Has This Checkpoint Been Abliterated? A Two-Signal Audit and Its Failure Map
Pith reviewed 2026-07-03 10:51 UTC · model grok-4.3
The pith
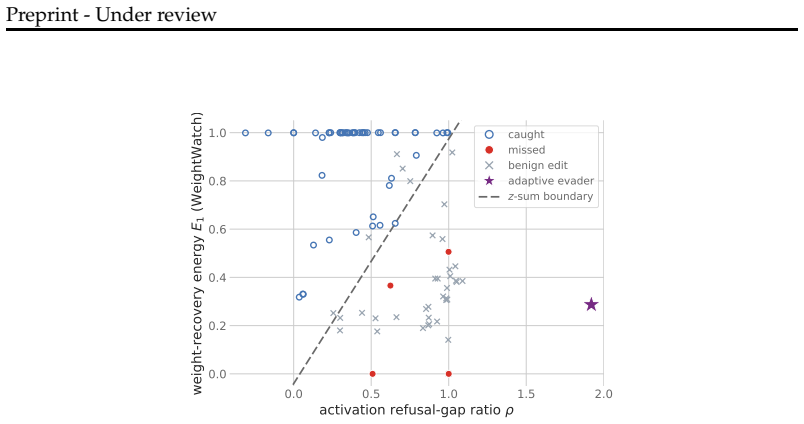
A z-sum of refusal-gap and weight energy detects abliterated checkpoints at AUROC 0.95 on 273 models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the z-sum of a reference-anchored activation refusal-gap and the weight-recovery energy of the base-to-candidate weight difference separates 57 public abliterations from 37 benign fine-tunes, merges, and instruction-tunes on a 273-checkpoint registry at AUROC 0.95, significantly above the individual signals at 0.84 and 0.90, and that a Youden-calibrated threshold transfers to held-out families at balanced accuracy 0.89 with FPR 0.11. The paper further maps two failure cases in order of severity: a spoofed reference evades both axes with ΔW=0 and correlation 1 by construction, and a white-box owner can train a checkpoint past the threshold while it remains guard-unsa
What carries the argument
The two-signal z-sum audit formed from a reference-anchored activation refusal-gap and base-to-candidate weight-recovery energy.
If this is right
- The combined z-sum outperforms the refusal-gap alone (AUROC 0.84) and the weight energy alone (AUROC 0.90).
- A Youden-calibrated threshold achieves balanced accuracy 0.89 and FPR 0.11 on held-out model families.
- Only four of the 57 abliterations fall below the threshold.
- A spoofed reference produces ΔW=0 and correlation 1, evading both signals by construction.
- A white-box owner can push a checkpoint past the threshold while it stays guard-unsafe.
Where Pith is reading between the lines
- Platforms hosting open weights could run the audit as an automated pre-upload check.
- Some form of reference-model attestation would be needed to block the identified spoofing failure.
- The same two-signal structure might be tested on other safety properties beyond refusal.
- Adding a third orthogonal signal could raise robustness against an adaptive white-box adversary.
Load-bearing premise
The audit requires access to an attested, non-spoofed reference model.
What would settle it
An abliterated checkpoint that scores below the Youden threshold on the z-sum when measured against a genuine reference model, or a non-abliterated checkpoint that scores above it, would falsify the separation claim.
Figures


read the original abstract
Can a platform tell, before deployment, whether an open-weight checkpoint has had its refusal mechanism stripped? Runtime guards cannot: they score generations, not the artifact. We combine two cheap internal signals, a reference-anchored activation refusal-gap and a weight-recovery energy of the base-to-candidate weight difference, into a threshold-free checkpoint audit. The two are negatively correlated and label-complementary: the gap supplies refusal-specificity and the weight energy supplies recall. On a 273-checkpoint registry spanning Qwen, DeepSeek-distilled Qwen, Llama, and Gemma, their z-sum separates 57 public abliterations from 37 benign fine-tunes, merges, and instruction-tunes at AUROC 0.95, significantly above either signal alone (0.84, 0.90), and a Youden-calibrated threshold transfers to held-out families at balanced accuracy 0.89 (FPR 0.11), missing only 4 of 57. We then map two failures, in order of severity: a spoofed reference evades both axes with no training ({\Delta}W=0, \r{ho}=1 by construction), and a white-box owner trains a checkpoint past the threshold while it stays guard-unsafe and coherent. The audit is effective triage, not tamper-proofing: it presumes an attested reference, and its claims are bounded by the registry we evaluate it on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-signal audit to detect whether an open-weight checkpoint has had its refusal mechanism abliterated. It combines a reference-anchored activation refusal-gap with a weight-recovery energy computed on the base-to-candidate weight difference; the signals are negatively correlated and label-complementary. On a 273-checkpoint registry spanning Qwen, DeepSeek-distilled Qwen, Llama, and Gemma families, the z-sum of the normalized signals separates 57 public abliterations from 37 benign fine-tunes, merges, and instruction-tunes at AUROC 0.95 (versus 0.84 and 0.90 for the individual signals). A Youden-calibrated threshold transfers to held-out families at balanced accuracy 0.89 (FPR 0.11), missing only 4 of 57 abliterations. The paper explicitly maps two failure modes: a spoofed reference that forces ΔW=0 and ρ=1 by construction, and white-box training that evades the threshold while remaining guard-unsafe. The method is presented as triage that presumes an attested reference model and is bounded by the evaluated registry.
Significance. If the reported separation holds, the work supplies a cheap, internal-signal triage tool that platforms could apply before deployment, improving on single-signal baselines and explicitly bounding its scope via the two documented failure cases. The held-out transfer result and the construction of the failure map (including the exact spoofed-reference construction) are concrete strengths that clarify applicability without overclaiming tamper-proofing.
major comments (1)
- [Abstract / Evaluation] Abstract and evaluation description: the Youden-calibrated threshold and the negative-correlation premise for the z-sum are both derived from the same 273-checkpoint registry used to report the AUROC of 0.95; while transfer performance on held-out families is stated at balanced accuracy 0.89, the absence of a separate calibration set or cross-validated threshold selection leaves the primary metric vulnerable to optimistic bias from data-dependent calibration.
minor comments (1)
- [Abstract / Methods] The abstract states that exact signal definitions and registry construction details are limited; expanding the methods section with precise formulas for the refusal-gap and weight-energy signals, plus explicit criteria for including checkpoints in the 273-item registry, would improve reproducibility without altering the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the positive overall assessment and for the specific comment on evaluation protocol. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the Youden-calibrated threshold and the negative-correlation premise for the z-sum are both derived from the same 273-checkpoint registry used to report the AUROC of 0.95; while transfer performance on held-out families is stated at balanced accuracy 0.89, the absence of a separate calibration set or cross-validated threshold selection leaves the primary metric vulnerable to optimistic bias from data-dependent calibration.
Authors: The AUROC of 0.95 is a ranking metric on the z-sum scores and does not depend on the Youden threshold; the threshold is used only for the secondary balanced-accuracy transfer result. The negative-correlation observation is an empirical finding on the registry that motivates the linear combination, but the z-sum itself is a fixed linear transform once the per-signal means and standard deviations are estimated. The held-out-family transfer applies the threshold fixed from the main registry, which is the standard protocol for assessing generalization. We agree that reporting a cross-validated threshold or an explicit train/calibration split would further strengthen the presentation. In revision we will add a sentence in the evaluation section clarifying that the primary reported figure is the threshold-independent AUROC, that normalization parameters are registry-wide, and that the transfer result uses a fixed threshold; we will also note the limitation that a fully nested cross-validation was not performed. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper reports direct empirical measurements: AUROC 0.95 for z-sum separation on the 273-checkpoint registry and balanced accuracy 0.89 for the Youden threshold on held-out families. The negative correlation observation and z-sum choice are data-driven but do not reduce any performance claim to a tautology or fitted input by construction. The spoofed-reference failure case is explicitly constructed as ΔW=0 and ρ=1, which the paper states outright rather than deriving as a result. No self-citations, uniqueness theorems, or ansatzes are invoked. The derivation chain consists of signal definitions, z-normalization, summation, and ROC evaluation on the stated registry and splits; these steps are self-contained against the external benchmark of the evaluated checkpoints and do not collapse to the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Youden threshold =
calibrated on registry
axioms (1)
- domain assumption The two signals are negatively correlated and label-complementary across model families
Reference graph
Works this paper leans on
-
[1]
An embarrassingly simple defense against LLM abliteration attacks, 2025
Harethah Abu Shairah, Hasan Abed Al Kader Hammoud, Bernard Ghanem, and George Turkiyyah. An embarrassingly simple defense against LLM abliteration attacks, 2025
2025
-
[2]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. In Advances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Obfuscated activations bypass LLM latent-space defenses, 2024
Luke Bailey, Alex Serrano, Abhay Sheshadri, Mikhail Seleznyov, Jordan Taylor, Erik Jenner, Jacob Hilton, Stephen Casper, Carlos Guestrin, and Scott Emmons. Obfuscated activations bypass LLM latent-space defenses, 2024
2024
-
[4]
Black-box access is insufficient for rigorous AI audits, 2024
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, J \'e r \'e my Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin Von Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. Black-box access...
2024
-
[5]
Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong. JailbreakBench : An open robustness benchmark for jailbreaking large language models, 2024. NeurIPS 2024 Datasets and Benchmarks
2024
-
[6]
Anthony Ray Coslett. Safety-alignment removal as a model-identity failure --- structural evidence from published weight-level mutation checkpoints, 2026. Fall Risk AI; Zenodo 10.5281/zenodo.19383019
-
[7]
What makes and breaks safety fine-tuning? a mechanistic study
Samyak Jain et al. What makes and breaks safety fine-tuning? a mechanistic study. In NeurIPS, 2024
2024
-
[8]
Uncensor any LLM with abliteration
Maxime Labonne. Uncensor any LLM with abliteration. Hugging Face blog, 2024. Coined ``abliteration''; weight orthogonalization against the refusal direction
2024
-
[9]
HarmBench : A standardized evaluation framework for automated red teaming and robust refusal, 2024
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench : A standardized evaluation framework for automated red teaming and robust refusal, 2024. ICML 2024
2024
-
[10]
Neural chameleons: Language models can learn to hide their thoughts from unseen activation monitors, 2025
Max McGuinness, Alex Serrano, Luke Bailey, and Scott Emmons. Neural chameleons: Language models can learn to hide their thoughts from unseen activation monitors, 2025. ICLR 2026 Workshop on Trustworthy AI
2025
-
[11]
AMS : Activation-based model scanner for open-weight LLM safety verification
Glen Messenger. AMS : Activation-based model scanner for open-weight LLM safety verification. Google Open Source Blog, 2026
2026
-
[12]
Heretic: Automated censorship removal for language models
p-e-w . Heretic: Automated censorship removal for language models. https://github.com/p-e-w/heretic, 2025. Optuna-tuned per-layer directional abliteration; 1000+ released checkpoints
2025
-
[13]
Daly, Michael Hind, Werner Geyer, Ambrish Rawat, Kush R
Inkit Padhi, Manish Nagireddy, Giandomenico Cornacchia, Subhajit Chaudhury, Tejaswini Pedapati, Pierre Dognin, Keerthiram Murugesan, Erik Miehling, Mart \'i n Santill \'a n Cooper, Kieran Fraser, Giulio Zizzo, Muhammad Zaid Hameed, Mark Purcell, Michael Desmond, Qian Pan, Inge Vejsbjerg, Elizabeth M. Daly, Michael Hind, Werner Geyer, Ambrish Rawat, Kush R...
2024
-
[14]
The hidden dimensions of LLM alignment: A multi-dimensional analysis of orthogonal safety directions
Wenbo Pan, Zhichao Liu, Qiguang Chen, Xiangyang Zhou, Haining Yu, and Xiaohua Jia. The hidden dimensions of LLM alignment: A multi-dimensional analysis of orthogonal safety directions. In International Conference on Machine Learning (ICML), 2025. arXiv:2502.09674
-
[15]
Preventing safety drift in large language models via coupled weight and activation constraints, 2026
Songping Peng, Zhiheng Zhang, Daojian Zeng, Lincheng Jiang, and Xieping Gao. Preventing safety drift in large language models via coupled weight and activation constraints, 2026. ACL 2026
2026
-
[16]
SOM directions are better than one: Multi-directional refusal suppression in language models, 2025
Giorgio Piras, Raffaele Mura, Fabio Brau, Luca Oneto, Fabio Roli, and Battista Biggio. SOM directions are better than one: Multi-directional refusal suppression in language models, 2025. AAAI 2026; Self-Organizing-Map extraction of multiple refusal directions. Code: https://github.com/pralab/som-refusal-directions
2025
-
[17]
Qwen3guard technical report, 2025
Qwen Team . Qwen3guard technical report, 2025. Generative Qwen3Guard-Gen-8B (Apache-2.0); emits per-response Safety and Refusal labels
2025
-
[18]
Open problems in technical AI governance, 2024
Anka Reuel, Ben Bucknall, Stephen Casper, et al. Open problems in technical AI governance, 2024
2024
-
[19]
Model evaluation for extreme risks, 2023
Toby Shevlane et al. Model evaluation for extreme risks, 2023. arXiv:2305.15324; dangerous-capability vs alignment/propensity evaluation pillars
-
[20]
COSMIC : Generalized refusal direction identification in LLM activations
Vincent Siu, Nicholas Crispino, Zihao Yu, Sam Pan, Zhun Wang, Yang Liu, Dawn Song, and Chenguang Wang. COSMIC : Generalized refusal direction identification in LLM activations. In Findings of the Association for Computational Linguistics: ACL, 2025
2025
-
[21]
Tamper-resistant safeguards for open-weight LLM s, 2024
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, Andy Zou, Dawn Song, Bo Li, Dan Hendrycks, and Mantas Mazeika. Tamper-resistant safeguards for open-weight LLM s, 2024. ICLR 2025
2024
-
[22]
The geometry of refusal in large language models: Concept cones and representational independence, 2025
Tom Wollschl \"a ger et al. The geometry of refusal in large language models: Concept cones and representational independence, 2025
2025
-
[23]
Zhenyu Xu and Victor S. Sheng. A behavioral fingerprint for large language models: Provenance tracking via refusal vectors, 2026
2026
-
[24]
Where do reasoning models refuse?, 2025
Kureha Yamaguchi, Benjamin Etheridge, and Andy Arditi. Where do reasoning models refuse?, 2025. ICML 2025 Workshop on Reliable and Responsible Foundation Models (R2FM)
2025
-
[25]
Refusal falls off a cliff: How safety alignment fails in reasoning?, 2025
Qingyu Yin, Chak Tou Leong, Wenxuan Huang, Wenjie Li, Linyi Yang, Xiting Wang, Jaehong Yoon, YunXing , XingYu , and Jinjin Gu. Refusal falls off a cliff: How safety alignment fails in reasoning?, 2025
2025
-
[26]
Richard J. Young. Comparative analysis of LLM abliteration methods: A cross-architecture evaluation, 2025
2025
-
[27]
LLMs encode harmfulness and refusal separately, 2025 a
Jiachen Zhao, Jing Huang, Zhengxuan Wu, David Bau, and Weiyan Shi. LLMs encode harmfulness and refusal separately, 2025 a . NeurIPS 2025
2025
-
[28]
Chain-of-thought hijacking, 2025 b
Jianli Zhao, Tingchen Fu, Rylan Schaeffer, Mrinank Sharma, and Fazl Barez. Chain-of-thought hijacking, 2025 b
2025
-
[29]
Watch the weights: Unsupervised monitoring and control of fine-tuned LLM s, 2025
Ziqian Zhong and Aditi Raghunathan. Watch the weights: Unsupervised monitoring and control of fine-tuned LLM s, 2025. ICLR 2026
2025
-
[30]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to A...
2023
-
[31]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023 b . AdvBench harmful-behaviors set
2023
-
[32]
Zico Kolter, Matt Fredrikson, and Dan Hendrycks
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, J. Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving alignment and robustness with circuit breakers, 2024. NeurIPS 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.