Adaptive Oscillatory Inductive Bias for Modeling Sharp Prosodic Dynamics in Diffusion-Based TTS
Pith reviewed 2026-06-25 20:09 UTC · model grok-4.3
The pith
An adaptive oscillatory nonlinearity in diffusion TTS decoders improves modeling of sharp prosodic transitions by allowing controllable periodic modulation with a linear stability bypass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
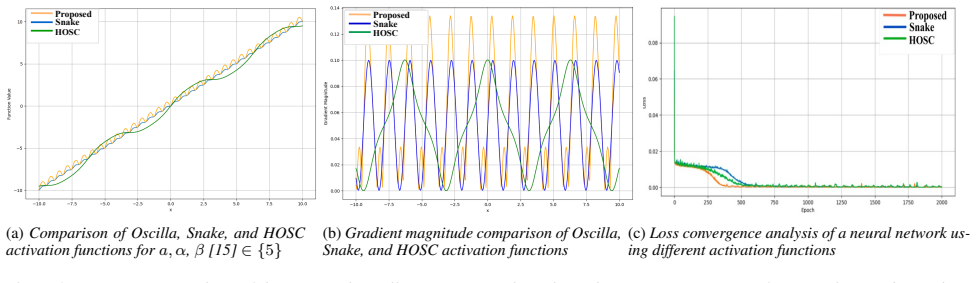
Existing diffusion-based TTS decoders use periodic nonlinearities such as the Snake activation to capture harmonic structure, yet these provide limited adaptability for abrupt amplitude and frequency variations. Replacing them with an adaptive oscillatory nonlinearity enables controllable periodic modulation while a linear bypass component maintains signal stability. The resulting OscillaTTS system produces consistent gains on objective and subjective measures when trained and tested on LJSpeech and the Emotional Speech Dataset.
What carries the argument
Adaptive oscillatory nonlinearity that combines periodic activation with a parallel linear bypass path for controllable modulation and stability.
If this is right
- Objective scores improve on both LJSpeech and the Emotional Speech Dataset.
- Subjective listener ratings rise for naturalness of expressive prosody.
- The decoder gains the ability to model sharp amplitude and frequency variations without losing overall signal stability.
- Periodic modulation becomes adjustable rather than fixed by the choice of activation.
Where Pith is reading between the lines
- The same bypass-plus-adaptive-periodic pattern could be tested in other audio generators that need stable periodic content with sudden changes, such as singing voice or instrument synthesis.
- Varying the adaptation strength at inference time might allow users to dial prosodic sharpness without retraining.
- If the linear bypass is the main stabilizer, removing it in controlled tests would likely reintroduce the instability the paper avoids.
Load-bearing premise
The limited adaptability of fixed periodic nonlinearities such as Snake is the main reason current diffusion TTS models struggle with abrupt prosodic changes, rather than other aspects of the decoder or training.
What would settle it
A side-by-side run of the identical diffusion TTS architecture on the same data, differing only by swapping the activation for the proposed adaptive version, then measuring F0 contour accuracy specifically on segments with known rapid pitch jumps.
Figures
read the original abstract
Diffusion-based text-to-speech (TTS) models have achieved significant improvements in speech quality. However, modeling sharp prosodic transitions and rapid pitch variations in expressive speech remains challenging. Existing diffusion-based TTS decoders commonly utilize periodic nonlinearities such as Snake activation function to capture harmonic structures, but this activation funcation provides limited adaptability when modeling abrupt amplitude and frequency variations. In this paper, we investigate the role of oscillatory inductive bias in diffusion-based TTS decoders and introduce an adaptive oscillatory nonlinearity that enables controllable periodic modulation while maintaining signal stability through a linear bypass component. We refer the resulting TTS system as OscillaTTS. Experiments on the LJSpeech and Emotional Speech Dataset show consistent improvements across objective and subjective evaluations, indicating improved modeling of expressive prosodic dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OscillaTTS, a diffusion-based TTS system that replaces standard periodic nonlinearities such as Snake with an adaptive oscillatory nonlinearity incorporating a linear bypass component. This change is intended to provide controllable periodic modulation while improving modeling of sharp prosodic transitions and rapid pitch variations in expressive speech. Experiments on LJSpeech and the Emotional Speech Dataset are reported to show consistent improvements in objective and subjective evaluations.
Significance. If the gains can be rigorously isolated to the proposed nonlinearity and the experimental design rules out confounding changes, the work would supply a targeted inductive bias for periodic signal modeling that could benefit expressive TTS synthesis. The approach directly targets a known limitation in current diffusion decoders for prosody.
major comments (3)
- [Abstract] Abstract: The claim of 'consistent improvements across objective and subjective evaluations' is unsupported by any quantitative metrics, baseline comparisons, statistical tests, error bars, or experimental controls. This absence prevents evaluation of whether the data support the central empirical claim.
- [Abstract] Abstract / Experiments: No information is given on whether the baseline diffusion TTS decoder (U-Net architecture, noise schedule, training procedure) was held fixed except for the activation function. Without explicit ablation studies isolating the adaptive oscillatory nonlinearity, improvements cannot be attributed to the inductive bias rather than other unmentioned modifications.
- [Abstract] Abstract: The motivation asserts that limited adaptability of Snake and similar activations is the primary bottleneck for abrupt amplitude/frequency variations, yet no supporting analysis, comparison, or diagnostic is supplied to establish this as the dominant cause.
minor comments (2)
- [Abstract] Typo: 'activation funcation' should read 'activation function'.
- [Abstract] Grammatical error: 'We refer the resulting TTS system as OscillaTTS' should be 'We refer to the resulting TTS system as OscillaTTS'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'consistent improvements across objective and subjective evaluations' is unsupported by any quantitative metrics, baseline comparisons, statistical tests, error bars, or experimental controls. This absence prevents evaluation of whether the data support the central empirical claim.
Authors: The abstract is a high-level summary; the full paper reports specific objective metrics (MCD, F0 RMSE, duration error), baseline comparisons against standard diffusion TTS with Snake, and subjective MOS scores. We will revise the abstract to include key quantitative results along with references to error bars and significance testing from the experiments section. revision: yes
-
Referee: [Abstract] Abstract / Experiments: No information is given on whether the baseline diffusion TTS decoder (U-Net architecture, noise schedule, training procedure) was held fixed except for the activation function. Without explicit ablation studies isolating the adaptive oscillatory nonlinearity, improvements cannot be attributed to the inductive bias rather than other unmentioned modifications.
Authors: The experimental setup holds the U-Net, noise schedule, training procedure, and all other hyperparameters fixed, changing only the nonlinearity. We will add an explicit statement in both the abstract and methods section confirming the controlled comparison and will ensure ablation results isolating the nonlinearity are clearly presented. revision: yes
-
Referee: [Abstract] Abstract: The motivation asserts that limited adaptability of Snake and similar activations is the primary bottleneck for abrupt amplitude/frequency variations, yet no supporting analysis, comparison, or diagnostic is supplied to establish this as the dominant cause.
Authors: The motivation draws from prior analyses of periodic activations in audio modeling literature. We agree that direct diagnostics (e.g., activation response curves on high-variation segments) would strengthen the claim and will add such supporting analysis and visualizations in the revised manuscript. revision: partial
Circularity Check
No circularity in derivation or results
full rationale
The paper proposes an adaptive oscillatory nonlinearity (with linear bypass) as an inductive bias for diffusion TTS decoders and reports empirical gains on LJSpeech/ESD. No equations, predictions, or central claims reduce by construction to fitted inputs, self-definitions, or self-citation chains. The motivation cites limitations of Snake-style activations but treats the new form as an ansatz validated externally via objective/subjective metrics; no load-bearing step equates the reported improvements to quantities defined by the method itself. This is a standard empirical architecture paper whose derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in deep learning have significantly improved the quality of text-to-speech (TTS) synthesis systems, enabling highly natural and intelligible synthetic speech [1, 2]. In par- ticular, diffusion-based TTS models have demonstrated strong performance in generating high-fidelity speech by progressively refining acoustic representat...
Pith/arXiv arXiv 2026
-
[2]
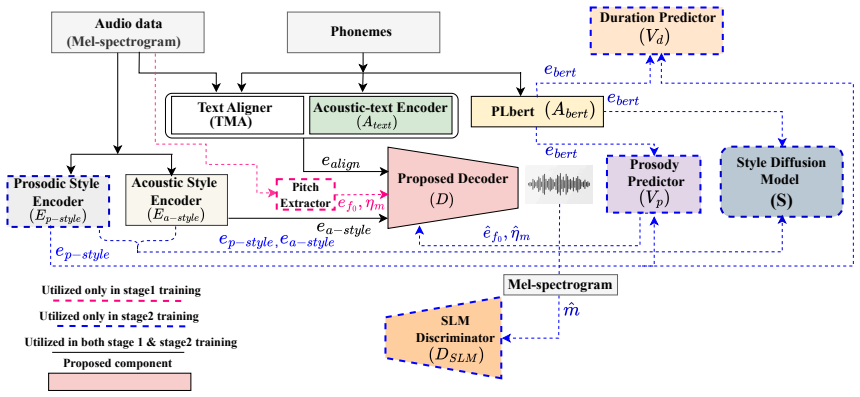
As illustrated in Fig
Adaptive Oscillatory Inductive Bias for Diffusion-Based TTS In this section, We first present the overall architecture and training pipeline, and the integration of the proposed Oscilla ac- tivation within the decoder. As illustrated in Fig. 1, the architec- tural framework and training mechanism follow the StyleTTS2 architecture [9]. Similar to [9], the ...
-
[3]
LJSpeech [16] is used for single- speaker English TTS evaluation
Experimental Setup We evaluate the proposed approach on two publicly available datasets to assess both standard TTS quality and expressive speech synthesis performance. LJSpeech [16] is used for single- speaker English TTS evaluation. The dataset contains approx- imately 24 hours of high-quality speech recordings from a sin- gle female speaker and is wide...
-
[4]
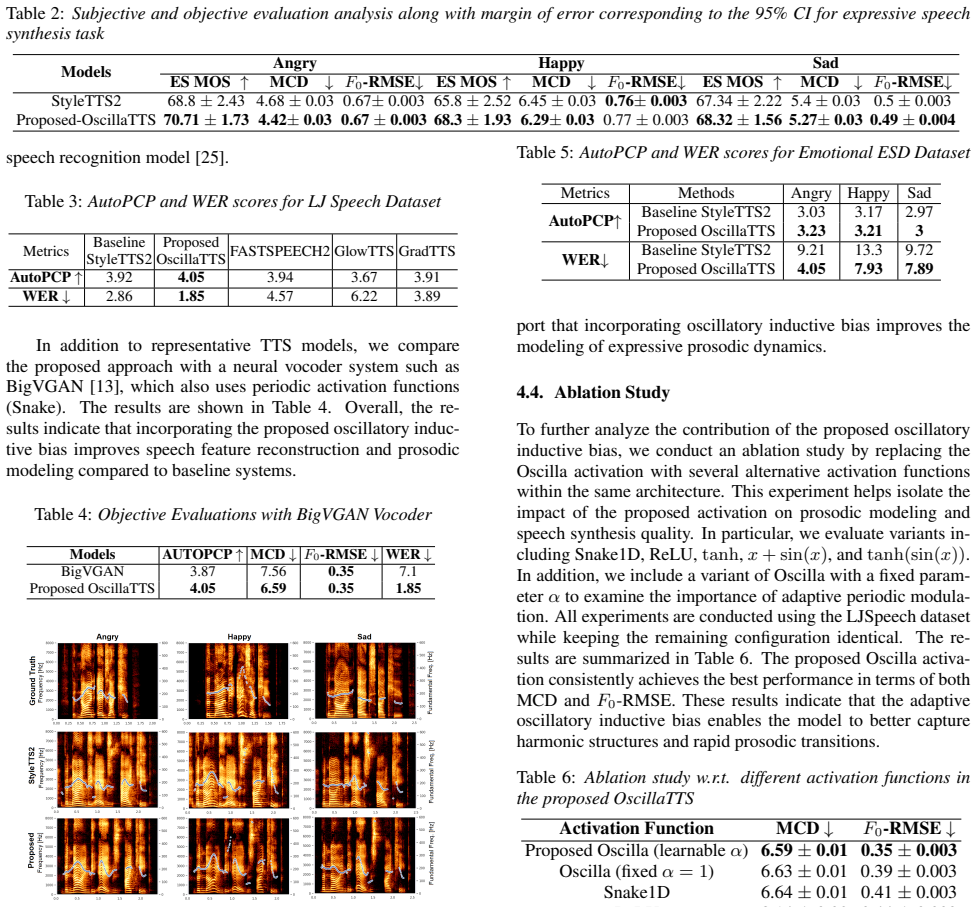
Results and Discussion This section evaluates the effectiveness of the proposed adaptive oscillatory inductive bias in diffusion-based TTS. 4.1. Subjective Evaluation To evaluate perceptual speech quality, MUSHRA-style human listening tests were conducted. A total of 25 human subjects (aged between 22 and 36 years old with no reported hearing impairments)...
-
[5]
We proposed an adaptive oscillatory activation mechanism that enables controllable periodic modulation while maintaining signal stability
Conclusion This work investigated the role of oscillatory inductive bias in diffusion-based TTS systems for modeling expressive speech dynamics. We proposed an adaptive oscillatory activation mechanism that enables controllable periodic modulation while maintaining signal stability. The activation was incorporated into the decoder of the StyleTTS2 archite...
-
[6]
Generative AI Use Disclosure Generative AI tools were used solely for language refinement, grammar correction, and improving the overall clarity and read- ability of the manuscript. These tools assisted in polishing and structuring the text but were not used to generate or design the core research ideas, methodology, experimental setup, analy- sis, or con...
-
[7]
Towards con- trollable speech synthesis in the era of large language models: A systematic survey,
T. Xie, Y . Rong, P. Zhang, W. Wang, and L. Liu, “Towards con- trollable speech synthesis in the era of large language models: A systematic survey,” inProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing, 2025, pp. 764– 791
2025
-
[8]
A survey on audio diffusion models: Text to speech synthesis and enhancement in generative ai,
C. Zhang, C. Zhang, S. Zheng, M. Zhang, M. Qamar, S.-H. Bae, and I.-S. Kweon, “A survey on audio diffusion models: Text to speech synthesis and enhancement in generative ai,”ArXiv, vol. abs/2303.13336, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257913174
arXiv 2023
-
[9]
Diffusion models: A comprehensive survey of methods and applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,”ACM Comput. Surv., vol. 56, no. 4, nov 2023
2023
-
[10]
Grad-tts: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. A. Kudinov, “Grad-tts: A diffusion probabilistic model for text-to-speech,” in Proceedings of the 38 th International Conference on Machine Learning (ICML), 2021
2021
-
[11]
Diff- tts: A denoising diffusion model for text-to-speech,
M. Jeong, H. Kim, S. J. Cheon, B. J. Choi, and N. S. Kim, “Diff- tts: A denoising diffusion model for text-to-speech,” inInter- speech, Brno, Czechia, 2021, pp. 3605–3609
2021
-
[12]
Guided-tts: A diffusion model for text-to-speech via classifier guidance,
H. Kim, S. Kim, and S. Yoon, “Guided-tts: A diffusion model for text-to-speech via classifier guidance,” inInternational Con- ference on Machine Learning, Baltimore, Maryland, USA, 2022
2022
-
[13]
Dutoit,An Introduction to Text-to-Speech Synthesis, 1st ed., ser
T. Dutoit,An Introduction to Text-to-Speech Synthesis, 1st ed., ser. Text, Speech and Language Technology. Dordrecht, The Netherlands: Springer, 1997, vol. 3
1997
-
[14]
VECL-TTS: V oice identity and Emotional style controllable Cross-Lingual Text-to-Speech,
A. Gudmalwar, N. Shah, S. Akarsh, P. Wasnik, and R. R. Shah, “VECL-TTS: V oice identity and Emotional style controllable Cross-Lingual Text-to-Speech,” inInterspeech 2024, 2024, pp. 3000–3004
2024
-
[15]
StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech lan- guage models,
Y . A. Li, C. Han, V . S. Raghavan, G. Mischler, and N. Mes- garani, “StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech lan- guage models,”Advances in neural information processing sys- tems, vol. 36, pp. 19 594–19 621, 2023
2023
-
[16]
Phoneme-level bert for enhanced prosody of text-to-speech with grapheme pre- dictions,
Y . A. Li, C. Han, X. Jiang, and N. Mesgarani, “Phoneme-level bert for enhanced prosody of text-to-speech with grapheme pre- dictions,”IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 1–5, 2023
2023
-
[17]
T. F. Quatieri,Discrete-time speech signal processing: principles and practice. Pearson Education India, 2002
2002
-
[18]
Neural networks fail to learn periodic functions and how to fix it,
L. Ziyin, T. Hartwig, and M. Ueda, “Neural networks fail to learn periodic functions and how to fix it,”Advances in Neural Infor- mation Processing Systems, vol. 33, pp. 1583–1594, 2020
2020
-
[19]
BigVGAN: A universal neural vocoder with large-scale train- ing,
S.-g. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large-scale train- ing,” inThe Eleventh International Conference on Learning Rep- resentations (ICLR), 2023
2023
-
[20]
Ezaudio: Enhancing text-to-audio generation with efficient dif- fusion transformer,
J. Hai, Y . Xu, H. Zhang, C. Li, H. Wang, M. Elhilali, and D. Yu, “Ezaudio: Enhancing text-to-audio generation with efficient dif- fusion transformer,” inProc. INTERSPEECH, Rotterdam, The Netherlands, 2025, pp. 4233–4237
2025
-
[21]
D. Serrano, J. Szymkowiak, and P. Musialski, “HOSC: a periodic activation function for preserving sharp features in implicit neural representations,”ArXiv, vol. abs/2401.10967, 2024
arXiv 2024
-
[22]
The LJ Speech Dataset,
K. Ito and L. Johnson, “The LJ Speech Dataset,” https://keithito.c om/LJ-Speech-Dataset/,{Last Accessed: March 1, 2026}, 2017
2026
-
[23]
Emotional voice con- version: Theory, databases and esd,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional voice con- version: Theory, databases and esd,”Speech Communication, vol. 137, pp. 1–18, 2021
2021
-
[24]
StyleTTS: A style-based generative model for natural and diverse text-to-speech synthesis,
Y . A. Li, C. Han, and N. Mesgarani, “StyleTTS: A style-based generative model for natural and diverse text-to-speech synthesis,” IEEE Journal of Selected Topics in Signal Processing, vol. 19, no. 1, pp. 283–296, 2025
2025
-
[25]
ISTFTNET: fast and lightweight mel-spectrogram vocoder incorporating in- verse short-time fourier transform,
T. Kaneko, K. Tanaka, H. Kameoka, and S. Seki, “ISTFTNET: fast and lightweight mel-spectrogram vocoder incorporating in- verse short-time fourier transform,”IEEE international confer- ence on acoustics, speech and signal processing (ICASSP), pp. 6207–6211, 2022
2022
-
[26]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,”IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 914–921, 2021
2021
-
[27]
Decoupled weight decay reg- ularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay reg- ularization,” in7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[28]
Glow-tts: A genera- tive flow for text-to-speech via monotonic alignment search,
J. Kim, S. Kim, J. Kong, and S. Yoon, “Glow-tts: A genera- tive flow for text-to-speech via monotonic alignment search,”Ad- vances in Neural Information Processing Systems, vol. 33, pp. 8067–8077, 2020
2020
-
[29]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Y . Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T. Liu, “Fastspeech 2: Fast and high-quality end-to-end text to speech,” in 9th International Conference on Learning Representations, ICLR, Virtual Event, Austria, 2021
2021
-
[30]
An overview of voice conversion and its challenges: From statistical modeling to deep learning,
B. Sisman, J. Yamagishi, S. King, and H. Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 132–157, 2020
2020
-
[31]
Seamless: Multilingual expressive and streaming speech translation,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haa- heimet al., “Seamless: Multilingual expressive and streaming speech translation,”arXiv preprint arXiv:2312.05187, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.