Joint discovery of governing partial differential equations from multi-source datasets by competitive optimization
Pith reviewed 2026-07-01 07:17 UTC · model grok-4.3
The pith
A competitive optimization framework recovers shared governing PDEs by fusing sparse multi-source datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
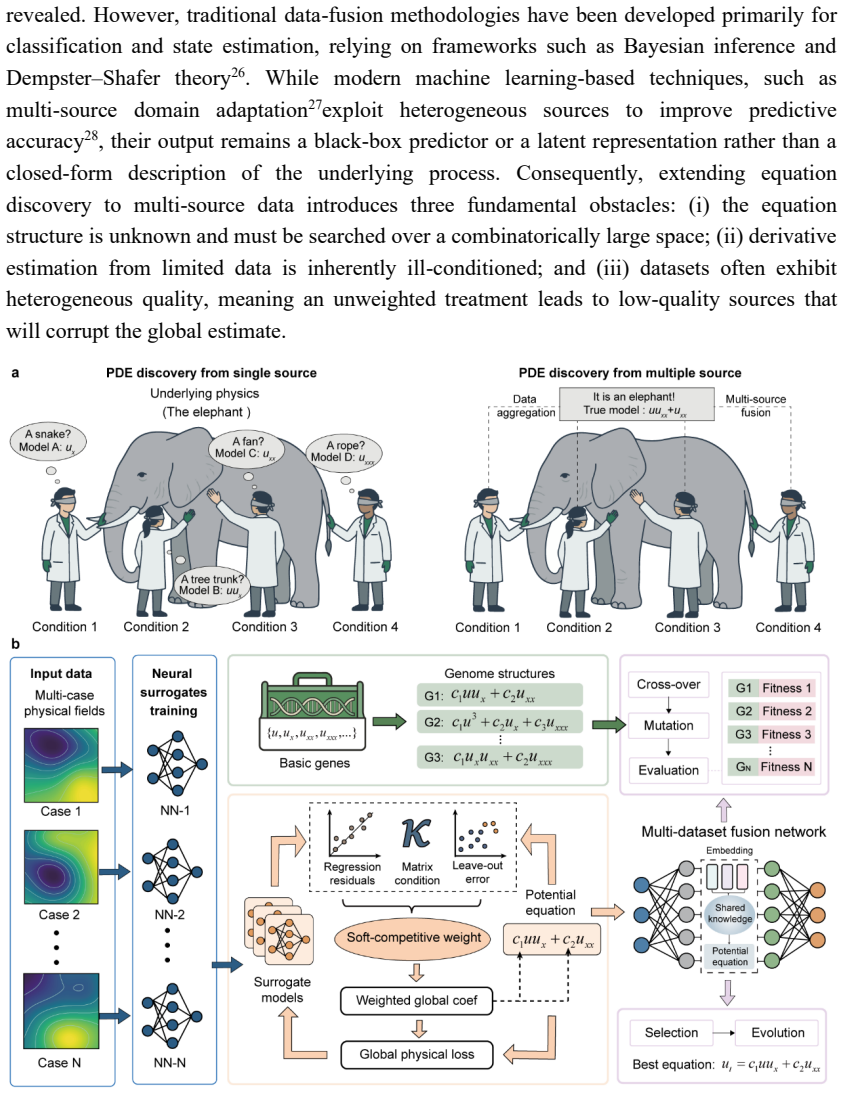
MCO-PDE discovers shared partial differential equations from multiple data sources by first fitting independent neural surrogates to each source and then applying a soft-competitive weighting mechanism that dynamically evaluates dataset credibility to form a consensus global coefficient; this coefficient is optimized jointly with a genetic algorithm that searches over possible functional forms.
What carries the argument
Soft-competitive weighting mechanism that dynamically assesses dataset credibility to aggregate a consensus global coefficient from independently trained neural surrogates.
Load-bearing premise
The soft-competitive weighting can reliably judge dataset credibility and produce an unbiased consensus coefficient.
What would settle it
Run the method on a collection of datasets in which one source contains a known systematic bias while the others are accurate; check whether the recovered equation matches the true PDE or is pulled toward the biased source.
Figures
read the original abstract
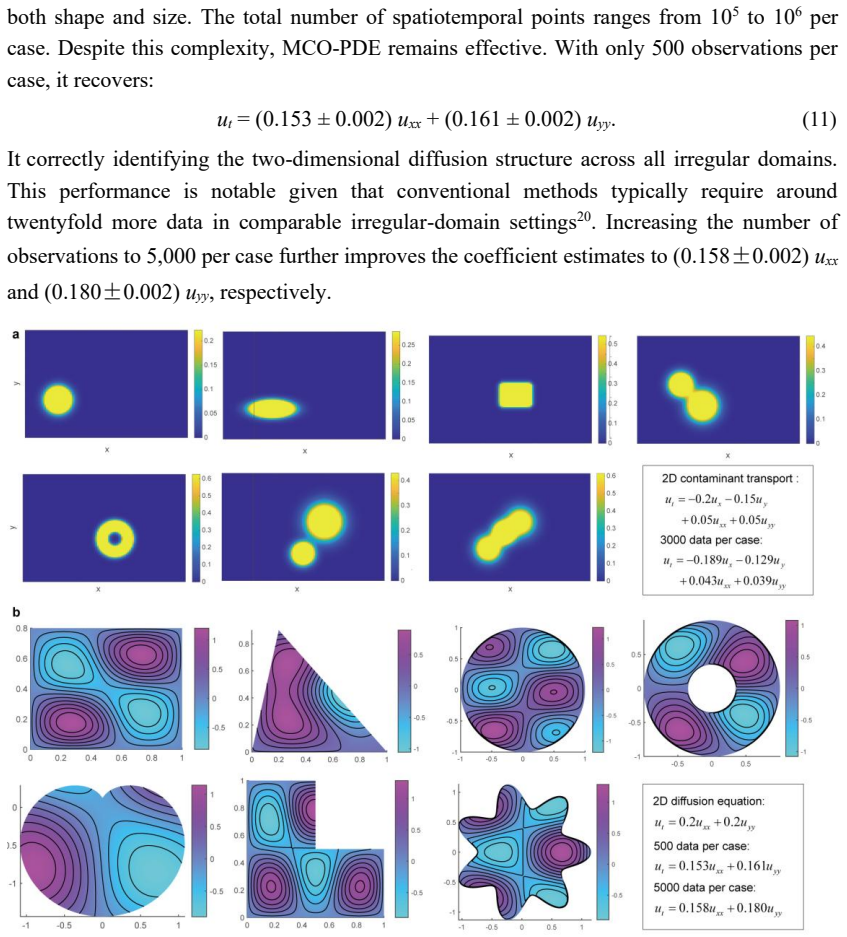
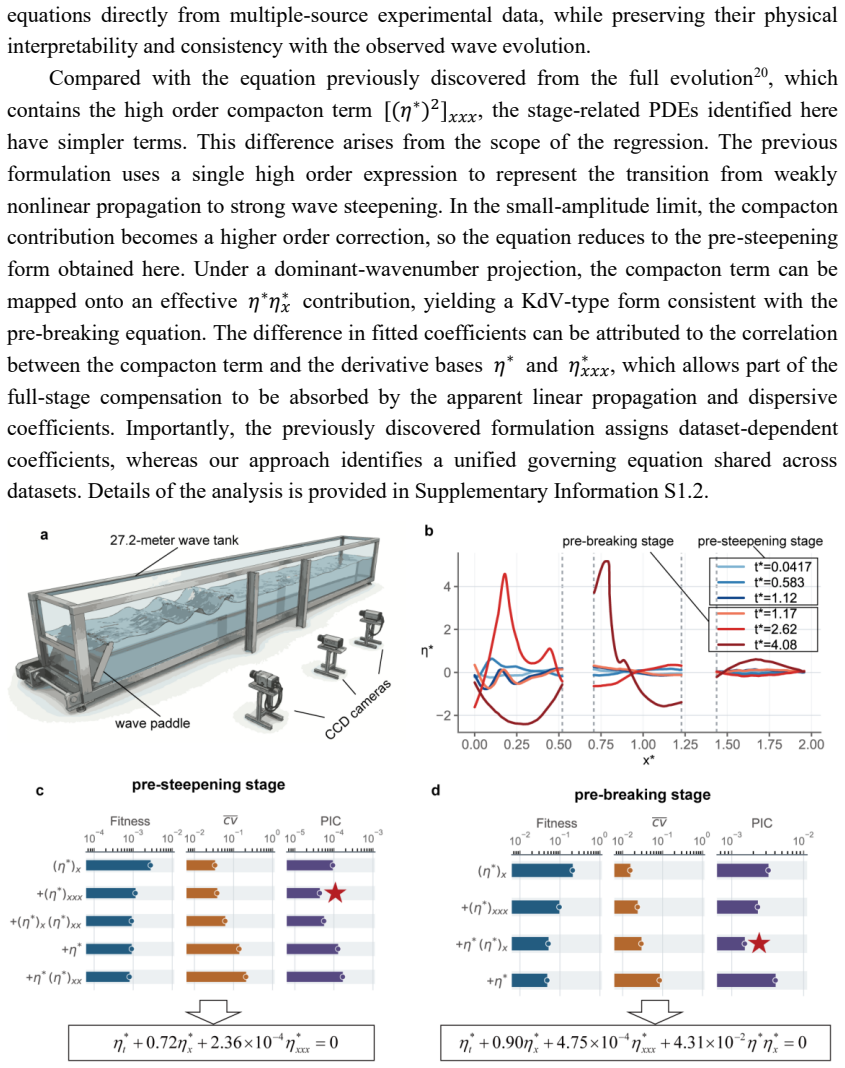
Discovering governing equations directly from observational data is a key step towards interpretable scientific machine learning. Current data-driven approaches typically operate on a single dataset, inherently limiting their performance when faced with restricted observations. In practice, multiple datasets are often available for the same physical system, distinguished only by distinct initial conditions or boundary configurations. Here, we present a competitive optimization framework designed to discover shared partial differential equations (PDEs) from multi-source datasets, termed MCO-PDE. The framework first trains independent neural surrogates for each data source, and then employs a soft-competitive weighting mechanism to dynamically assess dataset credibility and aggregate a consensus global coefficient. Integrated with a genetic algorithm for structural search, this approach simultaneously identifies the functional forms and parameters of the governing laws. We demonstrate that fusing as few as 50 observations per dataset across seven cases recovers canonical equations with high accuracy. The framework inherently handles two- and three-dimensional domains characterized by irregular boundaries and heterogeneous coefficients, and successfully extracts physically meaningful laws from real-world wave-tank experiments. Overall, this work establishes a promising route for automated scientific discovery via heterogeneous data fusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MCO-PDE, a framework for joint discovery of shared governing PDEs from multi-source datasets. Independent neural surrogates are trained per data source; a soft-competitive weighting mechanism then assesses credibility and produces a consensus global coefficient vector. This is combined with a genetic algorithm for simultaneous structural and parametric identification. The method is demonstrated on seven cases (including 2D/3D irregular domains with heterogeneous coefficients) using as few as 50 observations per source, recovering canonical equations at high accuracy and extracting laws from real wave-tank experiments.
Significance. If the soft-competitive aggregation step is shown to be robust, the approach would offer a practical route to PDE discovery when individual datasets are small but multiple sources are available, extending data-driven methods to heterogeneous real-world settings.
major comments (2)
- [§3.2 (method description of weighting)] The central claim that the soft-competitive weighting yields an unbiased consensus coefficient (and thereby reliable structural identification) rests on an unverified assumption. No bias analysis, sensitivity study to surrogate error, or ablation against uniform averaging is reported for the aggregation step.
- [§4 (experimental results)] The reported recovery accuracy with 50 observations per source across seven cases is presented without quantitative metrics (e.g., coefficient error distributions, false-positive rates on library terms, or recovery success rates under controlled noise). This makes it impossible to assess whether the genetic search is actually driven by the aggregated coefficients or by other factors.
minor comments (2)
- [§3] Notation for the neural surrogate outputs and the credibility weights is introduced without a consolidated symbol table, making the aggregation formula difficult to follow on first reading.
- [Figure 7] Figure captions for the wave-tank experiment do not state the number of observations used or the library size, which are central to the headline claim.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and constructive feedback on our manuscript. The comments highlight important aspects regarding the validation of the soft-competitive weighting mechanism and the need for more quantitative experimental metrics. We address each major comment below and commit to revising the manuscript to incorporate additional analyses and metrics as suggested.
read point-by-point responses
-
Referee: [§3.2 (method description of weighting)] The central claim that the soft-competitive weighting yields an unbiased consensus coefficient (and thereby reliable structural identification) rests on an unverified assumption. No bias analysis, sensitivity study to surrogate error, or ablation against uniform averaging is reported for the aggregation step.
Authors: We agree that the manuscript would benefit from a more rigorous validation of the soft-competitive weighting step. While the design of the mechanism is intended to dynamically assess credibility based on per-dataset surrogate performance, we did not include a dedicated bias analysis or ablation study in the original submission. In the revised version, we will add a sensitivity analysis to surrogate approximation errors and an ablation comparing the soft-competitive aggregation against uniform averaging across the datasets. This will provide evidence for the unbiased nature of the consensus coefficient and its impact on structural identification. revision: yes
-
Referee: [§4 (experimental results)] The reported recovery accuracy with 50 observations per source across seven cases is presented without quantitative metrics (e.g., coefficient error distributions, false-positive rates on library terms, or recovery success rates under controlled noise). This makes it impossible to assess whether the genetic search is actually driven by the aggregated coefficients or by other factors.
Authors: We acknowledge that the experimental section relies on qualitative descriptions of 'high accuracy' without detailed quantitative metrics. To address this, the revised manuscript will include coefficient error distributions, false-positive rates for library terms, and recovery success rates under controlled noise levels for all seven cases. These additions will allow readers to evaluate the contribution of the aggregated coefficients to the genetic search process. revision: yes
Circularity Check
No circularity; derivation relies on external optimization steps without self-referential reduction
full rationale
The provided abstract and description outline a pipeline of independent neural surrogate training per dataset, followed by soft-competitive weighting for coefficient aggregation and genetic search for structure. No equations or self-citations are quoted that reduce any claimed prediction or uniqueness result to the input data or prior author work by construction. The method is presented as an empirical fusion framework whose validity rests on performance across cases rather than a definitional loop, making it self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brunton, S. L. & Kutz, J. N. Promising directions of machine learning for partial differential equations. Nat. Comput. Sci. 4, 483–494 (2024)
2024
-
[2]
L., Proctor, J
Brunton, S. L., Proctor, J. L., Kutz, J. N. & Bialek, W. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. U. S. A. 113, 3932–3937 (2016)
2016
-
[3]
H., Brunton, S
Rudy, S. H., Brunton, S. L., Proctor, J. L. & Kutz, J. N. Data-driven discovery of partial differential equations. Sci. Adv. 3, 1–7 (2017)
2017
-
[4]
Messenger, D. A. & Bortz, D. M. Weak SINDy for partial differential equations. J. Comput. Phys. 443, 110525 (2021)
2021
-
[5]
& Kang, S
Tang, M., Liao, W., Kuske, R. & Kang, S. H. WeakIdent: Weak formulation for identifying differential equation using narrow-fit and trimming. J. Comput. Phys. 483, 112069 (2023)
2023
-
[6]
& Earls, C
Stephany, R. & Earls, C. Weak -PDE-LEARN: A weak form based approach to discovering PDEs from noisy, limited data. J. Comput. Phys. 506, 112950 (2024)
2024
-
[7]
& Wang, N
Xu, H., Zhang, D. & Wang, N. Deep -learning based discovery of partial differential equations in integral form from sparse and noisy data. J. Comput. Phys. 445, (2021)
2021
-
[8]
& Zhang, D
Xu, H., Chang, H. & Zhang, D. DLGA -PDE: Discovery of PDEs with incomplete candidate library via combination of deep learning and genetic algorithm. J. Comput. Phys. 418, 109584 (2020)
2020
-
[9]
& Kalyuzhnaya, A
Maslyaev, M., Hvatov, A. & Kalyuzhnaya, A. Data-Driven Partial Derivative Equations Discovery with Evolutionary Approach. in Computational Science -- ICCS 2019 (eds. Rodrigues, J. M. F. et al.) 635–641 (Springer International Publishing, Cham, 2019)
2019
-
[10]
& Zhang, D
Du, M., Chen, Y . & Zhang, D. DISCOVER: Deep identification of symbolically concise open-form partial differential equations via enhanced reinforcement learning. Phys. Rev. Res. 6, (2024)
2024
-
[11]
& Zhang, D
Chen, Y ., Luo, Y ., Liu, Q., Xu, H. & Zhang, D. Symbolic genetic algorithm for discovering open -form partial differential equations (SGA -PDE). Phys. Rev. Res. 4, (2022)
2022
-
[12]
Petersen, B. K. et al. Deep Symbolic Regression: Recovering Mathematical Expressions From Data Via Risk -Seeking Policy Gradients. ICLR 2021 - 9th International Conference on Learning Representations (2021)
2021
-
[13]
& Dong, B
Long, Z., Lu, Y ., Ma, X. & Dong, B. Pde-net: Learning pdes from data. in International conference on machine learning 3208–3216 (PMLR, 2018)
2018
-
[14]
& Dong, B
Long, Z., Lu, Y . & Dong, B. PDE -Net 2.0: Learning PDEs from data with a numeric-symbolic hybrid deep network. J. Comput. Phys. 399, 108925 (2019)
2019
-
[15]
J., Choudhury, S., Sens, P
Both, G. J., Choudhury, S., Sens, P. & Kusters, R. DeepMoD: Deep learning for model discovery in noisy data. J. Comput. Phys. 428, 109985 (2021)
2021
-
[16]
& Zhang, D
Xu, H., Chang, H. & Zhang, D. Dl -pde: Deep-learning based data-driven discovery of partial differential equations from discrete and noisy data. Commun. Comput. Phys. 29, 698–728 (2021)
2021
-
[17]
& Zhang, D
Xu, H. & Zhang, D. Robust discovery of partial differential equations in complex situations. Phys. Rev. Res. 3, (2021)
2021
-
[18]
& Sun, H
Chen, Z., Liu, Y . & Sun, H. Physics -informed learning of governing equations from scarce data. Nat. Commun. 12, 1–13 (2021)
2021
-
[19]
& Fukui, K
Thanasutives, P., Morita, T., Numao, M. & Fukui, K. Noise -aware physics-informed machine learning for robust PDE discovery. Mach. Learn. Sci. Technol. 4, 015009 (2023)
2023
-
[20]
Xu, H. et al. Generative discovery of partial differential equations by learning from math handbooks. Nat. Commun. 16, 10255 (2025)
2025
-
[21]
Du, M., Chen, Y ., Wang, Z., Nie, L. & Zhang, D. LLM4ED: Large Language Models for Automatic Equation Discovery. arXiv preprint arXiv:2405.07761 (2024)
- [22]
-
[23]
& Bolton, T
Zanna, L. & Bolton, T. Data-Driven Equation Discovery of Ocean Mesoscale Closures. Geophys. Res. Lett. 47, (2020)
2020
-
[24]
Beetham, S., Fox, R. O. & Capecelatro, J. Sparse identification of multiphase turbulence closures for coupled fluid-particle flows. J. Fluid Mech. 914, (2021)
2021
- [25]
-
[26]
A review of data fusion techniques
Castanedo, F. A review of data fusion techniques. The scientific world journal 2013, 704504 (2013)
2013
-
[27]
Peng, X. et al. Moment matching for multi-source domain adaptation. in Proceedings of the IEEE/CVF international conference on computer vision 1406–1415 (2019)
2019
-
[28]
& Pedrycz, W
Meng, T., Jing, X., Yan, Z. & Pedrycz, W. A survey on machine learning for data fusion. Information Fusion 57, 115–129 (2020)
2020
-
[29]
& Zhang, D
Xu, H., Zeng, J. & Zhang, D. Discovery of Partial Differential Equations from Highly Noisy and Sparse Data with Physics -Informed Information Criterion. Research 6, (2023)
2023
-
[30]
& Earls, C
Stephany, R. & Earls, C. PDE -READ: Human -readable partial differential equation discovery using deep learning. Neural Networks 154, 360–382 (2022)
2022
-
[31]
& Zhou, Z.-H
Gao, E.-H., Ge, C., Jiang, Y . & Zhou, Z.-H. Discovering Symbolic Partial Differential Equation by Abductive Learning. in The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[32]
& Qiu, Y
Meng, Y . & Qiu, Y . Sparse discovery of differential equations based on multi-fidelity Gaussian process. J. Comput. Phys. 523, 113651 (2025)
2025
-
[33]
Cao, R., Padilla, E. M. & Callaghan, A. H. The influence of bandwidth on the energetics of intermediate to deep water laboratory breaking waves. J. Fluid Mech. 971, A11 (2023)
2023
-
[34]
M., Fang, Y
Cao, R., Padilla, E. M., Fang, Y . & Callaghan, A. H. Identification of the free surface for unidirectional nonbreaking water waves from side-view digital images. IEEE Journal of Oceanic Engineering (2024). Supplementary Information for Joint discovery of governing partial differential equations from multi-source datasets by competitive optimization Hao X...
2024
-
[35]
Across all examples, the equation coefficients were fixed, whereas the multiple cases were created by varying the initial conditions, the computational domain, or both
Supplementary text 1.1 Datasets description All synthetic datasets used in this work were generated from prescribed governing equations in MATLAB or Python under controlled initial and boundary conditions. Across all examples, the equation coefficients were fixed, whereas the multiple cases were created by varying the initial conditions, the computational...
2000
-
[36]
Supplementary figures and tables Fig. S1. Training dynamics of multi -source discovery for the incorrect equation structure. (a,b), Evolution of the identified coefficients for the term uuxx and uxx across the seven cases during training. (c), Evolution of the competitive weights assigned to each case. (d), Evolution of the data loss, PDE loss and total l...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.