Understanding LLMs in Title-Abstract Screening: From Disagreements to Recommendations
Pith reviewed 2026-06-27 00:04 UTC · model grok-4.3
The pith
Disagreements between humans and LLMs in screening papers for systematic reviews come from boundary ambiguity in terms, overemphasis on keywords, and incorrect topic inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
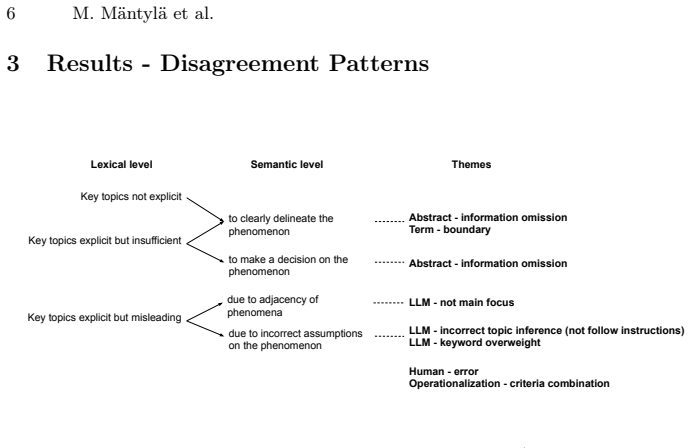
Analysis of disagreements across six systematic reviews and over 1,000 papers shows that human-LLM differences arise from recurring causes: boundary ambiguity in key terms, keyword overemphasization, and incorrect topic inference. Kappa agreement ranged from 0.52 to 0.77. The authors translate these causes into recommendations including validating semantic understanding before deployment, running multiple LLMs, and concentrating validation effort on borderline cases.
What carries the argument
Qualitative coding of disagreements between zero-shot LLM outputs and human expert decisions across the six systematic reviews.
If this is right
- Validating semantic understanding of LLMs before use can reduce disagreements in screening.
- Running multiple different LLMs and comparing outputs helps catch errors from any single model.
- Validation effort should concentrate on borderline cases rather than the full set of papers.
- Future work is required to test whether these recommendations actually improve screening reliability.
Where Pith is reading between the lines
- The same disagreement patterns may appear in LLM use for other evidence-synthesis tasks beyond software engineering.
- Testing the recommendations in few-shot or retrieval-augmented settings could show whether prompting changes reduce the identified causes.
- Community guidelines for LLM use in systematic reviews could be built directly around the three causes listed.
Load-bearing premise
The patterns found in disagreements from these six reviews and zero-shot prompting represent the main general causes of LLM failures in title-abstract screening.
What would settle it
A new set of systematic reviews where the recommended practices are applied and agreement rates are measured to see whether they rise above the 0.52-0.77 Kappa range observed here.
Figures
read the original abstract
Several studies have examined the use of large language models (LLMs) for title-abstract screening in systematic reviews (SRs), reporting mixed accuracy. However, questions of reliability remain largely unaddressed. In this study, we go beyond quantitative LLM-human agreement metrics and qualitatively investigate how and why LLMs fail. We also propose actionable recommendations. We analyzed disagreements between LLMs and researchers across six software engineering SRs and over 1,000 primary study papers. For each SR, papers were screened independently by human experts and LLMs in zero-shot mode, resulting in Kappa values ranging from 0.52 to 0.77. Qualitative analysis suggests that human-LLM disagreement results from recurring, identifiable causes, such as boundary ambiguity in key terms, keyword overemphasization, and incorrect topic inference. Based on these findings, we propose recommendations such as validating semantic understanding before deployment, running multiple LLMs, and focusing validation efforts on borderline cases. Future studies are needed to validate the impact of our recommendations, and community efforts are needed to develop normative guidelines on LLM usage in SRs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes disagreements between LLMs (zero-shot) and human experts during title-abstract screening across six software engineering systematic reviews involving over 1,000 papers. It reports inter-rater Kappa values ranging from 0.52 to 0.77 and uses qualitative analysis of disagreements to identify recurring causes (boundary ambiguity in key terms, keyword overemphasization, incorrect topic inference). From these patterns the authors derive actionable recommendations for LLM deployment and call for normative guidelines.
Significance. If the identified causes can be shown to be dominant and generalizable, the work would supply concrete, practice-oriented guidance for an increasingly common but still unreliable use of LLMs in evidence synthesis. The empirical focus on real SRs and the move beyond aggregate accuracy metrics are strengths.
major comments (2)
- [Abstract] Abstract: the central claim that human-LLM disagreement 'results from recurring, identifiable causes' rests on a qualitative analysis whose sampling frame, number of coded disagreements, and proportion attributed to each cause are not reported; without these quantities it is impossible to determine whether the listed factors are the main drivers or merely illustrative examples.
- [Methods/Results] Methods/Results (qualitative analysis subsection): no inter-coder reliability statistic, coding protocol, or description of how disagreements were sampled from the >1,000 papers is supplied, which directly undermines the assertion that the observed patterns are generalizable across SRs.
minor comments (1)
- [Abstract] The abstract states Kappa values but does not indicate whether they were computed on the full set of papers or only on the subset that produced disagreements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in our qualitative analysis. We address each major comment below and will revise the manuscript accordingly to strengthen the reporting of our methods and findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that human-LLM disagreement 'results from recurring, identifiable causes' rests on a qualitative analysis whose sampling frame, number of coded disagreements, and proportion attributed to each cause are not reported; without these quantities it is impossible to determine whether the listed factors are the main drivers or merely illustrative examples.
Authors: We agree that the abstract and main text do not report the sampling frame, exact number of coded disagreements, or the proportion attributed to each cause. This information is necessary to substantiate the claim of recurring causes. In the revision we will add these details to the Methods and Results sections (including a table summarizing the coded sample) and revise the abstract to describe the analysis as exploratory rather than definitive. revision: yes
-
Referee: [Methods/Results] Methods/Results (qualitative analysis subsection): no inter-coder reliability statistic, coding protocol, or description of how disagreements were sampled from the >1,000 papers is supplied, which directly undermines the assertion that the observed patterns are generalizable across SRs.
Authors: The referee is correct that the current manuscript omits the inter-coder reliability statistic, the coding protocol, and the sampling procedure for selecting disagreements. We will expand the qualitative analysis subsection to include: (1) a description of how disagreements were sampled (e.g., stratified random sample across the six SRs), (2) the coding protocol and codebook, and (3) inter-coder reliability (Cohen's kappa or equivalent) for the two authors who performed the coding. These additions will directly address concerns about generalizability. revision: yes
Circularity Check
No significant circularity; empirical observational study with independent qualitative analysis
full rationale
The paper performs a qualitative analysis of disagreements between LLMs and human screeners across six SRs, identifying recurring causes from direct inspection of cases. No equations, fitted parameters, predictions, or derivations exist. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked to justify the central claims. The findings are presented as observational suggestions requiring future validation, rendering the chain self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The six software engineering SRs are representative for studying LLM screening in general.
Reference graph
Works this paper leans on
-
[1]
Beller, M., Bacchelli, A., Zaidman, A., Juergens, E.: Modern code reviews in open- sourceprojects:Whichproblemsdotheyfix?In:11thworkingconferenceonmining software repositories (2014)
2014
-
[2]
Braun, V., Clarke, V.: Using thematic analysis in psychology. Qualitative Research in Psychology3(2), 77–101 (Jan 2006). https://doi.org/10.1191/1478088706qp063oa, publisher: Routledge
-
[3]
Research Synthesis Methods pp
Chan, G.C., He, E., Leung, J., Verspoor, K.: A comprehensive systematic review dataset is a rich resource for training and evaluation of ai systems for title and abstract screening. Research Synthesis Methods pp. 1–15 (2025)
2025
-
[4]
In: 2025International Workshop on Methodological Issues with Empirical Studies in Software Engineer- ing (WSESE)
Felizardo, K., Deizepe, A., Coutinho, D., Gomes, G., Meireles, M., Gerosa, M., Steinmacher, I.: On the difficulties of conducting and replicating systematic lit- erature reviews studies using llms in software engineering. In: 2025International Workshop on Methodological Issues with Empirical Studies in Software Engineer- ing (WSESE). pp. 20–23. IEEE (2025)
2025
-
[5]
In: 18th ACM/IEEE Interna- tional Symposium on Empirical Software Engineering and Measurement
Felizardo, K., Lima, M., Deizepe, A., Conte, T.U., Steinmacher, I.: ChatGPT ap- plication in Systematic Literature Reviews in Software Engineering: An evaluation of its accuracy to support the selection activity. In: 18th ACM/IEEE Interna- tional Symposium on Empirical Software Engineering and Measurement. pp. 25–
-
[6]
ESEM ’24 (2024). https://doi.org/10.1145/3674805.3686666
-
[7]
Information and software technology106, 101–121 (2019)
Garousi, V., Felderer, M., Mäntylä, M.V.: Guidelines for including grey literature and conducting multivocal literature reviews in software engineering. Information and software technology106, 101–121 (2019)
2019
-
[8]
In: 2025 ACM/IEEE International Symposium on Empirical Software Engineer- ing and Measurement (ESEM)
Huotala, A., Kuutila, M., Mäntylä, M.: SESR-Eval: Dataset for Evalu- ating LLMs in the Title-Abstract Screening of Systematic Reviews. In: 2025 ACM/IEEE International Symposium on Empirical Software Engineer- ing and Measurement (ESEM). pp. 1–12. ESEM ’25, IEEE (Oct 2025). https://doi.org/10.1109/ESEM64174.2025.00053
-
[9]
In: 28th International Conference on Evaluation and Assessment in Software Engineering
Huotala, A., Kuutila, M., Ralph, P., Mäntylä, M.: The Promise and Challenges of Using LLMs to Accelerate the Screening Process of Systematic Reviews. In: 28th International Conference on Evaluation and Assessment in Software Engineering. pp. 262–271. EASE ’24 (July 18, 2024). https://doi.org/10.1145/3661167.3661172
-
[10]
34th ACM Joint ESEC/FSE, July 05–09, 2026, Montreal, QC, Canada pp
Huotala, A., Kuutila, M., Turtio, O.P., Sipilä, S., Mäntylä, M.: Aisysrev - llm-based tool for title-abstract screening. 34th ACM Joint ESEC/FSE, July 05–09, 2026, Montreal, QC, Canada pp. 1–5 (2026), https://arxiv.org/abs/2510.06708
Pith/arXiv arXiv 2026
-
[11]
Prentice Hall, 3rd edn
Jurafsky, D., Martin, J.H.: Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models. Prentice Hall, 3rd edn. (2026) 16 M. Mäntylä et al
2026
-
[12]
Journal of Medical Artificial Intelligence8, 34 (2025)
Kim, J.K., Rickard, M., Dangle, P., Batra, N., Chua, M.E., Khondker, A., Szy- manski, K.M., Misseri, R., Lorenzo, A.J.: Evaluating large language models for title/abstract screening: a systematic review and meta-analysis & development of new tool. Journal of Medical Artificial Intelligence8, 34 (2025)
2025
-
[13]
In: 26th International Conference on Software Engineering
Kitchenham, B.A., Dyba, T., Jorgensen, M.: Evidence-based software engineering. In: 26th International Conference on Software Engineering. pp. 273–281. IEEE (2004). https://doi.org/10.1109/ICSE.2004.1317449
-
[14]
Information and Software Technology121, 106257 (2020)
Kuutila, M., Mäntylä, M., Farooq, U., Claes, M.: Time pressure in software engi- neering: A systematic review. Information and Software Technology121, 106257 (2020). https://doi.org/10.1016/j.infsof.2020.106257
-
[15]
Journal of Clinical Epidemiology181(2025)
Lieberum, J.L., Toews, M., Metzendorf, M.I., Heilmeyer, F., Siemens, W., Haverkamp, C., Böhringer, D., Meerpohl, J., Eisele-Metzger, A.: Large lan- guage models for conducting systematic reviews: on the rise, but not yet ready for use—a scoping review. Journal of Clinical Epidemiology181(2025). https://doi.org/10.1016/j.jclinepi.2025.111746
-
[16]
arXiv preprint arXiv:2511.12635 (2025)
Madeyski, L., Kitchenham, B., Shepperd, M.: Llm4screenlit: Recommendations on assessing the performance of large language models for screening literature in systematic reviews. arXiv preprint arXiv:2511.12635 (2025)
Pith/arXiv arXiv 2025
-
[17]
Mäntylä, M.V., Lassenius, C.: What types of defects are really discovered in code reviews? IEEE Transactions on Software Engineering35(3), 430–448 (2008)
2008
-
[18]
Journal of Systems and Software185, 111148 (2022)
Matsubara, P.G.F., Gadelha, B.F., Steinmacher, I., Conte, T.U.: Sextamt: A systematic map to navigate the wide seas of factors affecting expert judg- ment software estimates. Journal of Systems and Software185, 111148 (2022). https://doi.org/https://doi.org/10.1016/j.jss.2021.111148
-
[19]
Information and Software Technology171, 107452 (2024)
Petersen, K.: Case study identification with gpt-4 and implications for mapping studies. Information and Software Technology171, 107452 (2024)
2024
-
[20]
Information and Software Technology178, 107611 (2025)
Petersen, K., Gerken, J.M.: On the road to interactive llm-based systematic mapping studies. Information and Software Technology178, 107611 (2025). https://doi.org/10.1016/j.infsof.2024.107611
-
[21]
Information and software technology64, 1–18 (2015)
Petersen, K., Vakkalanka, S., Kuzniarz, L.: Guidelines for conducting systematic mapping studies in software engineering: An update. Information and software technology64, 1–18 (2015)
2015
-
[22]
Empirical Software Engineering30(1), 10 (2025)
Pizard, S., Lezama, J., García, R., Vallespir, D., Kitchenham, B.: Using rapid reviews to support software engineering practice: a systematic review and a replication study. Empirical Software Engineering30(1), 10 (2025). https://doi.org/10.1007/s10664-024-10545-6
-
[23]
Rainer, A.: Using argumentation theory to analyse software practitioners’ defeasi- ble evidence, inference and belief. Inf. Softw. Technolg87, 62–80 (2017)
2017
-
[24]
In: Intl Conference on Data Science, Technology and Applications (DATA 25)
Sandner, E., Fontana, L., Kothari, K., Henriques, A., Jakovljevic, I., Simniceanu, A., Wagner, A., Gütl, C.: Evaluating large language models for literature screening: A systematic review of sensitivity and workload reduction. In: Intl Conference on Data Science, Technology and Applications (DATA 25). pp. 508–517 (2025)
2025
-
[25]
ICSM 2001
Siy, H., Votta, L.: Does the modern code inspection have value? In: International Conference on Software Maintenance. ICSM 2001. pp. 281–289. IEEE (2001)
2001
-
[26]
Information and Software Technology p
Thode, L., Iftikhar, U., Mendez, D.: Exploring the use of llms for the selection phase in systematic literature studies. Information and Software Technology p. 107757 (2025). https://doi.org/10.1016/j.infsof.2025.107757
-
[27]
Trinkenreich, B., Wiese, I., Sarma, A., Gerosa, M., Steinmacher, I.: Women’s Participation in Open Source Software: A Survey of the Literature. ACM Trans. Softw. Eng. Methodol.31(4) (2022). https://doi.org/10.1145/3510460, https://doi.org/10.1145/3510460
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.