Scaling Linear Mode Connectivity and Merging to Billion Parameter Pretrained Transformers
Pith reviewed 2026-06-26 08:38 UTC · model grok-4.3
The pith
Bidirectional optimization of functionality-preserving weight transformations enables near-zero loss barriers when linearly interpolating large pretrained transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
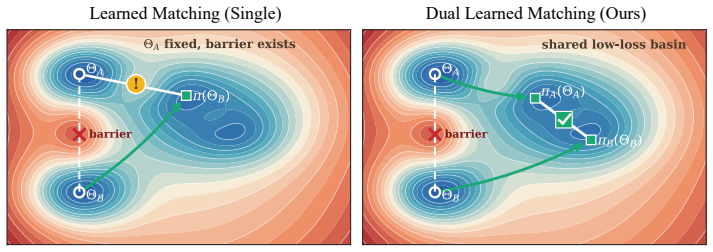
Properly parameterized functionality-preserving weight transformations combined with a dual learning procedure, in which both endpoint models jointly optimize their transformations toward one shared linear interpolation path, substantially reduce interpolation barriers and enable reliable merging of billion-parameter pretrained transformers.
What carries the argument
The dual learning procedure that jointly optimizes bidirectional functionality-preserving weight transformations to produce a shared linear interpolation path.
If this is right
- Linear interpolation becomes a practical route for merging large language models once symmetries are aligned.
- The same alignment procedure scales from medium-sized transformers to billion-parameter models with only small remaining barriers.
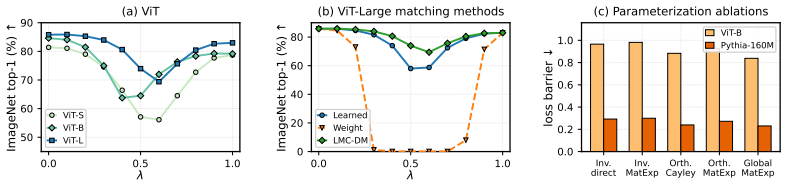
- Vision transformers such as ViT-L maintain high accuracy across the entire linear path after the transformations are learned.
- Model merging no longer requires searching for complex nonlinear paths when the dual procedure is applied.
Where Pith is reading between the lines
- Many independently trained large models may share latent functional equivalences that linear paths can capture once symmetries are removed.
- The approach could be tested on other generative architectures such as diffusion models to check whether the same bidirectional alignment reduces barriers there.
- If the transformations remain stable under continued training, the method might support incremental merging of models fine-tuned on successive tasks.
Load-bearing premise
Functionality-preserving weight transformations exist that can be jointly optimized from both models without lowering the performance of either original network.
What would settle it
After running the bidirectional optimization on a specific billion-parameter LLM, measuring a loss barrier that remains as large as the unaligned case would show the method does not deliver the claimed reduction.
Figures
read the original abstract
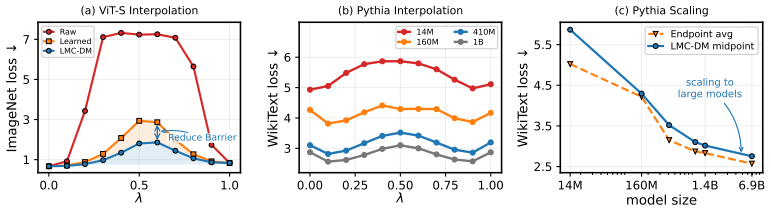
Linear mode connectivity (LMC) provides a promising foundation for understanding and merging independently trained neural networks, but existing methods typically optimize the interpolation path from only one model endpoint, limiting their scalability and effectiveness for large pretrained transformers. We propose a novel and scalable framework for enabling LMC-based model merging to {\em billion-parameter pretrained transformers}. Our method applies properly parameterized functionality-preserving weight transformations to align functionally equivalent solutions, and introduces a dual learning procedure in which both models jointly learn their corresponding transformations toward a shared linear interpolation path. This bidirectional optimization substantially reduces interpolation barriers and enables more reliable merging across large-scale architectures. Empirically, we show that our approach achieves near-zero loss barriers on WikiText for language models with medium-sized parameters, representing, to our knowledge, the first demonstration of near-barrier-free linear connectivity at this scale. In the vision domain, ViT-L maintains above 69\% ImageNet top-1 accuracy throughout the interpolation path, while modern billion-parameter LLMs exhibit only small loss barriers. These results suggest that properly resolving parameter symmetries enables large pretrained Transformers to be connected and merged through simple linear paths with substantially improved interpolation performance. Code: https://github.com/VILA-Lab/Dual-Learned-Matching .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a scalable framework for achieving linear mode connectivity (LMC) in billion-parameter pretrained transformers. It applies parameterized functionality-preserving weight transformations and introduces a dual learning procedure in which both models jointly optimize their transformations toward a shared linear interpolation path. The central empirical claims are near-zero loss barriers on WikiText for medium-sized language models (first such demonstration at this scale), ViT-L maintaining above 69% ImageNet top-1 accuracy throughout the interpolation path, and only small loss barriers for modern billion-parameter LLMs.
Significance. If the reported results hold under rigorous verification, the work would represent a meaningful advance by scaling LMC and model merging to billion-parameter regimes where prior methods have not achieved near-barrier-free connectivity. The bidirectional optimization approach addresses a known limitation of one-sided path optimization, and the public code release supports reproducibility.
minor comments (2)
- [Abstract] Abstract: the claim of 'near-zero loss barriers' and 'first demonstration at this scale' would benefit from explicit numerical values (e.g., barrier height in nats or perplexity) and a direct comparison table against prior one-sided LMC baselines in the main text.
- [Methods] The description of the dual optimization objective and the precise parameterization of the functionality-preserving transformations would be clearer with an explicit equation or pseudocode block early in the methods section.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of our manuscript, recognition of the bidirectional optimization approach, and recommendation for minor revision. We appreciate the acknowledgment that the results, if verified, would represent a meaningful advance in scaling LMC to billion-parameter regimes.
Circularity Check
No significant circularity; empirical method stands on its own
full rationale
The paper describes an optimization-based procedure (parameterized functionality-preserving transformations + bidirectional joint learning toward a shared interpolation path) whose outputs are measured empirically on held-out metrics such as loss barriers and ImageNet accuracy. No equations, uniqueness theorems, or self-citations are invoked that would make the reported connectivity results equivalent to the inputs by construction. The central claim therefore remains an independent empirical finding rather than a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiaolong Han, Zehong Wang, Bo Zhao, Binchi Zhang, Jundong Li, Damian Borth, Rose Yu, Haggai Maron, Yanfang Ye, Lu Yin, et al. A survey of weight space learning: Understanding, representation, and generation.arXiv preprint arXiv:2603.10090, 2026
-
[2]
Loss surfaces, mode connectivity, and fast ensembling of dnns.Advances in neural information processing systems, 31, 2018
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns.Advances in neural information processing systems, 31, 2018
2018
-
[3]
Git re-basin: Merging models modulo permutation symmetries
Samuel K Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries.arXiv preprint arXiv:2209.04836, 2022
-
[4]
Symmetry in neural network parameter spaces.arXiv preprint arXiv:2506.13018, 2025
Bo Zhao, Robin Walters, and Rose Yu. Symmetry in neural network parameter spaces.arXiv preprint arXiv:2506.13018, 2025
-
[5]
Linear mode connectivity and the lottery ticket hypothesis
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the lottery ticket hypothesis. InInternational conference on machine learning, pages 3259–3269. PMLR, 2020
2020
-
[6]
arXiv preprint arXiv:2402.13144 , year=
Kai Wang, Dongwen Tang, Boya Zeng, Yida Yin, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, and Yang You. Neural network diffusion.arXiv preprint arXiv:2402.13144, 2024
-
[7]
Boya Zeng, Yida Yin, Zhiqiu Xu, and Zhuang Liu. Generative modeling of weights: General- ization or memorization?arXiv preprint arXiv:2506.07998, 2025
-
[8]
Large Language Models: A Survey
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey.arXiv preprint arXiv:2402.06196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Essentially no barriers in neural network energy landscape
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. InInternational conference on machine learning, pages 1309–1318. PMLR, 2018
2018
-
[10]
Devin Kwok, Gül Sena Altınta¸ s, Colin Raffel, and David Rolnick. The butterfly effect: Neu- ral network training trajectories are highly sensitive to initial conditions.arXiv preprint arXiv:2506.13234, 2025
-
[11]
Johanni Brea, Berfin Simsek, Bernd Illing, and Wulfram Gerstner. Weight-space symmetry in deep networks gives rise to permutation saddles, connected by equal-loss valleys across the loss landscape.arXiv preprint arXiv:1907.02911, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[12]
Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur. The role of permutation invariance in linear mode connectivity of neural networks.arXiv preprint arXiv:2110.06296, 2021
-
[13]
On the algebraic structure of feedforward network weight spaces
Robert Hecht-Nielsen. On the algebraic structure of feedforward network weight spaces. In Advanced Neural Computers, pages 129–135. Elsevier, 1990
1990
-
[14]
On the geometry of feedforward neural network error surfaces.Neural computation, 5(6):910–927, 1993
An Mei Chen, Haw-minn Lu, and Robert Hecht-Nielsen. On the geometry of feedforward neural network error surfaces.Neural computation, 5(6):910–927, 1993
1993
-
[15]
Model fusion via optimal transport.Advances in Neural Information Processing Systems, 33:22045–22055, 2020
Sidak Pal Singh and Martin Jaggi. Model fusion via optimal transport.Advances in Neural Information Processing Systems, 33:22045–22055, 2020
2020
-
[16]
Op- timizing mode connectivity via neuron alignment.Advances in Neural Information Processing Systems, 33:15300–15311, 2020
Norman Tatro, Pin-Yu Chen, Payel Das, Igor Melnyk, Prasanna Sattigeri, and Rongjie Lai. Op- timizing mode connectivity via neuron alignment.Advances in Neural Information Processing Systems, 33:15300–15311, 2020
2020
-
[17]
Convergent learning: Do different neural networks learn the same representations? InFeature Extraction: Modern Questions and Challenges, pages 196–212
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft. Convergent learning: Do different neural networks learn the same representations? InFeature Extraction: Modern Questions and Challenges, pages 196–212. PMLR, 2015. 10
2015
-
[18]
Slicegpt: Compress large language models by deleting rows and columns
Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024, 2024
-
[19]
Generalized linear mode connectivity for transformers.arXiv preprint arXiv:2506.22712, 2025
Alexander Theus, Alessandro Cabodi, Sotiris Anagnostidis, Antonio Orvieto, Sidak Pal Singh, and Valentina Boeva. Generalized linear mode connectivity for transformers.arXiv preprint arXiv:2506.22712, 2025
-
[20]
Binchi Zhang, Zaiyi Zheng, Zhengzhang Chen, and Jundong Li. Beyond the permutation sym- metry of transformers: The role of rotation for model fusion.arXiv preprint arXiv:2502.00264, 2025
-
[21]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[22]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International conference on machine learning, pages 2397–2430. PMLR, 2023
2023
-
[24]
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Nai...
2024
-
[25]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[26]
Pointer sentinel mixture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016
2016
-
[27]
Going beyond linear mode connectivity: The layerwise linear feature connectivity.Advances in neural information processing systems, 36:60853–60877, 2023
Zhanpeng Zhou, Yongyi Yang, Xiaojiang Yang, Junchi Yan, and Wei Hu. Going beyond linear mode connectivity: The layerwise linear feature connectivity.Advances in neural information processing systems, 36:60853–60877, 2023
2023
-
[28]
Layer-wise linear mode connectivity.arXiv preprint arXiv:2307.06966, 2023
Linara Adilova, Maksym Andriushchenko, Michael Kamp, Asja Fischer, and Martin Jaggi. Layer-wise linear mode connectivity.arXiv preprint arXiv:2307.06966, 2023
-
[29]
Linear mode connectivity between multiple models modulo permutation symmetries
Akira Ito, Masanori Yamada, and Atsutoshi Kumagai. Linear mode connectivity between multiple models modulo permutation symmetries. InF orty-second International Conference on Machine Learning, 2025
2025
-
[30]
Viet-Hoang Tran, Van Hoan Trinh, Khanh Vinh Bui, and Tan M Nguyen. On linear mode connectivity of mixture-of-experts architectures.arXiv preprint arXiv:2509.11348, 2025
-
[31]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportu- nities.ACM Computing Surveys, 58(8):1–41, 2026
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportu- nities.ACM Computing Surveys, 58(8):1–41, 2026. 11
2026
-
[33]
Merging text transformer models from different initializations
Neha Verma and Maha Elbayad. Merging text transformer models from different initializations. arXiv preprint arXiv:2403.00986, 2024
-
[34]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[35]
Fineweb-edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024. URL https://huggingface.co/datasets/ HuggingFaceFW/fineweb-edu
2024
-
[36]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024. 12 Appendix A Limitations Our framework relies on explicitly parameterized functionality-preserving symmetries, and there- fore may not capture all sources of misalignment between independently pretrained models. The ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.