RaBitQCache: Rotated Binary Quantization for KVCache in Long Context LLM Inference
Pith reviewed 2026-07-01 06:31 UTC · model grok-4.3
The pith
RaBitQCache uses randomized rotated binary quantization to produce an unbiased proxy for attention weights, enabling adaptive Top-p retrieval in long-context LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RaBitQCache utilizes randomized rotated binary quantization of KV cache entries together with high-throughput binary-INT4 arithmetic to compute a proxy attention score that is an unbiased estimator possessing a proven error bound; the bound in turn supports adaptive Top-p retrieval that dynamically sizes the active token set to the observed sparsity pattern.
What carries the argument
randomized rotated binary quantization combined with binary-INT4 arithmetic to form a fast, unbiased proxy attention score
If this is right
- Adaptive Top-p retrieval replaces static Top-k, automatically matching token budget to attention sparsity
- Memory I/O during inference is reduced because fewer KV cache entries are loaded
- End-to-end generation quality remains comparable to dense attention while inference accelerates
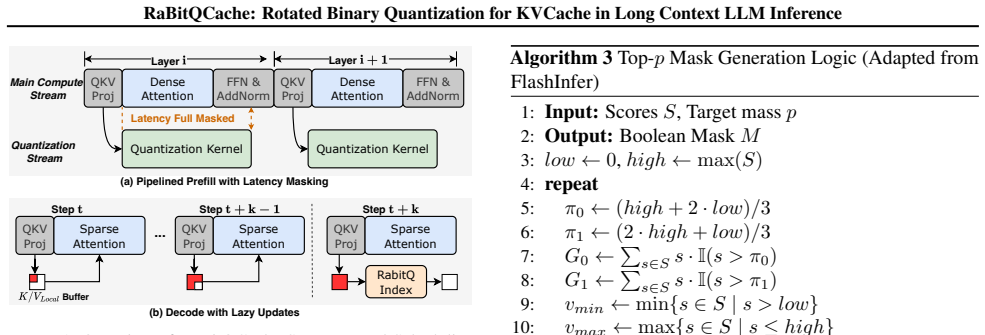
- Asynchronous pipelining and lazy updates keep the quantization overhead from appearing in wall-clock time
Where Pith is reading between the lines
- The same quantization approach could be applied to grouped-query or multi-query attention variants to test whether the error bound still holds
- If the sparsity patterns observed here persist at 1 M+ token contexts, the method may allow further memory reduction without additional algorithmic changes
- Hardware that accelerates binary-INT4 operations would directly amplify the throughput gains reported
Load-bearing premise
The randomized rotated binary quantization produces a proxy whose estimation error stays within the proven bound and whose arithmetic overhead can be completely hidden by pipelining without harming end-to-end speed or generation quality.
What would settle it
An experiment that measures the actual deviation between the proxy scores and exact attention weights on a long-context benchmark and finds the deviation exceeds the claimed error bound, or that shows measurable drop in generation quality relative to full-attention baselines.
Figures
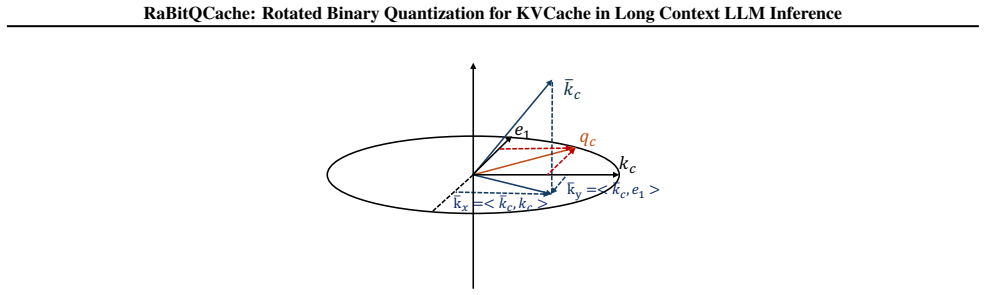
read the original abstract
Long-context Large Language Model inference is severely bottlenecked by the massive Key-Value (KV) cache, yet existing sparse attention methods often suffer from static fixed-budget (Top-k) retrieval or rely on proxy scores that are computationally expensive and biased. To address these limitations, we propose RaBitQCache, a novel sparse attention framework that utilizes randomized rotated binary quantization and high-throughput binary-INT4 arithmetic to efficiently estimate attention weights. Our proxy score serves as an unbiased estimator with a proven error bound, enabling adaptive Top-p retrieval that dynamically adjusts the token budget based on actual attention sparsity. We further implement a hardware-aware system with asynchronous pipelining and lazy updates to mask overhead. Evaluations demonstrate that RaBitQCache significantly accelerates inference and reduces memory I/O while preserving generation quality compared to state-of-the-art baselines. Code is available at https://github.com/Sakuraaa0/RaBitQCache.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
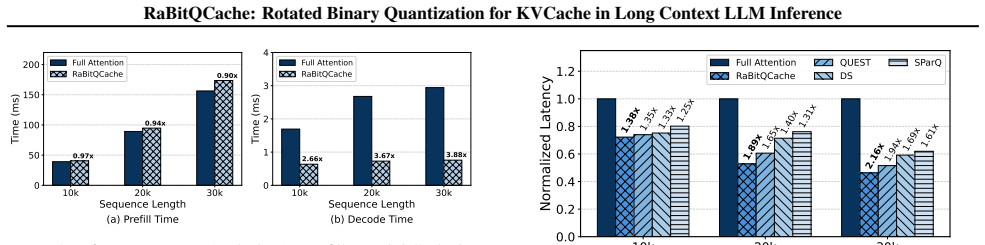
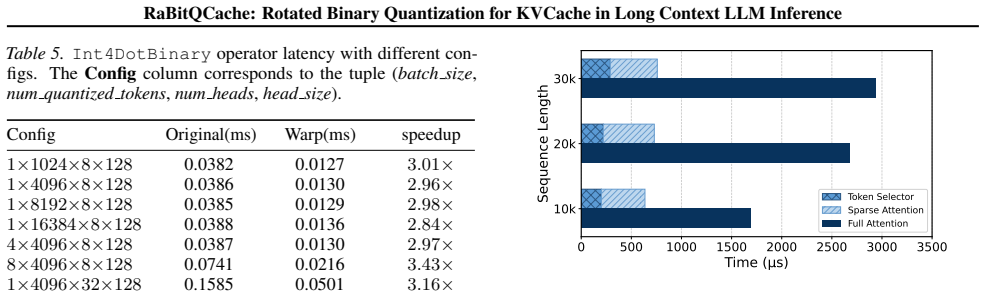
Summary. The paper proposes RaBitQCache, a sparse attention framework for long-context LLM inference. It uses randomized rotated binary quantization combined with binary-INT4 arithmetic to produce a proxy attention score that is claimed to be an unbiased estimator with a proven error bound. This enables adaptive Top-p retrieval that dynamically sets the token budget according to observed attention sparsity. The system adds asynchronous pipelining and lazy updates to hide overhead, and the abstract reports empirical gains in inference speed and memory I/O while preserving generation quality.
Significance. If the unbiased-estimator claim and error bound are rigorously established, the work could meaningfully advance sparse-attention methods by replacing static Top-k budgets and biased proxies with an adaptive, theoretically grounded alternative. The open-source release would further increase its utility for the community.
major comments (1)
- Abstract: the central claim that the proxy 'serves as an unbiased estimator with a proven error bound' is stated without any derivation, distributional assumptions on activations, or statement of the bound itself. Because this property is load-bearing for the adaptive Top-p mechanism, the absence of the proof (or even the relevant equations) prevents evaluation of correctness.
minor comments (1)
- Abstract: the description of the hardware-aware system (asynchronous pipelining, lazy updates) is high-level; a concrete description of how the binary-INT4 arithmetic is scheduled relative to the main attention computation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need for clearer exposition of the central theoretical claim. We address the concern below.
read point-by-point responses
-
Referee: [—] Abstract: the central claim that the proxy 'serves as an unbiased estimator with a proven error bound' is stated without any derivation, distributional assumptions on activations, or statement of the bound itself. Because this property is load-bearing for the adaptive Top-p mechanism, the absence of the proof (or even the relevant equations) prevents evaluation of correctness.
Authors: We agree that the abstract states the claim without supporting details and that the manuscript as submitted does not contain the derivation, assumptions, or explicit bound. This omission makes independent verification impossible from the current text. In the revised version we will (1) expand the abstract with a one-sentence statement of the key assumption (zero-mean activations after rotation) and the form of the bound, and (2) add the full derivation and Theorem 1 (including the O(1/sqrt(d)) high-probability error bound) to Section 3.2 with the relevant equations. We will also move the proof sketch from the appendix into the main body for accessibility. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available summary present RaBitQCache as introducing randomized rotated binary quantization and binary-INT4 arithmetic to produce a proxy score claimed as an unbiased estimator with a proven error bound. No equations, fitting procedures, or self-citations are visible that would reduce any claimed prediction or bound to the inputs by construction. The central claims rest on new components and hardware optimizations rather than re-deriving prior quantities or relying on load-bearing self-citations. Per the rules, absent quotable reductions from the paper's own text, the derivation is treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
arXiv preprint arXiv:2601.20326 , year=
Beyond Speedup--Utilizing KV Cache for Sampling and Reasoning , author=. arXiv preprint arXiv:2601.20326 , year=
-
[4]
M. J. Kearns , title =
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Learning Representations , volume=
Magicpig: Lsh sampling for efficient llm generation , author=. International Conference on Learning Representations , volume=
-
[10]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[11]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[12]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
arXiv preprint arXiv:2501.09499 , year=
VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization , author=. arXiv preprint arXiv:2501.09499 , year=
-
[15]
Data Science and Engineering , volume=
Db-gpt: Large language model meets database , author=. Data Science and Engineering , volume=. 2024 , publisher=
2024
-
[16]
ACM Transactions on Software Engineering and Methodology , volume=
Large language models for software engineering: A systematic literature review , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2024 , publisher=
2024
-
[17]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the 41st International Conference on Machine Learning , pages=
Data engineering for scaling language models to 128K context , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[19]
Qwen2. 5-1m technical report , author=. arXiv preprint arXiv:2501.15383 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the 41st International Conference on Machine Learning , pages=
QUEST: query-aware sparsity for efficient long-context LLM inference , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[22]
ACM Computing Surveys , volume=
Towards efficient generative large language model serving: A survey from algorithms to systems , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[23]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Model tells you what to discard: Adaptive kv cache compression for llms , author=. arXiv preprint arXiv:2310.01801 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in Neural Information Processing Systems , volume=
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Machine Learning , pages=
SparQ Attention: Bandwidth-Efficient LLM Inference , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[26]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Kivi: A tuning-free asymmetric 2bit quantization for kv cache , author=. arXiv preprint arXiv:2402.02750 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the ACM on Management of Data , volume=
Pqcache: Product quantization-based kvcache for long context llm inference , author=. Proceedings of the ACM on Management of Data , volume=. 2025 , publisher=
2025
-
[28]
International Conference on Machine Learning , pages=
Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[29]
arXiv preprint arXiv:2402.18096 , year=
No token left behind: Reliable kv cache compression via importance-aware mixed precision quantization , author=. arXiv preprint arXiv:2402.18096 , year=
-
[30]
arXiv preprint arXiv:2502.02770 , year=
Twilight: Adaptive Attention Sparsity with Hierarchical Top- p Pruning , author=. arXiv preprint arXiv:2502.02770 , year=
-
[31]
arXiv preprint arXiv:2404.15574 , year=
Retrieval head mechanistically explains long-context factuality , author=. arXiv preprint arXiv:2404.15574 , year=
-
[32]
Efficient Streaming Language Models with Attention Sinks
Efficient streaming language models with attention sinks , author=. arXiv preprint arXiv:2309.17453 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Retrievalattention: Accelerating long-context llm inference via vector retrieval , author=. arXiv preprint arXiv:2409.10516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Duoattention: Efficient long-context llm inference with retrieval and streaming heads , author=. arXiv preprint arXiv:2410.10819 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Contemporary mathematics , volume=
Extensions of Lipschitz mappings into a Hilbert space , author=. Contemporary mathematics , volume=
-
[37]
Proceedings of the ACM on Management of Data , volume=
Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search , author=. Proceedings of the ACM on Management of Data , volume=. 2024 , publisher=
2024
-
[38]
Proceedings of the thirty-eighth annual ACM symposium on Theory of computing , pages=
Approximate nearest neighbors and the fast Johnson-Lindenstrauss transform , author=. Proceedings of the thirty-eighth annual ACM symposium on Theory of computing , pages=
-
[39]
Generic LSH families for the angular distance based on Johnson-Lindenstrauss projections and feature hashing LSH , author=. arXiv preprint arXiv:1704.04684 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[41]
Proceedings of Machine Learning and Systems , volume=
Atom: Low-bit quantization for efficient and accurate llm serving , author=. Proceedings of Machine Learning and Systems , volume=
-
[42]
arXiv preprint arXiv:2305.02633 , year=
Conformal nucleus sampling , author=. arXiv preprint arXiv:2305.02633 , year=
-
[43]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Flashinfer: Efficient and customizable attention engine for llm inference serving , author=. arXiv preprint arXiv:2501.01005 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following , year=
How long can context length of open-source llms truly promise? , author=. NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following , year=
2023
-
[47]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[48]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[49]
arXiv preprint arXiv:2408.07092 , year=
Post-training sparse attention with double sparsity , author=. arXiv preprint arXiv:2408.07092 , year=
-
[50]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[51]
LMCache: An efficient KV cache layer for enterprise-scale LLM inference,
Lmcache: An efficient KV cache layer for enterprise-scale LLM inference , author=. arXiv preprint arXiv:2510.09665 , year=
-
[52]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. arXiv preprint arXiv:2307.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
International conference on machine learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[54]
Annals of mathematics , volume=
Der Massbegriff in der Theorie der kontinuierlichen Gruppen , author=. Annals of mathematics , volume=. 1933 , publisher=
1933
-
[55]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[56]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.