PowerOPD: Stabilizing On-Policy Distillation with Bounded Power Transformation
Pith reviewed 2026-06-27 03:36 UTC · model grok-4.3
The pith
PowerOPD bounds the log-ratio reward via Box-Cox power transformation to stabilize on-policy distillation in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
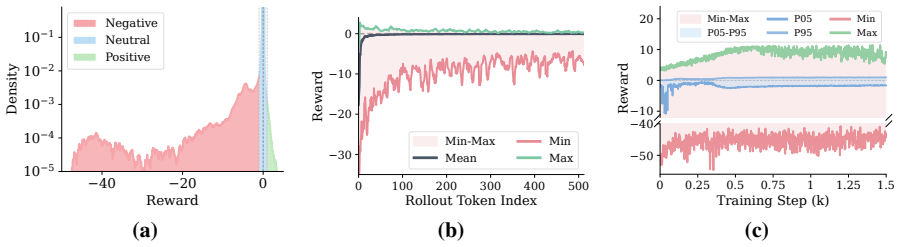
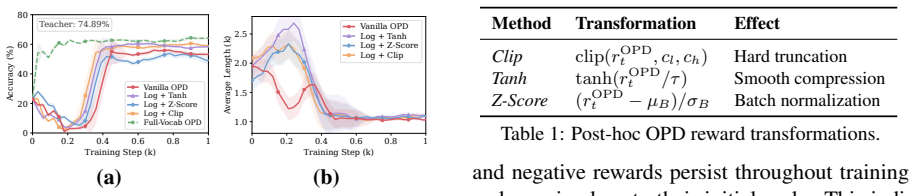
The paper establishes that the Box-Cox power transformation applied to the log-ratio produces a family of bounded rewards whose optimization remains aligned with the original distillation objective; these rewards eliminate the training pathologies of vanilla on-policy distillation and deliver measurable accuracy and efficiency improvements over both vanilla and post-hoc stabilized baselines as well as over full-vocabulary OPD.
What carries the argument
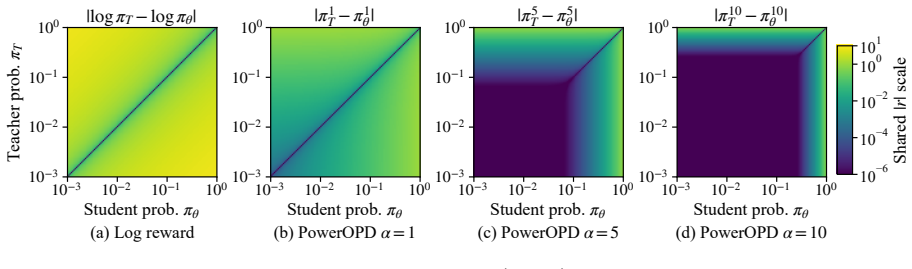
The Box-Cox power transformation (parameterized by alpha greater than zero) applied to the log-ratio reward, which yields bounded sign-consistent signals while recovering the original objective as alpha approaches zero.
If this is right
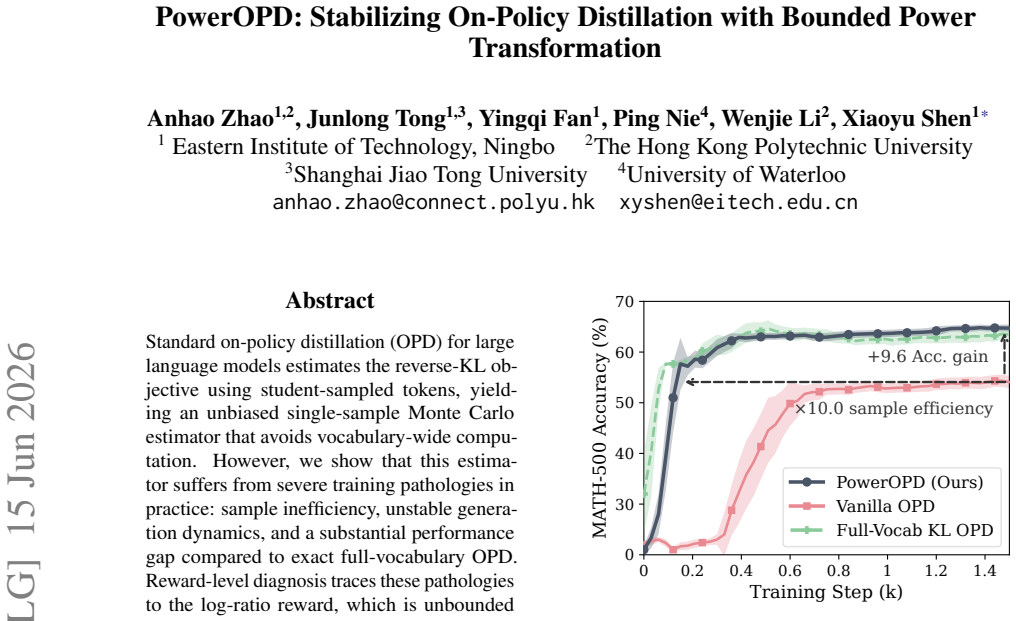
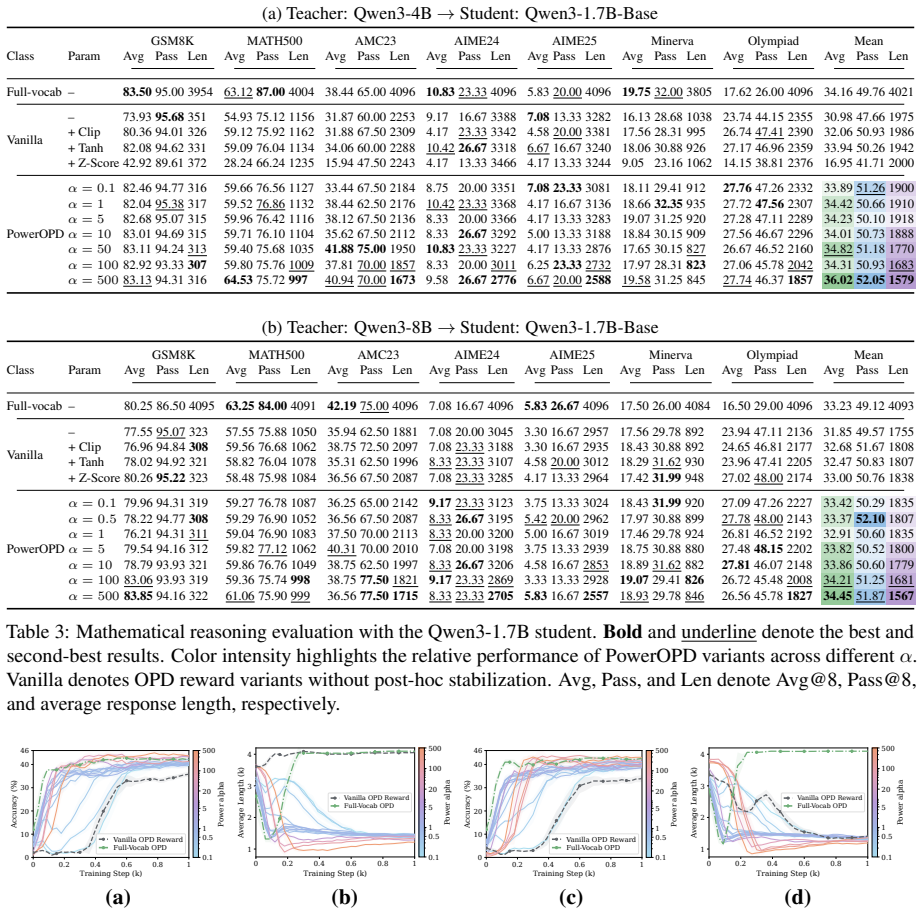
- PowerOPD produces benchmark-averaged Avg@8/Pass@8 gains of up to +6.37/+5.71 over vanilla OPD.
- It outperforms post-hoc stabilization by up to +3.01/+3.54 and full-vocabulary OPD by up to +2.59/+8.90 on the same averaged metrics.
- Wall-clock training time drops by 59.2 percent and peak GPU memory by 23.1 percent relative to vanilla OPD.
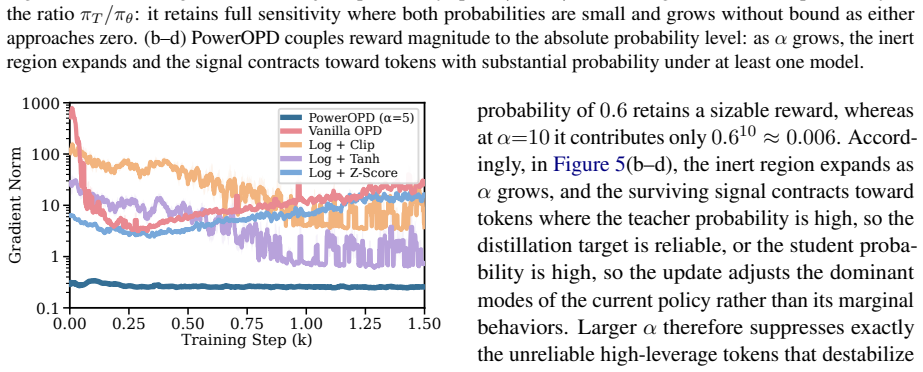
- Larger alpha values increase accuracy, shorten generated responses, and keep gradient norms more than 3,000 times smaller than vanilla OPD.
Where Pith is reading between the lines
- The same bounded-reward construction could be tested on non-math domains where on-policy distillation is currently unstable.
- Alpha may act as a tunable knob that trades off exploration breadth against response brevity.
- If the bounded reward removes the need for vocabulary-wide computation, it could make on-policy distillation practical for even larger teacher models.
Load-bearing premise
The transformed reward keeps the optimization target aligned with the original distillation objective without introducing bias or mode collapse.
What would settle it
A controlled run in which the same teacher-student pair is trained with PowerOPD and with vanilla OPD until both reach identical final accuracy, then checked whether response-length statistics and output diversity remain the same or diverge systematically.
Figures
read the original abstract
Standard on-policy distillation (OPD) for large language models estimates the reverse-KL objective using student-sampled tokens, yielding an unbiased single-sample Monte Carlo estimator that avoids vocabulary-wide computation. However, we show that this estimator suffers from severe training pathologies in practice: sample inefficiency, unstable generation dynamics, and a substantial performance gap compared to exact full-vocabulary OPD. Reward-level diagnosis traces these pathologies to the log-ratio reward, which is unbounded by construction, producing extremely high-variance gradients concentrated at early positions and persisting throughout training; standard post-hoc scaling fail as they operate only after this distortion occurs. To solve this problem, we propose PowerOPD: a family of natively bounded, sign-consistent rewards from the Box-Cox power transformation, parameterized by alpha > 0, of which the log-ratio is the degenerate alpha -> 0 limit. Across six mathematical reasoning benchmarks and four Qwen3 teacher-student pairs, PowerOPD achieves benchmark-averaged Avg@8/Pass@8 gains of up to +6.37/+5.71 over vanilla OPD, +3.01/+3.54 over post-hoc stabilization, and +2.59/+8.90 over full-vocabulary OPD, while reducing wall-clock time by 59.2% and peak GPU memory by 23.1%. Larger alpha generally improves accuracy, consistently shortens responses, and keeps gradient norms more than 3,000x smaller than vanilla OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PowerOPD, which replaces the unbounded log-ratio reward in on-policy distillation (OPD) with a bounded Box-Cox power transformation (parameterized by alpha > 0) of the log-ratio. It claims this stabilizes the unbiased single-sample Monte Carlo estimator of the reverse-KL objective without changing the optimization target, yielding benchmark-averaged gains of up to +6.37/+5.71 Avg@8/Pass@8 over vanilla OPD, +3.01/+3.54 over post-hoc stabilization, and +2.59/+8.90 over exact full-vocabulary OPD across six math reasoning benchmarks and four Qwen3 pairs, plus 59.2% wall-clock and 23.1% memory reductions, with larger alpha improving accuracy and shrinking gradient norms.
Significance. If the transformation stabilizes the original reverse-KL estimator while preserving its optimum, the approach would offer a practical, efficient alternative to full-vocabulary computation for on-policy distillation. The multi-benchmark empirical results and efficiency claims would then represent a meaningful engineering contribution, particularly if accompanied by ablations and variance reporting.
major comments (2)
- [Abstract] Abstract: the reported +2.59/+8.90 Avg@8/Pass@8 gains over full-vocabulary OPD (the exact reverse-KL objective) directly contradict the central claim that the Box-Cox transform (alpha > 0) merely stabilizes the original estimator without altering its optimization target; outperformance over the exact method indicates the transformed reward produces a different policy optimum.
- [Abstract] Abstract: no derivation is supplied showing that the Box-Cox reward (alpha > 0) yields an objective whose stationary points coincide with those of the original reverse-KL; the statement that the log-ratio is the alpha -> 0 limit does not establish equivalence for finite alpha, which is required to interpret the benchmark gains as stabilization rather than objective modification.
minor comments (1)
- [Abstract] Abstract: performance numbers are stated without reference to experimental protocol, number of runs, variance estimates, or ablation details on alpha selection; these should be summarized even at abstract level for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the abstract. We agree that the reported gains over exact full-vocabulary OPD indicate a change in the optimization target for finite alpha, and we will revise the manuscript accordingly to remove any implication of equivalence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported +2.59/+8.90 Avg@8/Pass@8 gains over full-vocabulary OPD (the exact reverse-KL objective) directly contradict the central claim that the Box-Cox transform (alpha > 0) merely stabilizes the original estimator without altering its optimization target; outperformance over the exact method indicates the transformed reward produces a different policy optimum.
Authors: We acknowledge the inconsistency. The superior performance over exact full-vocabulary OPD demonstrates that the Box-Cox reward (alpha > 0) produces a different policy optimum. The central claim in the abstract that the method stabilizes the estimator 'without changing the optimization target' is therefore inaccurate for finite alpha. We will revise the abstract to state that PowerOPD optimizes a Box-Cox transformed objective whose limit as alpha -> 0 recovers the original reverse-KL, and that the empirical gains arise from the modified objective's improved numerical properties rather than from preserving the original target. revision: yes
-
Referee: [Abstract] Abstract: no derivation is supplied showing that the Box-Cox reward (alpha > 0) yields an objective whose stationary points coincide with those of the original reverse-KL; the statement that the log-ratio is the alpha -> 0 limit does not establish equivalence for finite alpha, which is required to interpret the benchmark gains as stabilization rather than objective modification.
Authors: We agree that no derivation of coinciding stationary points is (or can be) supplied, because the objectives are not equivalent for finite alpha. The alpha -> 0 limit statement applies only in the degenerate case and does not establish equivalence. We will revise the abstract and relevant sections to explicitly clarify that the transformed objective differs from the original reverse-KL for alpha > 0, and that benchmark improvements should be interpreted as resulting from optimization of this alternative objective with bounded rewards. revision: yes
Circularity Check
No circularity detected; PowerOPD is a direct application of Box-Cox to the existing log-ratio reward
full rationale
The paper defines PowerOPD by applying the known Box-Cox family (alpha > 0) to the log-ratio reward from the reverse-KL objective, explicitly noting that the original log-ratio is recovered as the alpha -> 0 limit. This is a standard mathematical parameterization with no equations that define the transformed reward in terms of the paper's own fitted outputs, predictions, or benchmark results. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify the core construction. Empirical gains over vanilla OPD, post-hoc methods, and full-vocabulary OPD are reported as separate experimental outcomes and do not reduce the method itself to a fit or renaming by construction. The derivation chain is therefore self-contained as an empirical stabilization technique.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (1)
- domain assumption The Box-Cox power transformation applied to the log-ratio yields a family of rewards that remain sign-consistent for alpha > 0.
Reference graph
Works this paper leans on
-
[1]
Journal of the Royal Statistical Society: Series B (Methodological) , volume =
An Analysis of Transformations , author =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =
-
[2]
2024 , url =
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle =. 2024 , url =
2024
-
[3]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[4]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Unveiling the key factors for distilling chain-of-thought reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[5]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[6]
arXiv preprint arXiv:2505.09388 , year =
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
-
[7]
arXiv preprint arXiv:2602.15763 , year =
-
[8]
Nemotron-Cascade 2: Post-Training
Zhuolin Yang and Zihan Liu and Yang Chen and Wenliang Dai and Boxin Wang and Sheng-Chieh Lin and Chankyu Lee and Yangyi Chen and Dongfu Jiang and Jiafan He and Renjie Pi and Grace Lam and Nayeon Lee and Alexander Bukharin and Mohammad Shoeybi and Bryan Catanzaro and Wei Ping , journal =. Nemotron-Cascade 2: Post-Training. 2026 , url =
2026
-
[9]
Technical Report , year =
-
[10]
2025 , eprint=
HY-MT1.5 Technical Report , author=. 2025 , eprint=
2025
-
[11]
2026 , eprint=
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents , author=. 2026 , eprint=
2026
-
[12]
2026 , eprint=
MiMo-V2-Flash Technical Report , author=. 2026 , eprint=
2026
-
[13]
2026 , eprint=
KAT-Coder-V2 Technical Report , author=. 2026 , eprint=
2026
-
[14]
2026 , eprint=
Qwen3.5-Omni Technical Report , author=. 2026 , eprint=
2026
-
[15]
arXiv preprint arXiv:2601.07155 , year =
Stable On-Policy Distillation through Adaptive Target Reformulation , author =. arXiv preprint arXiv:2601.07155 , year =
-
[16]
arXiv preprint arXiv:2603.07079 , year =
Entropy-Aware On-Policy Distillation of Language Models , author =. arXiv preprint arXiv:2603.07079 , year =
-
[17]
arXiv preprint arXiv:2603.11137 , year =
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation , author =. arXiv preprint arXiv:2603.11137 , year =
-
[18]
arXiv preprint arXiv:2603.25562 , year =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. arXiv preprint arXiv:2603.25562 , year =
-
[19]
Demystifying
Feng Luo and Yu-Neng Chuang and Guanchu Wang and Zicheng Xu and Xiaotian Han and Tianyi Zhang and Vladimir Braverman , journal =. Demystifying. 2026 , url =
2026
-
[20]
2026 , eprint=
Prefix Teach, Suffix Fade: Local Teachability Collapse in Strong-to-Weak On-Policy Distillation , author=. 2026 , eprint=
2026
-
[21]
2026 , url =
Binbin Zheng and Xing Ma and Yiheng Liang and Jingqing Ruan and Xiaoliang Fu and Kepeng Lin and Benchang Zhu and Ke Zeng and Xunliang Cai , journal =. 2026 , url =
2026
-
[22]
arXiv preprint arXiv:2604.13016 , year =
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author =. arXiv preprint arXiv:2604.13016 , year =
-
[23]
2026 , url =
Yuanda Xu and Hejian Sang and Zhengze Zhou and Ran He and Zhipeng Wang and Alborz Geramifard , journal =. 2026 , url =
2026
-
[24]
2026 , url =
Wenjin Hou and Shangpin Peng and Weinong Wang and Zheng Ruan and Yue Zhang and Zhenglin Zhou and Mingqi Gao and Yifei Chen and Kaiqi Wang and Hongming Yang and Chengquan Zhang and Zhuotao Tian and Han Hu and Yi Yang and Fei Wu and Hehe Fan , journal =. 2026 , url =
2026
-
[25]
2026 , eprint=
Decoupling KL and Trajectories: A Unified Perspective for SFT, DAgger, Offline RL, and OPD in LLM Distillation , author=. 2026 , eprint=
2026
-
[26]
arXiv preprint arXiv:2605.06387 , year =
Asymmetric On-Policy Distillation: Bridging Exploitation and Imitation at the Token Level , author =. arXiv preprint arXiv:2605.06387 , year =
-
[27]
2026 , url =
Minjae Oh and Sangjun Song and Gyubin Choi and Yunho Choi and Yohan Jo , journal =. 2026 , url =
2026
-
[28]
2026 , url =
Zhicheng Yang and Zhijiang Guo and Yifan Song and Minrui Xu and Yongxin Wang and Yiwei Wang and Xiaodan Liang and Jing Tang , journal =. 2026 , url =
2026
-
[29]
arXiv preprint arXiv:2605.05940 , year =
Near-Policy: Accelerating On-Policy Distillation via Asynchronous Generation and Selective Packing , author =. arXiv preprint arXiv:2605.05940 , year =
-
[30]
arXiv preprint arXiv:2604.00626 , year =
A Survey of On-Policy Distillation for Large Language Models , author =. arXiv preprint arXiv:2604.00626 , year =
-
[31]
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL , author=
-
[32]
2022 , eprint=
Solving Quantitative Reasoning Problems with Language Models , author=. 2022 , eprint=
2022
-
[33]
2024 , eprint=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. 2024 , eprint=
2024
-
[34]
Measuring mathematical problem solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle=. Measuring mathematical problem solving with the. 2021 , url=
2021
-
[35]
International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. International Conference on Learning Representations , year=
-
[36]
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , url =
Bengio, Samy and Vinyals, Oriol and Jaitly, Navdeep and Shazeer, Noam , booktitle =. Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , url =
-
[37]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[38]
arXiv preprint arXiv:2006.05990 , year=
What matters in on-policy reinforcement learning? a large-scale empirical study , author=. arXiv preprint arXiv:2006.05990 , year=
arXiv 2006
-
[39]
Machine Learning , volume =
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =
-
[40]
Journal of Machine Learning Research , year=
Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning , author=. Journal of Machine Learning Research , year=
-
[41]
2018 , eprint=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. 2018 , eprint=
2018
-
[42]
NIPS Deep Learning and Representation Learning Workshop , year =
Distilling the Knowledge in a Neural Network , author =. NIPS Deep Learning and Representation Learning Workshop , year =
-
[43]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
-
[44]
2025 , url =
On-Policy Distillation , author =. 2025 , url =
2025
-
[45]
Policy Gradient Methods for Reinforcement Learning with Function Approximation , url =
Sutton, Richard S and McAllester, David and Singh, Satinder and Mansour, Yishay , booktitle =. Policy Gradient Methods for Reinforcement Learning with Function Approximation , url =
-
[46]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[47]
DeepSeek-AI , year=. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , volume=. Nature , publisher=. doi:10.1038/s41586-025-09422-z , number=
-
[48]
2026 , eprint=
OPD+: Rethinking the Advantage Design for On-Policy Distillation , author=. 2026 , eprint=
2026
-
[49]
2026 , eprint=
Teacher-Guided Policy Optimization for On-Policy Reasoning Distillation under Large Policy Divergence , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.