Explaining Data Mixing Scaling Laws
Pith reviewed 2026-06-27 20:19 UTC · model grok-4.3
The pith
A framework based on capacity competition and noise reduction explains how data mixtures determine domain losses and allows extrapolation of optimal mixes to larger scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
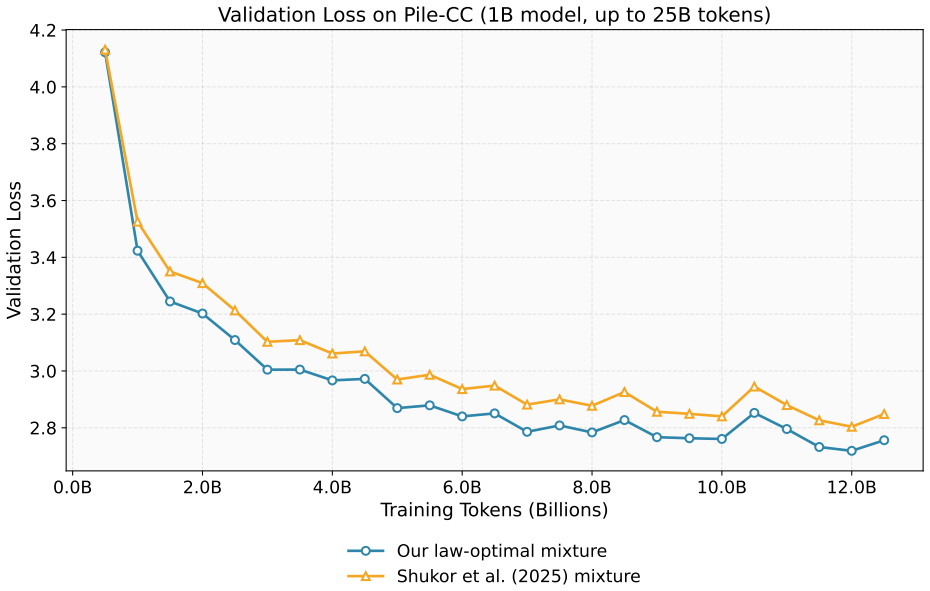
Based on the distributional assumption that domains overlap on fundamental skills while diverging on specialized skills, the authors identify Capacity Competition, where the allocation of finite model capacity couples domain losses globally, and Noise Reduction, where optimal weights shift toward harder-to-learn domains to minimize overall noise, as the governing mechanisms. Their model fits the loss landscape with lower mean relative error than baselines, identifies higher-performing mixtures, and extrapolates parameters fitted at small scales to predict effective mixtures at large unseen scales using significantly fewer parameters than previous empirical laws.
What carries the argument
The unified framework that extends single-domain scaling laws to the multi-domain case by positing shared fundamental skills across domains and domain-specific specialized skills, from which Capacity Competition and Noise Reduction follow as the mechanisms that determine domain losses under different mixtures.
If this is right
- Domain losses become globally coupled because any mixture must allocate a fixed amount of model capacity across all domains.
- Optimal mixture weights shift toward domains that are harder to learn because this choice reduces the total noise in the training signal.
- The framework reproduces the loss surface across mixtures with lower mean relative error than existing empirical scaling laws.
- Parameters estimated at small scales predict high-performing mixtures at large unseen scales.
- The same accuracy is achieved with significantly fewer parameters than prior empirical laws.
Where Pith is reading between the lines
- If the extrapolation holds, experimenters could optimize mixtures for frontier-scale models without running full-scale mixture searches.
- Data collection priorities would tilt toward domains whose specialized skills remain noisy even at large capacity.
- The same separation of shared and specialized skills might be used to design curricula or synthetic data that deliberately balance the two effects.
- Analogous capacity-competition and noise-reduction dynamics could appear in multi-task or multi-modal training beyond language modeling.
Load-bearing premise
Domains overlap on fundamental skills while diverging on specialized skills.
What would settle it
Fit the model's parameters on loss data from small-scale mixture experiments, then train models at a substantially larger scale and check whether the predicted optimal mixture weights produce lower loss than the weights actually observed to be best at that larger scale.
Figures
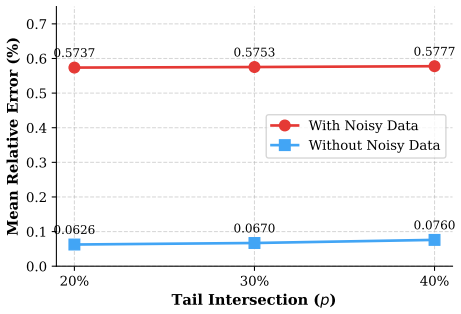
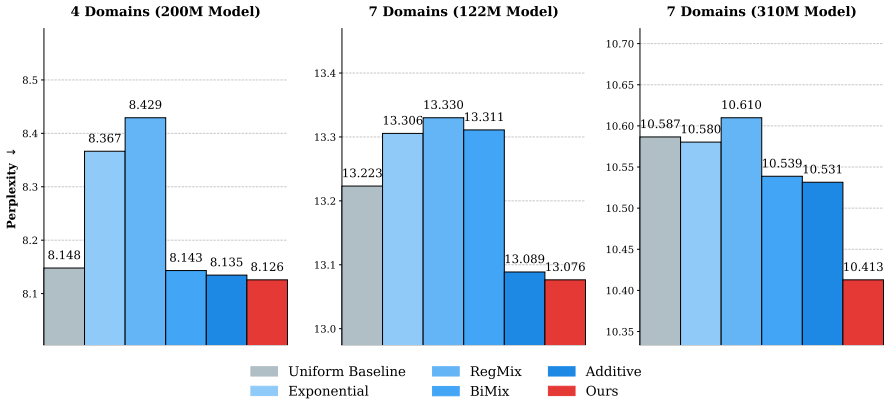
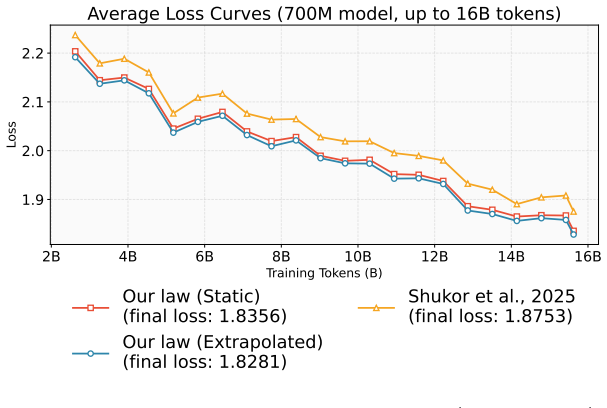
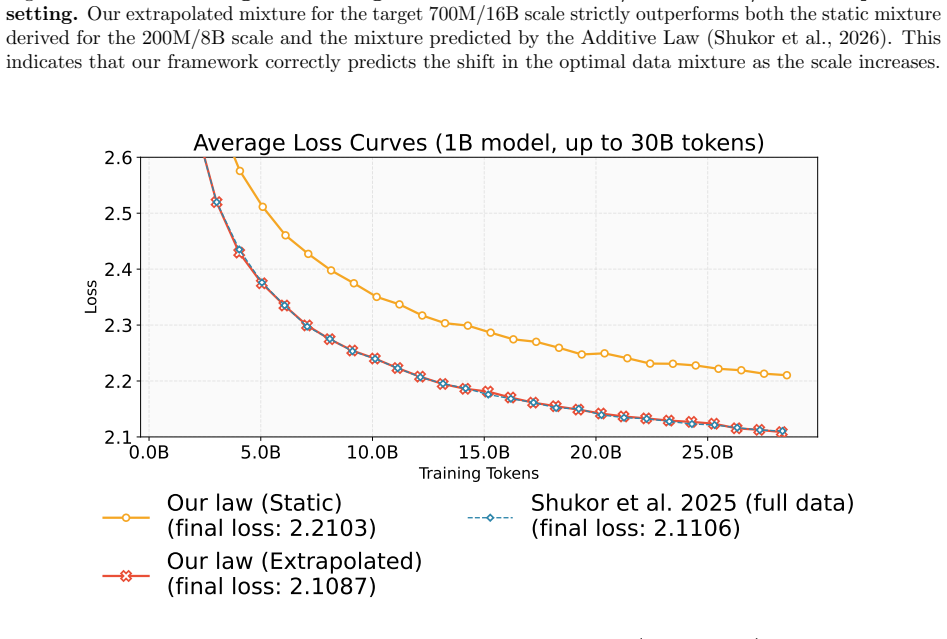
read the original abstract
Recent research has established empirical scaling laws to predict model performance on multi-domain data mixtures. However, a theoretical understanding of these model loss behaviors remains absent. In this work, we propose a unified framework to explain the underlying mechanics of data mixing. Our approach extends theoretical perspectives originally developed for standard neural scaling laws (e.g., Kaplan and Chinchilla) to the multi-domain setting. Based on the distributional assumption that domains overlap on fundamental skills while diverging on specialized skills, we identify two key factors that govern the domain losses of models trained on different data mixtures: \textit{Capacity Competition}, where the allocation of finite model capacity couples domain losses globally, and \textit{Noise Reduction}, where optimal weights shift toward harder-to-learn domains to minimize overall noise. Empirical evaluations show that our framework outperforms existing baselines by fitting the loss landscape with a lower Mean Relative Error and identifying higher-performing training mixtures. Most importantly, our model successfully extrapolates across scales, predicting highly effective mixtures for large, unseen scales using parameters fitted on smaller ones. In addition, our model achieves these results using significantly fewer parameters compared to previous empirical laws. Our code is available at https://github.com/meiqwq/Explaining-Data-Mixing-Scaling-Laws.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified theoretical framework extending standard neural scaling laws to multi-domain data mixtures. Based on the assumption that domains share fundamental skills but diverge on specialized ones, it identifies two governing factors—Capacity Competition (global coupling of domain losses via finite model capacity) and Noise Reduction (optimal weights shifting toward harder domains)—and derives a model that fits loss landscapes with lower mean relative error than baselines, identifies better mixtures, extrapolates optimal mixtures to large unseen scales from parameters fitted on small scales, and uses fewer parameters overall.
Significance. If the extrapolation result holds without circularity, the framework would supply a mechanistic account of data-mixing scaling laws and a practical tool for predicting effective mixtures at scales where direct experimentation is costly. The reported reduction in parameter count relative to prior empirical laws and the public code release are concrete strengths that would aid reproducibility and adoption.
major comments (2)
- [Abstract] Abstract: the headline extrapolation claim—that parameters fitted on small-scale mixtures successfully predict optimal mixtures at large unseen scales—rests on the untested premise that the relative weighting of Capacity Competition and Noise Reduction remains invariant with model capacity. No ablation or direct measurement is reported that confirms the skill-overlap structure (shared fundamental skills vs. domain-specific) does not shift dimensionality with scale.
- [Abstract] Abstract and empirical evaluation sections: it is unclear whether the central functional form is derived from the stated distributional assumption or is itself a post-hoc parametric fit; if the latter, the reported extrapolation reduces to using fitted coefficients to predict within the same functional family, undermining the claim of genuine out-of-sample prediction.
minor comments (1)
- [Abstract] The abstract states the model 'outperforms existing baselines by fitting the loss landscape with a lower Mean Relative Error' but does not specify the exact baselines, the number of domains, or the range of scales used in the extrapolation test.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the theoretical derivation and the scope of our empirical claims while proposing targeted revisions where the manuscript can be strengthened without overclaiming.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline extrapolation claim—that parameters fitted on small-scale mixtures successfully predict optimal mixtures at large unseen scales—rests on the untested premise that the relative weighting of Capacity Competition and Noise Reduction remains invariant with model capacity. No ablation or direct measurement is reported that confirms the skill-overlap structure (shared fundamental skills vs. domain-specific) does not shift dimensionality with scale.
Authors: We agree that the scale-invariance of the relative weighting between Capacity Competition and Noise Reduction is an assumption of the framework rather than a directly verified property. The skill-overlap structure is posited as a fixed distributional property of the data domains and is not re-estimated per scale; the model parameters fitted at small scales are then used to predict at large scales under this fixed structure. The reported extrapolation success provides supporting evidence but does not constitute a direct ablation of scale-dependent shifts in overlap dimensionality. We will revise the manuscript to explicitly state this modeling assumption, add a limitations paragraph discussing its implications, and include a brief sensitivity analysis (if feasible with existing data) showing how violations would affect predictions. revision: partial
-
Referee: [Abstract] Abstract and empirical evaluation sections: it is unclear whether the central functional form is derived from the stated distributional assumption or is itself a post-hoc parametric fit; if the latter, the reported extrapolation reduces to using fitted coefficients to predict within the same functional family, undermining the claim of genuine out-of-sample prediction.
Authors: The functional form is derived from the overlapping-skills distributional assumption. Capacity Competition follows directly from allocating a finite total capacity across shared fundamental skills (inducing global loss coupling) and domain-specific skills. Noise Reduction follows from the requirement to minimize aggregate effective noise by up-weighting domains whose specialized skills are harder to learn. The resulting closed-form expressions for domain losses contain a small number of interpretable coefficients that are fitted to data; the functional shape itself is not an arbitrary parametric choice. Consequently, the extrapolation uses the same theoretically derived form at unseen scales, which is out-of-sample with respect to both mixture weights and model size. We will add an appendix deriving the loss expressions step-by-step from the distributional premise to make this distinction clearer. revision: no
Circularity Check
Extrapolation claim reduces to applying parameters fitted on small-scale data
specific steps
-
fitted input called prediction
[Abstract]
"our model successfully extrapolates across scales, predicting highly effective mixtures for large, unseen scales using parameters fitted on smaller ones"
Parameters are obtained by fitting to small-scale loss data; the 'prediction' for large scales is then produced by direct substitution of those same fitted parameters into the model. The result is therefore generated from quantities defined by the fit on the input data rather than from an independent derivation or external constraint.
full rationale
The paper's headline result is that parameters fitted on small-scale mixtures successfully predict optimal mixtures at large unseen scales. This matches the fitted_input_called_prediction pattern: the functional form and coefficients are determined by fitting to the small-scale regime, after which the same form is applied to larger scales. The distributional assumption (domains overlap on fundamental skills) is invoked to justify the form but is not independently verified at large scales within the paper. No self-citation load-bearing or self-definitional steps are evident from the provided text; the circularity is limited to the extrapolation procedure itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- framework parameters
axioms (1)
- domain assumption domains overlap on fundamental skills while diverging on specialized skills
invented entities (2)
-
Capacity Competition
no independent evidence
-
Noise Reduction
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Arora, S. and Goyal, A. A theory for emergence of complex skills in language models.arXiv preprint arXiv:2307.15936,
-
[3]
Scaling and renormalization in high-dimensional regression
Atanasov, A., Zavatone-Veth, J. A., and Pehlevan, C. Scaling and renormalization in high-dimensional regression.arXiv preprint arXiv:2405.00592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Explaining neural scaling laws , volume=
doi: 10.1073/pnas.2311878121. URL https://www.pnas.org/doi/abs/10.1073/pnas.2311878121. Bordelon, B., Atanasov, A., and Pehlevan, C. A dynamical model of neural scaling laws. InInternational Conference on Machine Learning, pp. 4345–4382. PMLR,
-
[5]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J
URL https://openreview.net/ forum?id=dEypApI1MZ. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[6]
doi: 10.1364/JOSAA.4.002379. URL https: //opg.optica.org/josaa/abstract.cfm?URI=josaa-4-12-2379. Fonseca, N., Lee, S. H., Mingard, C., Louis, A., et al. An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem.Advances in Neural Information Processing Systems, 37: 39632–39693,
-
[7]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
16 Gu, X., Lyu, K., Li, J., and Zhang, J
URLhttps://openreview.net/forum?id=JsM46OZix7. 16 Gu, X., Lyu, K., Li, J., and Zhang, J. Data mixing can induce phase transitions in knowledge acquisition. In ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models,
2025
-
[9]
Training Compute-Optimal Large Language Models
URL https://openreview.net/forum?id=ZKA4yiGdrA. Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Scaling Laws for Neural Language Models
URL https: //openreview.net/forum?id=rujwIvjooA. Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Li, B., Chen, F., Huang, Z., Wang, L., and Wu, L
URL https://arxiv.org/abs/2205.05198. Li, B., Chen, F., Huang, Z., Wang, L., and Wu, L. Functional scaling laws in kernel regression: Loss dynamics and learning rate schedules. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026a. URLhttps://openreview.net/forum?id=dpllevHMbc. Li, Z., Deng, Y., Zhong, P., Razaviyayn, M., an...
-
[12]
URL https://openreview.net/forum?id=p9YlQPF8fE. Maloney, A., Roberts, D. A., and Sully, J. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859,
-
[13]
TinyLlama: An Open-Source Small Language Model
URL https://openreview.net/forum?id=kJ5i29FejW. Zhang, P., Zeng, G., Wang, T., and Lu, W. Tinyllama: An open-source small language model.arXiv preprint arXiv:2401.02385,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
18 A Empirical Data Mixing Laws As detailed in Table 3, these baselines offer distinct functional forms for predicting the domain loss Li(h) given the data mixture weights h. Specifically, we consider: (1) theAdditive Law(Shukor et al., 2026), which models the loss using an inverse polynomial combination of mixture weights alongside model and data scale p...
2026
-
[15]
19 C Implementation Details For the experiments in Section 5.3, we implement our pretraining pipeline using the Megatron-LM framework in Korthikanti et al
12:end while 13:Return:Optimal mixtureh ∗ ←h (t). 19 C Implementation Details For the experiments in Section 5.3, we implement our pretraining pipeline using the Megatron-LM framework in Korthikanti et al. (2022) on a cluster of 8 NVIDIA H200 GPUs. To investigate the scaling laws with respect to data mixture ratios, we construct two GPT-style transformer ...
2022
-
[16]
resolves
Table 4: Hyperparameters for the 200M and 700M proxy models used in our data mixing experiments. Hyperparameter 200M Model 700M Model Architecture Layers (L) 24 24 Hidden Size (d model) 768 1536 Attention Heads 12 12 Sequence Length 1024 1024 Optimization Global Batch Size 128 128 Micro Batch Size 16 16 Learning Rate 3.5×10 −4 3.5×10 −4 Minimum Learning R...
2024
-
[17]
sketching matrix
is independent Gaussian noise. 21 • Spectral Assumptions:When training a linear regression model with one-pass SGD, the learning dynamics are determined by the spectrum of the covariance matrixH= E[xx⊤]. Intuitively, the eigenvalues λk ofHrepresent the variance (or signal strength) of the data along the k-th principal component. Empirical studies on natur...
1987
-
[18]
In the following section, λk denotes the eigenvalue associated with the eigenvector uk, i.e.H uk = λkuk (but not the k-th largest eigenvalue)
+ i. In the following section, λk denotes the eigenvalue associated with the eigenvector uk, i.e.H uk = λkuk (but not the k-th largest eigenvalue). In this basis with flattened index,A i is diagonal withA i = diag(a1, a2, . . .) and ak =u ⊤ k Aiuk = ( l−αi k= Γ(i, l) 0 otherwise. In addition,H(h) = P hjAj is diagonal as well. We then make a standard assum...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.