L3Cube-MahaPOS: A Marathi Part-of-Speech Tagging Dataset and BERT Models
Pith reviewed 2026-06-25 23:43 UTC · model grok-4.3
The pith
A new manually annotated dataset supplies 32,354 Marathi sentences for part-of-speech tagging and benchmarks models at 88.67 percent token accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
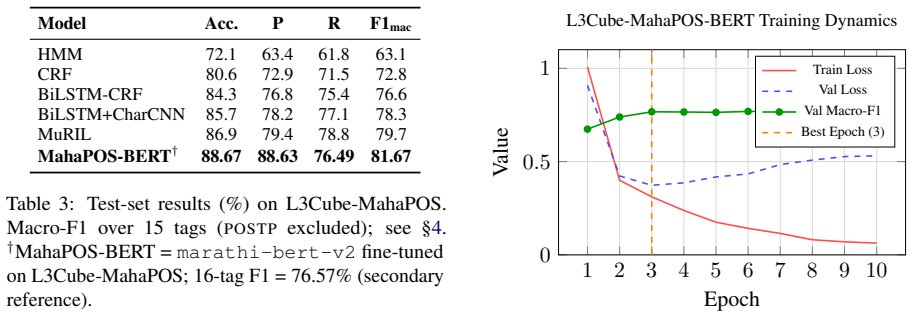
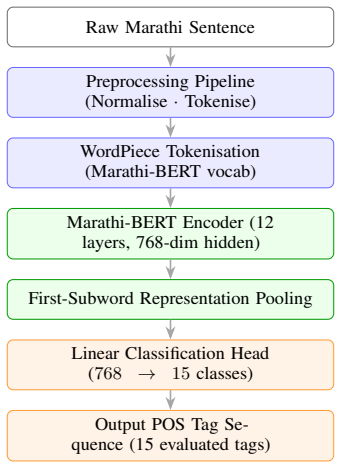
We introduce L3Cube-MahaPOS, a gold-standard POS tagging dataset for Marathi comprising 32,354 manually annotated sentences drawn from news text. Annotation was performed entirely manually by a team of Marathi-proficient annotators following a 16-tag Universal Dependencies-aligned scheme. A structured preprocessing pipeline covering Unicode normalisation, Devanagari-aware tokenisation, and noise filtering ensures label consistency across all splits. The best system achieves 88.67% token-level accuracy and a macro-F1 of 81.67% over 15 evaluated tag classes.
What carries the argument
The L3Cube-MahaPOS dataset of 32,354 manually annotated sentences under a 16-tag Universal Dependencies scheme, together with the evaluation pipeline across HMM, CRF, BiLSTM, and transformer families.
If this is right
- The released dataset and checkpoints can be used immediately to train or fine-tune POS taggers for Marathi text.
- Downstream tasks such as syntactic parsing and machine translation for Marathi gain an immediate labeled resource.
- The preprocessing steps provide a reusable template for creating similar corpora in other Devanagari-script languages.
- The performance gap between traditional and transformer models supplies a baseline for future Marathi-specific model development.
Where Pith is reading between the lines
- The same manual annotation approach could be applied to other under-resourced Indian languages that share morphological complexity and code-mixing patterns.
- Extending the corpus beyond news text into domains such as literature or social media would test whether the reported accuracies hold in more varied text.
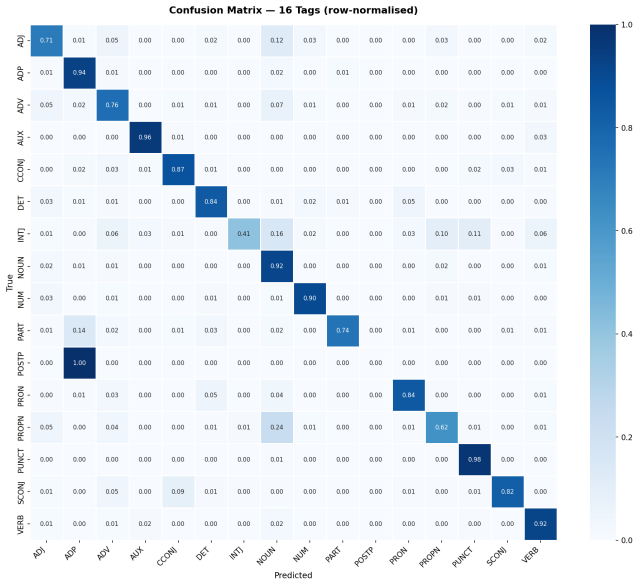
- The 15-tag evaluation setup leaves one tag class aside, so future work could measure whether including the omitted class changes model rankings.
Load-bearing premise
Manual annotation by Marathi-proficient annotators following the 16-tag scheme produces consistent gold-standard labels with minimal errors or inconsistencies.
What would settle it
An independent review that finds annotation errors or tag inconsistencies in more than a small fraction of the sentences would show the labels are not gold-standard.
Figures

read the original abstract
Part-of-Speech (POS) tagging is a foundational NLP task underpinning machine translation, information extraction, and syntactic parsing. Despite Marathi being spoken by over 83 million people and ranking among the top twenty most spoken languages worldwide, it remains severely under-resourced in annotated corpora and standardised evaluation benchmarks. Marathi presents unique challenges for computational modelling owing to its rich morphology, relatively free word order, lack of capitalisation conventions, and pervasive code-mixing with Hindi and English. We introduce L3Cube-MahaPOS, a gold-standard POS tagging dataset for Marathi comprising 32,354 manually annotated sentences drawn from news text. Annotation was performed entirely manually by a team of Marathi-proficient annotators following a 16-tag Universal Dependencies-aligned scheme. A structured preprocessing pipeline covering Unicode normalisation, Devanagari-aware tokenisation, and noise filtering ensures label consistency across all splits. We benchmark the dataset across six model families spanning HMM, CRF, BiLSTM, BiLSTM+CharCNN, MuRIL, and the Marathi-specific transformer MahaBERT-v2. The best system achieves 88.67\% token-level accuracy and a macro-F1 of 81.67% over 15 evaluated tag classes. We release the dataset, annotation guidelines, and trained model checkpoints to foster further research in Marathi NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces L3Cube-MahaPOS, a new manually annotated POS tagging dataset for Marathi consisting of 32,354 sentences from news text, using a 16-tag Universal Dependencies-aligned scheme. It describes a preprocessing pipeline and benchmarks six model families (HMM, CRF, BiLSTM variants, MuRIL, MahaBERT-v2), reporting a best token-level accuracy of 88.67% and macro-F1 of 81.67% over 15 tag classes, while releasing the dataset, guidelines, and model checkpoints.
Significance. If the annotation quality holds, the work provides a valuable new resource for an under-resourced language with complex morphology and code-mixing, enabling standardized evaluation and further Marathi NLP research. The release of data and models is a clear strength for reproducibility in low-resource settings.
major comments (1)
- [Abstract / Annotation description] Abstract and (presumed) Methods/Annotation section: The central claim that L3Cube-MahaPOS constitutes a 'gold-standard' dataset with reliable labels supporting the reported 88.67% accuracy and 81.67% macro-F1 rests on manual annotation by Marathi-proficient annotators, yet no inter-annotator agreement statistic (Cohen's kappa, Fleiss' kappa, or similar), disagreement resolution protocol, or post-annotation validation is reported. This is load-bearing for the dataset's utility as a benchmark.
minor comments (2)
- [Abstract / Results] The abstract mentions '15 evaluated tag classes' while using a 16-tag scheme; clarify the excluded class and any rationale in the results section.
- [Dataset description] Data splits (train/dev/test sizes and stratification) are referenced but not quantified in the provided abstract; include explicit numbers and any domain or tag distribution statistics.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of L3Cube-MahaPOS as a valuable resource and for the detailed feedback. We address the single major comment below and commit to revisions that strengthen the manuscript's claims about annotation quality.
read point-by-point responses
-
Referee: [Abstract / Annotation description] Abstract and (presumed) Methods/Annotation section: The central claim that L3Cube-MahaPOS constitutes a 'gold-standard' dataset with reliable labels supporting the reported 88.67% accuracy and 81.67% macro-F1 rests on manual annotation by Marathi-proficient annotators, yet no inter-annotator agreement statistic (Cohen's kappa, Fleiss' kappa, or similar), disagreement resolution protocol, or post-annotation validation is reported. This is load-bearing for the dataset's utility as a benchmark.
Authors: We agree that the absence of inter-annotator agreement (IAA) metrics and annotation protocol details is a significant omission that weakens the 'gold-standard' claim. The original manuscript reports only that annotation was performed manually by Marathi-proficient annotators following a 16-tag UD-aligned scheme, without quantifying agreement or describing disagreement resolution. In the revised version we will add a new subsection under Methods detailing: (i) the number of annotators and their qualifications, (ii) the exact annotation workflow including how disagreements were resolved (e.g., majority vote or adjudicator review), (iii) IAA statistics (Cohen's kappa on a 10% overlap subset), and (iv) any post-annotation validation steps. These additions will be supported by the existing annotation guidelines that are already being released with the dataset. revision: yes
Circularity Check
No circularity; empirical dataset release and benchmarking
full rationale
The paper introduces a new manually annotated POS dataset for Marathi and reports benchmark accuracies from standard models (HMM, CRF, BiLSTM, transformers). No derivations, predictions, or first-principles results are claimed. The annotation process is presented as an input (manual labeling by proficient annotators following UD scheme) rather than derived from model outputs. No self-citations, fitted parameters renamed as predictions, or ansatzes appear in the provided text. The work is self-contained as a data contribution with external model evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thorsten Brants. 2000. TnT -- a statistical part-of-speech tagger. In Sixth Applied Natural Language Processing Conference, pages 224--231, Seattle, Washington, USA
2000
-
[2]
Eric Brill. 1992. A simple rule-based part of speech tagger. In Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, February 23-26, 1992
1992
-
[3]
Harsh Vijay Chaudhari, Anuja Dinesh Patil, Dhanashree Lavekar, Pranav Khairnar, and Raviraj Joshi. 2023. L3Cube-MahaSocialNER : A social media based M arathi named entity recognition dataset and BERT models. In Proceedings of the 15th Annual Meeting of the Forum for Information Retrieval Evaluation, pages 93--100
2023
-
[4]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440--8451
2020
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4171--4186
2019
-
[6]
Mona Diab, Kadri Hacioglu, and Daniel Jurafsky. 2004. Automatic tagging of A rabic text: From raw text to base phrase chunks. In Proceedings of HLT-NAACL 2004: Short Papers , pages 149--152, Boston, Massachusetts, USA
2004
-
[7]
S Hochreiter. 1997. Long short-term memory. Neural Computation MIT-Press
1997
-
[8]
Raviraj Joshi. 2022 a . L3cube-mahacorpus and mahabert: Marathi monolingual corpus, marathi bert language models, and resources. In Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference, pages 97--101
2022
-
[9]
Raviraj Joshi. 2022 b . L3Cube-MahaNLP : M arathi natural language processing datasets, models, and library. arXiv preprint arXiv:2205.14728
arXiv 2022
-
[10]
Nidhi Kowtal and Raviraj Bhuminand Joshi. 2025. L3Cube-MahaEmotions : A M arathi emotion recognition dataset with synthetic annotations using CoTR prompting and large language models. In Proceedings of the 39th Pacific Asia Conference on Language, Information and Computation, pages 419--427
2025
-
[11]
Taku Kudo, Kaoru Yamamoto, and Yuji Matsumoto. 2004. Applying conditional random fields to J apanese morphological analysis. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 230--237, Barcelona, Spain
2004
-
[12]
Atharva Kulkarni, Meet Mandhane, Manali Likhitkar, Gayatri Kshirsagar, and Raviraj Joshi. 2021. L3Cube-MahaSent : A M arathi tweet-based sentiment analysis dataset. In Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, pages 213--220
2021
-
[13]
John Lafferty, Andrew McCallum, and Fernando CN Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data
2001
-
[14]
Gary Geunbae Lee, Jeongwon Cha, and Jong-Hyeok Lee. 2002. Syllable-pattern-based unknown-morpheme segmentation and estimation for hybrid part-of-speech tagging of K orean. Computational Linguistics, 28(1):53--70
2002
-
[15]
Onkar Litake, Maithili Ravindra Sabane, Parth Sachin Patil, Aparna Abhijeet Ranade, and Raviraj Bhuminand Joshi. 2022. L3Cube-MahaNER : A M arathi named entity recognition dataset and BERT models. In Proceedings of the WILDRE-6 Workshop within the 13th Language Resources and Evaluation Conference , pages 29--34
2022
-
[16]
Xuezhe Ma and Eduard Hovy. 2016. End-to-end sequence labeling via bi-directional LSTM-CNN s- CRF . In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1064--1074
2016
-
[17]
Christopher D. Manning. 2011. Part-of- S peech tagging from 97 \ In Computational Linguistics and Intelligent Text Processing, pages 171--189, Berlin, Heidelberg. Springer Berlin Heidelberg
2011
-
[18]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of E nglish: The P enn T reebank. Computational Linguistics, 19(2):313--330
1993
-
[19]
Hwee Tou Ng and Jin Kiat Low. 2004. C hinese part-of-speech tagging: One-at-a-time or all-at-once? word-based or character-based? In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 277--284
2004
-
[20]
Manning, Ryan McDonald, Slav Petrov, Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, and Daniel Zeman
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Yoav Goldberg, Jan Haji c , Christopher D. Manning, Ryan McDonald, Slav Petrov, Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, and Daniel Zeman. 2016. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the Tenth International Conference on Language Resources and Evalua...
2016
-
[21]
Martha Palmer, Rajesh Bhatt, Bhuvana Narasimhan, Owen Rambow, Dipti Misra Sharma, and Fei Xia. 2009. Hindi syntax: Annotating dependency, lexical predicate-argument structure, and phrase structure. In The 7th International Conference on Natural Language Processing, pages 14--17
2009
-
[22]
Aabha Pingle, Aditya Vyawahare, Isha Joshi, Rahul Tangsali, and Raviraj Bhuminand Joshi. 2023. L3Cube-MahaSent-MD : A multi-domain M arathi sentiment analysis dataset and transformer models. In Proceedings of the 37th Pacific Asia Conference on Language, Information and Computation, pages 274--281
2023
-
[23]
Adwait Ratnaparkhi. 1996. A maximum entropy model for part-of-speech tagging. In Conference on Empirical Methods in Natural Language Processing, pages 133--142
1996
-
[24]
Smriti Singh, Kuhoo Gupta, Manish Shrivastava, and Pushpak Bhattacharyya. 2006. Morphological richness offsets resource demand -- experiences in constructing a POS tagger for H indi. In Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions , pages 779--786
2006
-
[25]
Manning, and Yoram Singer
Kristina Toutanova, Dan Klein, Christopher D. Manning, and Yoram Singer. 2003. Feature-rich part-of-speech tagging with a cyclic dependency network. In Proceedings of the 2003 Human Language Technology Conference of the North A merican Chapter of the Association for Computational Linguistics , pages 252--259
2003
-
[26]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in Neural Information Processing Systems, 30
2017
-
[27]
Part-of- S peech Tagging from 97 \
Manning, Christopher D. Part-of- S peech Tagging from 97 \. Computational Linguistics and Intelligent Text Processing. 2011
2011
-
[28]
Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, February 23-26, 1992 , year =
A simple rule-based part of speech tagger , author =. Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, February 23-26, 1992 , year =
1992
-
[29]
Conditional random fields: Probabilistic models for segmenting and labeling sequence data , author =
-
[30]
Neural Computation MIT-Press , year =
Long short-term memory , author =. Neural Computation MIT-Press , year =
-
[31]
End-to-end sequence labeling via bi-directional
Ma, Xuezhe and Hovy, Eduard , booktitle =. End-to-end sequence labeling via bi-directional
-
[32]
Advances in Neural Information Processing Systems , volume =
Attention is all you need , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =
-
[34]
Kulkarni, Atharva and Mandhane, Meet and Likhitkar, Manali and Kshirsagar, Gayatri and Joshi, Raviraj , booktitle =
-
[35]
The 7th International Conference on Natural Language Processing , pages =
Hindi syntax: Annotating dependency, lexical predicate-argument structure, and phrase structure , author =. The 7th International Conference on Natural Language Processing , pages =
-
[36]
Joshi, Raviraj , journal =
-
[37]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
Unsupervised cross-lingual representation learning at scale , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[38]
Litake, Onkar and Sabane, Maithili Ravindra and Patil, Parth Sachin and Ranade, Aparna Abhijeet and Joshi, Raviraj Bhuminand , booktitle =
-
[39]
Pingle, Aabha and Vyawahare, Aditya and Joshi, Isha and Tangsali, Rahul and Joshi, Raviraj Bhuminand , booktitle =
-
[40]
Chaudhari, Harsh Vijay and Patil, Anuja Dinesh and Lavekar, Dhanashree and Khairnar, Pranav and Joshi, Raviraj , booktitle =
-
[41]
Kowtal, Nidhi and Joshi, Raviraj Bhuminand , booktitle =
-
[42]
Conference on Empirical Methods in Natural Language Processing , pages =
A Maximum Entropy Model for Part-Of-Speech Tagging , author =. Conference on Empirical Methods in Natural Language Processing , pages =
-
[43]
and Santorini, Beatrice and Marcinkiewicz, Mary Ann , journal =
Marcus, Mitchell P. and Santorini, Beatrice and Marcinkiewicz, Mary Ann , journal =. Building a Large Annotated Corpus of
-
[44]
Brants, Thorsten , booktitle =
-
[45]
Proceedings of the 2003 Human Language Technology Conference of the North
Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network , author =. Proceedings of the 2003 Human Language Technology Conference of the North
2003
-
[46]
Automatic Tagging of
Diab, Mona and Hacioglu, Kadri and Jurafsky, Daniel , booktitle =. Automatic Tagging of
-
[47]
Ng, Hwee Tou and Low, Jin Kiat , booktitle =
-
[48]
Applying Conditional Random Fields to
Kudo, Taku and Yamamoto, Kaoru and Matsumoto, Yuji , booktitle =. Applying Conditional Random Fields to
-
[49]
Syllable-Pattern-Based Unknown-Morpheme Segmentation and Estimation for Hybrid Part-of-Speech Tagging of
Lee, Gary Geunbae and Cha, Jeongwon and Lee, Jong-Hyeok , journal =. Syllable-Pattern-Based Unknown-Morpheme Segmentation and Estimation for Hybrid Part-of-Speech Tagging of
-
[50]
Morphological Richness Offsets Resource Demand -- Experiences in Constructing a
Singh, Smriti and Gupta, Kuhoo and Shrivastava, Manish and Bhattacharyya, Pushpak , booktitle =. Morphological Richness Offsets Resource Demand -- Experiences in Constructing a
-
[51]
Proceedings of the Tenth International Conference on Language Resources and Evaluation (
Universal Dependencies v1: A Multilingual Treebank Collection , author =. Proceedings of the Tenth International Conference on Language Resources and Evaluation (
-
[52]
Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference , pages=
L3cube-mahacorpus and mahabert: Marathi monolingual corpus, marathi bert language models, and resources , author=. Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.