farkhondeh,A.,Vuillecard,P.,Odobez,J.M.:Mtgs:Anovel framework for multi-person temporal gaze following and social gaze prediction. Advances in Neural Information Processing Systems37, 15646–15673 (2024)
2024
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gupta, A., Tafasca, S., Odobez, J.M.: A modular multimodal architecture for gaze target prediction: Application to privacy-sensitive settings. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5041–5050 (2022)
2022
-
[23]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[24]
In: 2021 IEEE international conference on robotics and automation (ICRA)
Holman, B., Anwar, A., Singh, A., Tec, M., Hart, J., Stone, P.: Watch where you’re going! gaze and head orientation as predictors for social robot navigation. In: 2021 IEEE international conference on robotics and automation (ICRA). pp. 3553–3559. IEEE (2021)
2021
-
[25]
Horanyi, N., Zheng, L., Chong, E., Leonardis, A., Chang, H.J.: Where are they looking in the 3d space? In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 2678–2687 (2023)
2023
-
[26]
IEEE Transactions on Circuits and Systems for Video Technology32(12), 8524–8536 (2022)
Hu, Z., Zhao, K., Zhou, B., Guo, H., Wu, S., Yang, Y., Liu, J.: Gaze target estima- tion inspired by interactive attention. IEEE Transactions on Circuits and Systems for Video Technology32(12), 8524–8536 (2022)
2022
-
[27]
Engineering Applications of Artificial Intelligence113, 104924 (2022)
Jin, T., Yu, Q., Zhu, S., Lin, Z., Ren, J., Zhou, Y., Song, W.: Depth-aware gaze- following via auxiliary networks for robotics. Engineering Applications of Artificial Intelligence113, 104924 (2022)
2022
-
[28]
Jin, Y., Guo, G., Wang, B.: Gatector+: A unified head-free framework for gaze object and gaze following prediction. arXiv preprint arXiv:2510.25301 (2025) Multi-scale Object-Aware Gaze Estimation via Geometric Reasoning 17
-
[29]
In: Pattern Recognition and Computer Vision: 8th Chinese Conference, PRCV 2025, Shanghai, China, October 15–18, 2025, Proceedings, Part VII
Lan, E., Yang, Y., Zhao, C., Liu, D.: Fgi-gaze: Gaze target detection. In: Pattern Recognition and Computer Vision: 8th Chinese Conference, PRCV 2025, Shanghai, China, October 15–18, 2025, Proceedings, Part VII. p. 471. Springer Nature (2026)
2025
-
[30]
Lian, D., Yu, Z., Gao, S.: Believe it or not, we know what you are looking at! In: Asian Conference on Computer Vision. pp. 35–50. Springer (2018)
2018
-
[31]
In: Proceedings of the 11th ACM symposium on eye tracking research & applications
Liu, C., Chen, Y., Tai, L., Ye, H., Liu, M., Shi, B.E.: A gaze model improves autonomous driving. In: Proceedings of the 11th ACM symposium on eye tracking research & applications. pp. 1–5 (2019)
2019
-
[32]
In: Pre- dictive Modeling in Biomedical Data Mining and Analysis, pp
Madhusanka, B., Ramadass, S., Rajagopal, P., Herath, H.: Biofeedback method for human–computer interaction to improve elder caring: Eye-gaze tracking. In: Pre- dictive Modeling in Biomedical Data Mining and Analysis, pp. 137–156. Elsevier (2022)
2022
-
[33]
In: Eye movement research: An introduction to its scientific foundations and applications, pp
Majaranta, P., Räihä, K.J., Hyrskykari, A., Špakov, O.: Eye movements and human-computer interaction. In: Eye movement research: An introduction to its scientific foundations and applications, pp. 971–1015. Springer (2019)
2019
-
[34]
arXiv preprint arXiv:2511.06348 (2025)
Mathew, A.M., Hermassi, H., Khalid, T., Khan, A.A., Souissi, R.: Gazevlm: A vision-language model for multi-task gaze understanding. arXiv preprint arXiv:2511.06348 (2025)
-
[35]
arXiv preprint arXiv:2504.19271 (2025)
Mathew, A.M., Khan, A.A., Khalid, T., Al-Tam, F., Souissi, R.: Leverag- ing multi-modal saliency and fusion for gaze target detection. arXiv preprint arXiv:2504.19271 (2025)
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Miao, Q., Golani, V.R., Xu, J., Dutta, P.P., Hoai, M., Samaras, D.: Multi-view gaze target estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5371–5381 (2025)
2025
-
[37]
In: European Confer- ence on Computer Vision
Miao, Q., Graikos, A., Zhang, J., Mondal, S., Hoai, M., Samaras, D.: Diffusion- refined vqa annotations for semi-supervised gaze following. In: European Confer- ence on Computer Vision. pp. 439–457. Springer (2024)
2024
-
[38]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Miao, Q., Hoai, M., Samaras, D.: Patch-level gaze distribution prediction for gaze following. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 880–889 (2023)
2023
-
[39]
Psychology Press (2014)
Moore, C., Dunham, P.J., Dunham, P.: Joint attention: Its origins and role in development. Psychology Press (2014)
2014
-
[40]
Nieva-Suárez, Á., Marron-Romera, M., Losada-Gutiérrez, C., Guardiola-Luna, I.: Towards fusing gaze estimation and object prediction: What are you looking at? Engineering Applications of Artificial Intelligence157, 111113 (2025)
2025
-
[41]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Prada, J.D.P., Lee, M.H., Song, C.: A gaze-speech system in mixed reality for human-robot interaction. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 7547–7553. IEEE (2023)
2023
-
[43]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Recasens, A., Khosla, A., Vondrick, C., Torralba, A.: Where are they looking? Advances in neural information processing systems28(2015)
2015
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ryan, F., Bati, A., Lee, S., Bolya, D., Hoffman, J., Rehg, J.M.: Gaze-lle: Gaze target estimation via large-scale learned encoders. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28874–28884 (2025) 18 J. Mi et al
2025
-
[46]
In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Saran, A., Majumdar, S., Short, E.S., Thomaz, A., Niekum, S.: Human gaze fol- lowing for human-robot interaction. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 8615–8621. IEEE (2018)
2018
-
[47]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Visual Intelligence2(1), 31 (2024)
Song, Y., Wang, X., Yao, J., Liu, W., Zhang, J., Xu, X.: Vitgaze: gaze following with interaction features in vision transformers. Visual Intelligence2(1), 31 (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF international conference on computer vision
Tafasca, S., Gupta, A., Odobez, J.M.: Childplay: A new benchmark for under- standing children’s gaze behaviour. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 20935–20946 (2023)
2023
-
[50]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Tafasca, S., Gupta, A., Odobez, J.M.: Sharingan: A transformer architecture for multi-person gaze following. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 2008–2017 (2024)
2008
-
[51]
First Language21(63), 245–264 (2001)
Thoermer, C., Sodian, B.: Preverbal infants’ understanding of referential gestures. First Language21(63), 245–264 (2001)
2001
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tomas, H., Reyes, M., Dionido, R., Ty, M., Mirando, J., Casimiro, J., Atienza, R., Guinto, R.: Goo: A dataset for gaze object prediction in retail environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3125–3133 (2021)
2021
-
[53]
In: Proceedings of the 2022 International Conference on Multimodal Interaction
Tonini, F., Beyan, C., Ricci, E.: Multimodal across domains gaze target detection. In: Proceedings of the 2022 International Conference on Multimodal Interaction. pp. 420–431 (2022)
2022
-
[54]
In: Proceedings of the IEEE/CVF international conference on computer vision
Tonini, F., Dall’Asen, N., Beyan, C., Ricci, E.: Object-aware gaze target detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 21860–21869 (2023)
2023
-
[55]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tu, D., Min, X., Duan, H., Guo, G., Zhai, G., Shen, W.: End-to-end human-gaze- target detection with transformers. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2192–2200. IEEE (2022)
2022
-
[56]
IEEE Transactions on Circuits and Systems for Video Technology34(5), 3271–3285 (2023)
Tu, D., Shen, W., Sun, W., Min, X., Zhai, G., Chen, C.: Un-gaze: A unified trans- former for joint gaze-location and gaze-object detection. IEEE Transactions on Circuits and Systems for Video Technology34(5), 3271–3285 (2023)
2023
-
[57]
IEEE Transactions on Cyber- netics (2026)
Wang, B., Guo, C., Cui, J., Xia, H., Guo, G., Li, Z.: Vl-htr: Learning human– target representation from vision–language model. IEEE Transactions on Cyber- netics (2026)
2026
-
[58]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, B., Guo, C., Jin, Y., Xia, H., Liu, N.: Transgop: Transformer-based gaze ob- ject prediction. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 10180–10188. No. 9 (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, B., Hu, T., Li, B., Chen, X., Zhang, Z.: Gatector: A unified framework for gaze object prediction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19588–19597 (2022)
2022
-
[60]
Visual Intelligence3(1), 26 (2025)
Yang, Y., Lu, F.: Gazellm: a plug-and-play zero-shot llm reasoning framework for boosting gaze target detection. Visual Intelligence3(1), 26 (2025)
2025
-
[61]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, Y., Yin, Y., Lu, F.: Gaze target detection by merging human attention and activity cues. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6585–6593 (2024)
2024
-
[62]
Yu, X., Li, Y., Zhang, Y., Zhao, H., Yang, Y., Tang, H., Song, Y., Hu, X., Qin, C., Yan, S., et al.: Anisotropic modality align. arXiv preprint arXiv:2605.07825 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
Yu, X., Xin, Y., Zhang, Y., Zhang, W., Liu, C., Zhao, H., Liu, C., Hu, X., Qiao, Z., Tang, H., et al.: Modality gap-driven subspace alignment training paradigm for multimodal large language models. arXiv preprint arXiv:2602.07026 (2026) Multi-scale Object-Aware Gaze Estimation via Geometric Reasoning 19
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
In: 2023 IEEE international conference on robotics and automation (ICRA)
Zhang, Q., Hu, Z., Song, Y., Pei, J., Liu, J.: The human gaze helps robots run bravely and efficiently in crowds. In: 2023 IEEE international conference on robotics and automation (ICRA). pp. 7540–7546. IEEE (2023)
2023
-
[65]
IEEE Transactions on Intelligent Transportation Systems24(11), 12716–12725 (2023)
Zhao, Y., Lei, C., Shen, Y., Du, Y., Chen, Q.: Improving autonomous vehicle visual perception by fusing human gaze and machine vision. IEEE Transactions on Intelligent Transportation Systems24(11), 12716–12725 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.