EQuANt (Enhanced Question Answer Network)
Pith reviewed 2026-05-25 17:52 UTC · model grok-4.3
The pith
EQuANt extends QANet to detect unanswerable questions and nearly doubles performance over a lightweight baseline on SQuAD 2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EQuANt shows it is possible to extend QANet to the unanswerable domain, achieving results close to 2 times better than a lightweight QANet baseline on SQuAD 2 while also demonstrating that training on SQuAD 2 boosts performance on SQuAD 1.1 over training only on SQuAD 1.1.
What carries the argument
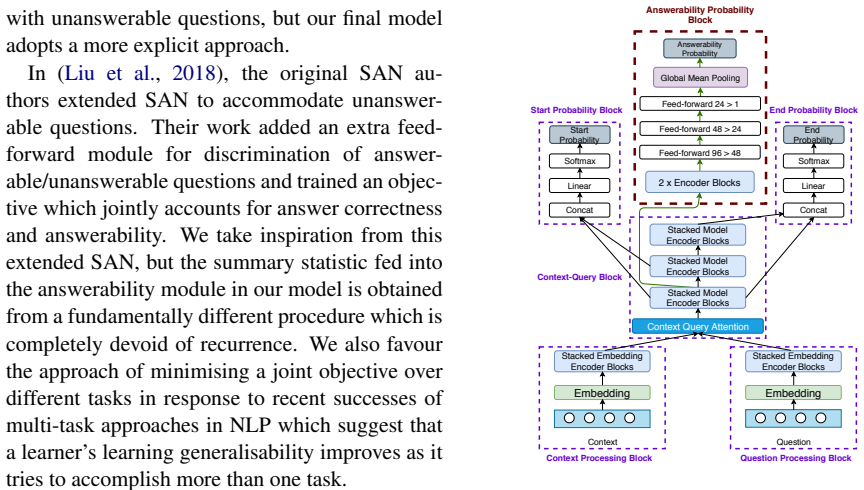
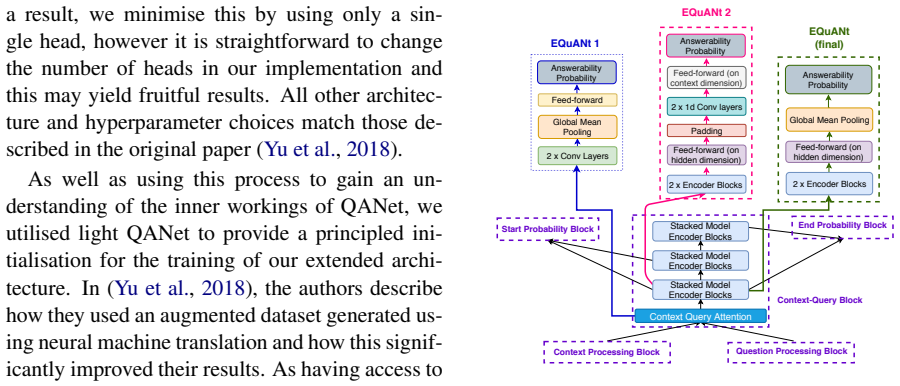
Specific architectural extensions added to the original QANet model to enable detection and handling of unanswerable questions.
If this is right
- EQuANt reaches nearly double the score of the lightweight QANet baseline on SQuAD 2.
- Training EQuANt on SQuAD 2 improves its results when tested on SQuAD 1.1 compared with training only on SQuAD 1.1.
- Multi-task learning across answerable and unanswerable questions benefits model performance in machine reading comprehension.
- The same extension approach can be applied to other models that currently lack support for unanswerable questions.
Where Pith is reading between the lines
- The multi-task benefit observed here suggests similar gains could appear when mixing other question-answering datasets that differ in answerability.
- If the extensions generalize, they could be tested on newer reading-comprehension benchmarks that include unanswerable items.
- Further work could isolate which single extension contributes most to the improvement by ablating them one at a time.
Load-bearing premise
The chosen extensions to QANet are what allow it to handle unanswerable questions, and the lightweight QANet version is a fair baseline for comparison.
What would settle it
Running the original QANet or another unmodified baseline on SQuAD 2 and finding performance comparable to EQuANt would show the extensions did not drive the reported gains.
Figures

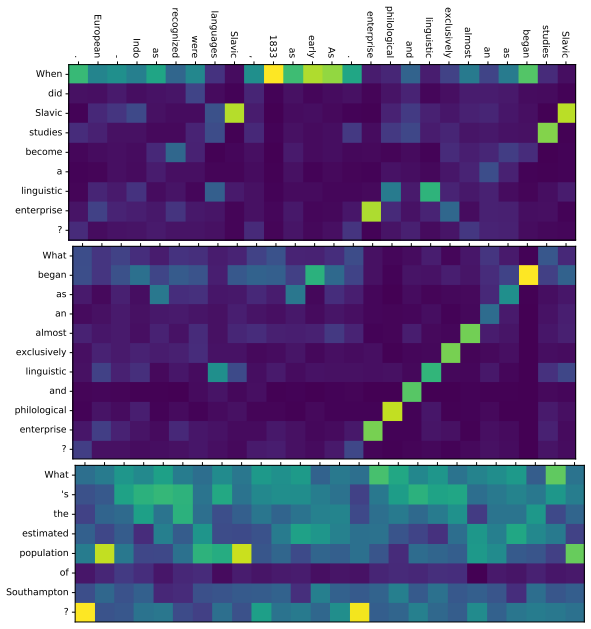
read the original abstract
Machine Reading Comprehension (MRC) is an important topic in the domain of automated question answering and in natural language processing more generally. Since the release of the SQuAD 1.1 and SQuAD 2 datasets, progress in the field has been particularly significant, with current state-of-the-art models now exhibiting near-human performance at both answering well-posed questions and detecting questions which are unanswerable given a corresponding context. In this work, we present Enhanced Question Answer Network (EQuANt), an MRC model which extends the successful QANet architecture of Yu et al. to cope with unanswerable questions. By training and evaluating EQuANt on SQuAD 2, we show that it is indeed possible to extend QANet to the unanswerable domain. We achieve results which are close to 2 times better than our chosen baseline obtained by evaluating a lightweight version of the original QANet architecture on SQuAD 2. In addition, we report that the performance of EQuANt on SQuAD 1.1 after being trained on SQuAD2 exceeds that of our lightweight QANet architecture trained and evaluated on SQuAD 1.1, demonstrating the utility of multi-task learning in the MRC context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EQuANt as an extension of the QANet architecture to address unanswerable questions in machine reading comprehension. It reports that training and evaluating EQuANt on SQuAD 2 yields performance close to twice that of a lightweight QANet baseline on the same dataset, and that multi-task training on SQuAD 2 improves EQuANt's results on SQuAD 1.1 relative to the lightweight baseline trained directly on SQuAD 1.1.
Significance. If the reported gains can be attributed to the proposed extensions rather than baseline capacity differences and are supported by full implementation details, the work would demonstrate a concrete adaptation of QANet for the unanswerable-question setting and highlight multi-task benefits across SQuAD variants. At present the absence of these details prevents evaluation of whether the central empirical claims hold.
major comments (3)
- [Abstract] Abstract: the headline claim that EQuANt achieves results 'close to 2 times better' than the baseline supplies neither the exact metric values (F1/EM), error bars, nor any numerical comparison; without these the central empirical result cannot be verified.
- [Abstract] Abstract: the baseline is characterized only as 'a lightweight version of the original QANet architecture' with no specification of the capacity reductions (layer count, hidden size, parameter count, or other architectural changes). This is load-bearing for the 2x improvement claim, because the observed gains could arise simply from restoring capacity that was removed in the baseline rather than from the unanswerable-question extensions.
- [Abstract] Abstract: no implementation details are provided for the modifications made to QANet, the training hyperparameters, or the exact procedure used to obtain the multi-task SQuAD 1.1 result; these omissions prevent assessment of whether the architectural extensions are sufficient to handle unanswerable questions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the abstract to incorporate the requested details for improved clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that EQuANt achieves results 'close to 2 times better' than the baseline supplies neither the exact metric values (F1/EM), error bars, nor any numerical comparison; without these the central empirical result cannot be verified.
Authors: We agree that the abstract should report the precise F1 and EM values for both EQuANt and the baseline on SQuAD 2, together with any available error bars from repeated runs and the direct numerical ratio. The revised abstract will include these exact figures and comparisons. revision: yes
-
Referee: [Abstract] Abstract: the baseline is characterized only as 'a lightweight version of the original QANet architecture' with no specification of the capacity reductions (layer count, hidden size, parameter count, or other architectural changes). This is load-bearing for the 2x improvement claim, because the observed gains could arise simply from restoring capacity that was removed in the baseline rather than from the unanswerable-question extensions.
Authors: The observation is correct. The revised abstract will explicitly state the capacity reductions used for the lightweight baseline, including layer count, hidden size, and resulting parameter count, to demonstrate that the reported gains stem from the proposed extensions. revision: yes
-
Referee: [Abstract] Abstract: no implementation details are provided for the modifications made to QANet, the training hyperparameters, or the exact procedure used to obtain the multi-task SQuAD 1.1 result; these omissions prevent assessment of whether the architectural extensions are sufficient to handle unanswerable questions.
Authors: We acknowledge the need for these details in the abstract. The revision will add a concise description of the QANet modifications for unanswerable questions, the training hyperparameters, and the multi-task procedure, while retaining full specifications in the methods section. revision: yes
Circularity Check
No significant circularity; empirical results on public benchmarks
full rationale
The paper describes an architectural extension to QANet and reports performance numbers obtained by training and evaluating on the public SQuAD 1.1 and SQuAD 2 benchmarks. No equations, fitted parameters, or derivation steps are presented that reduce any reported quantity to a definition, a self-citation chain, or an input by construction. The comparison is against a separately implemented lightweight baseline; this is an empirical claim whose validity can be checked externally and does not collapse into self-reference. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EQuANt 3 ... two encoder transformations ... three feedforward layers ... global mean pooling ... answerability score
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
loss function ... L0(p0) + δ(L1(p1) + L2(p2)) ... Adam optimiser
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: pre-training of deep bidirectional transformers for language under- standing. CoRR, abs/1810.04805. Bhuwan Dhingra, Hanxiao Liu, William W. Cohen, and Ruslan Salakhutdinov
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gated-Attention Readers for Text Comprehension
Gated-attention read- ers for text comprehension. CoRR, abs/1606.01549. Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Goldilocks Principle: Reading Children's Books with Explicit Memory Representations
The goldilocks principle: Reading children’s books with explicit memory representa- tions. CoRR, abs/1511.02301. Minghao Hu, Furu Wei, Yuxing Peng, Zhen Huang, Nan Yang, and Ming Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
Read + verify: Machine reading comprehension with unanswerable questions. CoRR, abs/1808.05759. Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Zero-Shot Relation Extraction via Reading Comprehension
Zero-shot relation extraction via reading comprehension. CoRR, abs/1706.04115. Xiaodong Liu, Wei Li, Yuwei Fang, Aerin Kim, Kevin Duh, and Jianfeng Gao
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Stochastic Answer Networks for SQuAD 2.0
Stochastic answer networks for squad 2.0. CoRR, abs/1809.09194. Xiaodong Liu, Yelong Shen, Kevin Duh, and Jianfeng Gao
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Stochastic Answer Networks for Machine Reading Comprehension
Stochastic answer networks for machine reading comprehension. CoRR, abs/1712.03556. Jeffrey Pennington, Richard Socher, and Christo- pher D. Manning
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Know What You Don't Know: Unanswerable Questions for SQuAD
Know what you don’t know: Unanswerable ques- tions for squad. CoRR, abs/1806.03822. Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Squad: 100, 000+ ques- tions for machine comprehension of text. CoRR, abs/1606.05250. Min Joon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Bidirectional Attention Flow for Machine Comprehension
Bidirectional at- tention flow for machine comprehension. CoRR, abs/1611.01603. Fu Sun, Linyang Li, Xipeng Qiu, and Yang Liu
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
U-Net: Machine Reading Comprehension with Unanswerable Questions
U-net: Machine reading comprehension with unan- swerable questions. CoRR, abs/1810.06638. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
Qanet: Combining local convolution with global self-attention for reading comprehen- sion. CoRR, abs/1804.09541
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.