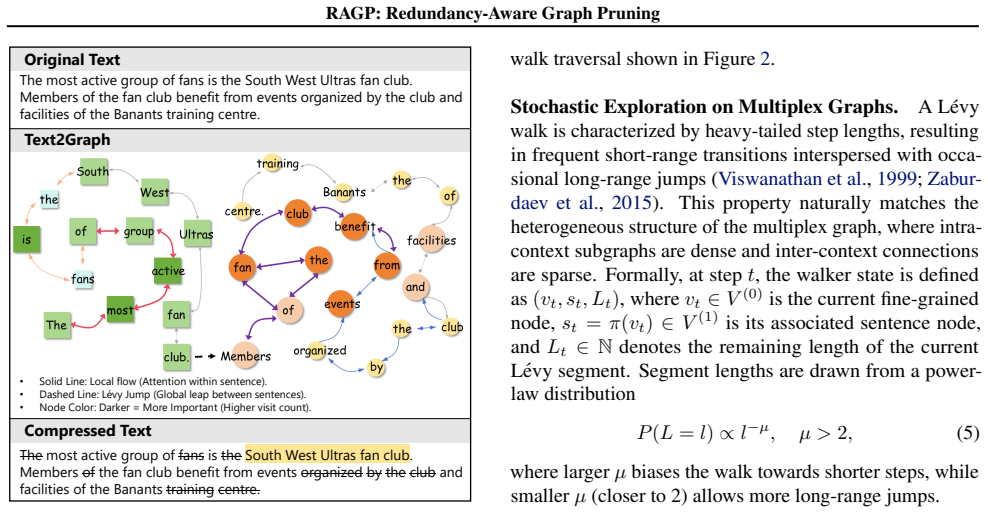
Mapping Text to Multiplex Graph: Prompt Compression as L\'evy Walk-Guided Graph Pruning
Pith reviewed 2026-07-04 01:43 UTC · model grok-4.3
The pith
Prompt compression improves by mapping text to a multiplex graph and pruning redundant nodes with Lévy walks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
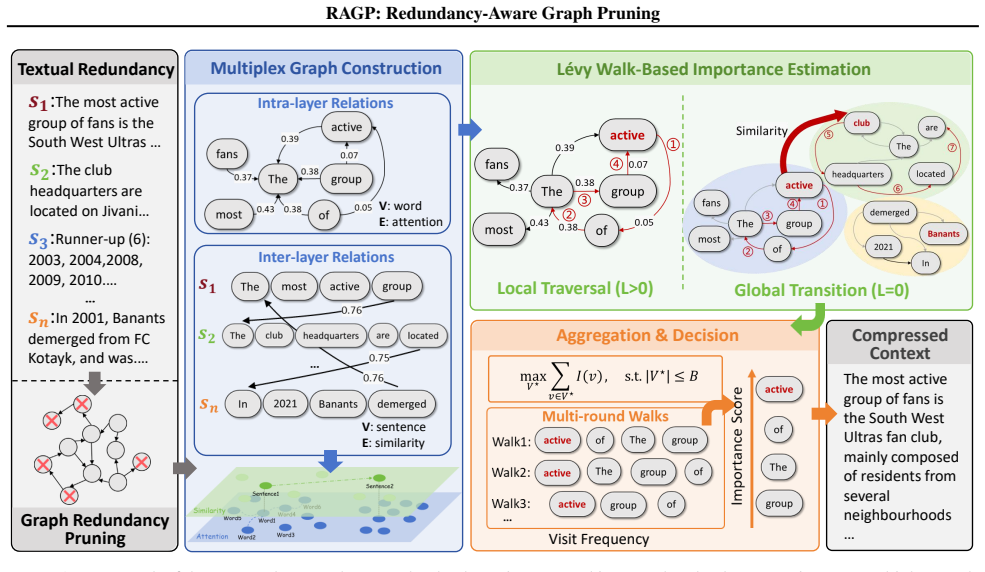
RAGP formulates prompt compression as redundancy-aware graph pruning on a multiplex graph that jointly models fine-grained attention-based dependencies and coarse-grained semantic relations; Lévy walks, whose heavy-tailed steps balance local and global search, efficiently locate non-redundant nodes in this structure.
What carries the argument
Multiplex graph with Lévy walk-guided pruning, which models attention dependencies and semantic relations as separate edge layers and uses heavy-tailed random walks to prune while preserving distributed information.
If this is right
- Prompts can be compressed to one-quarter length while retaining higher average performance than prior methods achieve at one-third length.
- The same graph construction and pruning steps also exceed vision-based compression approaches on multiple tasks.
- Dense local subgraphs and sparse global connections are handled together without separate processing stages.
- The method scales to the heterogeneous relational structure that flat-sequence compressors ignore.
Where Pith is reading between the lines
- Graph construction cost may limit use on very short prompts where flat methods already suffice.
- The approach could be tested on non-English text to check whether attention patterns transfer across languages.
- If the multiplex layers prove complementary, similar dual-layer graphs might help in related tasks such as extractive summarization.
Load-bearing premise
Representing text as a multiplex graph of attention and semantic relations, then pruning with Lévy walks, correctly separates redundant tokens from those carrying distributed important information.
What would settle it
An experiment in which nodes marked redundant by the Lévy walk pruning are removed and task accuracy drops more than when the same number of nodes are removed at random or by a baseline sequence method.
Figures
read the original abstract
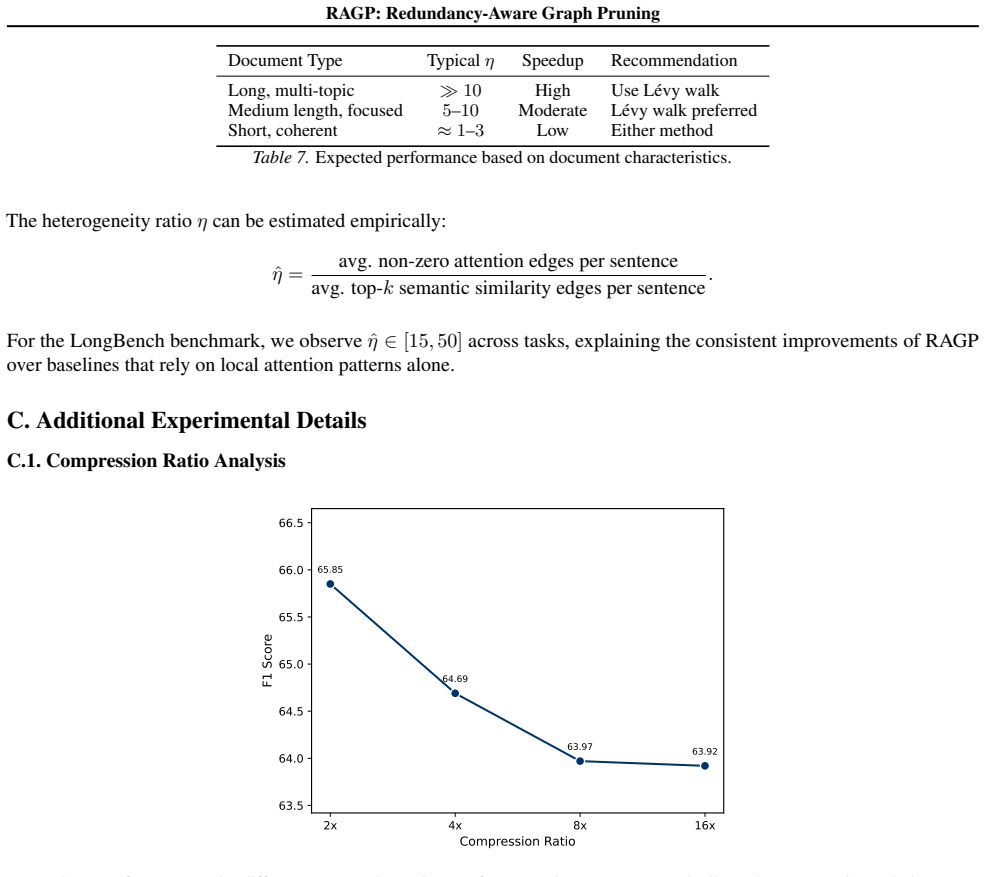
Existing prompt compression methods treat text as flat token sequences, failing to capture the distributed nature of important information, which is often spread across multiple locations and connected through both local syntactic dependencies and global semantic relations. Such relational structure is naturally represented as a graph, where tokens or sentences become nodes and their dependencies become edges. To this end, we propose RAGP, which formulates prompt compression as Redundancy-Aware Graph Pruning on a multiplex graph that jointly models fine-grained attention-based dependencies and coarse-grained semantic relations. To efficiently identify non-redundant nodes in this heterogeneous structure (dense local subgraphs and sparse global connections), we employ Levy walks whose heavy-tailed step distribution naturally balances local exploitation with global exploration. Experiments on LongBench show that RAGP achieves an average score of 49.3 under a 4x compression ratio, outperforming existing LLM-based compression methods, such as LongLLMLingua, which attains 48.8 at a 3x compression ratio. Besides, RAGP also surpasses state-of-the-art vision-based text compression paradigms on multiple tasks. The code is available at https://anonymous.4open.science/r/RAGP-B0CB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAGP, a prompt compression method that maps text to a multiplex graph jointly encoding fine-grained attention-based token dependencies and coarse-grained semantic relations, then applies Lévy walk-guided pruning to remove redundant nodes while preserving distributed important information. On LongBench, RAGP reports an average score of 49.3 at 4x compression, outperforming LongLLMLingua (48.8 at 3x) and several vision-based baselines; code is released at an anonymous repository.
Significance. If the empirical edge holds under controlled conditions, the work would demonstrate that multiplex-graph modeling plus heavy-tailed random walks can improve redundancy detection over flat-sequence or LLM-only compressors. The explicit code release is a clear strength for reproducibility.
major comments (2)
- [Abstract / Results] Abstract (and results section): the central superiority claim rests on a 0.5-point margin (49.3 vs 48.8) obtained at mismatched compression ratios (4x vs 3x). Direct comparison at identical ratios is required to support the claim that the graph+Lévy approach is superior.
- [Abstract / Experiments] Abstract / Experiments: no variance estimates, number of runs, per-task standard deviations, or statistical significance tests are reported for the LongBench aggregate scores. On LongBench, differences of this magnitude frequently arise from seed or prompt variation; without these controls the observed edge cannot be distinguished from noise.
minor comments (1)
- [Abstract] The abstract uses LaTeX markup (L\'evy) that should be rendered consistently in the final PDF.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract (and results section): the central superiority claim rests on a 0.5-point margin (49.3 vs 48.8) obtained at mismatched compression ratios (4x vs 3x). Direct comparison at identical ratios is required to support the claim that the graph+Lévy approach is superior.
Authors: We agree that the current comparison at mismatched ratios (4x for RAGP versus 3x for LongLLMLingua) limits the strength of the superiority claim. In the revised manuscript we will add direct head-to-head results for both methods at identical compression ratios of 3x and 4x on LongBench, allowing a controlled assessment of the contribution of the multiplex-graph and Lévy-walk components. revision: yes
-
Referee: [Abstract / Experiments] Abstract / Experiments: no variance estimates, number of runs, per-task standard deviations, or statistical significance tests are reported for the LongBench aggregate scores. On LongBench, differences of this magnitude frequently arise from seed or prompt variation; without these controls the observed edge cannot be distinguished from noise.
Authors: We acknowledge that the absence of variance estimates and statistical tests leaves the 0.5-point difference vulnerable to the criticism that it may reflect run-to-run variability. We will rerun all LongBench experiments across multiple random seeds, report per-task and aggregate standard deviations, and include paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests) in the revised results section and tables. revision: yes
Circularity Check
No circularity: empirical method with independent evaluation
full rationale
The paper introduces RAGP as a graph-pruning procedure on a multiplex graph with Lévy-walk guidance and reports LongBench scores. No equations, uniqueness theorems, or parameter-fitting steps are described that reduce a claimed prediction or first-principles result to the input data by construction. The central claims rest on external benchmark comparisons rather than self-referential definitions or self-citation chains. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.12968 , year=
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression , author=. arXiv preprint arXiv:2403.12968 , year=
-
[2]
arXiv preprint arXiv:2310.06839 , year=
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression , author=. arXiv preprint arXiv:2310.06839 , year=
-
[3]
arXiv preprint arXiv:2304.12102 , year=
Unlocking context constraints of llms: Enhancing context efficiency of llms with self-information-based content filtering , author=. arXiv preprint arXiv:2304.12102 , year=
-
[4]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
DisComp: A Two-Stage Prompt Optimization Framework Combining Task-Agnostic and Task-Aware Compression , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[5]
arXiv preprint arXiv:2503.07956 , year=
EFPC: Towards Efficient and Flexible Prompt Compression , author=. arXiv preprint arXiv:2503.07956 , year=
-
[6]
Llmlingua: Com- pressing prompts for accelerated inference of large language models, 2023
Llmlingua: Compressing prompts for accelerated inference of large language models , author=. arXiv preprint arXiv:2310.05736 , year=
-
[7]
2023 , eprint=
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. 2023 , eprint=
2023
-
[8]
Rho-1: not all tokens are what you need (2024) , author=
2024
-
[9]
arXiv preprint arXiv:2504.16574 , year=
Pis: Linking importance sampling and attention mechanisms for efficient prompt compression , author=. arXiv preprint arXiv:2504.16574 , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Leveraging attention to effectively compress prompts for long-context llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
arXiv preprint arXiv:2203.09629 , year=
HiStruct+: Improving extractive text summarization with hierarchical structure information , author=. arXiv preprint arXiv:2203.09629 , year=
-
[12]
Electronics , volume=
Hierarchical text classification and its foundations: A review of current research , author=. Electronics , volume=. 2024 , publisher=
2024
-
[13]
Scientific Reports , volume=
Hierarchical graph-based integration network for propaganda detection in textual news articles on social media , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Discourse-Aware Language Representation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[15]
ACM Transactions on Intelligent Systems and Technology , volume=
A survey on graph representation learning methods , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2024 , publisher=
2024
-
[16]
Journal of king saud university-computer and information sciences , volume=
Hierarchical graph-based text classification framework with contextual node embedding and BERT-based dynamic fusion , author=. Journal of king saud university-computer and information sciences , volume=. 2023 , publisher=
2023
-
[17]
Neurocomputing , volume=
Hierarchical graph attention networks for multi-modal rumor detection on social media , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[18]
Applied Sciences , volume=
AttenFlow: Context-Aware Architecture with Consensus-Based Retrieval and Graph Attention for Automated Document Processing , author=. Applied Sciences , volume=. 2025 , publisher=
2025
-
[19]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Fidelis: Faithful reasoning in large language models for knowledge graph question answering , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Harnessing large language models for knowledge graph question answering via adaptive multi-aspect retrieval-augmentation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
arXiv preprint arXiv:2501.13958 , year=
A survey of graph retrieval-augmented generation for customized large language models , author=. arXiv preprint arXiv:2501.13958 , year=
-
[22]
arXiv preprint arXiv:2404.00489 , year=
Prompt-saw: Leveraging relation-aware graphs for textual prompt compression , author=. arXiv preprint arXiv:2404.00489 , year=
-
[23]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Hierarchical knowledge guided fault intensity diagnosis of complex industrial systems , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[24]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[25]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Leveraging passage retrieval with generative models for open domain question answering , author=. arXiv preprint arXiv:2007.01282 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[26]
International conference on machine learning , pages=
Pegasus: Pre-training with extracted gap-sentences for abstractive summarization , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[27]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Codebert: A pre-trained model for programming and natural languages , author=. arXiv preprint arXiv:2002.08155 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[28]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Prompt compression with context-aware sentence encoding for fast and improved llm inference , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
GPT-C: Generative PrompT Compression , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[31]
arXiv preprint arXiv:2510.17800 , year=
Glyph: Scaling context windows via visual-text compression , author=. arXiv preprint arXiv:2510.17800 , year=
-
[32]
LLaMA 3.1-8B-Instruct , year =
-
[33]
Qwen2.5-7B-Instruct-1M , year =
-
[34]
GLM-4-9B-Chat-1M , year =
-
[35]
arXiv preprint arXiv:2503.10720 , year=
Attentionrag: Attention-guided context pruning in retrieval-augmented generation , author=. arXiv preprint arXiv:2503.10720 , year=
-
[36]
arXiv preprint arXiv:2501.06730 , year=
Better Prompt Compression Without Multi-Layer Perceptrons , author=. arXiv preprint arXiv:2501.06730 , year=
-
[37]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
arXiv preprint arXiv:2511.15244 , year=
Context cascade compression: Exploring the upper limits of text compression , author=. arXiv preprint arXiv:2511.15244 , year=
-
[39]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Dast: Context-aware compression in llms via dynamic allocation of soft tokens , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[40]
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
URL https://arxiv
Cot-valve: Length-compressible chain-of-thought tuning, 2025 , author=. URL https://arxiv. org/abs/2502 , volume=
2025
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
C3ot: Generating shorter chain-of-thought without compromising effectiveness , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
arXiv preprint arXiv:2505.14582 , year=
Can pruning improve reasoning? revisiting long-cot compression with capability in mind for better reasoning , author=. arXiv preprint arXiv:2505.14582 , year=
-
[44]
Lost in the Middle: How Language Models Use Long Contexts
Lost in the middle: How language models use long contexts, 2023 , author=. URL https://arxiv. org/abs/2307.03172 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Perception compressor: A training-free prompt compression framework in long context scenarios , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[46]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Multiplex heterogeneous graph convolutional network , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[47]
Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
CS-MLGCN: Multiplex graph convolutional networks for community search in multiplex networks , author=. Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
-
[48]
Advances in neural information processing systems , volume=
Beyond redundancy: Information-aware unsupervised multiplex graph structure learning , author=. Advances in neural information processing systems , volume=
-
[49]
Foundations and trends
The probabilistic relevance framework: BM25 and beyond , author=. Foundations and trends. 2009 , publisher=
2009
-
[50]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. arXiv preprint arXiv:1908.10084 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[51]
2023 , howpublished=
OpenAI Embeddings , author=. 2023 , howpublished=
2023
-
[52]
Nature , volume=
Optimizing the success of random searches , author=. Nature , volume=. 1999 , publisher=
1999
-
[53]
Zaburdaev, Vasily and Denisov, Sergey and Klafter, Joseph , journal=. L. 2015 , publisher=
2015
-
[54]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
muxGNN: Multiplex graph neural network for heterogeneous graphs , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
2023
-
[55]
, author=
The PageRank citation ranking: Bringing order to the web. , author=. 1999 , institution=
1999
-
[56]
Proceedings
Weighted pagerank algorithm , author=. Proceedings. Second Annual Conference on Communication Networks and Services Research, 2004. , pages=. 2004 , organization=
2004
-
[57]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.