Trading Complexity for Expressivity Through Structured Generalized Linear Token Mixing
Pith reviewed 2026-06-28 22:54 UTC · model grok-4.3
The pith
Structured multi-state recurrences let token mixers trade decoding speed for greater expressivity
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing structure on multi-state recurrence dependencies, new recurrence patterns provably achieve the desired complexity while providing theoretical insights on their expressivity, thereby trading runtime for expressivity in a principled way.
What carries the argument
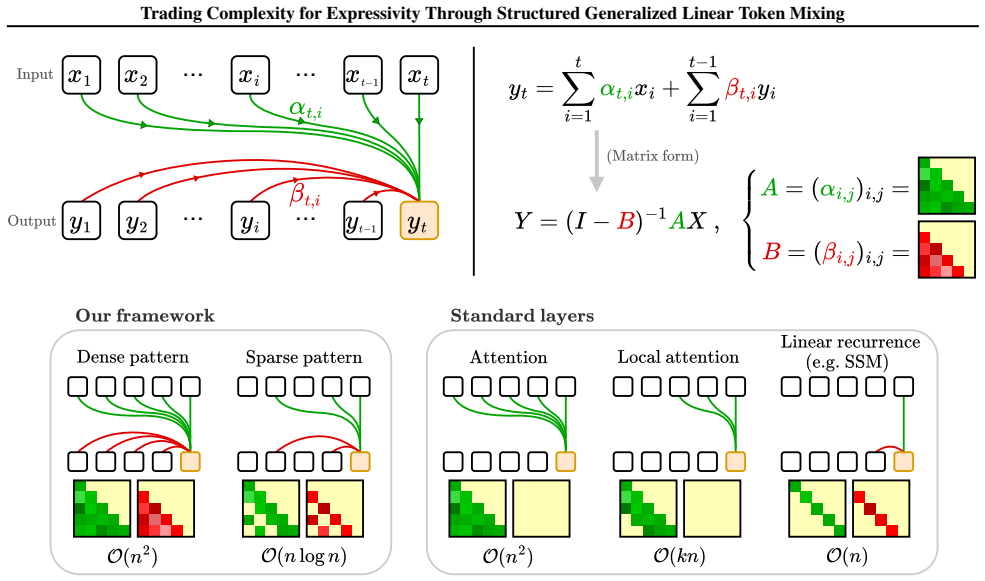
The structured generalization of recurrence equations allowing each state to depend on multiple past states rather than only the immediate predecessor
If this is right
- Attention and state-space models are special cases of the generalized framework.
- New token-mixer architectures can be systematically designed with explicit complexity-expressivity trade-offs.
- Theoretical analysis of the structured patterns reveals how dependence structure controls expressivity.
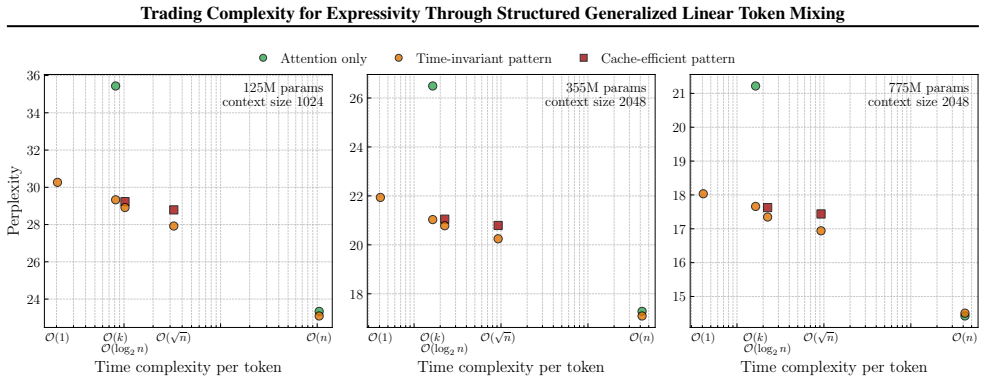
- Empirical results on synthetic tasks and language modeling confirm that the trade-offs are achievable in practice.
Where Pith is reading between the lines
- The separation into direct influence and recurrent propagation could be used to hybridize other sequence architectures.
- The same structuring technique might extend to higher-order or non-linear recurrence forms beyond the linear case studied here.
- Models built this way could target regimes where current quadratic or linear recurrences are either too slow or too weak for very long contexts.
Load-bearing premise
The structure imposed on multi-state recurrence dependencies maintains the claimed complexity bounds and delivers the stated expressivity gains without hidden costs or post-hoc adjustments.
What would settle it
An explicit counterexample in which one of the structured recurrence patterns either exceeds its claimed complexity bound during causal generation or shows no measurable expressivity improvement over standard single-state attention or SSM baselines on long-range synthetic tasks.
Figures

read the original abstract
Token mixing layers play a key role in how language models can learn and generate long-range dependencies. Their efficiency relies on the necessary trade-off between decoding speed and the memory requirements, along with the cache size. Considering causal generation, this paper explores new trade-offs thanks to a unified framework which separates two crucial features: (i) the direct influence of inputs on outputs in one generation step; (ii) the recurrent propagation of information through past outputs. This framework encompasses major architectures such as attention and state-space models, but also generalizes the recurrence equations by allowing each state to depend on multiple past states rather than only the immediate predecessor. By introducing structure, we design new recurrence patterns that provably achieve the desired complexity, while providing theoretical insights on their expressivity -- trading runtime for expressivity in a principled way. Empirical validation is performed on synthetic tasks, along with language modeling. Together, these results provide a unified toolkit for the understanding and design of efficient and expressive token mixers across model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified framework for token mixing layers in language models that separates direct input influence on outputs from recurrent propagation of information through past outputs. It generalizes attention and state-space model recurrences to allow multi-state dependencies, then imposes structure on these recurrences to design new patterns that provably achieve target complexity while yielding expressivity insights; the approach is evaluated on synthetic tasks and language modeling.
Significance. If the theoretical claims on complexity and expressivity hold, the work supplies a principled toolkit for trading runtime against expressivity in token mixers and unifies major architectures under one recurrence framework, which could guide design of efficient long-context models.
minor comments (3)
- The abstract states that new recurrence patterns 'provably achieve the desired complexity' but does not name the specific complexity measures (e.g., time or space per token) or the exact structural constraints used; adding one sentence with these quantities would improve readability.
- Empirical section: the description of synthetic tasks and language-modeling benchmarks would benefit from an explicit statement of the data-exclusion rules and error-analysis protocol referenced in the reader's assessment.
- Notation: the separation into 'direct influence' and 'recurrent propagation' is introduced without a compact equation label; assigning an equation number to the general multi-state recurrence would aid cross-references.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and the recommendation for minor revision. The provided report contains no specific major comments to address.
Circularity Check
No significant circularity detected
full rationale
The paper defines a unified framework separating direct input influence from recurrent state propagation, then generalizes standard attention/SSM recurrences by allowing multi-state dependencies and imposing structure to control complexity. Theoretical claims on expressivity and complexity bounds are presented as following from this explicit construction, with separate empirical validation on synthetic tasks and language modeling. No equations reduce predictions to fitted parameters by construction, no load-bearing self-citations underpin the core separation or uniqueness, and no ansatz is smuggled via prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of causal generation and linear token mixing operations hold.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=Ua6zuk0WRH. Dao, T. Flashattention-2: Faster attention with better paral- lelism and work partitioning. 2024:35549–35562, 2024. Dao, T. and Gu, A. Transformers are ssms: generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Lear...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main 2024
-
[2]
URL https://aclanthology.org/2024. emnlp-main.731/. Feng, L., Tung, F., Ahmed, M. O., Bengio, Y ., and Ha- jimirsadeghi, H. Were rnns all we needed?arXiv preprint arXiv:2410.01201, 2024. URL https:// arxiv.org/abs/2410.01201. Fu, D. Y ., Dao, T., Saab, K. K., Thomas, A. W., Rudra, A., and Re, C. Hungry hungry hippos: Towards lan- guage modeling with state...
arXiv 2024
-
[3]
URL https://openreview.net/forum? id=COZDy0WYGg. Gokaslan, A. and Cohen, V . Openwebtext cor- pus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019. Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. InFirst Conference on Lan- guage Modeling, 2024. URL https://openreview. net/forum?id=tEYskw1VY2. Gu, A., Dao, T., Ermo...
Pith/arXiv arXiv 2019
-
[4]
Hush, D., Abdallah, C., and Horne, B
URL https://openreview.net/forum? id=mOJgZWkXKW. Hush, D., Abdallah, C., and Horne, B. High order recursive neural networks. In1EEE 1991 ACC Conf, 1991. Jelassi, S., Brandfonbrener, D., Kakade, S. M., and Malach, E. Repeat after me: transformers are better than state space models at copying. InProceedings of the 41st In- ternational Conference on Machine ...
1991
-
[5]
Lahoti, A., Marwah, T., Puduppully, R., and Gu, A
URL https://openreview.net/forum? id=n2NidsYDop. Lahoti, A., Marwah, T., Puduppully, R., and Gu, A. Chimera: State space models beyond sequences.Transac- tions on Machine Learning Research, 2025. ISSN 2835-
2025
-
[6]
Mavi, V ., Jangra, A., and Jatowt, A
URL https://openreview.net/forum? id=yv0TUssepk. Mavi, V ., Jangra, A., and Jatowt, A. Multi-hop question answering.Found. Trends Inf. Retr., 17(5):457–586, June
-
[7]
ISSN 1554-0669. doi: 10.1561/1500000102. URL https://doi.org/10.1561/1500000102. NVIDIA, :, Blakeman, A., Basant, A., Khattar, A., Ren- duchintala, A., Bercovich, A., Ficek, A., Bjorlin, A., Taghibakhshi, A., Deshmukh, A. S., Mahabaleshwarkar, A. S., Tao, A., Shors, A., Aithal, A., Poojary, A., Dattagupta, A., Buddharaju, B., Chen, B., Ginsburg, B., Wang,...
-
[8]
Smith, J
URL https://openreview.net/forum? id=iF7MnXnxRw. Smith, J. T., Warrington, A., and Linderman, S. Simplified state space layers for sequence modeling. InThe Eleventh International Conference on Learning Representations,
-
[9]
URL https://openreview.net/forum? id=Ai8Hw3AXqks. Soltani, R. and Jiang, H. Higher order recurrent neural networks, 2017. URL https://openreview.net/ forum?id=ByZvfijeg. Stani´c, A., Ashley, D., Serikov, O., Kirsch, L., Faccio, F., Schmidhuber, J., Hofmann, T., and Schlag, I. The lan- guini kitchen: Enabling language modelling research at different scales...
arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.